







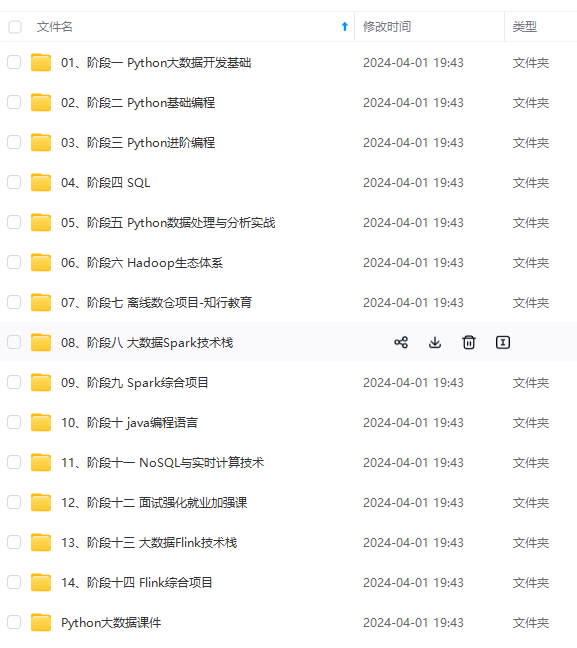
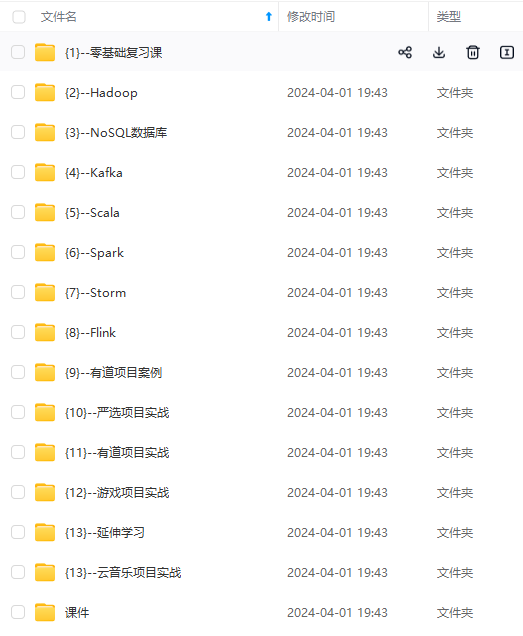
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
切换到hadoop用户写脚本
vim xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e KaTeX parse error: Expected 'EOF', got '#' at position 23: … then #̲5. 获取父目录 …(cd -P $(dirname KaTeX parse error: Expected 'EOF', got '#' at position 19: …e); pwd) #̲6. 获取当前文件的名称 …(basename $file)
ssh $host “mkdir -p $pdir”
rsync -av
p
d
i
r
/
pdir/
pdir/fname
h
o
s
t
:
host:
host:pdir
else
echo $file does not exists!
fi
done
done
请注意

这三个为自己的主机
给文件权限
chmod 777 xsync
分发内容
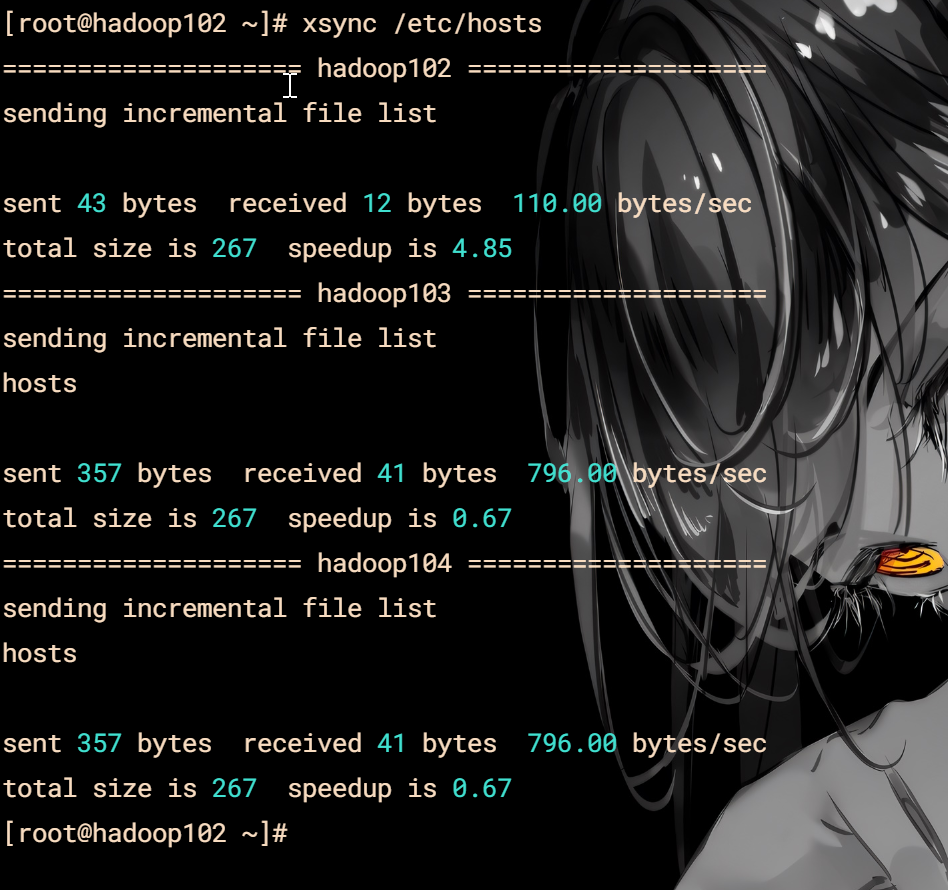
xsync /etc/hosts
### SSH互联
接下来就是互联按照往常的安装来说
分别是 root 和 hadoop 用户需要进行互联
这个软件有个好处就是可以批量操作

开始互联吧!
ssh-keygen -trsa -b 4096
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
**root 和 hadoop 用户都要操作一遍**
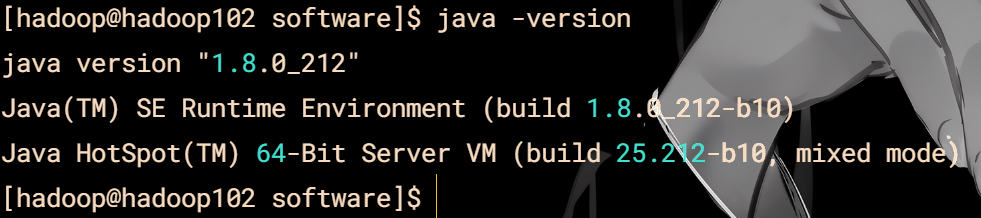
### jdk1.8
后续的安装都推荐使用hadoop用户且用hadoop102进行操作
先用root给hadoop权限
chown -R hadoop:hadoop /opt
上传目录
mkdir /opt/software
安装目录
mkdir /opt/module
#### 上传jdk,hadoop,zookeeper,kafka,flume
耐心等一会
现在上传完成开始进行jdk安装
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
