









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
*/
public class ProvincePartitioner2 extends Partitioner<FlowBean, Text> {
@Override
public int getPartition(FlowBean flowBean, Text text, int i) {
//获取手机号前三位prePhone
String phone = text.toString();
String prePhone = phone.substring(0,3);
//定义一个分区号变量partition, 根据prePhone 设置分区号
int partition;
if("136".equals(prePhone)){
partition = 0;
}else if("137".equals(prePhone)){
partition = 1;
}else if("138".equals(prePhone)){
partition = 2;
}else if("139".equals(prePhone)){
partition = 3;
}else {
partition = 4;
}
//最后返回分区号partition
return partition;
}
}
###### 13.3.7.3.2在驱动类中添加分区类
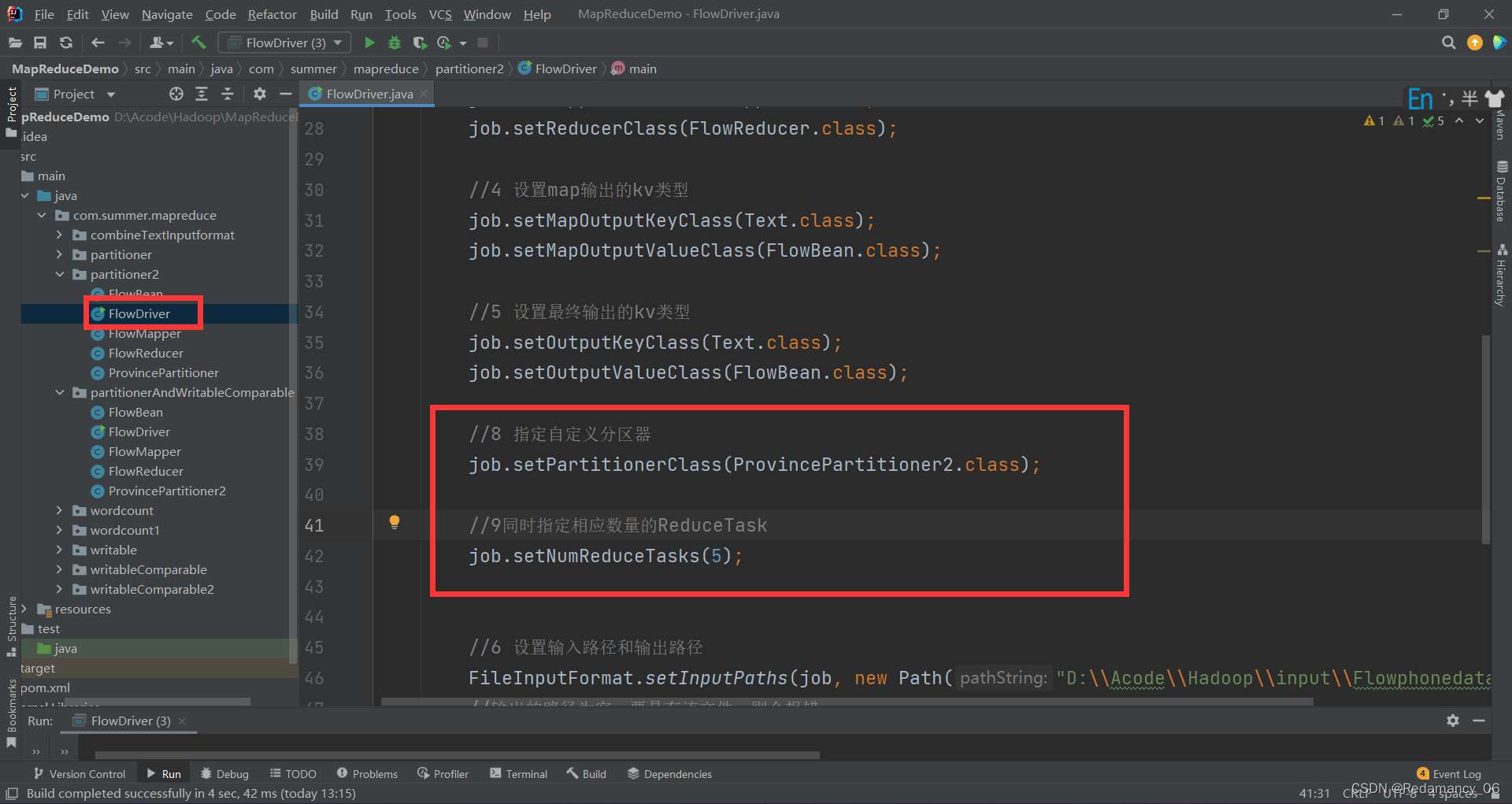在FlowDriver里面添加指定自定义分区器同时指定相应数量的ReduceTask
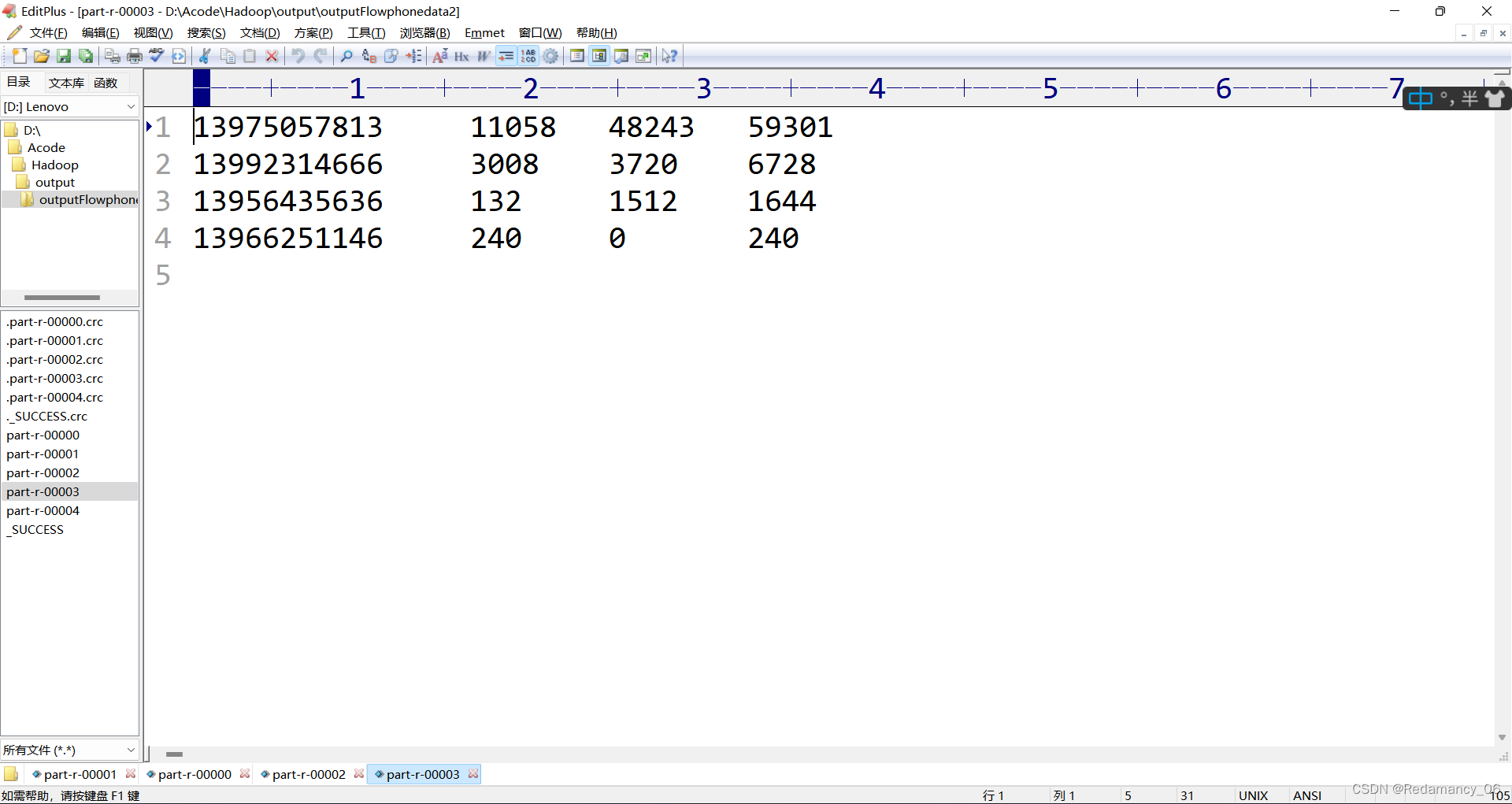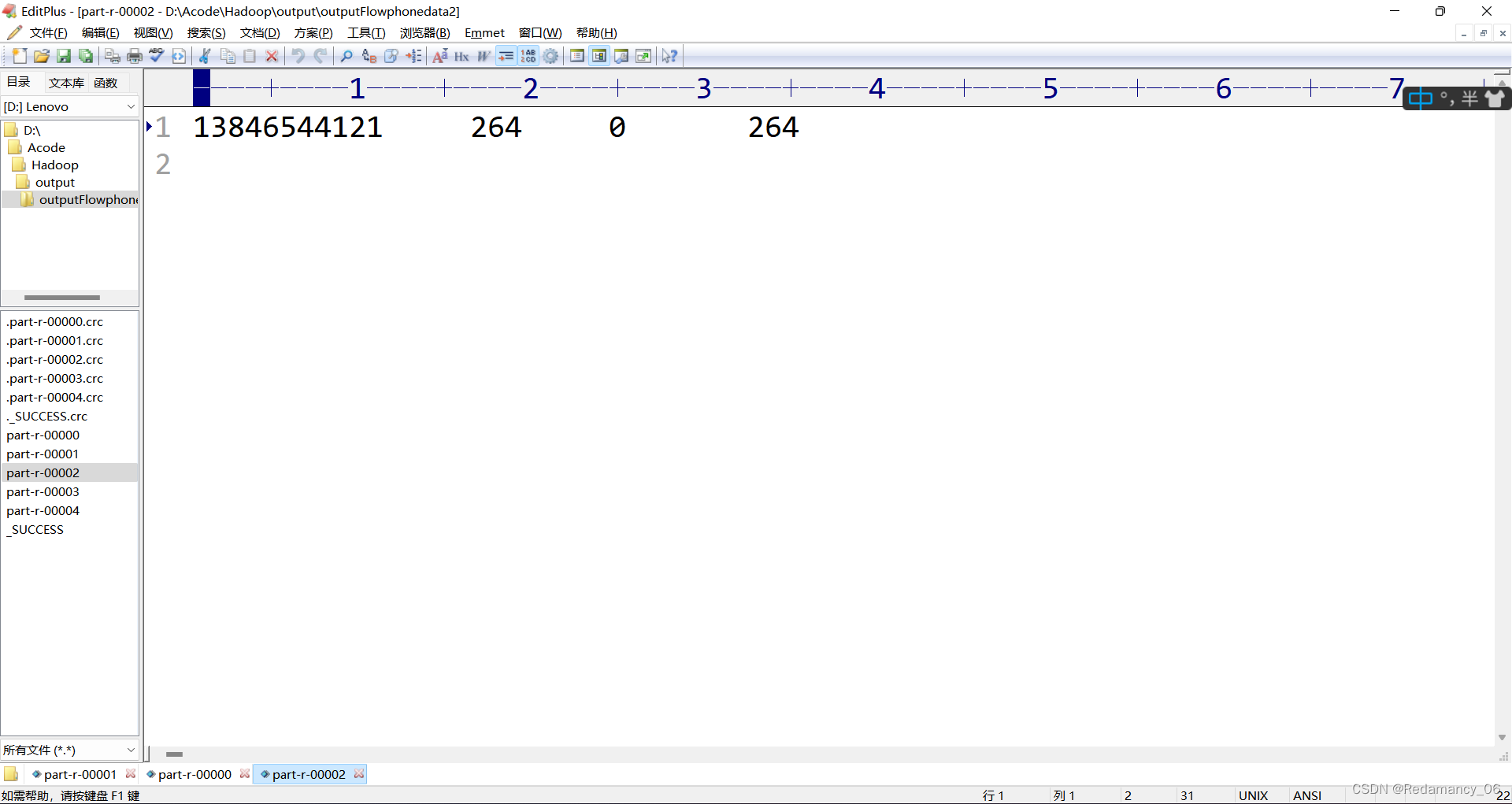
运行完成,结果和预想的一样,over!
