








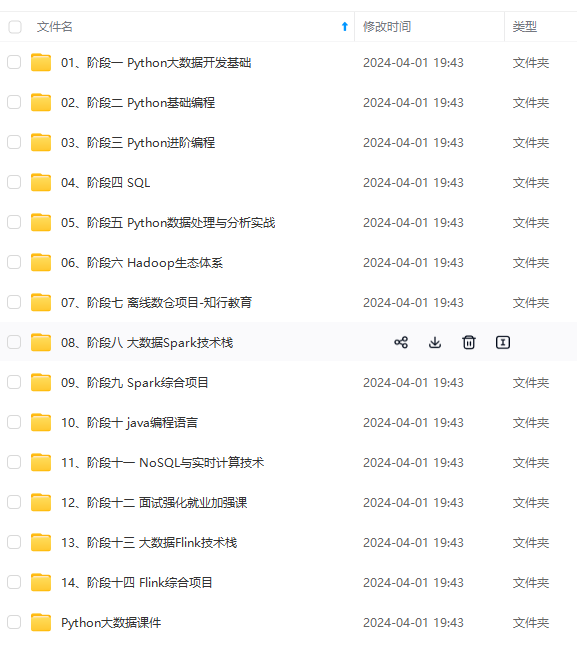
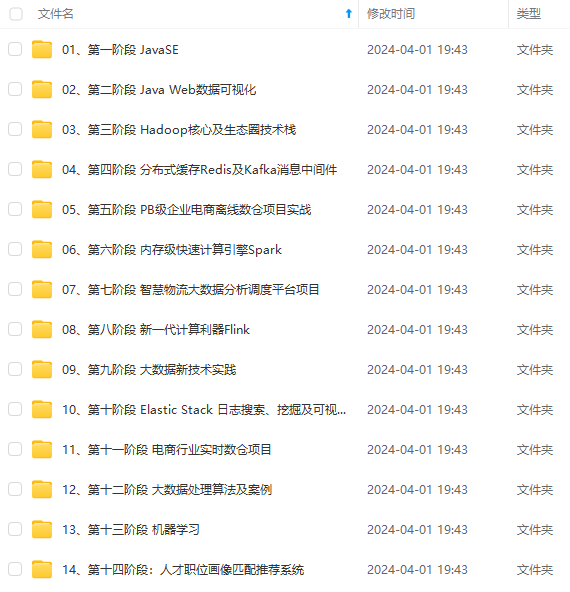
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
大数据工程师的门槛相对其他两个较低一些,所以同学们可以重点关注一下这个方向。
先说一些必备的技能吧。
-
对 Java 虚拟机有着深入的研究,推荐书籍,周志明的《深入理解 Java 虚拟机》。
-
对 Java 并发掌握得很透彻,推荐书籍,《Java 并发编程实战》。
-
掌握 Hadoop。Hadoop 是一款支持数据密集型分布式应用程序并以 Apache 2.0 许可协议发布的开源软件框架,可以使应用程序与成千上万的独立计算的电脑和 PB 级的数据连接起来,整个 Hadoop “平台”还包括 MapReduce、Hadoop 分布式文件系统(HDFS)。
-
掌握 HBase。HBase 是一个开源的非关系型分布式数据库,是 Hadoop 项目的一部分,运行于 HDFS 文件系统之上,对稀疏文件提供极高的容错率。
-
掌握 Hive。Hive 是一个建立在 Hadoop 架构之上的数据仓库,能够提供数据的精炼,查询和分析。
-
掌握 Kafka。Kafka 的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。
-
掌握 Storm。Storm 是一个分布式计算框架,使用用户创建的“管”和“螺栓”来定义信息源和操作,允许批量、分布式处理流式数据。
-
了解 Scala。Scala 是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。可以和 Java 兼容,运行在 Java 虚拟机上。
-
掌握 Spark。Spark 是一个开源集群运算框架,相对于 Hadoop 的 MapReduce 会在运行完工作后将中介数据存放到磁盘中,Spark 使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
-
会用 Linux。推荐书籍,鸟哥的《Linux 私房菜》。
再来说一些高阶的技能吧。
-
会用 Python。
-
会用 R 语言。
-
精通算法和数据结构。
03、大数据科学家的技能要求
“科学家”,这个 title 听起来就很牛逼,不会出乎同学们的意料,我小时候的梦想之一除了成为一名作家之外,就是成为一名“科学家”。
那大数据科学家,要求的技能就会超出绝大多数普通人的能力。首先,要对“统计机器学习方法”有着很深入的研究,既要会预测,还要能解释为什么要这样预测,对吧?
