







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2、定义停用词即不参与后期统计的词语
sf = “停用词/停用词.txt”
stop_words = []
with open(sf,‘r’,encoding=‘utf-8’) as f:
for i in f.read().splitlines():
stop_words.append(i)
3、将分词后的文本进行正则化,只保留文本,再次分词
la = re.sub(r’[\s[|]0123456789,、,。’+?!”“‘]’,“”,str(ls))
txt0 =jieba.lcut(la)
4、将正则化后的文本中包含的停用词过滤掉,之后保存到文本文件
ans = []
for x in txt0:
if x not in stop_words and len(x) > 1:
ans.append(x)
res = " ".join(ans)
with open(‘分词文件/a1.txt’,‘w’,encoding=‘utf-8’) as fi:
fi.write(res)
5、针对要统计次频的文本进行词云展示(本步非必要)
wd=wordcloud.WordCloud(font_path=‘C:\Windows\Fonts\simkai.ttf’,width=1800,height=1800,background_color=‘white’,stopwords=[‘要求’,‘甚至’,‘此次’,‘虽然’,‘发现’,‘继续’,‘一个’]).generate(res)
wd.to_file(‘新闻.png’)
**(2****)效果展示:**
**原合集文件内容:**

图 2-1 原文件内容展示
分词后效果:

图 2-2 分词后效果
**生成词云效果图:**
不使用蒙版—>

图 2-3 词云图(原始)
使用蒙版效果图如下(可自定义词云形状)—>

图 2-4 词云图(蒙版)
---
### 3.1 功能3——新闻词频统计
利用MapReduce框架编程对词频进行统计
#### 3.2 实现原理
MapReduce模型核心是Map函数和Reduce函数,核心思想可以用分而治之来描述。一个大的MapReduce作业首先会被拆分为多个Map任务并行执行,当Map任务全部结束后,Reduce过程开始,并且Map生成的中间结果会以<key,value>形式送到多个Reduce中进行合并,合并的过程中,有相同的key的键/值对则送到同一个Reduce上,并由Reduce具体计算出单词所对应的频数。
#### 3.3 主要步骤及代码
**(1****)主要步骤:**
1、进行统计前,我们首先要在Linux环境下配置好hadoop平台后,在进行编程处理
详细配置过程可参考[hadoop配置]( )
2、利用MapReduce框架编程并生成可执行jar包
public class lihongbo {
public lihongbo() {}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 创建一个对象,用于读取配置文件
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
// 获取命令行中除了配置文件以外的其他参数
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
// 如果参数不足两个,则输出用法提示并退出程序
Job job = Job.getInstance(conf, "word count"); // 创建一个作业对象
job.setJarByClass(lihongbo.class); // 设置作业运行时使用的 JAR 文件
job.setMapperClass(lihongbo.TokenizerMapper.class); // 设置 Mapper 类
job.setCombinerClass(lihongbo.IntSumReducer.class); // 设置 Combiner 类(可选)
job.setReducerClass(lihongbo.IntSumReducer.class); // 设置 Reducer 类
job.setOutputKeyClass(Text.class); // 设置输出键类型
job.setOutputValueClass(IntWritable.class); // 设置输出值类型
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i])); // 添加输入路径
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); // 设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 启动作业并等待其完成,返回状态码 0 表示成功,1 表示失败
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// 定义一个 Mapper 类,继承自 Mapper<Object, Text, Text, IntWritable>
private static final IntWritable one = new IntWritable(1); // 定义一个常量 one,值为 1
private Text word = new Text(); // 定义一个文本类型变量 word
public TokenizerMapper() {
// 构造函数,没有实际操作
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 实现 Mapper 类中的 map 函数,对输入数据进行处理
StringTokenizer itr = new StringTokenizer(value.toString()); // 将输入数据转化为字符串
while(itr.hasMoreTokens()) { // 如果还有单词可以读取
this.word.set(itr.nextToken()); // 获取下一个单词
context.write(this.word, one); // 输出键值对,键为单词,值为 one
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义一个 Reducer 类,继承自 Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable(); // 定义一个整数类型变量 result,用于保存累加结果
public IntSumReducer() {
// 构造函数,没有实际操作
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 实现 Reducer 类中的 reduce 函数,对经过 Mapper 处理后的数据进行汇总
int sum = 0; // 定义一个整数变量 sum,用于保存累加结果
for(IntWritable val : values) { // 遍历键值对列表
sum += val.get(); // 累加键值对的值
}
this.result.set(sum); // 将累加的结果设置为 result 的值
context.write(key, this.result); // 输出键值对,键为单词,值为累加结果
}
}
}
3、将做好的新闻分词文件上传至hadoop平台
通过xftp将分词文本上传至Linux系统中的B20041316目录下
./bin/hdfs dfs -mkdir B20041316 #在hdfs上生成一个目录
#将文件上传至hdfs中的B20041316目录下
./bin/hdfs dfs -put ./B20041316/a1.txt B20041316
4、将java程序生成可执行jar包后运行
运行可执行jar文件进行词频统计
./bin/hadoop jar ./myapp/WordCount.jar B20041316 output
5、查看运行结果
./bin/hdfs dfs -cat output/*
**(2****)实现效果图:**