修改名字(默认都在module操作,后续不提示)
mv jdk1.8.0_212/ jdk
环境变量
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
验证
分发
先不着急查看其他两台,profile还没有分发,等hadoop一起
### Hadoop
解压
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module/
改名
mv hadoop-3.3.4/ hadoop
#### 配置
cd hadoop/etc/hadoop/
推荐使用软件自带的编辑器 xedit命令
[core-site.xml](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/Untitled.xml)
[hdfs-site.xml](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/hdfs-site.xml)
[mapred-site.xml](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/mapred-site.xml)
[yarn-site.xml](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/yarn-site.xml)
xedit workers
hadoop102
hadoop103
hadoop104
xedit hadoop-env.sh
export JAVA_HOME=/opt/module/jdk
export HADOOP_HOME=/opt/module/hadoop
export HADOOP_CONF_DIR=
H
A
D
O
O
P
_
H
O
M
E
/
e
t
c
/
h
a
d
o
o
p
e
x
p
o
r
t
H
A
D
O
O
P
_
L
O
G
_
D
I
R
=
HADOOP\_HOME/etc/hadoop export HADOOP\_LOG\_DIR=
HADOOP_HOME/etc/hadoopexportHADOOP_LOG_DIR=HADOOP_HOME/logs
环境变量
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/sbin
分发环境
xsync /etc/proifle
分发hadoop