#### 13.3.8 Combiner合并
(1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)Combiner组件的父类就是Reducer。
(3)Combiner和Reducer的区别在于运行的位置
Combiner是在每一个MapTask所在的节点运行;
Reducer是接收全局所有Mapper的输出结果;
(4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。

##### 13.3.8.1 自定义 Combiner 实现步骤
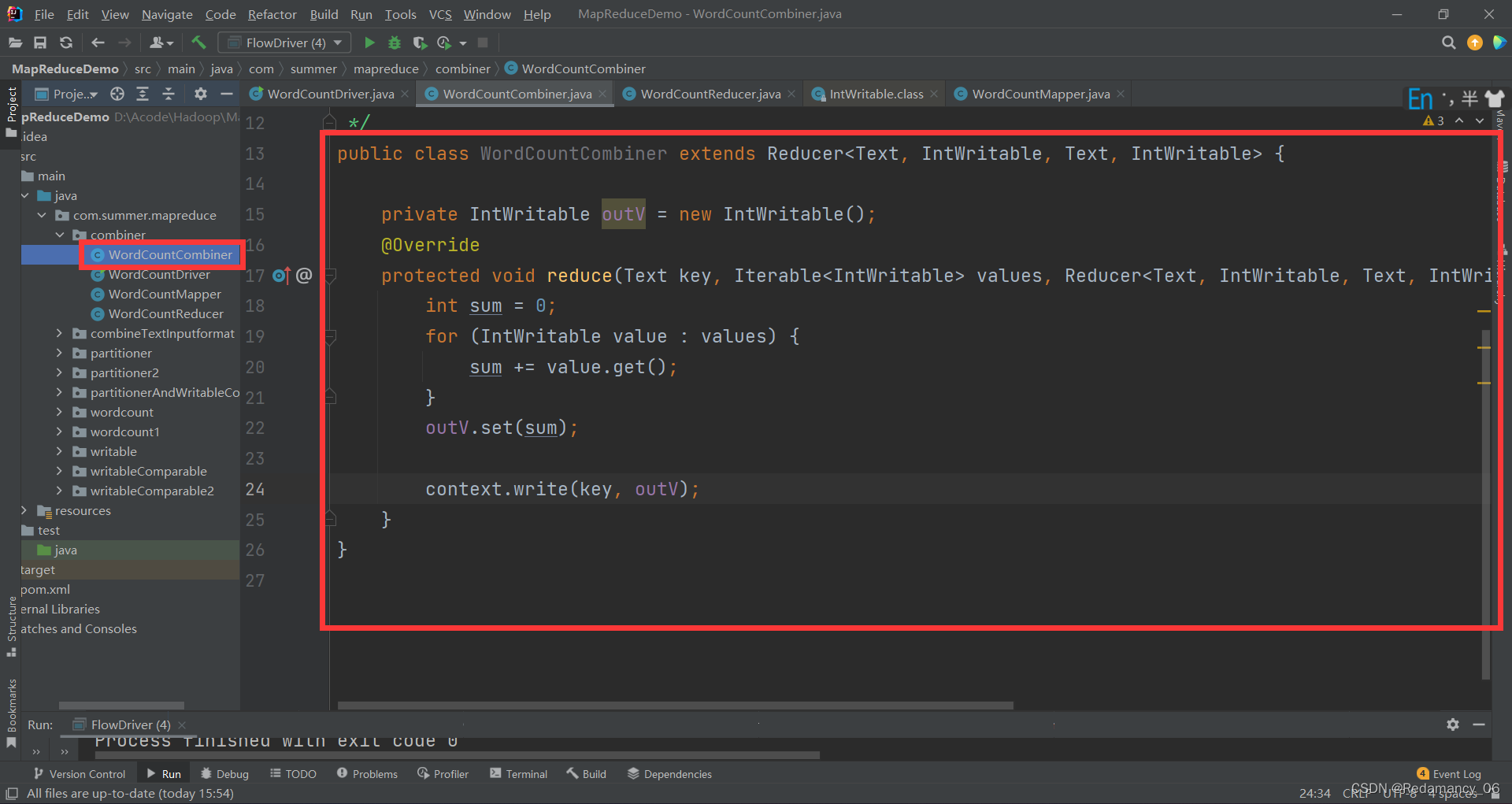
###### 13.3.8.1.1 自定义一个 Combiner 继承 Reducer,重写 Reduce 方法
package com.summer.mapreduce.combiner;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-10-04 17:21
*/
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
