







TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
执行命令:
[hadoop@hadoop104 conf]$ vim flink-conf.yaml
修改内容:
TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
## 三、启动关闭集群(Standalone模式)
>
> 在hadoop102节点服务器上执行start-cluster.sh启动Flink集群
>
>
>
启动
[hadoop@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
关闭
[hadoop@hadoop102 flink-1.17.0]$ bin/stop-cluster.sh
## 四、访问WEB-UI
>
> 启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理。
>
>
>
## 五、向集群提交作业(会话模式部署)
### 5.1 WEB-UI方式提交
### 5.2 命令行方式提交
bin/flink run -m hadoop102:8081 -c com.atguigu.flink01.Flink03_WC_Unbound_Socket ./flink-0918-1.0-SNAPSHOT.jar
## 六、Flink集群运行模式
>
> Flink集群的运行模式
>
>
>
### 6.1 Standalone模式
>
> 默认
>
>
>
### 6.2 Flink on Yarn模式
#### 6.2.1 相关准备和配置(配置环境变量并分发)
[hadoop@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#Flink on Yarn
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=hadoop classpath
>
> 其他两台机器同样新增该环境变量
>
>
>
使环境变量生效:
[hadoop@hadoop102 ~]$ mytools_call source /etc/profile
#### 6.2.2 以会话模式在Flink on Yarn集群上部署Flink应用程序
>
> YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群
> -nm(–name):配置在YARN UI界面上显示的任务名。
>
>
>
##### (1)启动关闭Flink集群
启动
[hadoop@hadoop102 flink-1.17.0]$ bin/yarn-session.sh -nm flink-session-cluster01
关闭
[hadoop@hadoop102 ~]$ yarn application -kill application_1700281106461_0453
##### (2)提交作业(WEB-UI方式)
>
> 部署到阿里云的这里IP有点问题,跳转到Flink WEB-UI时是内网IP
>
>
>
##### (3)提交作业(命令行方式)
[hadoop@hadoop102 flink-1.17.0]$ bin/flink run -c com.atguigu.flink01.Flink03_WC_Unbound_Socket ./flink-0918-1.0-SNAPSHOT.jar
#### 6.2.3 以单作业模式在Flink on Yarn集群上部署Flink应用程序
>
> 启动一个Flink集群并提交作业
>
>
>
>
> -d:后台运行
> -t:指定部署模式(单作业模式)
>
>
>
启动
[hadoop@hadoop102 flink-1.17.0]$ bin/flink run -d -t yarn-per-job -c com.atguigu.flink01.Flink03_WC_Unbound_Socket ./flink-0918-1.0-SNAPSHOT.jar
关闭(通过WEB UI页面cancel作业)
#### 6.2.4 以应用模式在Flink on Yarn集群上部署Flink应用程序
##### (1)启动
>
> 应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可
>
>
>
>
> -d:后台运行
> -t:指定部署模式(应用模式)
>
>
>
[hadoop@hadoop102 flink-1.17.0]$ bin/flink run-application -d -t yarn-application -c com.atguigu.flink01.Flink03_WC_Unbound_Socket ./flink-0918-1.0-SNAPSHOT.jar
##### (2)上传Flink的lib和plugins到HDFS上
>
> 将Flink应用程序用到Flink集群中的lib上传到Hadoop集群上。
>
>
>
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-dist
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -put lib/ /flink-dist
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -put plugins/ /flink-dist
##### (3)上传Flink应用程序jar到HDFS上
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-jars
