







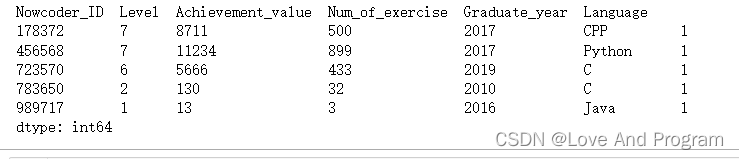
"Nowcoder\_ID":[178372,989717,783650,723570,456568],
"Level":[7,1,2,6,7],
"Achievement\_value":[8711,13,130,5666,11234],
"Num\_of\_exercise":[500,3,32,433,899],
"Graduate\_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java','C','C','Python'],
})
data.value_counts()
很明显,除非是两行数据一模一样,否则最右边统计个数只有一个,但是他也很人性化,若是遇见存在相同的数据会显示为空并放在一起,读者可以自行尝试
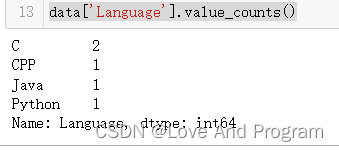
既然如此根据题目要求,我们选取特定一列即可完成任务:
data[‘Language’].value_counts()
---
>
> count() : For each column/row the number of non-NA/null entries.
>
>
>
翻译:对于每列/行,非 NA/空条目的数量。
总结一下:直接用的话计算的是数量,单纯的数量!但是我们有一个分组函数`groupby()`,他们可以结合使用,于是答案就出来了。
在此之前,我先给大家稍微说一下什么是`groupby()`函数,一个小demo可以轻松理解:
import numpy as np
import pandas as pd
data= pd.DataFrame({
“Num_of_exercise”:[500,3,32,433,899],
“Graduate_year”:[2017,2016,2010,2019,2017],
“Language”:[‘CPP’,‘Java’,‘C’,‘C’,‘Python’],
})
data[‘Language’].value_counts()
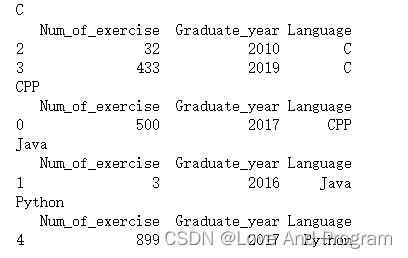
data1 = data.groupby(‘Language’)
for name,group in data1:
print (name)
print (group)
以不通语言为一组,这就是分组后的内容,注意:groupby函数不能够直接显示具体内容,其代指<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000028EA26A2B20>,所以需要循环输出。
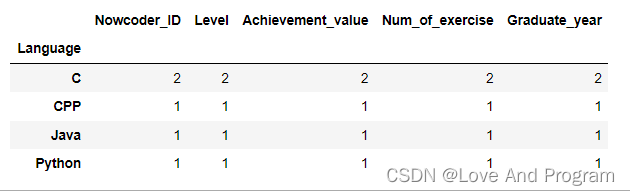
上面说了要用`count()`和`groupby()`函数两者结合,两者结合后会发生奇妙的化学反应,反应如下,可以直接生成数据:
data.groupby(‘Language’).count()
于是我们只需要随便选一行就好了
注意,因为与输出结果略显不同,所以count()无法输出牛客网的这道题
data.groupby(‘Language’).count()[‘Nowcoder_ID’]
---
>
> size() :Return the number of rows if Series. Otherwise return the number of rows times number of columns if DataFrame.
>
>
>
翻译:如果为`Series`,则返回行数。如果是 `DataFrame` 则返回列中的的行数。
总结一下:可以理解为在列中寻找相同的行,统计的是每条数据的条数,上面讲的`count()`函数统计的是值的个数,所以需要最后单独选一列,而`size`则不需要,代码如下:
注意,因为与输出结果略显不同,所以size()无法输出牛客网的这道题
data.groupby(‘Language’).size()

---
最终代码整理如下:
[DA12 牛客网不同语言使用人数](https://bbs.csdn.net/topics/618545628)
import pandas as pd
Nowcoder = pd.read_csv(‘Nowcoder.csv’, sep=‘,’)
print(Nowcoder.loc[:,‘Language’].value_counts())
---
>
> 我们热爱这个世界时,才真正活在这个世界上。 ————泰戈尔
>
>
>


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 2394
2394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