图 3-1 词频统计完成
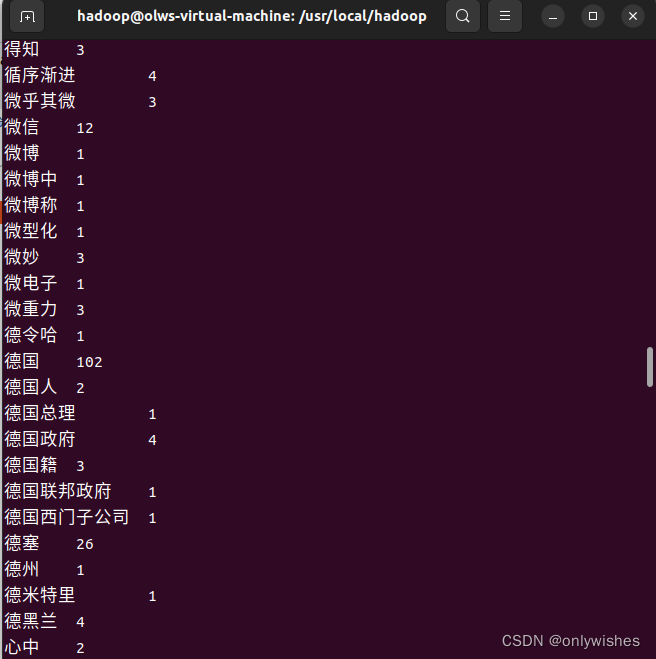
图 3-2 词频统计结果
ps:使用Python实现词频统计
with open(‘…/分词结果/a1.txt’, ‘r’, encoding=‘utf-8’) as f:
lines = f.read().split()
dic = {}
for w in lines:
dic[w] = dic.get(w, 0) + 1
ls = list(dic.items())
ls.sort(key=lambda x:x[0])
f = open(‘…/词频统计结果/out.txt’, ‘w’, encoding=‘utf-8’)
for i in range(len(ls)):
f.write(‘{} {}\n’.format(ls[i][0],ls[i][1]))
f.close()
---
### 4.1功能4——对词频进行排序
由于得到的词频是根据字词进行排序的,而不是字词出现的次数,在几千行词频中无法直接找到前50组,要进行排序,以便于进行可视化网页展示
#### 4.2 实现原理
由于每个词频中的词是不同的,唯一的,利用python中的字典来存储词和频次,对字典中元组进行排序即可得到频次排名前5前、前10、前20、前50的词频
#### 4.3 主要步骤及代码
**(1****)主要步骤:**
1、使用Python将词频存入字典中
with open(‘outcome.txt’, ‘r’,encoding=‘utf-8’) as f:
lines = f.readlines()
dic = {}
for line in lines[:-1]:
lk = line.strip(“\n”).split(“\t”)
dic[lk[0]] = dic.get(lk[0],int(lk[1]))
2、对词频进行排序并输出前5、前10、前20、前50排名的词频
li = list(dic.items())
li.sort(key=lambda x:x[1],reverse=True)
print(‘词频前5:’,li[:5])
print(“-------------------------------------------------”)
print(‘词频前10:’,li[:10])
print(“-------------------------------------------------”)
print(‘词频前20:’,li[:20])
print(“-------------------------------------------------”)
print(‘词频前50:’,li[:50])
**(2****)实现效果图:**
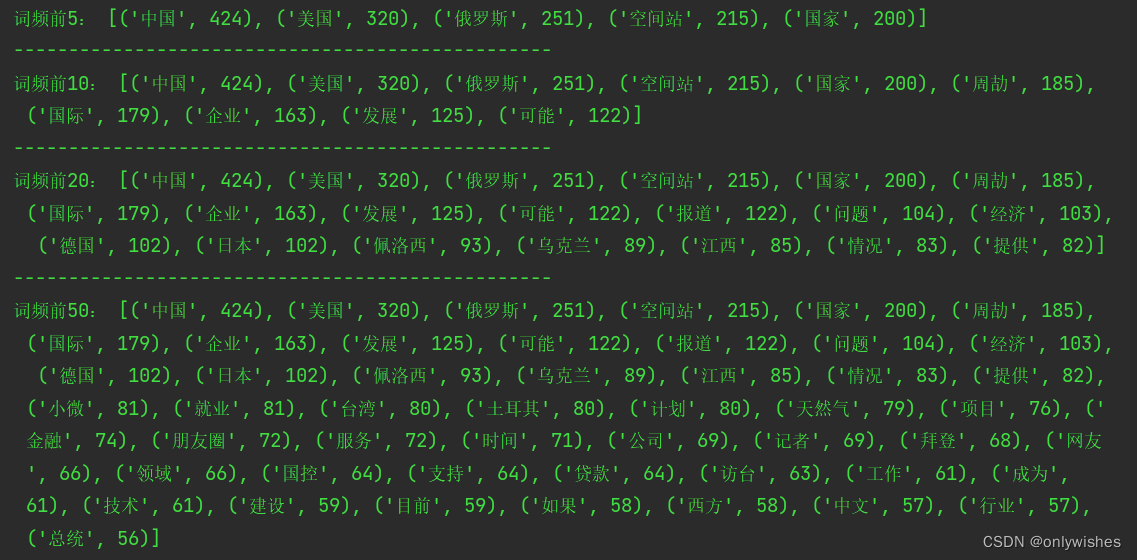
图 4-1 词频排序结果
---
### 5.1 功能5——可视化网页展示词频结果
利用Echarts根据词频排序结果分别进行4种不同的可视化效果展示。
关于Echarts,我们可以访问[Echarts官方文档]( )快速了解它