###### 13.3.8.1.2 在 Job 驱动类中设置
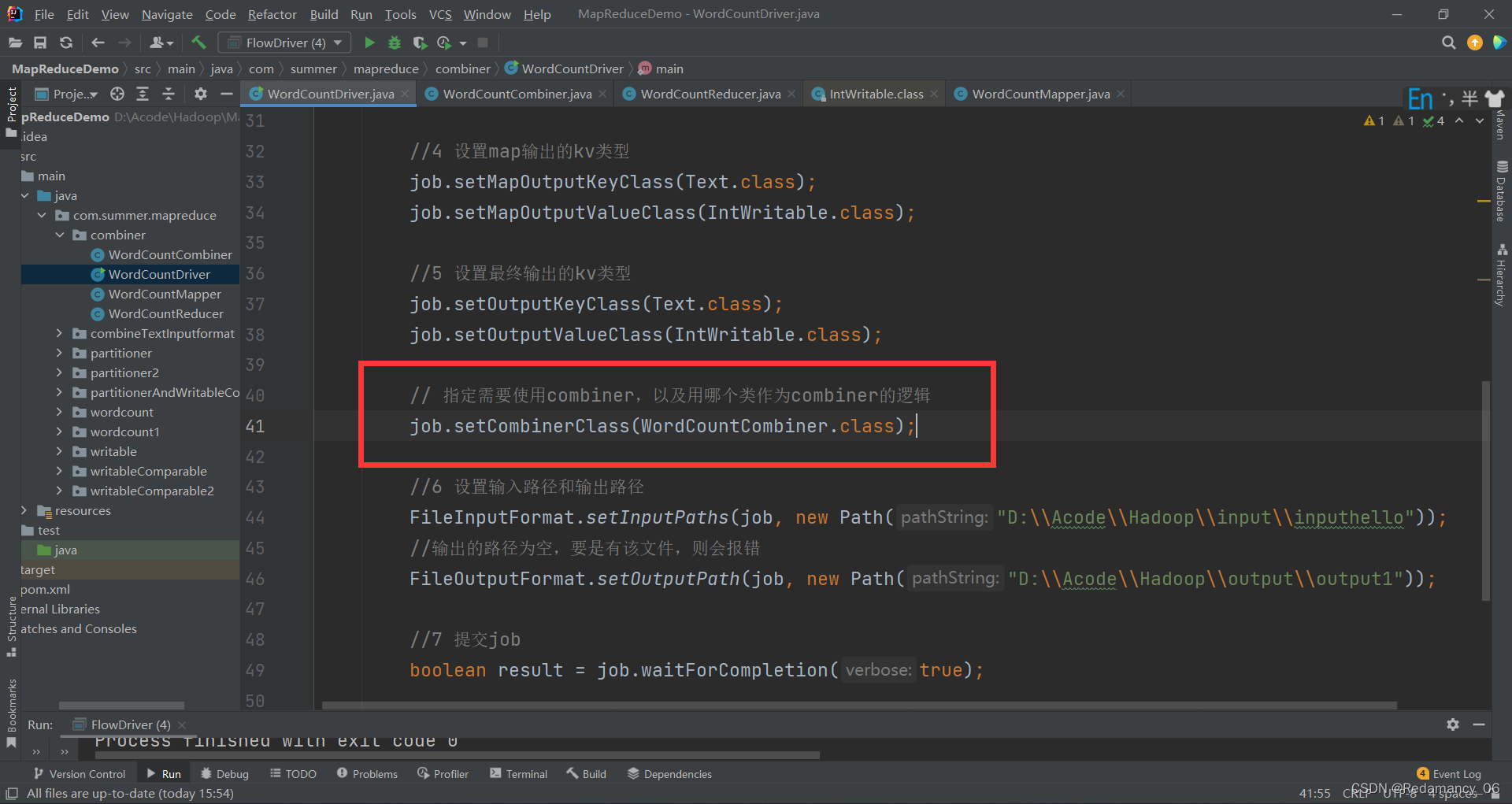
>
> // 指定需要使用combiner,以及用哪个类作为combiner的逻辑
> job.setCombinerClass(WordCountCombiner.class);
>
>
>
package com.summer.mapreduce.combiner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author Redamancy
* @create 2022-08-22 17:23
*/
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
//3 关联mapper和reduccer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 设置最终输出的kv类型

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