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -put ./flink-0918-1.0-SNAPSHOT.jar /flink-jars
##### (4)提交作业
[hadoop@hadoop102 flink-1.17.0]$ bin/flink run-application -d -t yarn-application -Dyarn.provided.lib.dirs=“hdfs://hadoop102:9820/flink-dist” -c com.atguigu.flink01.Flink03_WC_Unbound_Socket hdfs://hadoop102:9820/flink-jars/flink-0918-1.0-SNAPSHOT.jar
##### 6.2.5 应用模式与单作业模式的区别
>
> 单作业模式:客户端需要执行main方法,将JobGraph提交给YARN上的JobManager。
> 应用模式:应用程序jar的main()方法将在YARN中的JobManager上执行。客户端仅仅是执行命令。
>
>
>
### 6.3 配置Flink历史服务器
#### 6.3.1 创建存储目录
[hadoop@hadoop102 flink-1.17.0]$ hadoop fs -mkdir -p /logs/flink-job
#### 6.3.2 修改配置文件flink-config.yaml
[hadoop@hadoop102 conf]$ vim flink-conf.yaml
新增内容:
>
> 找到historyserver部分(在最后),添加到该位置即可。
>
>
>
jobmanager.archive.fs.dir: hdfs://hadoop102:9820/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:9820/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
#### 6.3.3 启动停止历史服务器
启动
[hadoop@hadoop102 flink-1.17.0]$ bin/historyserver.sh start
停止
[hadoop@hadoop102 flink-1.17.0]$ bin/historyserver.sh stop
#### 6.3.4 重启Yarn(跳过)
>
> 如果历史服务器不生效则需要重启,正常情况不需要。
>
>
>
stop-yarn.sh
start-yarn.sh
#### 6.3.5 访问Flink历史服务器地址
>
> 在yarn的WEB-UI界面,点击任务的History位置,如果Flink历史服务器生效就会跳转到Flink历史服务器UI界面,否则会跳转到Yarn的UI界面。
> 地址:http://hadoop102:8082
>
>
>
## 七、Flink Standalone会话模式的系统架构
### 7.1 基础架构图
>
> 核心组件:客户端、JobManager、TaskManager
>
>
>
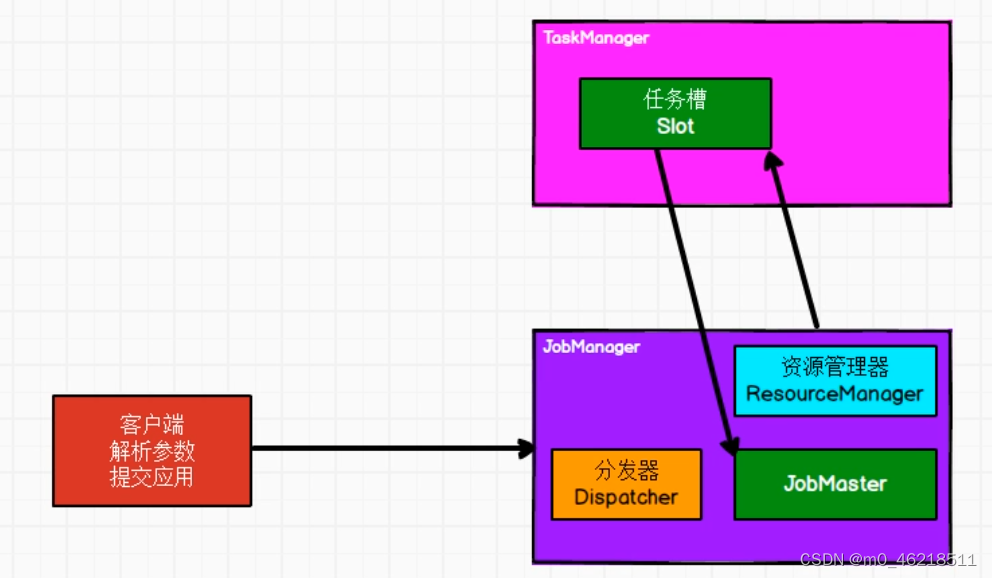
>
> 客户端执行命令,提交应用给Flink集群的JobManager。一个应用中可能有多个作业,分发器Dispatcher将每一个作业封装成一个JobMaster对象,JobMaster将每一个作业的代码执行逻辑生成一个执行图,资源管理器ResourceManager向TaskManager申请资源来执行该作业的执行操作,最终将作业交给TaskManager中的任务槽Slot来执行,作业执行完成后返回给客户端响应。
>
>
>
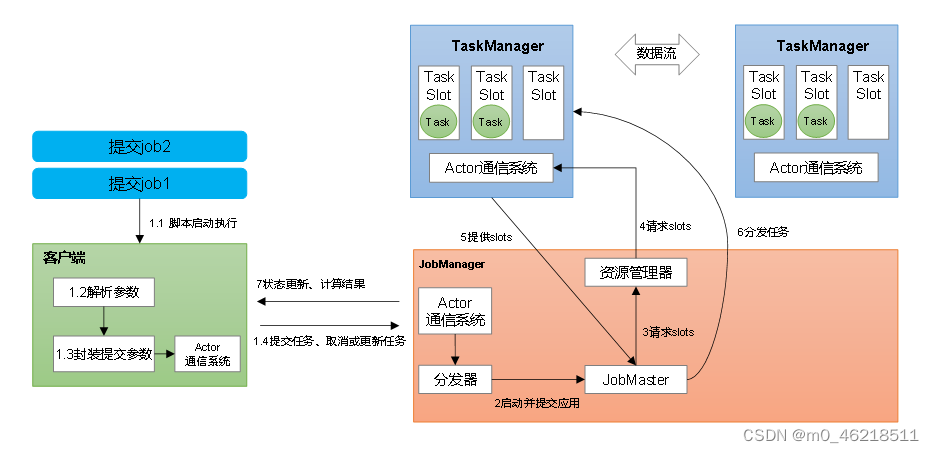
### 7.2 并行度
>
> 算子的子任务个数
> 默认并行度:由flink-conf.yaml配置文件中的parallelism.default指定。
> 根据资源确定如何设置算子的并行度:TaskManager数量(由Flink集群决定),每个TaskManager的Slot数量(由Flink配置文件flink-conf.yaml决定),相乘,就是在该资源下能够处理的最大并行度。
> 根据流程序的算子并行度计算需要多少Slot:最大算子并行度
> 验证流程序需要多少个slot:会话模式部署程序进行验证
>
>
>
#### 7.2.1 指定并行度的三种方式
##### (1)代码中
>
> 算子后跟着调用setParallelism()方法
>
>
>
##### (2)配置文件
>
> flink-conf.yaml配置文件中的parallelism.default
>
>
>
##### (3)提交作业时命令行指定
>
> -p
>
>
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**





**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

从何学起的朋友。**
[外链图片转存中...(img-DFPpA21A-1712889685637)]
[外链图片转存中...(img-86rakAJb-1712889685638)]
[外链图片转存中...(img-j4vwSZ2t-1712889685638)]
[外链图片转存中...(img-Ik4XrFhP-1712889685638)]
[外链图片转存中...(img-Iuur0nCI-1712889685639)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**
[外链图片转存中...(img-HvE2EOxB-1712889685639)]















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









