







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
关于 sql 语句的执行顺序网上有很多资料,但是大多都没进行验证,并且很多都有点小错误,尤其是对于 select 和 group by 执行的先后顺序,有说 select 先执行,有说 group by 先执行,到底它俩谁先执行呢?
今天我们通过 explain 来验证下 sql 的执行顺序。
在验证之前,先说结论,Hive 中 sql 语句的执行顺序如下:
from … where … join … on … select … group by … select … having … distinct … order by … limit … union/union all
可以看到 group by 是在两个 select 之间,我们知道 Hive 是默认开启 map 端的 group by 分组的,所以在 map 端是 select 先执行,在 reduce 端是 group by 先执行。
下面我们通过一个 sql 语句分析下:
select
sum(b.order_amount) sum_amount,
count(a.userkey) count_user
from user_info a
left join user_order b
on a.idno=b.idno
where a.idno > '112233'
group by a.idno
having count_user>1
limit 10;
上面这条 sql 语句是可以成功执行的,我们看下它在 MR 中的执行顺序:
Map 阶段:
- 执行 from,进行表的查找与加载;
- 执行 where,注意:sql 语句中 left join 写在 where 之前的,但是实际执行先执行 where 操作,因为 Hive 会对语句进行优化,如果符合谓词下推规则,将进行谓词下推;
- 执行 left join 操作,按照 key 进行表的关联;
- 执行输出列的操作,注意: select 后面只有两个字段(order_amount,userkey),此时 Hive 是否只输出这两个字段呢,当然不是,因为 group by 的是 idno,如果只输出 select 的两个字段,后面 group by 将没有办法对 idno 进行分组,所以此时输出的字段有三个:idno,order_amount,userkey;
- 执行 map 端的 group by,此时的分组方式采用的是哈希分组,按照 idno 分组,进行 order_amount 的 sum 操作和 userkey 的 count 操作,最后按照 idno 进行排序(group by 默认会附带排序操作);
Reduce 阶段:
6.执行 reduce 端的 group by,此时的分组方式采用的是合并分组,对 map 端发来的数据按照 idno 进行分组合并,同时进行聚合操作 sum(order_amount)和 count(userkey);
7.执行 select,此时输出的就只有 select 的两个字段:sum(order_amount) as sum_amount,count(userkey) as count_user;
8.执行 having,此时才开始执行 group by 后的 having 操作,对 count_user 进行过滤,注意:因为上一步输出的只有 select 的两个字段了,所以 having 的过滤字段只能是这两个字段;
9.执行 limit,限制输出的行数为 10。
上面这个执行顺序到底对不对呢,我们可以通过 explain 执行计划来看下,内容过多,我们分阶段来看。
1.首先看下 sql 语句的执行依赖:

我们看到 Stage-5 是根,也就是最先执行 Stage-5,Stage-2 依赖 Stage-5,Stage-0 依赖 Stage-2。
2.首先执行 Stage-5:
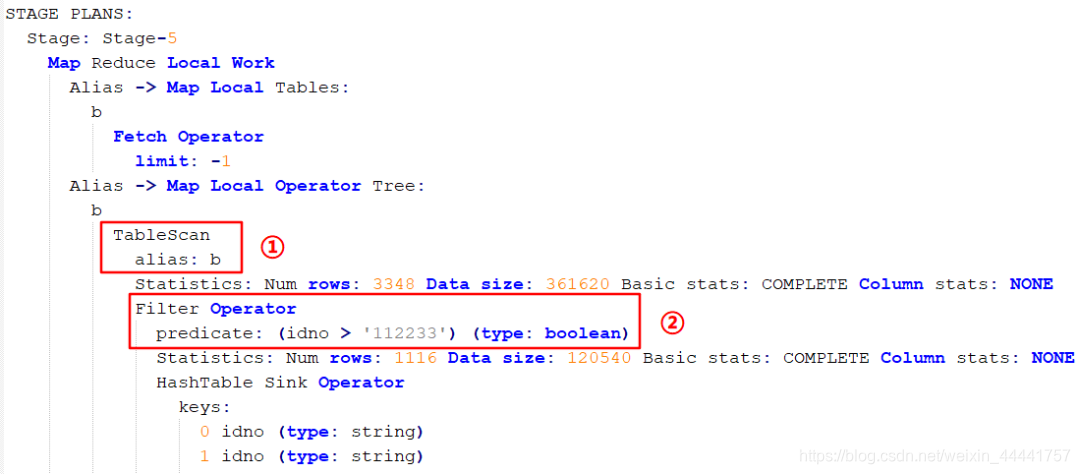
图中标 ① 处是表扫描操作,注意先扫描的 b 表,也就是 left join 后面的表,然后进行过滤操作(图中标 ② 处),我们 sql 语句中是对 a 表进行的过滤,但是 Hive 也会自动对 b 表进行相同的过滤操作,这样可以减少关联的数据量。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3297586659)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3388
3388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









