






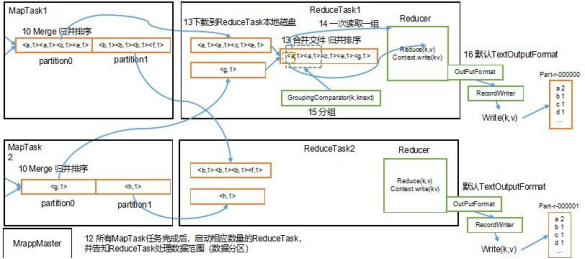
3.Yarn的Job提交流程
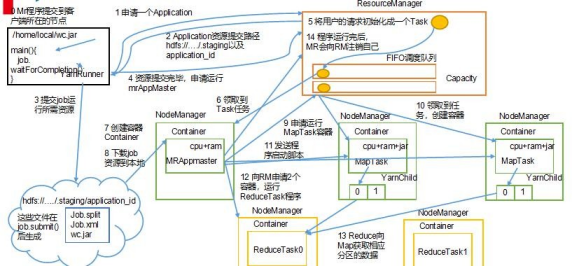
4.Yarn 的调度器分类
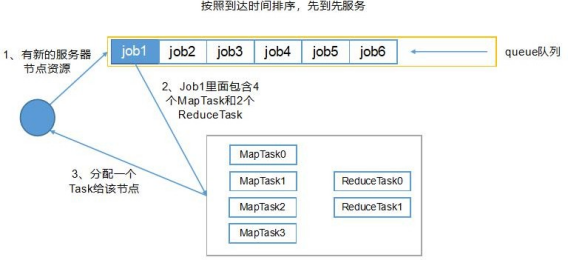
FIFO 调度器(先进先出调度器)
Capacity Scheduler(容量调度器)
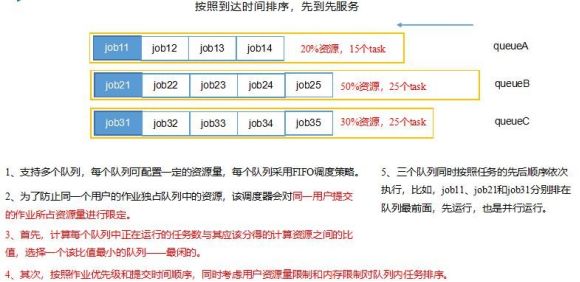
Fair Sceduler(公平调度器)

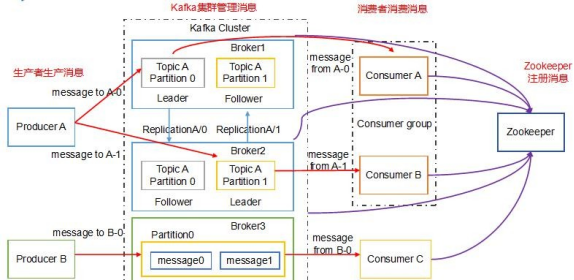
5.Kafka 架构图

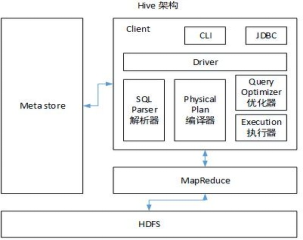
6.Hive架构图
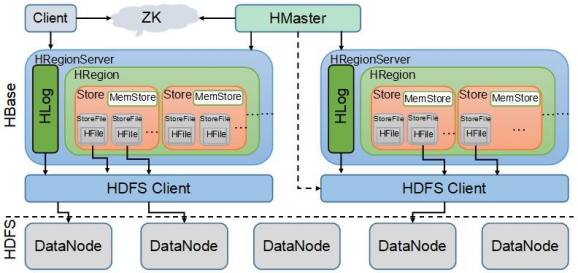
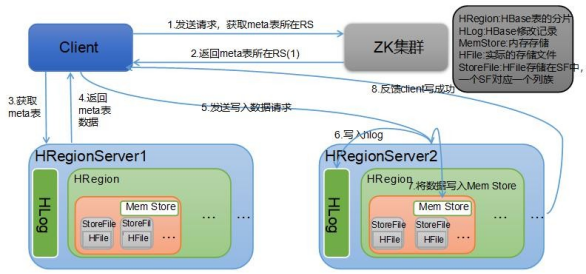
7.HBase存储结构图
HBase读流程
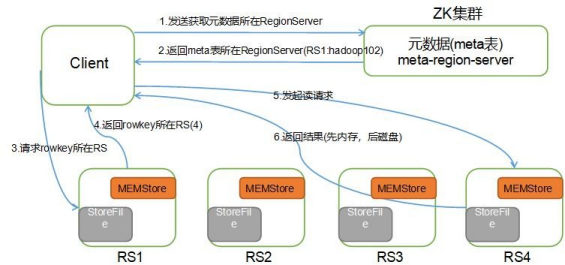
HBase读流程
Hadoop体系完了,下面是Spark和Flink体系
loading>>>>>>>>>>
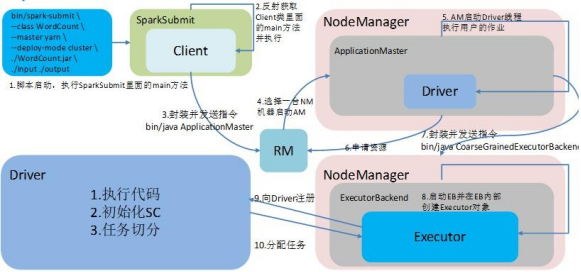
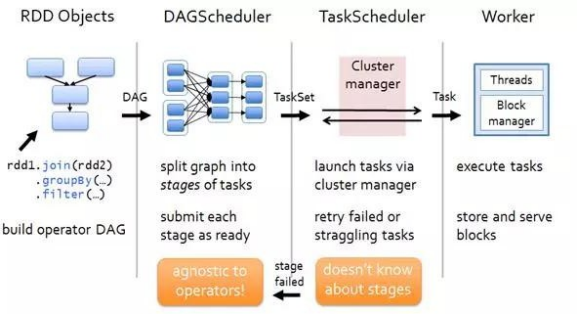
8.Spark 的架构与作业提交流程
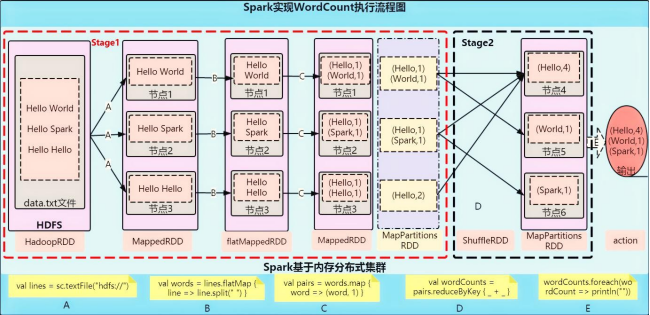
Spark实现WordCount执行流程图
补充 YARN Client 模式和YARN Cluster模式的区别

