








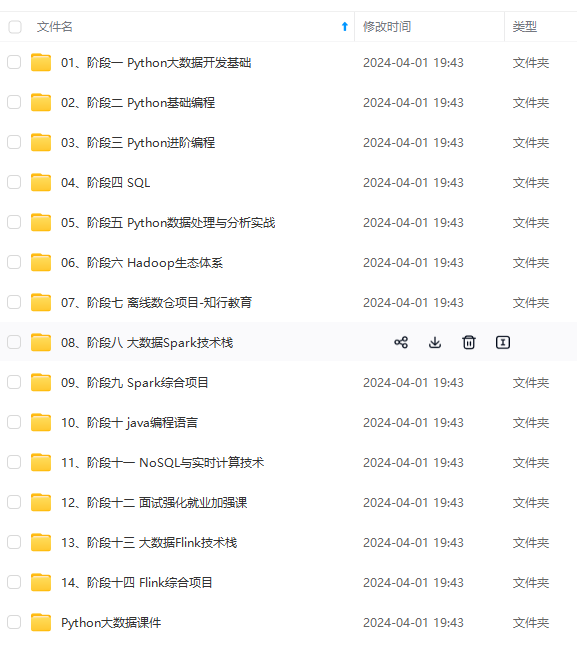

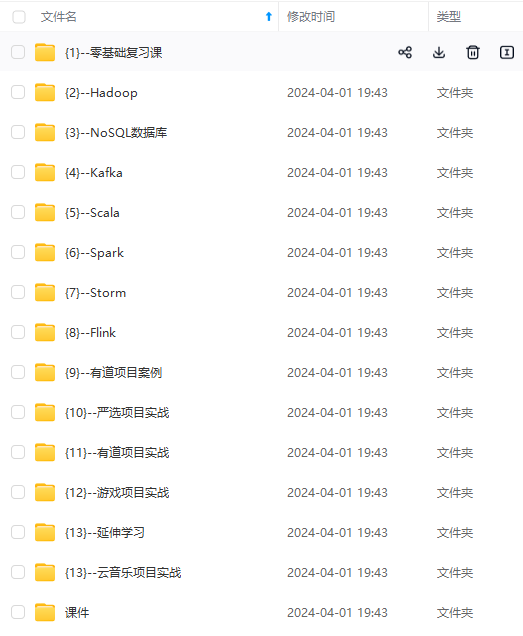
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
便于用sql操作:Hive(核心 metastore,存储这些结构化的数据),同类的还有Impala,hbase等
基于yaml的资源调度
hive :通过 HQL访问,适合执行ETL,报表查询,数据分析等数据仓库任务
支持运行在不同的计算框架,包括MapReduce,Spark,Tez等
支持java数据库连接(JDBC),可以建立与ETL,BI工具的通道
避免编写复杂的mapreduce,减少学习成本
可以直接使用存储在hadoop文件系统中的数据
将元数据保存在关系数据库中,大大减少查询过程中执行语义检查的时间
数据仓库:
(英文Data Warehouse 简称数仓,DW)是一个用于存储,分析,报告的数据系统,目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持
定义:
1 数据仓库并不“生产”任何数据,其数据来源不同的外部系统
2 数据仓库不需要“消费”任何的数据,其结果开放给各个外部应用使用
3 这也是为什么叫“仓库”,而不是“工厂”的原因
…
参考视频:
hdfs:
核心概念:
分布式存储(存储在多个机器上)
元数据(记录存储的位置,权限等,便于查找,由NameNode管理):
两种类型:
1 文件自身属性信息: 文件名称,权限,修改时间,文件大小,复制因子,数据块大小
2 文件块位置映射信息: 记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上
文件分块存储(一个文件特别大/剩余空间不够):默认一个块128M,不足的本身就是一块(hdfs-default.xml:dfs.blocksize)
副本机制(应对硬件故障): dfs.replication默认是3,也就是本身是一份,额外再复制2份。
抽象统一的目录树结构(namespace[命名空间],由nameNode管理,对任何系统文件名称空间或属性的修改都会被记录下来)
NameNode(记录元数据,统领dataNode)/DataNode
主从架构:
1 hdfs集群是标准的master/slave主从架构集群
2 一般一个hdfs是有一个NameNode和一定数目的DataNode组成
3 NameNode 是HDFS主节点,DataNode是HDFS的从节点,两种角色各司其职,共同协调完成分部署的文件存储服务
4 官方架构图是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上
hdfs的shell命令
格式: hadoop fs [generic options]
hadoop发展到现在,除了支持hdfs(hdfs://nn:8020),还支持谷歌(gfs://ip:port/),阿里云,linux,本地文件系统(file:///)等文件系统 —— 具体操作什么取决于命令中文件路径URL中的前缀协议,如果没有指定,则读取core-site.xml:fs.defaultFS属性
hadoop fs -ls hdfs://node1:8020/
hadoop fs -mkdir [-p] <path>
hadoop fs -ls [-h人性化显示] [-R递归查看目录和子目录] [<path>...]
hadoop fs -put [-f覆盖目录文件(已存在)] [-p保留访问和修改时间,所有权和权限] 文件 <path>
hadoop fs -cat :对于大文件读取,慎重
hadoop fs -get [-f] [-p]
完整的: hadoop fs -get hdfs://node1:8020/chino/2.txt file:///root/test/
简化: hadoop fs -get /chino/2.txt /root/test/(./)
hadoop fs -cp [-f覆盖]
hadoop fs -appendToFile :追加数据到文件中
hadoop fs -appendToFile 2.txt 3.txt/1.txt [2.txt,3.txt追加到1.txt末尾,1.txt要在namespace里]
hadoop fs -mv :移动
hdfs的角色和职责:
NameNode:
1 是HDFS的核心,架构中的主角色
2 namenode成为访问hdfs的唯一入口
3 维护和管理文件系统元数据,包括命名空间目录树结构、文件和块的位置信息、访问权限等信息
4 内部通过内存和磁盘文件两种方式管理元数据
磁盘上的元数据文件包括:Fsimage内存元数据镜像文件 和 edits log(Journal)编辑日志
职责:
1 NameNode仅存储HDFS的元数据: 文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据
2 NameNode知道HDFS中任何给定文件的块列表及其位置,使用此信息NameNode知道如果从块中构建文件
3 NameNode不持久化存储每个文件中各个块所在的datanode的位置,这些信息会在系统启动时从DataNode重构
4 NameNode是Hadoop集群中的单点故障
5 NameNode所在机器通常会配置有大量内存(RAM)
DataNode:
1 是HDFS的从角色,负责具体的数据库存储
2 DataNode的数量决定了HDFS集群的整体数据存储能力,通过和NameNode配合维护数据块
职责:
1 DataNode负责最终数据块block的存储,是集群中的从角色,也成为Slave
2 DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的快信息
3 当某个DataNode关闭时,不会影响数据的可用性,NameNode将安排由其他DataNode管理的块进行副本复制
4 DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中
SecondaryNameNode:
1 Secondary NameNode 充当NameNode的辅助节点,但不能替代NameNode
2 主要是帮助主角色进行元数据文件的合并动作,可以通俗理解为主角色的“秘书”
核心概念:
PipeLine :管道,这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
流程:客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点
Q/A
问:为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输?
答:因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的宽带,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时
ACK应答响应(两两之间的校验,三条数据三次响应)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ttps://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1956
1956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









