








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
Kudu存储数据以后,可以快速查询分析(即席查询,与Impala集成)和报表分析(SparkSQL)。
Kudu诞生之初(设计目标)就是为取代HDFS文件系统和HBase数据库,既能够实现随机读写,又能够批量加载分析,所以Kudu属于HBase和HDFS折中产品。
05-[理解]-SQL on Hadoop 技术发展
大数据技术框架中(领域中),SQL框架目前越来越多,从最开始Hive框架,到现在Flink SQL,至少10种以上框架出现,但是使用较多:Hive、
Impala、Presto、SparkSQL、FlinkSQL(正在迅速发展)。
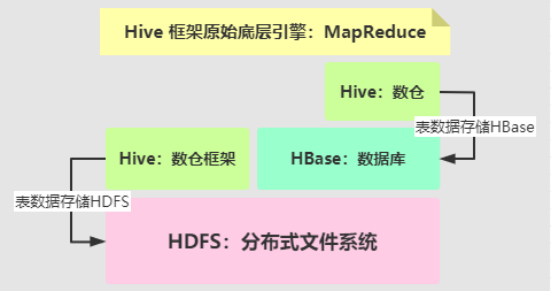
- 1)、Hive 数仓框架,建立在HDFS和HBase之上,提供SQL分析数据
- 2)、Impala 内存分析引擎,取代Hive底层MapReduce,使用内存分析数据
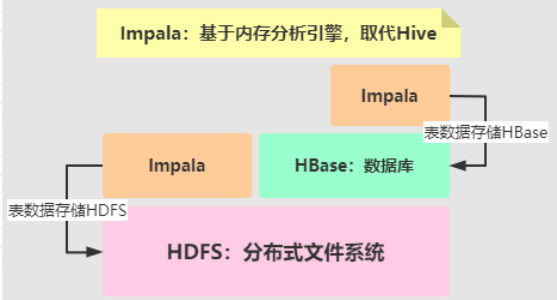
Cloudera公司依据Google论文:Dremel 论文,开发基于内存分析引擎Impala。
- 3)、Impala集成Kudu,在快速数据之上建立快速分析
Cloudera公司,如果公司既要求对数据进行随机读写查询,又要对数据进行批量加载快速分析,需要将数据存储到HDFS(PARQUET)和HBase,能不能一个框架存储引擎实现2个功能:
Kudu。