xsync hadoop/
检查java
检查hadoop

格式化
cd /opt/module/hadoop/
bin/hdfs namenode -format
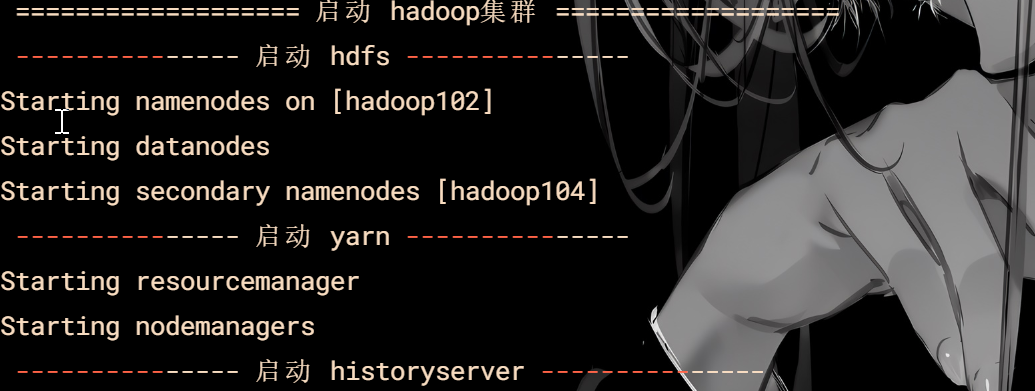
启动脚本
vim hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo “No Args Input…”
exit ;
fi
case $1 in
“start”)
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
“stop”)
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo “Input Args Error…”
;;
esac
给权限
chmod 777 hdp.sh
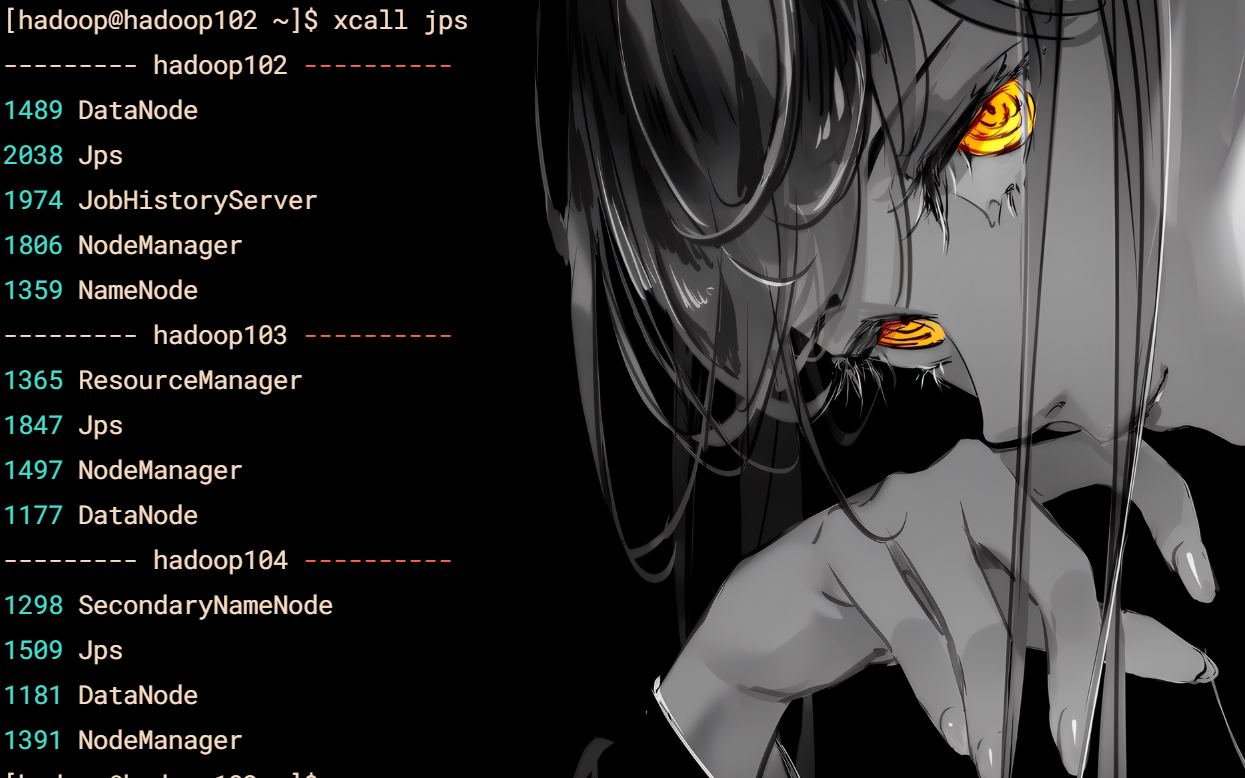
jps查看脚本
vim xcall
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i “/opt/module/jdk/bin/jps $$*”
done
chmod 777
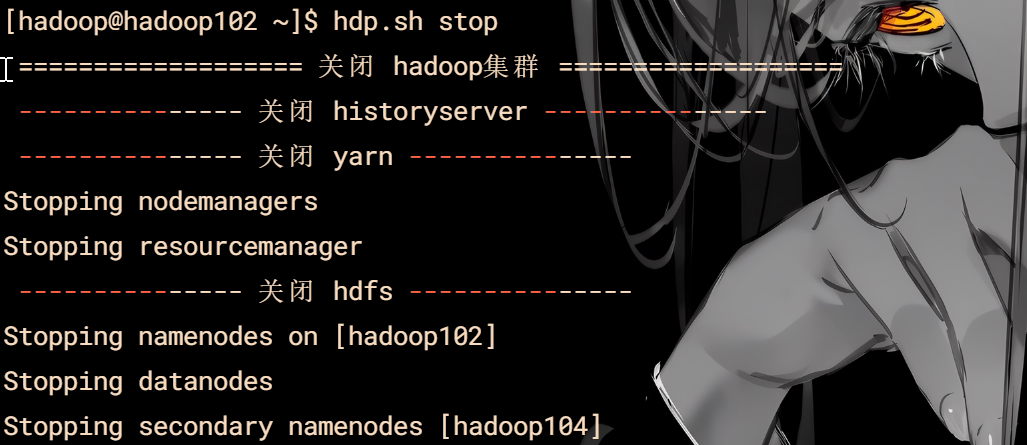
#### 启动与关闭
hdp.sh start
hdp.sh stop
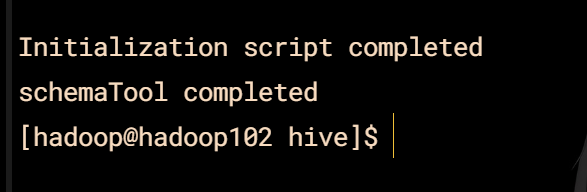
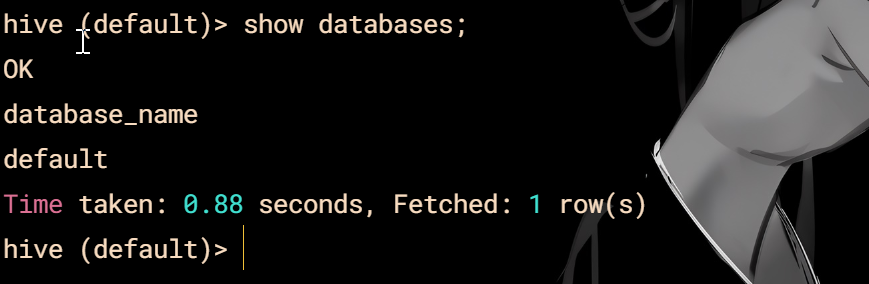
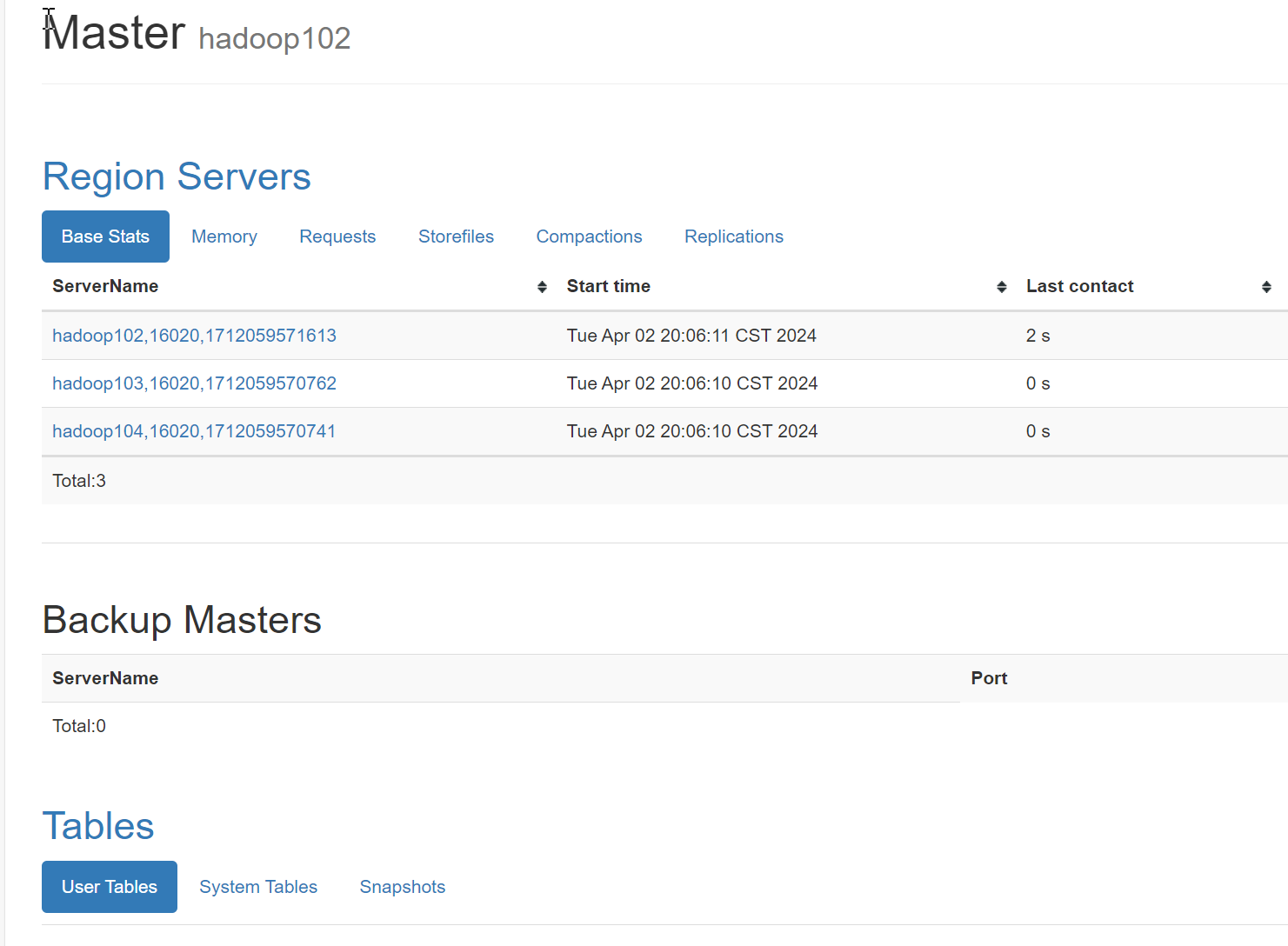
### Zookeeper
解压修改名字
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/
mv apache-zookeeper-3.7.1-bin/ zookeeper
#### 配置
配置服务器编号
cd zookeeper/
mkdir zkData
cd zkData/
vim myid
2
注意编号是2
修改配置文件
cd conf/
mv zoo_sample.cfg zoo.cfg
xedit zoo.cfg
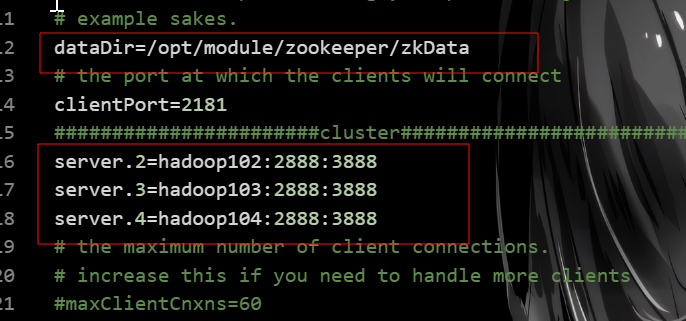
dataDir=/opt/module/zookeeper/zkData
