✒️个人主页:小鹏linux
💊个人社区:小鹏linux(个人社区)欢迎您的加入!

目录
1. 关于Spark
1.1 Spark简介
1.2 Spark特点
1.3 Spark集群架构
2. 在Docker中运行Spark
2.1 使用官方镜像
2.2 验证
2.3 容器外访问Spark
👑👑👑结束语👑👑👑
1. 关于Spark
1.1 Spark简介
|
|---|
|
| Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,基于Scala开发。最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一。 |
与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark支持更灵活的函数定义,可以将应用处理速度提升一到两个数量级,并且提供了众多方便的实用工具,包括SQL查询、流处理、机器学习和图处理等:
|
|
|---|
|
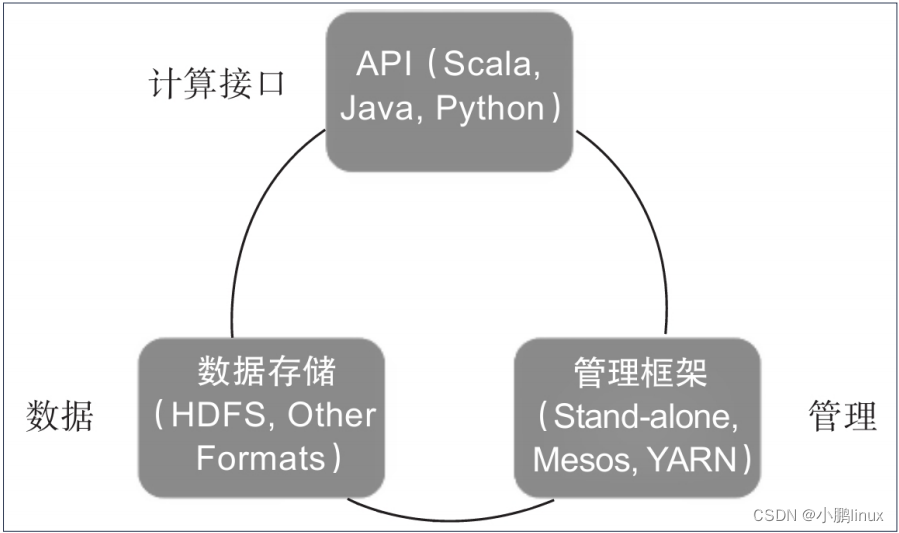
| Spark体系架构包括如下三个主要组件:数据存储、API、管理框架,如图所示。 |
|
1.2 Spark特点
|
|---|
| Apache Spark 具有以下特点: 使用先进的 DAG 调度程序,查询优化器和物理执行引擎,以实现性能上的保证; 多语言支持,目前支持的有 Java,Scala,Python 和 R; 提供了 80 多个高级 API,可以轻松地构建应用程序; 支持批处理,流处理和复杂的业务分析; 丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合; 丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行; 多数据源支持:支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。 |
1.3 Spark集群架构
| |
|---|
| Term(术语) | Meaning(含义) |
| Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
| Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
| Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
| Worker node | 执行计算任务的工作节点 |
| Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
| Task | 被发送到 Executor 中的工作单元 |
|
|---|
| 执行过程: 用户程序创建 SparkContext 后,它会连接到集群资源管理器,集群资源管理器会为用户程序分配计算资源,并启动 Executor; Driver 将计算程序划分为不同的执行阶段和多个 Task,之后将 Task 发送给 Executor; Executor 负责执行 Task,并将执行状态汇报给 Driver,同时也会将当前节点资源的使用情况汇报给集群资源管理器。 |
|
|---|
|
| 目前Spark推出了2.0版本,性能大幅度提升,并在数据流方面退推出了很多新功能。 |
|
2. 在Docker中运行Spark
2.1 使用官方镜像
|
|---|
|
| 用户可以使用sequenceiq/spark镜像,版本方面支持Hadoop 2.6.0,Apache Spark v1.6.0(CentOS)。同时此镜像还包含Dockerfile,用户可以基于它构建自定义的Apache Spark镜像。 |
|
$ docker pull sequenceiq/spark:1.6.0
1.6.0: Pulling from sequenceiq/spark
...
9d406b080497: Pull complete
Digest: sha256:64fbdd1a9ffb6076362359c3895d089afc65a533c0ef021ad4ae6da3f8b2a413
Status: Downloaded newer image for sequenceiq/spark:1.6.0
|
|---|
| 也可以使用docker build指令构建spark镜像: |
$ docker build --rm -t sequenceiq/spark:1.6.0 .
|
|---|
| 另外,用户在运行容器时,需要映射YARN UI需要的端口: |
$ docker run -it -p 8088:8088 -p 8042:8042 -h sandbox sequenceiq/spark:1.6.0 bash
bash-4.1#
|
|---|
| 启动后,可以使用bash命令行来查看namenode日志等信息: |
bash-4.1# cat /usr/local/hadoop/logs/hadoop-root-namenode-sandbox.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7758
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1048576
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) unlimited
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**






















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









