








数据清洗
首先通过debug 找到分割后各个字段的对应的

- 报错
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
执行第一步数据清洗时候,数据能打印出来,但是不能写入本地文件,这是因为本地没有hadoop伪分布式系统
装一个插件即可
https://hiszm.lanzous.com/iWyqmhrgk0f
下载上述插件,然后,新建目录并且放入到目录里面
C:\Data\hadoop\bin
然后再系统环境变量添加
HADOOP_HOME
C:\Data\hadoop
package org.sparksql
import org.apache.spark.sql.SparkSession
object SparkFormatApp {
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.master("local[2]").getOrCreate()
val access = spark.sparkContext.textFile("10000\_access.log")
//access.take(10).foreach(println)
access.map(line=>{
val splits = line.split(" ")
val ip = splits(0)
val time = splits(3) + " " + splits(4)
val traffic = splits(9)
val url = splits(11).replace("\"","")
//(ip,DateUtils.parse(time),traffic,traffic,url)
DateUtils.parse(time) + "\t" + url + "\t" + traffic + "\t" + ip
}).saveAsTextFile("output")
//.take(10).foreach(println)
//.saveAsTextFile("output")
spark.stop()
}
}
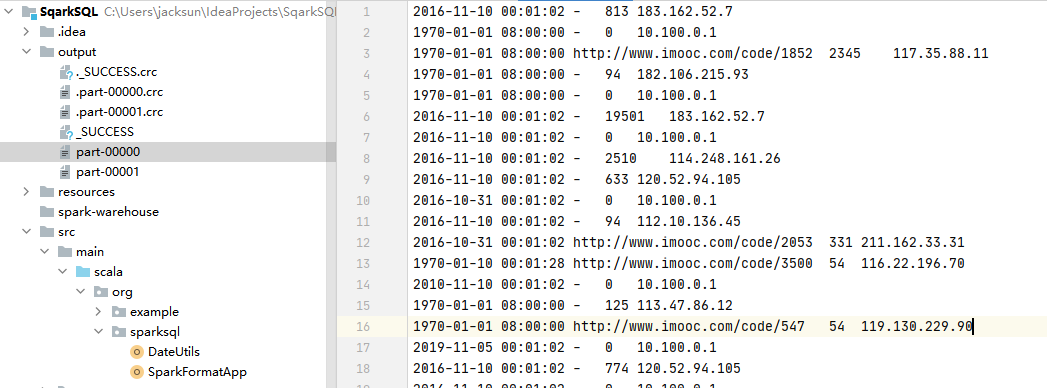
一般的日志处理方式,我们是需要进行分区的,
按照日志中的访问时间进行相应的分区,比如:d,h,m5(每5分钟一个分区)
二次清洗
- 输入:
访问时间、访问URL、耗费的流量、访问IP地址信息 - 输出:
URL、cmsType(video/article)、cmsId(编号)、流量、ip、城市信息、访问时间、天
package org.sparksql
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
//访问日志工具转换类
object AccessConvertUtils {
val struct=StructType(
Array(
StructField("url",StringType),
StructField("cmsType",StringType),
StructField("cmsId",LongType),
StructField("traffic",LongType),
StructField("ip",StringType),
StructField("city",StringType),
StructField("time",StringType),
StructField("day",StringType)
)
)
//根据输入的每一行信息转化成输出的样式
def parseLog(log:String)={
try{
val splits=log.split("\t")
val url =splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain="http://www.imooc.com/"
val cms=url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1){
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
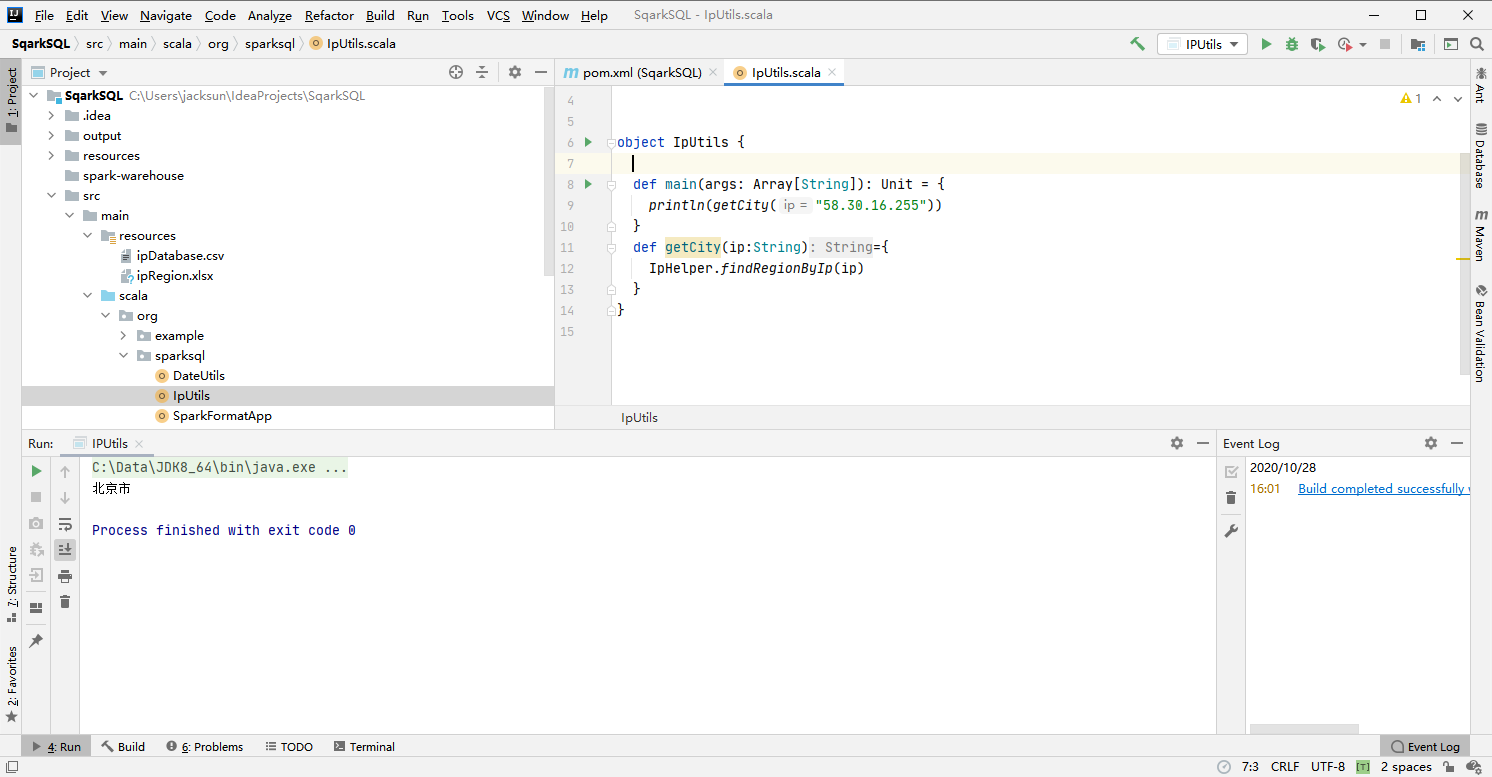
val city = IpUtils.getCity(ip)
val time = splits(0)
val day = time.substring(0,10).replaceAll("-","")
Row(url,cmsType,cmsId,traffic,ip,city,time,day)
}catch {
case e : Exception => Row(0)
}
}
}
- IP=>省份
使用github上已有的开源项目
1)git clone https://github.com/wzhe06/ipdatabase.git
2)编译下载的项目:mvn clean package -DskipTests

3)安装jar包到自己的maven仓库
