








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
| 名称 | 内网IP | CPU | 内存 | 用户名 |
| hadoop102 | 192.168.90.8 | 32核 | 64g | root |
| hadoop103 | 192.168.90.9 | 16核 | 32g | root |
| hadoop104 | 192.168.90.10 | 16核 | 32g | root |
(二)集群安装组件清单
| 服务****名称 | 子****服务 | 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Spark | √ | |||
| Superset | √ | |||
| Datax | √ | |||
| Dolphinscheduler | MasterServer | √ | ||
| WorkServer | √ | √ | √ |
二、运行环境准备(所有节点均需要操作)
1. 配置集群网络,若是虚拟机请参考:【Linux运维】Linux之虚拟机配置网络-CSDN博客
2.安装常用工具包
//更新yum包
yum update -y//安装vim编辑器、网络时间同步工具、工具包、下载工具、服务器与本地电脑传输工具、制作脚本工具、rsync工具包、locate命令包 “红帽系”操作系统的额外安装包
yum install -y vim ntpdate net-tools wget lrzsz git rsync mlocate ntp epel-release//httpd包,并开启服务
yum install -y httpd
//开启服务
service httpd restart
3. 修改主机名称
// 打开配置文件
vim /etc/hostname
// 删除文件中内容,在文件中增加主机别名,比如在01节点为hadoop01,02节点为hadoop02,03节点为hadoop03
4. 关闭防火墙与关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld.service
5. 创建bigdata用户,并修改bigdata用户的密码(此操作是为了降低用户权限,集群操作安全,可选步骤)
useradd bigdata
passwd bigdata
输入bigdata用户的密码
6. 配置bigdata用户具有root权限,方便后期加sudo执行root权限的命令(可选步骤)
修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示
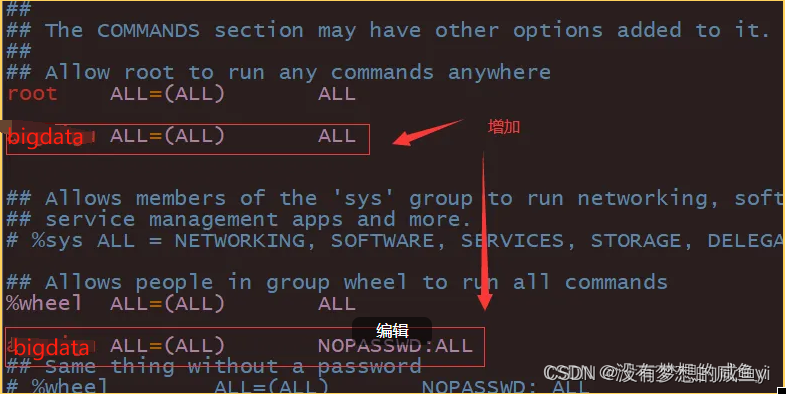
7. 配置集群分发脚本
- 在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行
- 脚本实现 (xsync文件)
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop01 hadoop02 hadoop03
do


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