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
[zoo.cfg](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/_opt_module_zookeeper_conf_zoo.cfg)
或者替换配置文件内容
#### 分发
cd /opt/moudle
xsync zookeeper/
修改hadoop103,hadoop104的myid配置
hadoop103 对应3
hadoop104 对应4
#### 脚本
cd /home/hadoop/bin
vim zk.sh
#!/bin/bash
设置JAVA_HOME和更新PATH环境变量
export JAVA_HOME=/opt/module/jdk
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
检查输入参数
if [ $# -ne 1 ]; then
echo “用法: $0 {start|stop|status}”
exit 1
fi
执行操作
case “$1” in
start)
echo “---------- Zookeeper 启动 ------------”
/opt/module/zookeeper/bin/zkServer.sh start
ssh hadoop103 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh start”
ssh hadoop104 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh start”
;;
stop)
echo “---------- Zookeeper 停止 ------------”
/opt/module/zookeeper/bin/zkServer.sh stop
ssh hadoop103 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh stop”
ssh hadoop104 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh stop”
;;
status)
echo “---------- Zookeeper 状态 ------------”
/opt/module/zookeeper/bin/zkServer.sh status
ssh hadoop103 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh status”
ssh hadoop104 “export JAVA_HOME=/opt/module/jdk; export PATH=$PATH:$JAVA_HOME/bin; /opt/module/zookeeper/bin/zkServer.sh status”
;;
*)
echo “未知命令: $1”
echo “用法: $0 {start|stop|status}”
exit 2
;;
esac
### kafka
解压和修改名
tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/module/
mv kafka_2.12-3.3.1/ kafka
#### 配置
xedit server.properties
添加
advertised.listeners=PLAINTEXT://hadoop102:9092
修改
log.dirs=/opt/module/kafka/datas
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
环境变量
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=
P
A
T
H
:
PATH:
PATH:KAFKA_HOME/bin
记得刷新
#### 分发
xsync kafka/
修改hadoop103/104的配置文件
[hadoop@hadoop103 module]$ vim kafka/config/server.properties
修改:
The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop103:9092
[hadoop@hadoop104 module]$ vim kafka/config/server.properties
修改:
The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop104:9092
#### 脚本
请记住kakfa是在zookeeper启动下才能成功启动
vim kf.sh
#!/bin/bash
Kafka和Zookeeper的配置
KAFKA_HOME=/opt/module/kafka
ZOOKEEPER_HOME=/opt/module/zookeeper
JAVA_HOME=/opt/module/jdk