mvn install:install-file -Dfile=C:\Data\ipdatabase\target\ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar

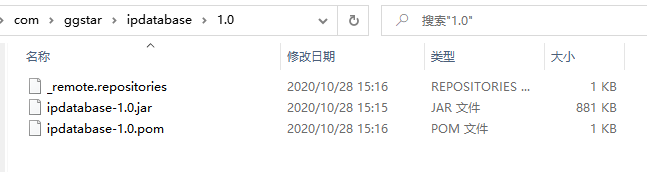
- 拷贝相关文件不然会报错
java.io.FileNotFoundException: file:/Users/rocky/maven_repos/com/ggstar/ipdatabase/1.0/ipdatabase-1.0.jar!/ipRegion.xlsx (No such file or directory)
- 测试
package org.sparksql
import org.apache.spark.sql.SparkSession
object SparkCleanApp {
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("access.log")
//accessRDD.take(10).foreach(println)
val accessDF = spark.createDataFrame(accessRDD.map(x=>AccessConvertUtils.parseLog(x)),AccessConvertUtils.struct)
accessDF.printSchema()
accessDF.show()
spark.stop
}
}
root
|-- url: string (nullable = true)
|-- cmsType: string (nullable = true)
|-- cmsId: long (nullable = true)
|-- traffic: long (nullable = true)
|-- ip: string (nullable = true)
|-- city: string (nullable = true)
|-- time: string (nullable = true)
|-- day: string (nullable = true)
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
| url|cmsType|cmsId|traffic| ip|city| time| day|
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
|http://www.imooc....| video| 4500| 304| 218.75.35.226| 浙江省|2017-05-11 14:09:14|20170511|
|http://www.imooc....| video|14623| 69| 202.96.134.133| 广东省|2017-05-11 15:25:05|20170511|
|http://www.imooc....|article|17894| 115| 202.96.134.133| 广东省|2017-05-11 07:50:01|20170511|
|http://www.imooc....|article|17896| 804| 218.75.35.226| 浙江省|2017-05-11 02:46:43|20170511|
|http://www.imooc....|article|17893| 893|222.129.235.182| 北京市|2017-05-11 09:30:25|20170511|
|http://www.imooc....|article|17891| 407| 218.75.35.226| 浙江省|2017-05-11 08:07:35|20170511|
|http://www.imooc....|article|17897| 78| 202.96.134.133| 广东省|2017-05-11 19:08:13|20170511|
|http://www.imooc....|article|17894| 658|222.129.235.182| 北京市|2017-05-11 04:18:47|20170511|
|http://www.imooc....|article|17893| 161| 58.32.19.255| 上海市|2017-05-11 01:25:21|20170511|
|http://www.imooc....|article|17895| 701| 218.22.9.56| 安徽省|2017-05-11 13:37:22|20170511|
|http://www.imooc....|article|17892| 986| 218.75.35.226| 浙江省|2017-05-11 05:53:47|20170511|
|http://www.imooc....| video|14540| 987| 58.32.19.255| 上海市|2017-05-11 18:44:56|20170511|
|http://www.imooc....|article|17892| 610| 218.75.35.226| 浙江省|2017-05-11 17:48:51|20170511|