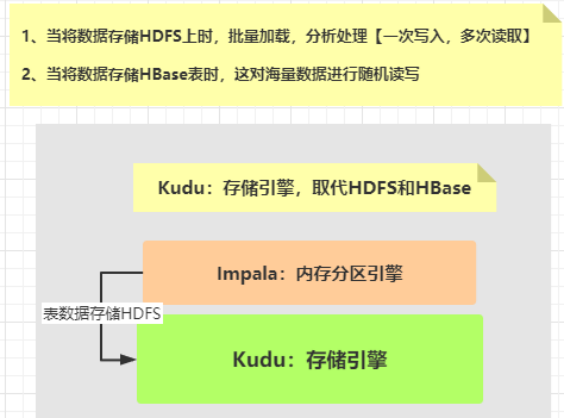
Kudu和Impala都是使用C++语言编写,使用内存进行数据存储和分析,速度比较快的,很多金融公司、证券公司或游戏公司,都会使用此种大数据技术,进行存储数据和分析数据。
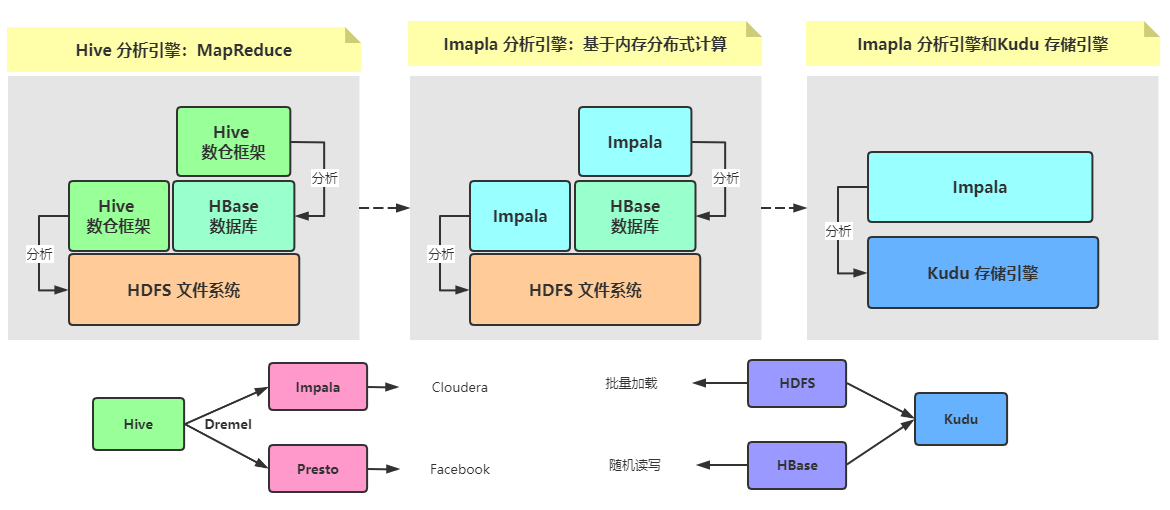
Kudu 在一个系统中融合了 OLTP 型随机读写能力与 OLAP 型分析能力,填补了 Hadoop存储层的缺憾,是 Hadoop 生态的一大生力军。

06-[理解]-Kudu 是什么及应用场景
Apache Kudu是由Cloudera开源的
存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。

1、Kudu是一种非洲的大羚羊,中文名叫“捻角羚”;
2、Impala是另一种非洲的羚羊,叫做“黑斑羚”,也叫“高角羚”;
不知道Cloudera公司为什么这么喜欢羚羊,也许是因为羚羊的速度快。
在Kudu之前,大数据主要以两种方式存储:

如果对业务数据既需要随机读写,有需要批量加载快速分析,实现如下架构:
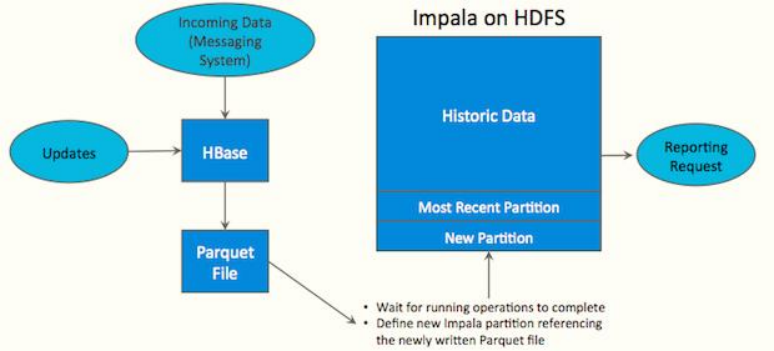
上述架构:数据冗余性比较大、技术框架复杂性比较高、数据实时性降低。
为了解决上述架构的这些问题,Kudu应运而生。Kudu的定位是
Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
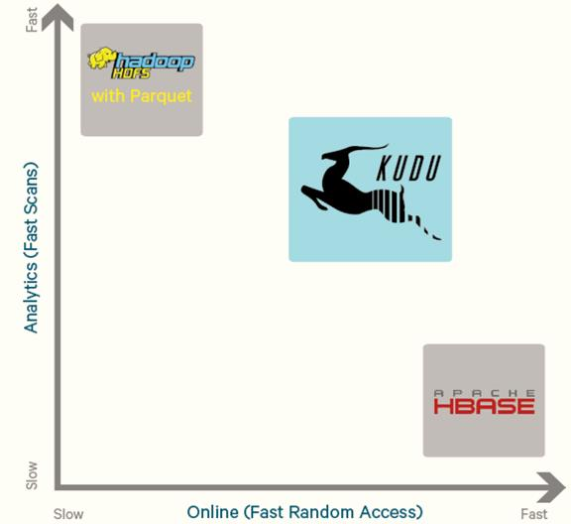