#### 5.2 实现原理
ECharts 是一个轻量级的 javascript 图形库,纯 js 实现,MVC 封装,数据驱动,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器,底层依赖矢量图形库 ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表。利用得到的排序结果中的数据就可以很轻松的将词频数据以图表的形式进行可视化
#### 5.3 主要步骤及代码
(1)主要步骤:这里以前排名前5的词频为例
1、编写柱状图JavaScript代码,载入数据
2、编写折线图JavaScript代码,载入数据
// 初始化echarts实例
var myChart = echarts.init(document.getElementById(‘main’));
// [(‘中国’, 424), (‘美国’, 320), (‘俄罗斯’, 251), (‘空间站’, 215), (‘国家’, 200)] 排序得到的数据
// 指定图表的配置项和数据
var xDataArr = [‘中国’,‘美国’,‘俄罗斯’,‘空间站’,‘国家’]
var yDataArr = [424, 320, 251, 215, 200]
var option = {
title: {
text: ‘词频前5–折线图’,
top: ‘1%’,
left: ‘10%’,
},
tooltip: {
triggerOn: ‘click’
},
xAxis: {
data: xDataArr,
type: ‘category’,
boundaryGap: ‘false’
},
yAxis: {
type: ‘value’,
// scale:“true”
},
series: [
{
name: ‘单词’,
type: ‘line’,
data: yDataArr,
label: {
show: true
},
markPoint: {
data: [
{
type: ‘max’
},
{
type: ‘min’
}
]
},
markLine: {
data: [
{
type: ‘average’
}
]
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
3、编写饼图JavaScript代码,载入数据
4、编写南丁格尔图JavaScript代码,载入数据(用于词频前5,前10)
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
ercent+'%'
}
}
}
],
selectedMode: 'single' //选中效果
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
4、编写南丁格尔图JavaScript代码,载入数据(用于词频前5,前10)
[外链图片转存中...(img-gh73TmeO-1715583823149)]
[外链图片转存中...(img-0jHN5ubk-1715583823149)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