9.Spark 的 两 种 核 心 Shuffle ( HashShuffle 与SortShuffle)的工作流程
(1)未经优化的 HashShuffle
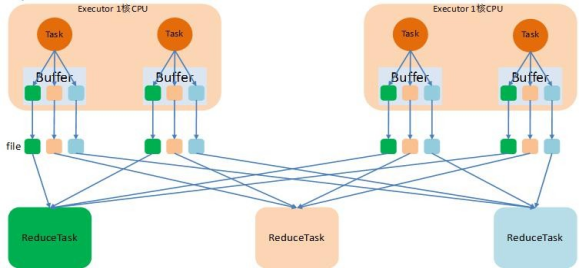
优化后的HashShuffle
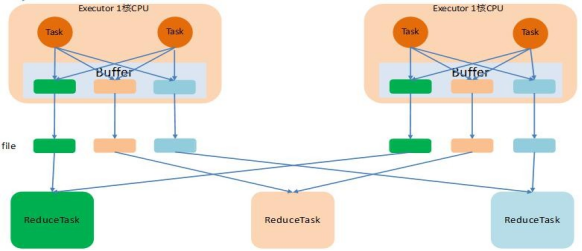
(2)普通的 SortShuffle:
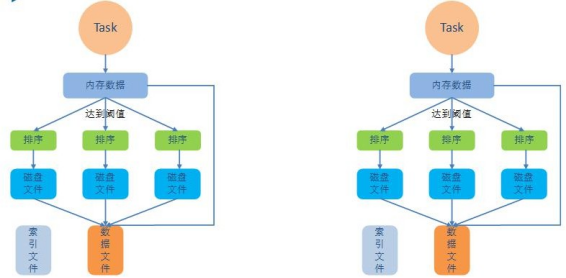
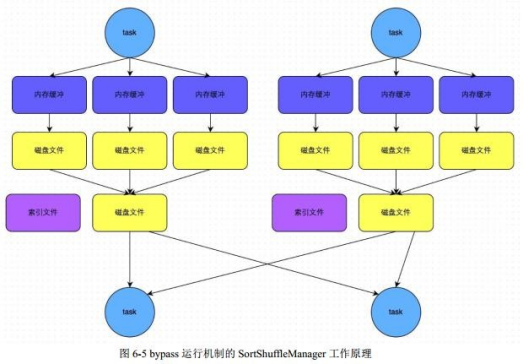
开启bypass机制后:
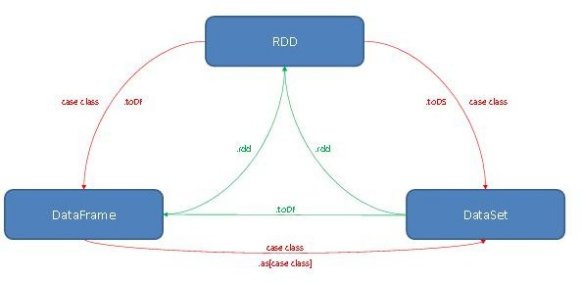
10.SparkSQL 中 RDD、DataFrame、DataSet 三者的区别与联系图解
11.Flink架构模型图
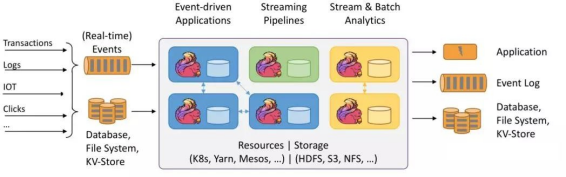
12.Flink任务调度图
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
bs.csdn.net/topics/618545628)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