从上图可以看出,KUDU 是一个折中的产品,在 HDFS 和 HBase 这两个偏科生中平衡了随机读写和批量分析的性能。
Kudu相比与以往的系统,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了。
Kudu 应用场景:

07-[掌握]-Kudu 数据存储模型
KUDU 的数据模型与传统的关系型数据库类似:一个 KUDU 集群由多个表组成,每个表由多个字段组成,一个表必须指定一个由若干个(>=1)字段组成的主键。
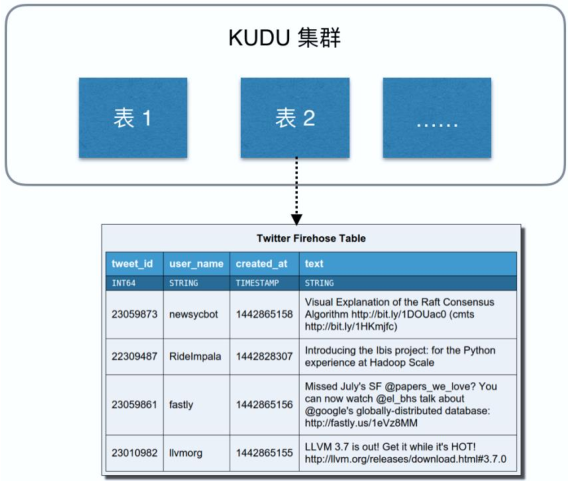
KUDU 表中的
每个字段是强类型的,而不是 HBase 那样所有字段都认为是 bytes。好处是可以对不同类型数据进行不同的编码,节省空间。同时,因为 KUDU 的使用场景是 OLAP 分析,有一个数据类型对下游的分析工具也更加友好。
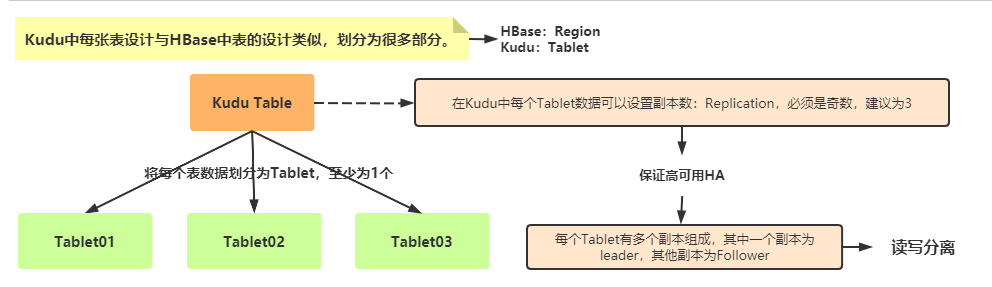
- 1)、Table表:Schema信息(字段名称和字段类型)、主键约束(PrimaryKey)
- 2)、Tablet:表的一个数据片段,类似HBase中Region
- 在Kudu中将表划分为多个Tablet,每个Tablet存储自己数据
- Tablet 副本机制,1个副本为leader,其他副本为Follower,类似Kafka Topic中分区Partition。
- 副本之间,
基于Raft协议,实现高可用HA,当leader挂掉以后,从Follower中选取leader。 - 副本数必须为奇数,例如为3个副本等