如果要预测股票是涨还是跌,就必须得有一套可以解释给客户听的理论,还要有一套预测方法,让程序能够按照这个方法去执行,并得出预期的结论。
现如今,数据已经不值钱了,哪里都是大量的数据,值钱的是通过对这些数据进行分析,得出指导性的建议——这就要求科学家要有数据处理的能力。
不多说了,这方面的要求非常高,最起码也得考个研究生吧。
04、数据分析师的技能要求
数据分析也可以细分为两个领域,一个类似产品经理,更注重业务,对业务能力要求比较高;一个偏向数据挖掘,更注重技术,对算法和数据结构要求比较高。
那不管是产品经理还是做数据挖掘,SQL 是必知必会的,因为数据分析师每天都要处理海量的数据,而这些数据来自哪呢?就是数据库。那怎么把数据从数据库中取出来呢?SQL 语句(select * from xxx,哈哈),别无其他。
那还需要什么技能呢?统计学基础,对,没错,数据和时间的关系,数据的动态分布,数据的最大值、最小值、平均值,这些都需要一定的统计学基础。
当然了,做数据分析最好的编程语言是 R 语言或者 Python,所以还需要学习一下这两门语言。不过,有了 Java 作为基础,学 Python 就会更容易些,因为 Python 本身的语言更简洁。(R 语言主要用于统计分析、绘图、数据挖掘)
推荐两本书吧,《深入浅出数据分析》和《精益数据分析》。
05、最后

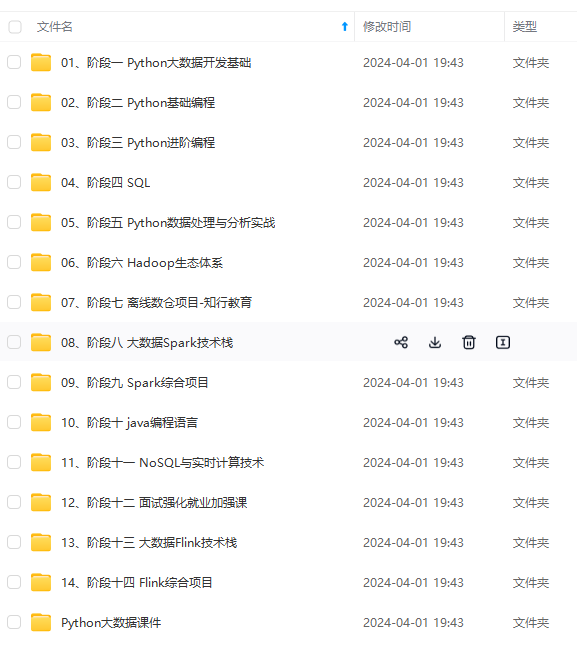
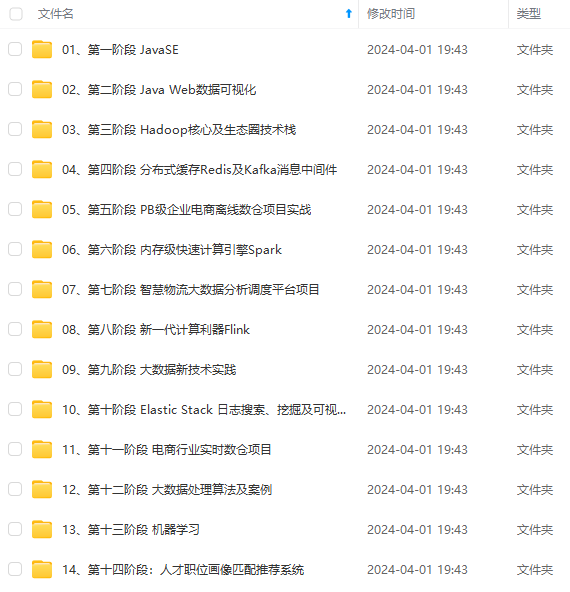
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