|http://www.imooc....|article|17893| 0| 218.22.9.56| 安徽省|2017-05-11 16:20:03|20170511|
|http://www.imooc....|article|17891| 262| 58.32.19.255| 上海市|2017-05-11 00:38:01|20170511|
|http://www.imooc....| video| 4600| 465| 218.75.35.226| 浙江省|2017-05-11 17:38:16|20170511|
|http://www.imooc....| video| 4600| 833|222.129.235.182| 北京市|2017-05-11 07:11:36|20170511|
|http://www.imooc....|article|17895| 320|222.129.235.182| 北京市|2017-05-11 19:25:04|20170511|
|http://www.imooc....|article|17898| 460| 202.96.134.133| 广东省|2017-05-11 15:14:28|20170511|
|http://www.imooc....|article|17899| 389|222.129.235.182| 北京市|2017-05-11 02:43:15|20170511|
+--------------------+-------+-----+-------+---------------+----+-------------------+--------+
调优点:
- 控制文件输出的大小: coalesce
- 分区字段的数据类型调整:spark.sql.sources.partitionColumnTypeInference.enabled
- 批量插入数据库数据,提交使用batch操作
package org.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object TopNApp {
//最受欢迎
def videoAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val videoTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
videoTopNDF.show()
accessDF.createOrReplaceTempView("access\_log")
val videoTopNDF1 = spark.sql("select day,cmsId,count(1) as times from access\_log where day='20170511' and cmsType = 'video' group by day,cmsId order by times desc")
videoTopNDF1.show()
}
def main(args: Array[String]): Unit = {
//SparkSession是spark的入口类
val spark = SparkSession.builder().appName("SparkFormatApp")
.config("spark.sql.sources.partitionColumnTypeInference.enabled","false")
.master("local[2]").getOrCreate()
val accessDF= spark.read.format("parquet").load("output2/")
accessDF.printSchema()
accessDF.show(false)
videoAccessTopN(spark,accessDF)
spark.stop()
}
}
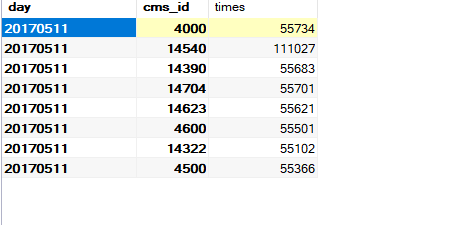
+--------+-----+------+
| day|cmsId| times|
+--------+-----+------+
|20170511|14540|111027|
|20170511| 4000| 55734|
|20170511|14704| 55701|
|20170511|14390| 55683|
|20170511|14623| 55621|
|20170511| 4600| 55501|
|20170511| 4500| 55366|
|20170511|14322| 55102|
+--------+-----+------+
视频访问
package org.sparksql
import java.sql.{Connection, DriverManager, PreparedStatement}
object MySqlUtils {
def getConnection() ={
// if (!conn.isClosed) System.out.println("已连接上数据库!")
