







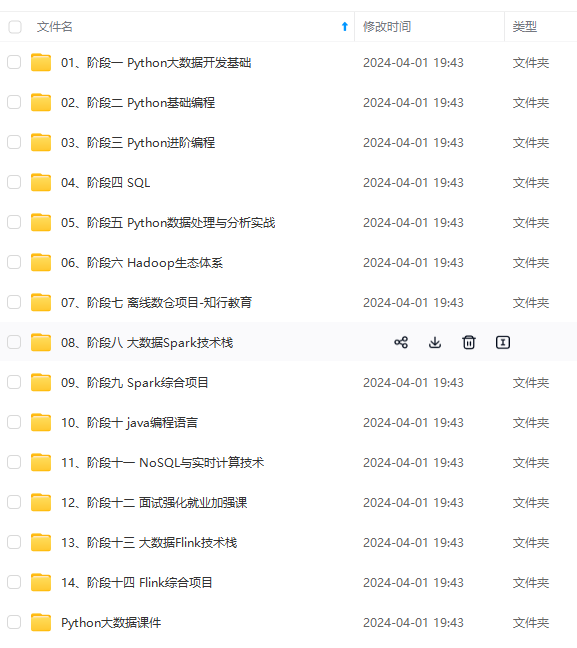
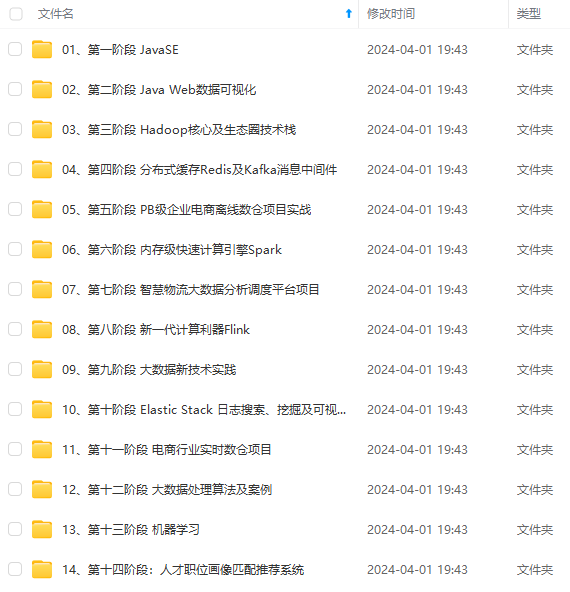
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
1)采用Flume对用户数据进行采集。
2)使用SparkSql计算业务指标。
3)Mahout推荐算法的嵌入。
4)Hive数据仓库设计和维护,数据主题的抽取,数据维度分析。
5)数据的ETL清洗。
6)运用Sqoop导入到Mysql。
7)数据报表展示。
责任描述:
1)Flume收集日志。
2)Kafka对数据流的分离。
3)参与Hive数据仓库设计的讨论。
4)ETL数据清洗。
项目名称: xxx网站用户精准定位系统
项目描述:根据用户在网站的停留时间、跳出率、回访者、新访问者、回访次数、回访相隔天数; 注册用户和非注册用户,分析两者之间的浏览习惯;用户选择什么样的入口形式(广告或者网站入口链接)更为有效; 用户访问网站流程,用来分析页面结构设计是否合理; 用户在页面上的网页热点图分布数据和网页覆盖图数据;用户在不同时段的访问量情况等。对有关数据进行统计、分析,从中发现用户访问网站的规律,并将这些规律与网络营销策略等相结合,从而发现目前网络营销活动中可能存在的问题,并为进一步修正或重新制定网络营销策略提供依据。同时对网站进一步的优化升级。
技术要点:
1)开发日志采集系统:采用埋点代码,采集用户访问行为。
2)采用Flume对记录日志进行收集。
3)Kafka根据业务对数据流的分离。
4)Spark进行业务指标的计算。
5)Hive数据仓库设计。
6)ETL数据的清洗。
7)Sqoop的数据到导入和导出。
8)数据报表展示。
责任描述:
1)Flume收集日志。
2)Kafka对数据流的分离。
3)参与Hive数据仓库设计的讨论。
4)ETL数据清洗。
项目名称:xx公司 xx平台 预警平台产品
项目描述:在电商平台上有很多的业务系统,一旦某个系统的运行出现异常,不能及时发现,将会对平台的运营产生一定的不好的影响。项目主要是通过在各个业务系统上部署埋点代码,分析各个业务系统的运行健康状态,主要包括:购物车系统分析、订单系统分析、支付系统分析、物流系统分析等等,当获取到相关的异常日志信息时就会向有关人员发送消息,保证及时获取异常信息,及时解决异常信息,将不良的影响降到你最低。
技术要点:
1)使用 Flume 收集相关业务系统的日志,自定义拦截器,对应不同的业务系统。
2)将 Flume 采集的业务系统的日志信息存入到 Kafka 中。
3)使用 KafkaSpout 读取日志信息,并定时更新规则库信息与其进行匹配。
4)当触发相关的业务系统报警规则之后,会用阿里大于发送短信通知。
5)使用 Redis 的过期时间保证消息不重复发送。
6)将日志告警信息保存到关系型数据库MySQL 中,供前端报表展示获取业务系统健康状态。
责任描述:
1)前期参与项目分析,讨论对那些系统日志信息进行采集。
2)与 Java 业务组相关人员进行沟通,对接我们的采集任务。
3)使用 Strom 与 Kafka 整合,编写业务代码。
4)当规则触发时,使用阿里大于向有关人员发送短信通知。
工作经历
2015/9 - 2016/5,郑州创新信息公司,Java程序员。
2016/7 - 2017/11,上海中最信息科技有限公司,大数据工程师。
自我评价
1)学习能力强,适应能力强,责任心强,抗压力强。
2)具备较好的沟通能力、团队协作精神、学习能力以及独立解决问题能力。


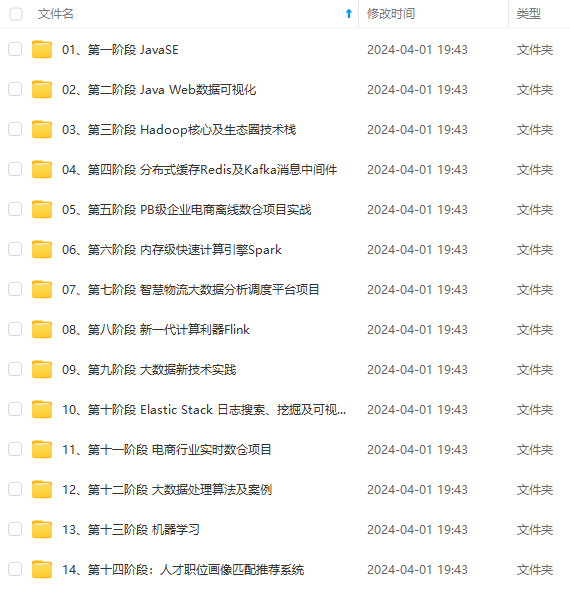
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
更新**















 2295
2295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