08-[掌握]-Kudu 分区策略及列式存储
在Kudu存储引擎中,如何将一个表Table数据划分为多个Tablet???有哪些分区策略:
在Kudu中,每个表的分区Tablet需要
在创建表的时候指定,表创建以后不能被修改。
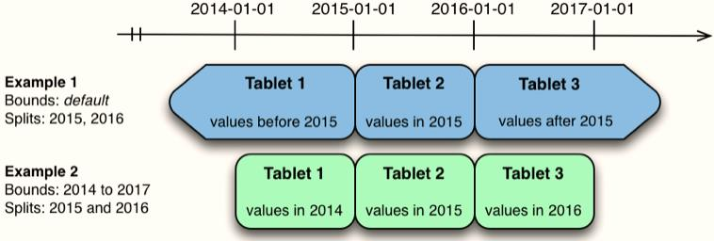
- 1)、范围分区:
Range Partitioning,类似HBase表划分
- 按照字段值范围进行分区,HBase 就采用了这种方式。
- 2)、
Hash Partitioning,按照字段的Hash 值进行分区,Cassandra采用了这个方式。
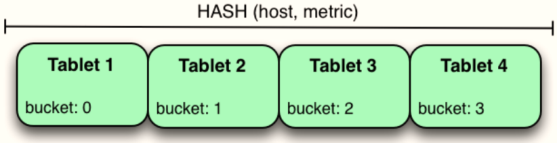
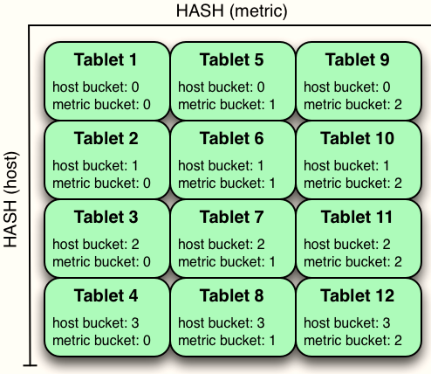
- 3)、多级分区,可以指定范围,再指定哈希或者指定多个哈希分析
KUDU 支持用户对一个表指定一个范围分区规则和多个 Hash 分区规则,如下图:
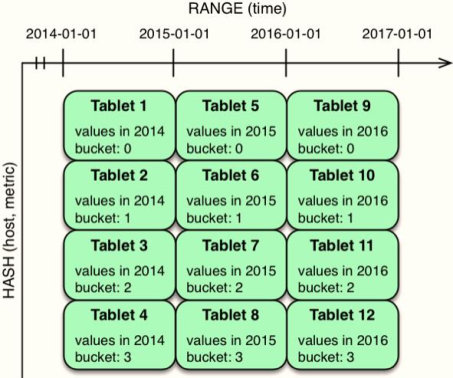
多级散列分区组合,如下图所示:
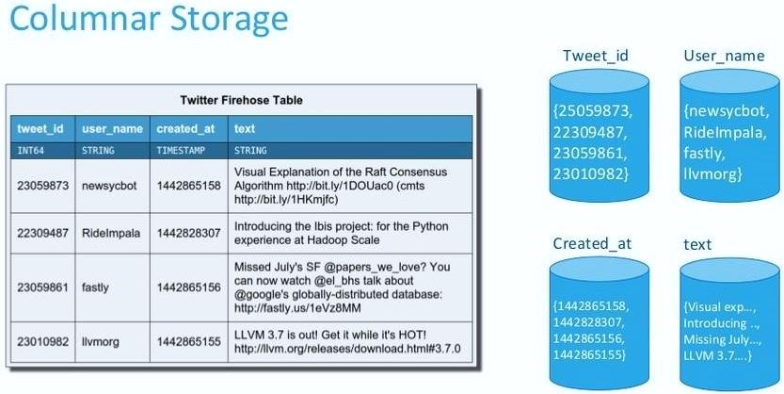
KUDU 是一个
列式存储的存储引擎,其数据存储方式如下:
列式存储的数据库很适合于
OLAP场景,其特点如下:

09-[掌握]-Kudu 框架整体架构设计
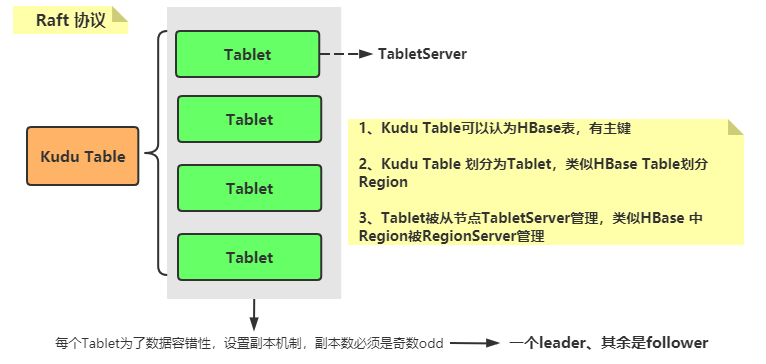
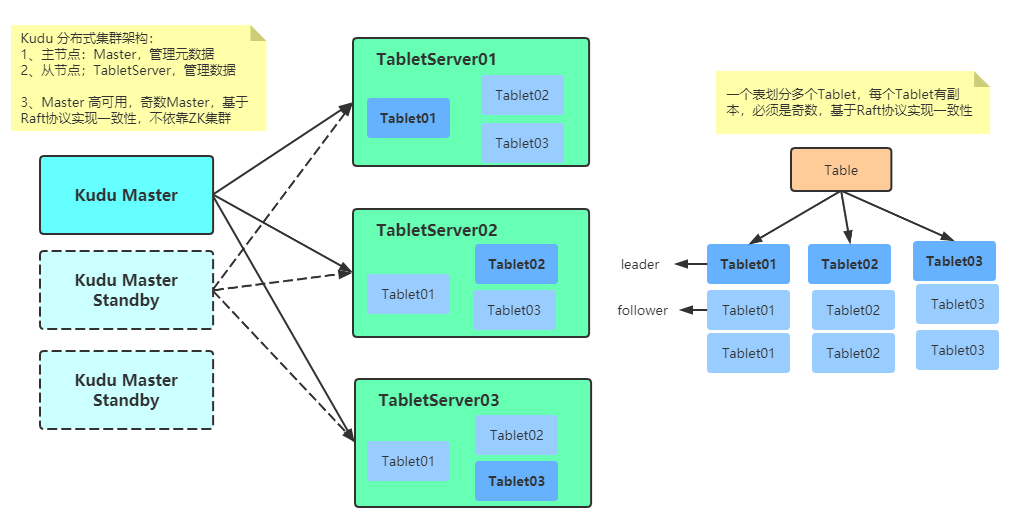