// else System.out.println("没有连接到数据库!")
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc\_user?user=root&password=root")
}
//释放数据库连接资源
def release(connection:Connection,pstmt:PreparedStatement): Unit ={
try{
if(pstmt != null){
pstmt.close()
}
}catch{
case e:Exception => e.printStackTrace()
}finally {
if(connection!=null){
connection.close()
}
}
}
def main(args: Array[String]): Unit = {
println(getConnection())
}
}
create table day_video_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
times bigint(10) not null,
primary key (day, cms_id)
);
package org.sparksql
import java.sql.{Connection, PreparedStatement}
import scala.collection.mutable.ListBuffer
object StatisticsDAO {
def insertDayVideoAccessTopN(list:ListBuffer[DayVideoAccessStatistics]): Unit ={
var connection:Connection = null
var pstmt:PreparedStatement = null
try{
connection= MySqlUtils.getConnection()
//取消自动提交
connection.setAutoCommit(false)
val sql = "insert into day\_video\_access\_topn\_stat(day,cms\_id,times) value (? ,? ,? )"
pstmt = connection.prepareStatement(sql)
for(i<-list){
pstmt.setString(1,i.day)
pstmt.setLong(2,i.cmsId)
pstmt.setLong(3,i.times)
pstmt.addBatch()
}
pstmt.executeBatch()//批量处理
//手动提交
connection.commit()
}catch {
case e:Exception=>e.printStackTrace()
}finally {
MySqlUtils.release(connection,pstmt)
}
}
}
package org.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import scala.collection.mutable.ListBuffer
object TopNApp {
//最受欢迎
def videoAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val videoTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
videoTopNDF.show()
try{
videoTopNDF.foreachPartition(partitionOfRecords =>{
val list = new ListBuffer[DayVideoAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val times = info.getAs[Long]("times")
list.append(DayVideoAccessStatistics(day,cmsId,times))
})
StatisticsDAO.insertDayVideoAccessTopN(list)
})
}catch {
case e:Exception =>e.printStackTrace()
}
}
java.sql.SQLException: No value specified for parameter 2
检查插入参数和类型是否一直
按照省份
create table day_video_city_access_topn_stat (
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day, cms_id, city)
);
def cityAccessTopN(spark: SparkSession, accessDF: DataFrame) = {
import spark.implicits._
val cityTopNDF = accessDF.filter($"day"==="20170511"&& $"cmsType" === "video")
.groupBy("day","city","cmsId").agg(count("cmsId")
.as("times")).orderBy($"times".desc)
cityTopNDF.show()
val top3DF = cityTopNDF.select(
cityTopNDF("day"),
cityTopNDF("city"),
cityTopNDF("cmsId"),
cityTopNDF("times"),
row_number().over(Window.partitionBy(cityTopNDF("city"))
.orderBy(cityTopNDF("times").desc)).as("times\_rank")
).filter("times\_rank <=3")//.show()
try{
top3DF.foreachPartition(partitionOfRecords =>{
val list = new ListBuffer[DayCityAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
Buffer[DayCityAccessStatistics]
partitionOfRecords.foreach(info =>{
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
[外链图片转存中...(img-9oI5rpm9-1714300063613)]
[外链图片转存中...(img-pWjyrGW9-1714300063614)]
[外链图片转存中...(img-i3DsNlz7-1714300063614)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**














 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