定义启动Kafka的函数
start_kafka() {
echo “Starting Kafka on hadoop102…”
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
echo "Starting Kafka on hadoop104..."
ssh hadoop104 "export JAVA\_HOME=$JAVA\_HOME; export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-start.sh -daemon $KAFKA\_HOME/config/server.properties"
echo "Starting Kafka on hadoop103..."
ssh hadoop103 "export JAVA\_HOME=$JAVA\_HOME; export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-start.sh -daemon $KAFKA\_HOME/config/server.properties"
}
定义停止Kafka的函数
stop_kafka() {
echo “Stopping Kafka on hadoop102…”
$KAFKA_HOME/bin/kafka-server-stop.sh
echo "Stopping Kafka on hadoop104..."
ssh hadoop104 "export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-stop.sh"
echo "Stopping Kafka on hadoop103..."
ssh hadoop103 "export KAFKA\_HOME=$KAFKA\_HOME; $KAFKA\_HOME/bin/kafka-server-stop.sh"
}
定义检查Kafka状态的函数
check_status() {
echo “Checking Kafka status on hadoop102…”
ssh hadoop102 “jps | grep -i kafka”
echo "Checking Kafka status on hadoop104..."
ssh hadoop104 "jps | grep -i kafka"
echo "Checking Kafka status on hadoop103..."