KUDU 中存在两个角色:基于Raft协议实现一致性,所以不依赖Zookeeper
- 1、
Master Server:负责集群管理、元数据管理等功能,类似HBase Master- 2、
Tablet Server:负责数据存储,并提供数据读写服务,类似HBase RegionServer在 KUDU 中都可以设置特定数量(3 或 5)的副本。各副本间通过 Raft 协议来保证数据一致性。Raft 协议与 ZAB 类似,都是 Paxos 协议的工程简化版本。
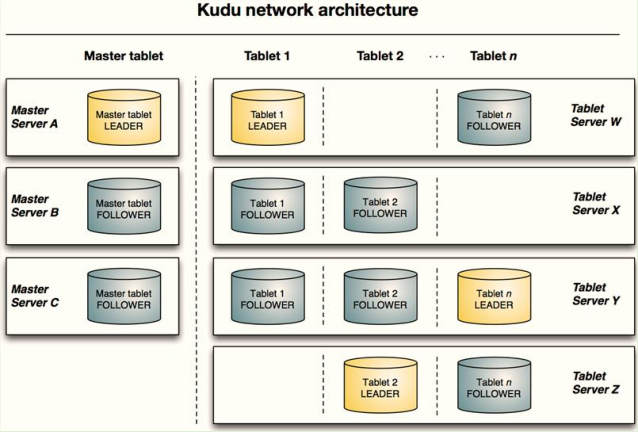
- 1)、Kudu Master通常3个节点,1个是leader,其余2个是Follower
- 2)、表的每个Tablet副本通常3个副本,1个leader,其余2个时Follower,各个副本存储在不同TabletServer机器。
Tablet server 的任务非常繁重, 其负责和数据相关的所有操作, 包括存储, 访问, 压缩, 其还负责将数据复制到其它机器。 因为 Tablet server`特殊的结构, 其任务过于繁重, 所以有如下限制:

10-[掌握]-Kudu 服务启动及相关配置
大数据所有技术框架都是安装在
node2.itcastn.cn机器上,基于CM安装CDH组件,所以已经安装完成。
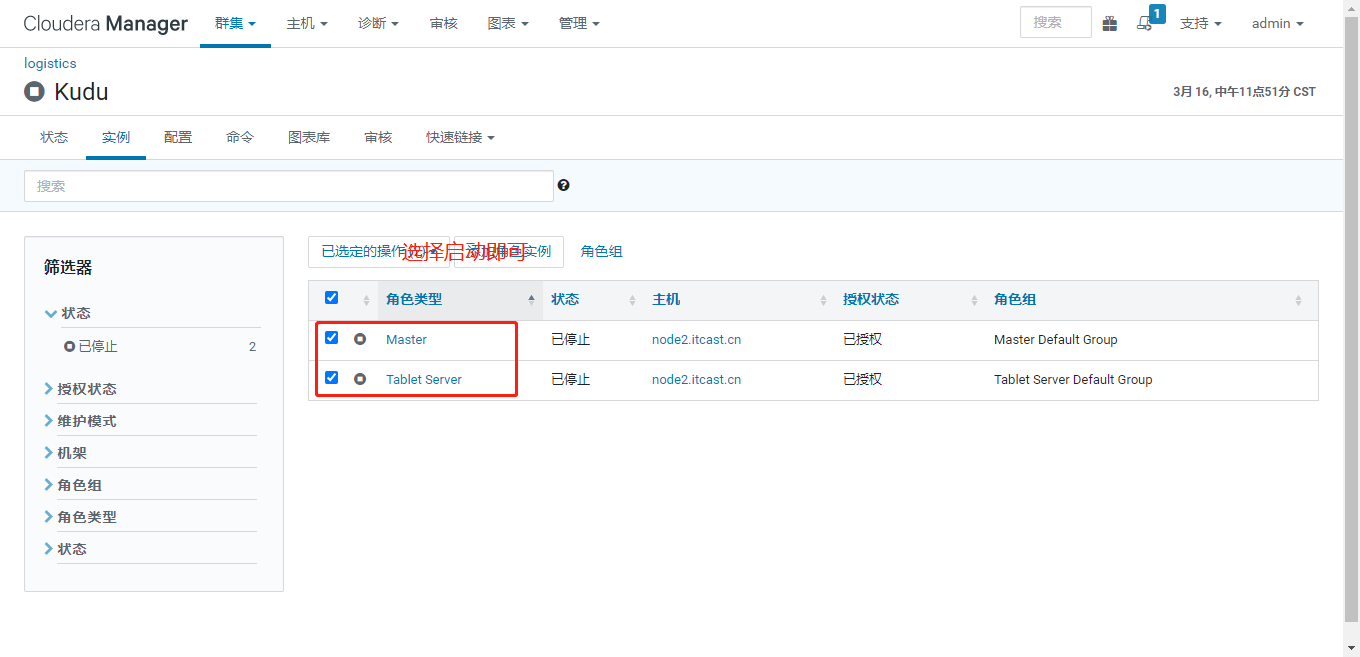
1)、登录CM管理界面,启动Kudu 服务组件即可
- http://node2.itcast.cn:7180/cmf
