






最近一个叫 Ell 的新语言模型编程库发布了。它希望能与 LangChain、Llama-Index 和 DSPy 等库竞争,如果可能,它想取代这些竞争对手。
下面是 Ell 发布的推文。从一开始就很有信心,核心维护者称其为提示工程的未来。
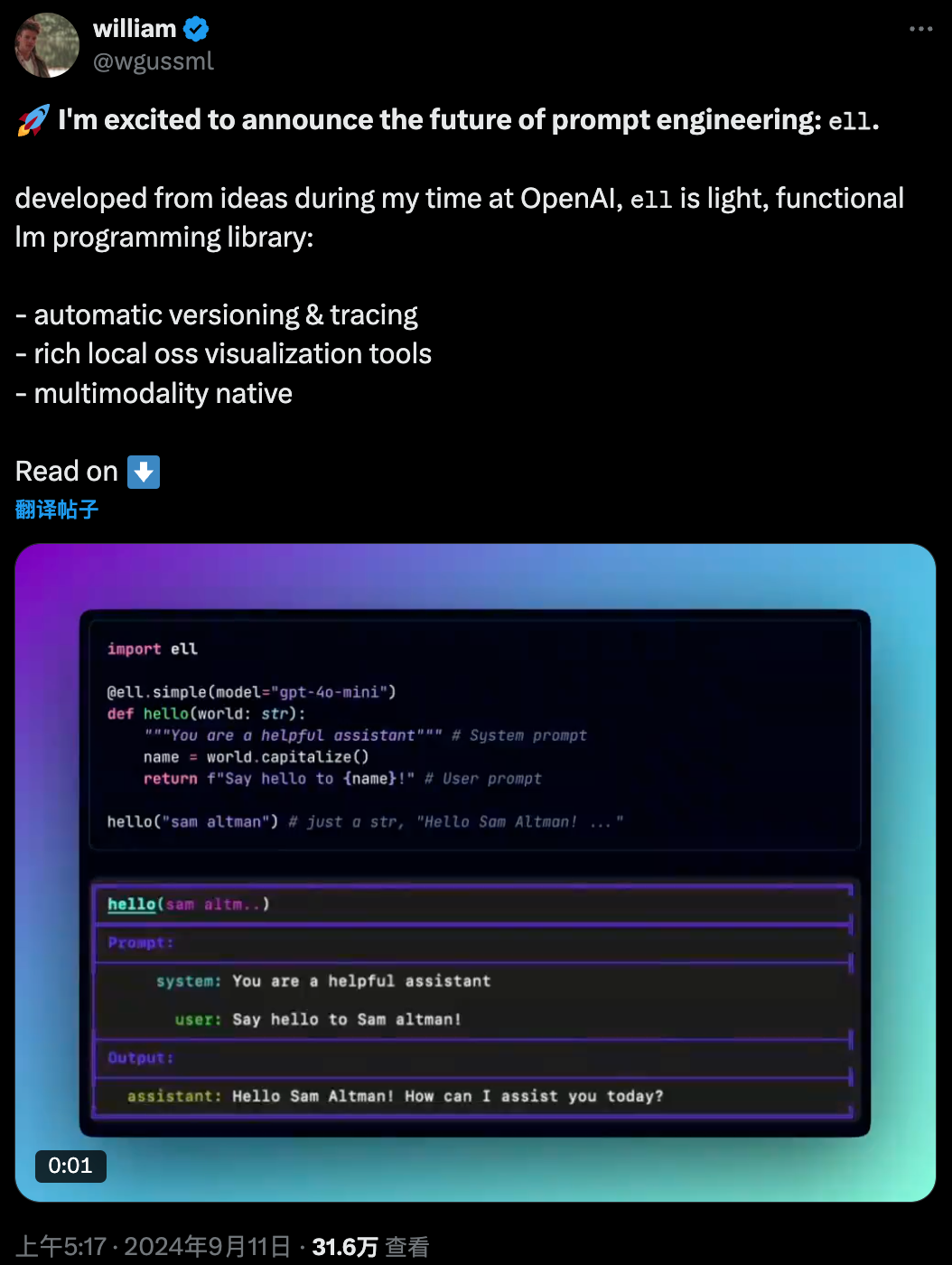
**Ell 的核心维护者说他是出于对使用 LangChain 的不满而构建的这个库。**提供的分屏代码比较显示了 LangChain 的抽象是多么臃肿和冗长,而 Ell 在完成相同任务时显得更加简洁。我也对 LangChain 的抽象有自己的批评。