ssh hadoop103 "jps | grep -i kafka"
}
处理命令行参数
case “$1” in
start)
start_kafka
;;
stop)
stop_kafka
;;
status)
check_status
;;
*)
echo “Usage: $0 {start|stop|status}”
exit 1
esac
### Flume
解压和修改名
tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /opt/module/
mv apache-flume-1.10.1-bin/ flume
#### 配置
[log4j2.xml](%E9%98%BF%E9%87%8C%E4%BA%91%E5%AE%89%E8%A3%85Hadoop%E5%9F%BA%E7%A1%80%20b14fbba39fbf42b5b80ca10cd96fa22e/log4j2.xml)
vim log4j2.xml
修改
/opt/module/flume/log
添加
分发
xsync flume/
### MySQL
[MySQL下载地址]( )(推荐)
或者用上面的
解压下载的
上传MySQL和hive
#### 安装MySQL
cd /opt/software/MySQL/
sh install_mysql.sh
root 密码是 000000
#### 检查登录
mysql -root -p000000
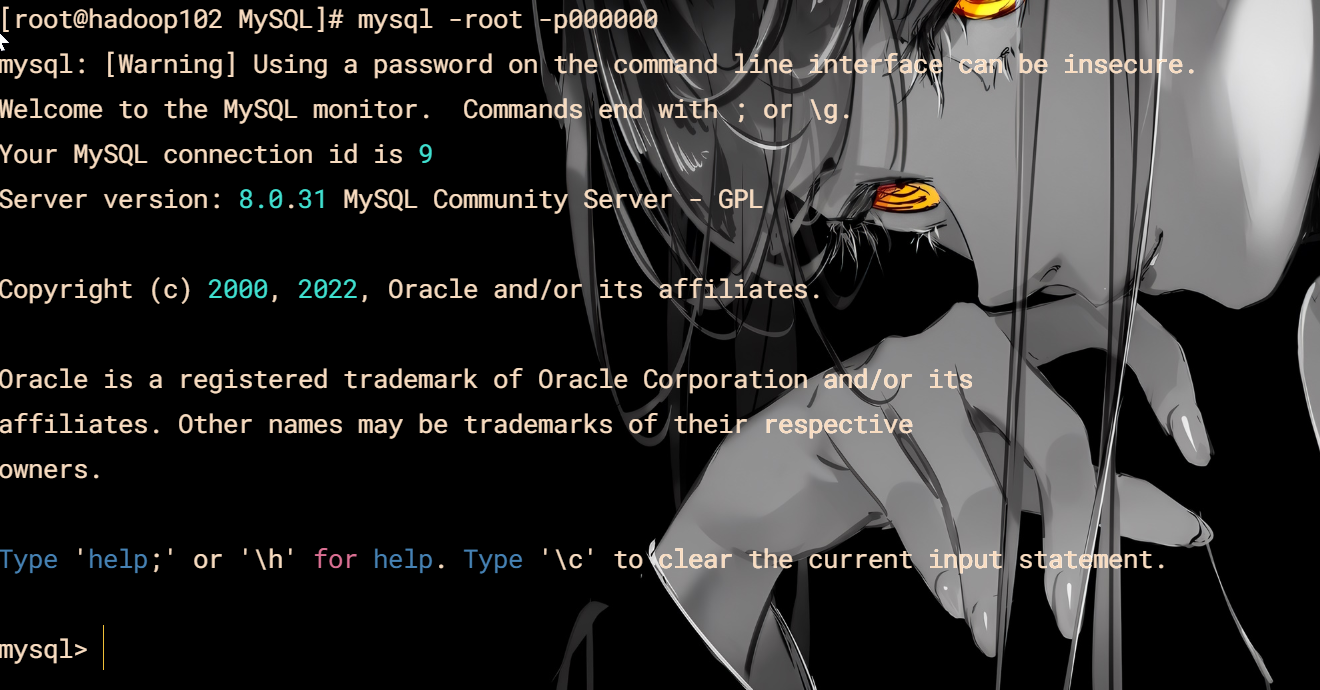
安装成功
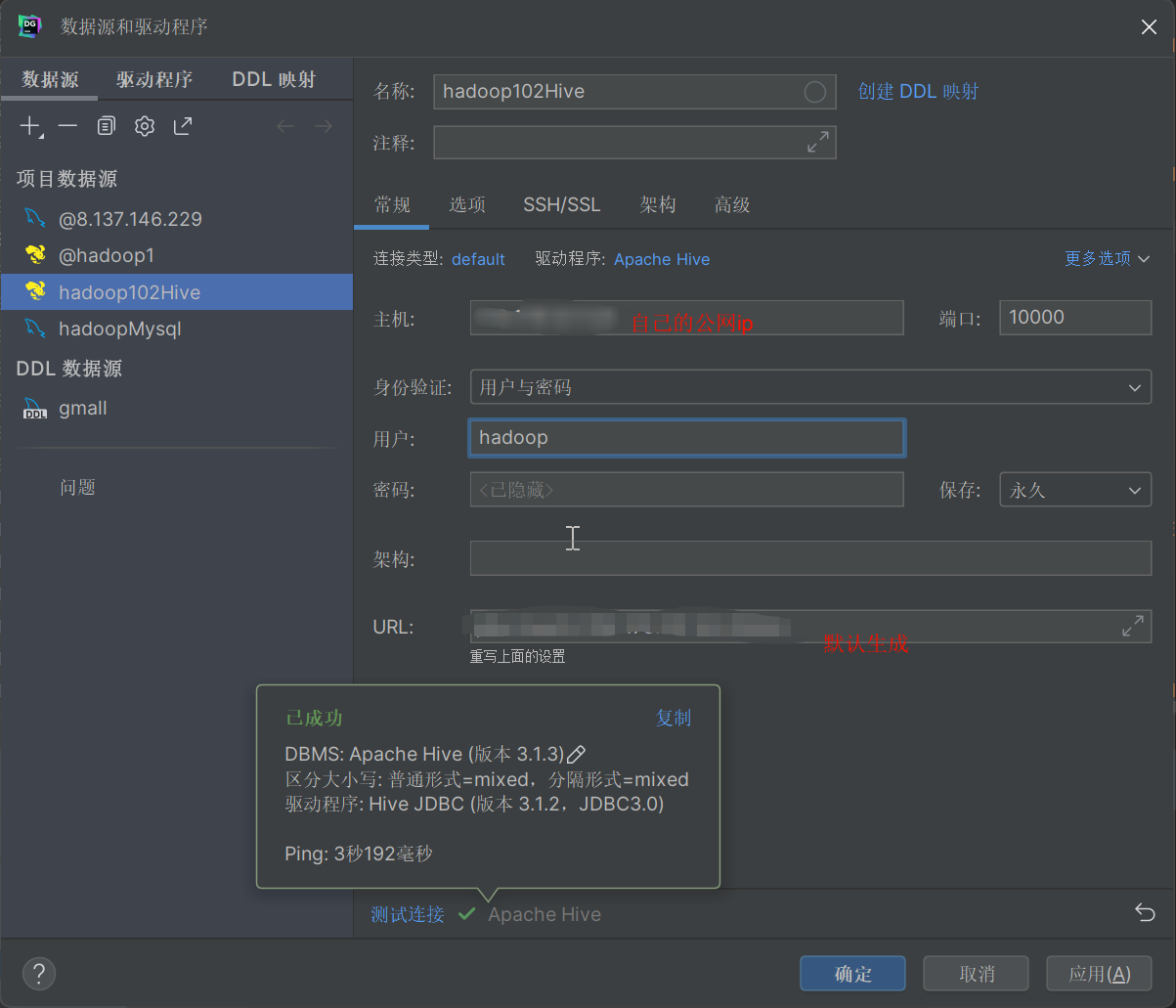
### Hive
解压和修改名
tar -zxvf hive-3.1.3.tar.gz -C /opt/module/
mv apache-hive-3.1.3-bin/ hive
#### 配置
**hive-env.sh**
vim hive-env.sh
export HADOOP_HOME=/opt/module/hadoop
export HIVE_CONF_DIR=/opt/module/hive/conf
export HIVE_AUX_JARS_PATH=/opt/module/hive/lib
**hive-site.xml**
vim hive-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> javax.jdo.option.ConnectionURL jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true<!--配置Hive连接MySQL的驱动全类名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--配置Hive连接MySQL的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--配置Hive连接MySQL的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
[外链图片转存中…(img-NoIGgWfP-1715481842203)]
[外链图片转存中…(img-2UKOozmy-1715481842204)]
[外链图片转存中…(img-cNHjijsi-1715481842204)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 8146
8146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









