







DataSet
DataFrame
1.3 SparkSQL特点
1.3.1 易整合
无缝的整合了SQL查询和Spark编程
1.3.2 统一的数据访问
使用相同的方式连接不同的数据源
1.3.3 兼容Hive
在已有的仓库上直接运行SQL或者HiveQL
1.3.4 标准数据连接
通过JDBC或者ODBC来连接
1.4 DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,RDD只关心数据,如传入一数组(1,2,3,4),RDD不关心数组的意思。而DataFrame关心数据结构,如主键。
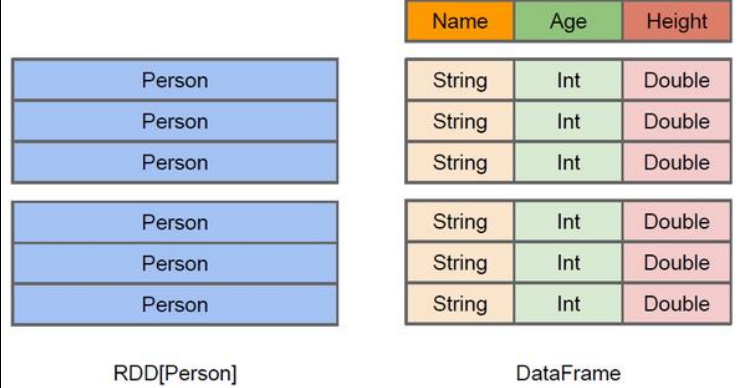
RDD:
虽然以Person为参数类型,但Spark框架本身不了解Person类的内部结构。
DataFrame:
提供了详细的结构信息,使得SparkSQL可以清楚的知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame为数据提供了Schema视图,可以把它当作数据库中的一张表来对待。
1.5 DataSet是什么
DataSet是分布式数据集合,是DataFrame的一个扩展。提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点
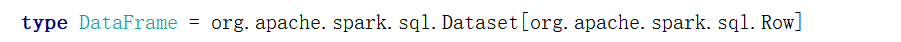
DataFrame是一个特定泛型的DataSet。
二、SparkSQL核心编程
2.1 新的起点
SparkCore中,如果想要执行应用程序,首先需要构建上下文环境对象SparkContext。SparkSQL可以理解为是对SparkCore的封装。不仅是在模型上进行了封装,上下文环境对象也进行了封装。
在老的版本中,SparkSQL提供了两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。Spark Session 内部封装了 SparkContext,所以计算实际上是由 sparkContext 完成的。当我们使用 spark-shell 的时候, spark 框架会自动的创建一个名称叫做 spark 的SparkSession 对 象, 就像我们以前可以自动获取到一个 sc 来表示 SparkContext 对象一样。
2.2 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。
2.2.1 创建DataFrame
Spark支持创建文件的数据源格式:spark.read.
csv format jdbc json load option options orc
parquet
schema table text textFile


object DataFrameTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("detaSetDemo").getOrCreate()
val dataFrame = spark.read.json("in/user.json")
dataFrame.printSchema()
dataFrame.show()
spark.stop()
}
}
注意:
如果从内存中获取数据,spark 可以知道数据类型具体是什么。
如果是数字,默认作 为 Int 处理;但是从文件中读取的数字,不能确定是什么类型,所以用 bigint 接收,可以和 Long 类型转换,但是和 Int 不能进行转换。
结果展示:

2.2.2 SQL语法
1)读取JSON文件创建DataFrame
val dataFrame = spark.read.json("in/user.json")
2)对DataFrame创建一个临时表
dataFrame.createTempView("user")
// 或
dataFrame.createOrReplaceTempView("user")
3)通过SQL语句实现查询全表
val frame = spark.sql("select * from user")
4)结果展示
frame.show()

注意:
普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
2.2.3 DSL语法
DataFrame提供一个特定领域语言(domain-specific kanguage, DSL)去管理结构化的数据。可以在Sacla, Java, Python和 R 中使用DSL,使用DSL语法风格不必去创建临时试图了。
1)创建一个DataFrame
val df = spark.read.json("in/user.json")
2)查看DataFrame的Schema信息
df.printSchema()
3)只查看列数据的6种方式
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
// 输出的6种方式
import spark.implicits._
userDF.select('name,'age).show()
userDF.select("name","age").show()
userDF.select($"name",$"age").show()
userDF.select(userDF("name"),userDF("age")).show()
userDF.select(col("name"),col("age")).show()
userDF.select(column("name"),column("age")).show()
val idColumn = df("id")
4)查看“age”大于“22”的数据
条件过滤可以使用filter,也可以使用where,where的底层调用的也是filter方法。
df.select(userDF("name"),userDF("age"),(userDF("age")+1).as("ageinc"))
.where($"name"=!="zhangsan").show() // where底层也是filter
// .filter($"ageinc">22).show()
5)按照“age”分区,查看数据条数
val countDF = df.groupBy("age").count()
countDF.printSchema()
6)增加列****withColumn
val frame = countDF.withColumn("number",$"count".cast(StringType))
7)修改列名withColumnRenamed
val frame2 = countDF.withColumnRenamed("count","number")
2.2.4 RDD转换为DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入import spark.implicits._
这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
rdd =>DataFrame: rdd.toDF
DataFrame => rdd: df.rdd

2.3 DataSet
DataSet是具有强类型的数据集合,需要提供对于的类型信息。
2.3.1 创建DataSet
object DataSetDemo {
// 1)使用样例类来创建DataSet
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("dataSet").getOrCreate()
val sc = spark.sparkContext
// 重点记忆
import spark.implicits._
// 2)使用基本类型的序列创建DataSet
val points: Seq[Point] = Seq(Point("nj", 23.43, 57.12), Point("bj", 18.21, 199.43), Point("sh", 16.11, 18.3))
val pointDS = points.toDS()
val categories: Seq[Category] = Seq(Category(1, "nj"), Category(2, "bj"))
val categoryDS = categories.toDS()
categoryDS.printSchema()
categoryDS.show()
}
注意:
在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet。
2.3.2 RDD转换为DataSet
SparkSQL能够自动将包含case类的RDD转换成DataSet,case类定义了table的结构,case类属性通过反射编程了表的列名。case类可以包含如Seq或者Array等复杂的结构。
case class User(name: String, age: Int)
sc.makeRDD(Seq(("zhangsan",18), ("zhaosi",20))).toDS
2.3.3 DataSet转换为RDD
DataSet也是对RDD的封装,所以可以直接获得内部的RDD。
case class User(name: String, age: Int)
val res1 = sc.makeRDD(Seq(("zhangsan",18), ("zhaosi",20))).toDS
val rdd = res1.rdd
2.3.4 DataFrame和DataSet转换
DataFrame => DataSet:as[样例类]
DataSet => DataFrame:toDF
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

[外链图片转存中…(img-AOSBMSqQ-1712890617396)]
[外链图片转存中…(img-OMZEQeoq-1712890617397)]
[外链图片转存中…(img-sYhSPQQz-1712890617397)]
[外链图片转存中…(img-TxS93k2Y-1712890617397)]
[外链图片转存中…(img-i1h2EKfo-1712890617397)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-x7A3RgIN-1712890617398)]















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