如果你需要复习一下,请阅读下面文章:
https://fsndzomga.medium.com/jailbreaking-langchain-ad9415a7abb6
但这是否意味着 Ell 具备正确的抽象?它值得投资吗?我想找出答案,所以决定查看 Ell 的文档,理解其核心抽象,进行实验,并形成自己的看法。
我就不说怎么安装 Ell 了,直接开始。
首先,让我们看看 Ell 的创建者是如何看待 LangChain 的局限性以及他创建 Ell 的原因:
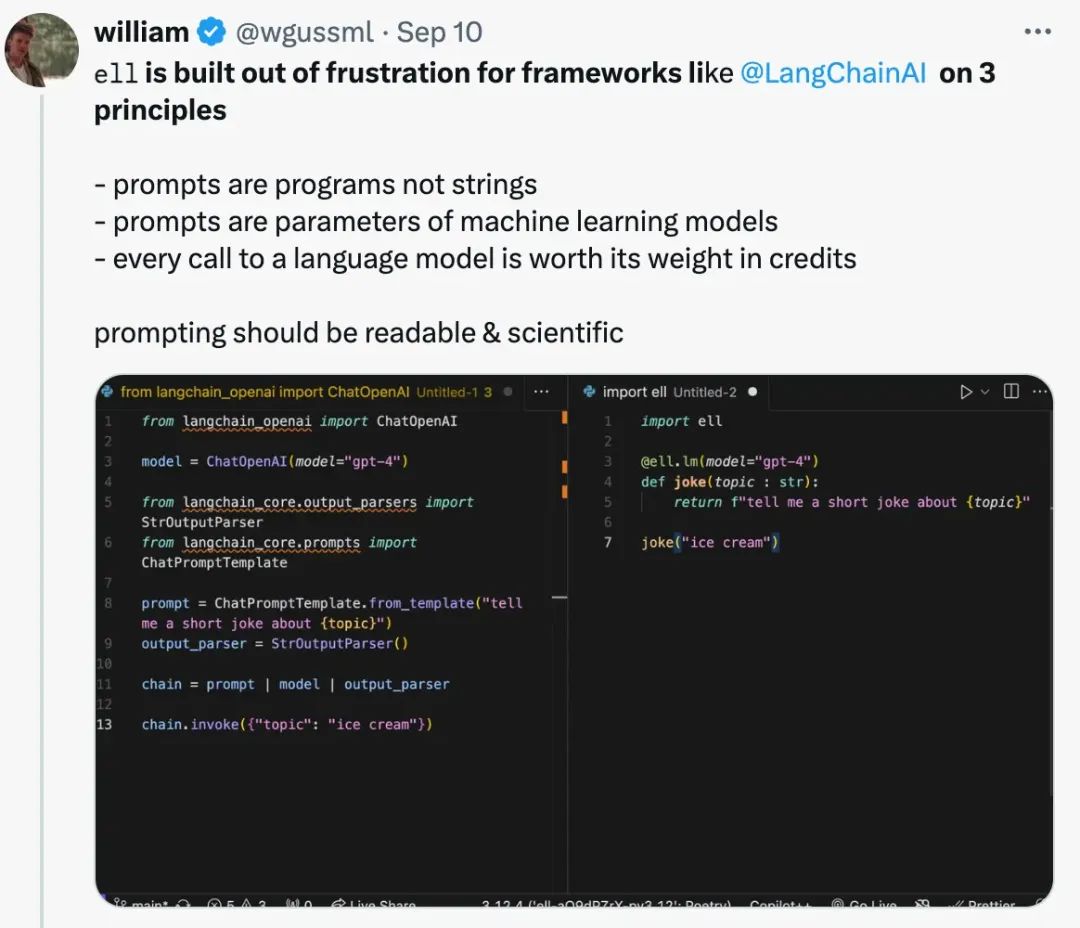
我们在概念上是否认同这个说法呢?