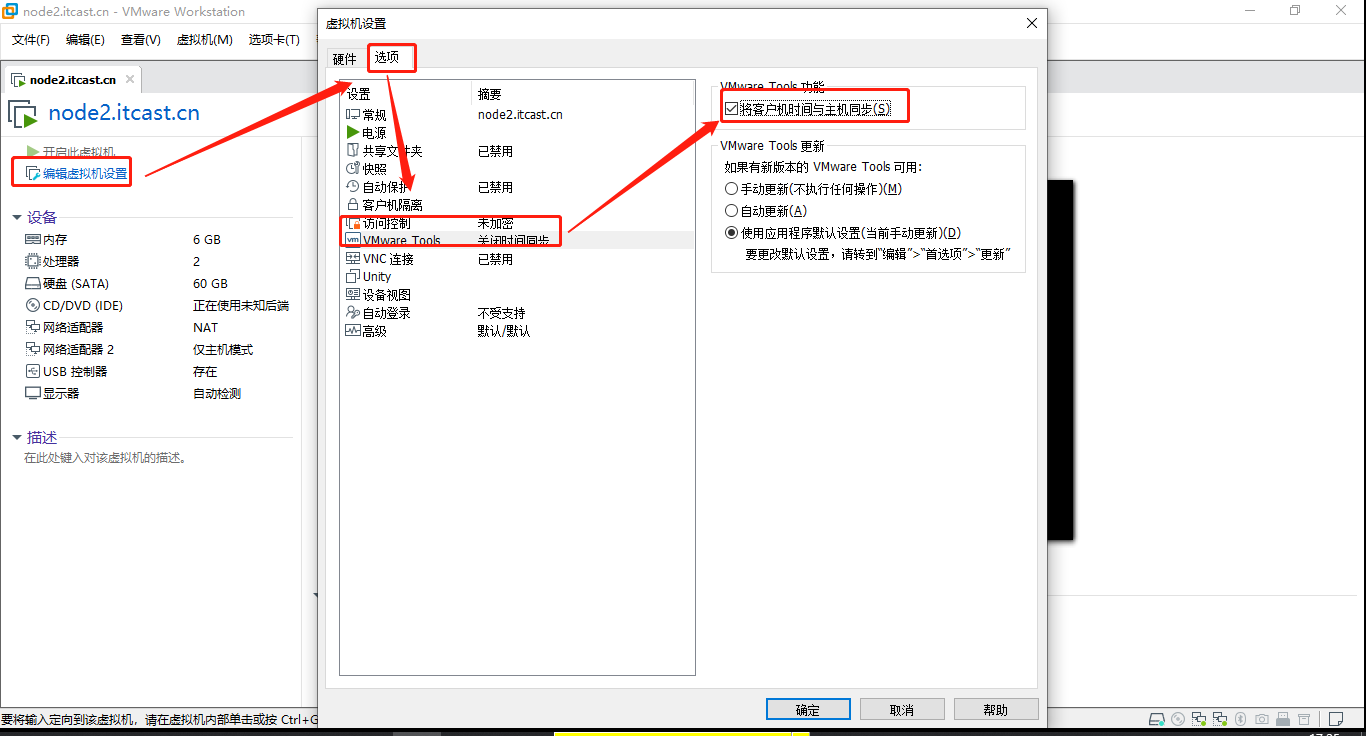
admin/admin- 由于单机版本,伪分布式安装,启动基本上会成功,如果集群的话,Kudu对集群机器时间同步要求很高,使用
ntp进行同步时间。最好配置,虚拟机与宿主机时间同步
- 记住,设置虚拟机与网络时间同步,虚拟机必须联网。
[root@node2 ~]# ntpdate ntp1.aliyun.com
- 2)、Kudu Master提供Web UI界面:http://node2.itcast.cn:8051/
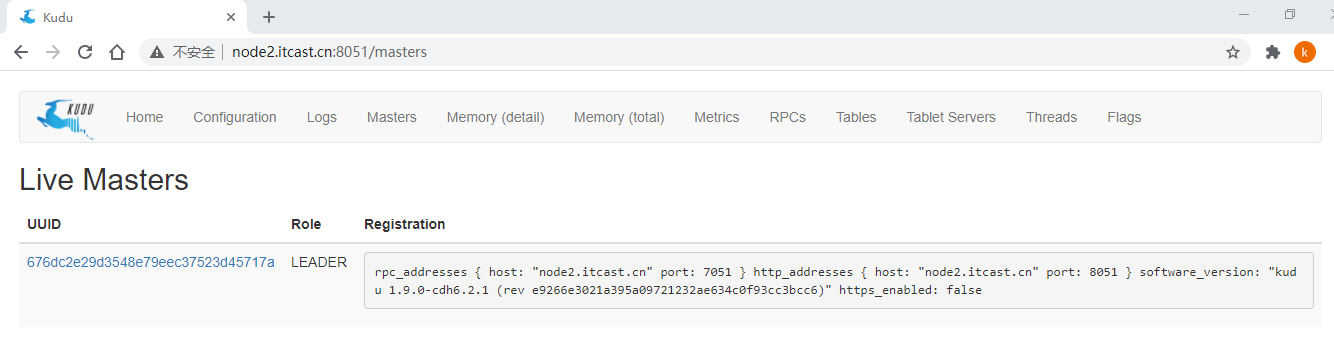
- 3)、Kudu配置文件:
/etc/kudu/conf
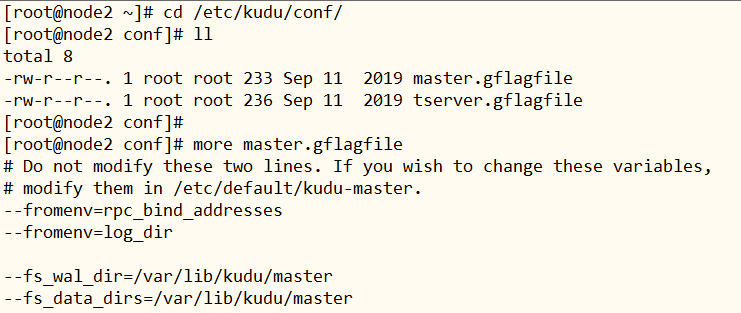
- 4)、Kudu 存储数据目录:
/var/lib/kudu/master,/var/lib/kudu/tserver- 5)、Kudu 日志存储:
/var/log/kudu/
[root@node2 ~]# ps -ef|grep kudu
kudu 2878 2865 1 11:53 ? 00:00:06 /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/kudu/sbin/kudu-master --location_mapping_cmd=/var/run/cloudera-scm-agent/process/6-kudu-KUDU_MASTER/topology.py --flagfile=/var/run/cloudera-scm-agent/process/6-kudu-KUDU_MASTER/gflagfile
kudu 2879 2865 0 11:53 ? 00:00:00 /usr/bin/python2 /opt/cloudera/cm-agent/bin/cm redactor --fds 3 5
kudu 2890 2864 6 11:53 ? 00:00:26 /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/kudu/sbin/kudu-tserver --tserver_master_addrs=node2.itcast.cn --flagfile=/var/run/cloudera-scm-agent/process/5-kudu-KUDU_TSERVER/gflagfile
kudu 2891 2864 0 11:53 ? 00:00:00 /usr/bin/python2 /opt/cloudera/cm-agent/bin/cm redactor --fds 3 5
Kudu Master还是Kudu TabletServer都有很多配置属性,可以进行配置:https://kudu.apache.org/docs/configuration.html
11-[掌握]-Kudu 使用方式及KuduPlus 工具
Kudu提供三种方式,操作Kudu数据库,进行DDL操作和DML操作:
- 1)、方式一:可通过
Java client、C++ client、Python client操作Kudu表,要构建Client并编写应用程序;- https://kudu.apache.org/docs/developing.html#developing-applications-with-apache-kudu
- 2)、方式二:可通过Impala的shell对Kudu表进行交互式的操作,因为Impala2.8及以上的版本已经集成了对Kudu的操作。
- 直接定义Impala表数据存储在Kudu中,内部集成
- 3)、方式三:通过
Kudu-Spark包集成Kudu与Spark,并编写Spark应用程序来操作Kudu表- KuduContext,类似SparkContext,进行DDL操作和DML操作
- SparkSession操作Kudu表数据,CRUD操作
无论是Java Client API使用,还是Kudu集成Spark使用,添加Maven 依赖:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
sion操作Kudu表数据,CRUD操作
无论是Java Client API使用,还是Kudu集成Spark使用,添加Maven 依赖:
[外链图片转存中…(img-G0gKlTk3-1715448238762)]
[外链图片转存中…(img-gWYSlwxK-1715448238763)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3909
3909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