为什么我们应该将提示视为程序,而不仅仅是字符串?自 ChatGPT 出现以来已经两年了,但在我看来,我通过 API 发送的内容 —— 甚至是在应用程序中获得回应的内容 —— 仍然只是一些字符串,问题、指令、上下文 —— 这都是文本。那么为什么我现在要认为我发送的是程序呢?
我认为文本始终是一组指令,而 LLM 则是执行这些指令的语言计算机,这听起来吸引人,但也有些不对。我主要将 LLM 视为知识压缩的结果,更像是数据库而非正常的计算机,更多地像是语言接口而非语言编译器。不过,这只是我的看法,并不是唯一的概念化方式。
有人认为 —— 我倾向于同意 ——LLM 不仅仅是记住它们所训练的文本,还是捕捉到半通用的统计模式,“程序”,帮助它们进行如计算(不完善)或在某种程度上模拟逻辑推理。从这个意义上讲,我可以理解为什么有人会将 LLM 视为语言程序的编译器,从而将提示视为程序。
“提示是机器学习模型的参数。” 什么??我甚至不确定为什么有人会这样说。让我们假装没有看到这一点,开始探索 Ell。
#01
探索
基础知识
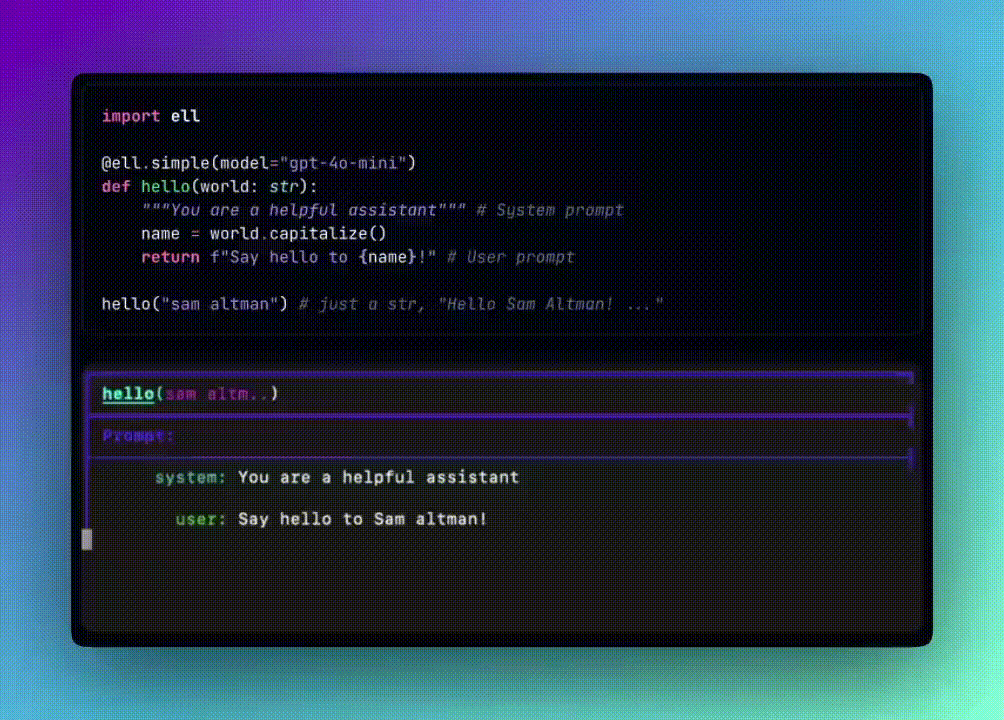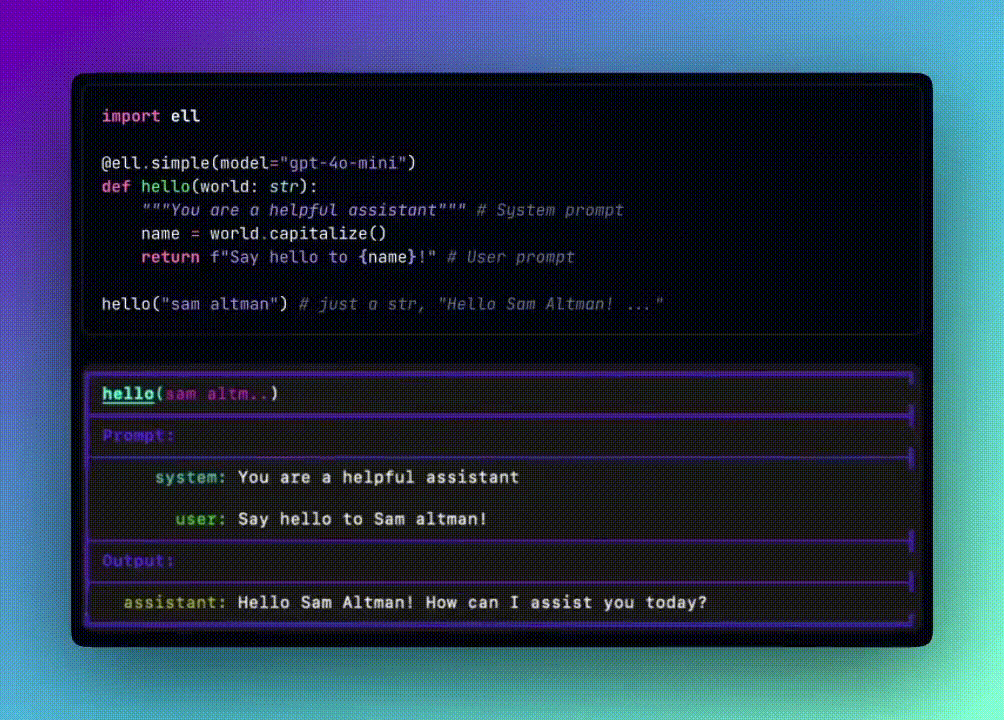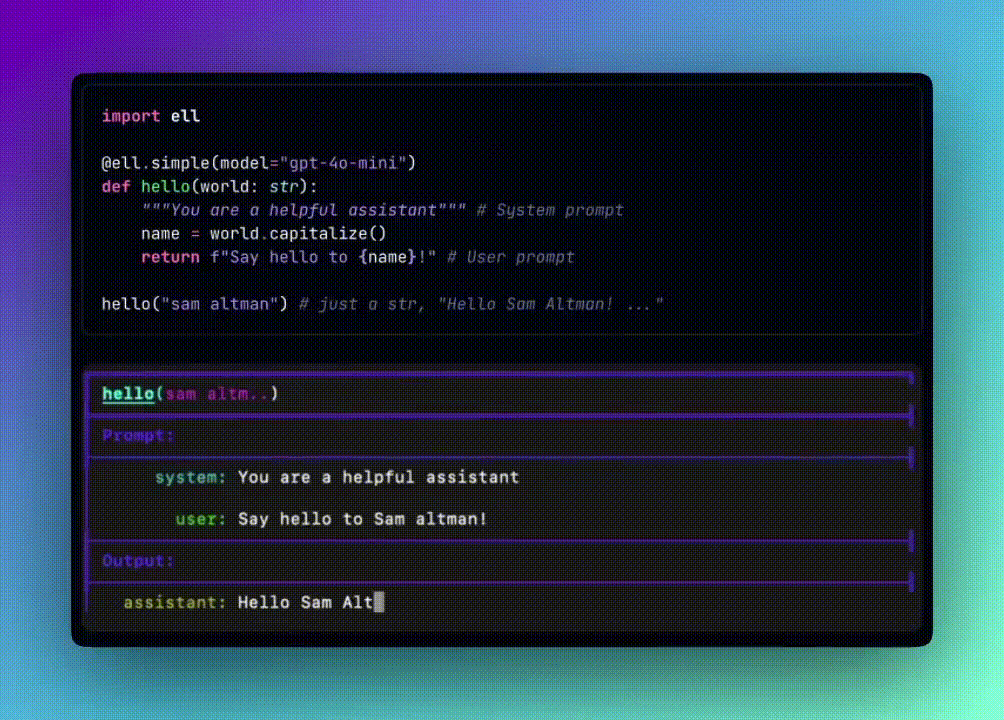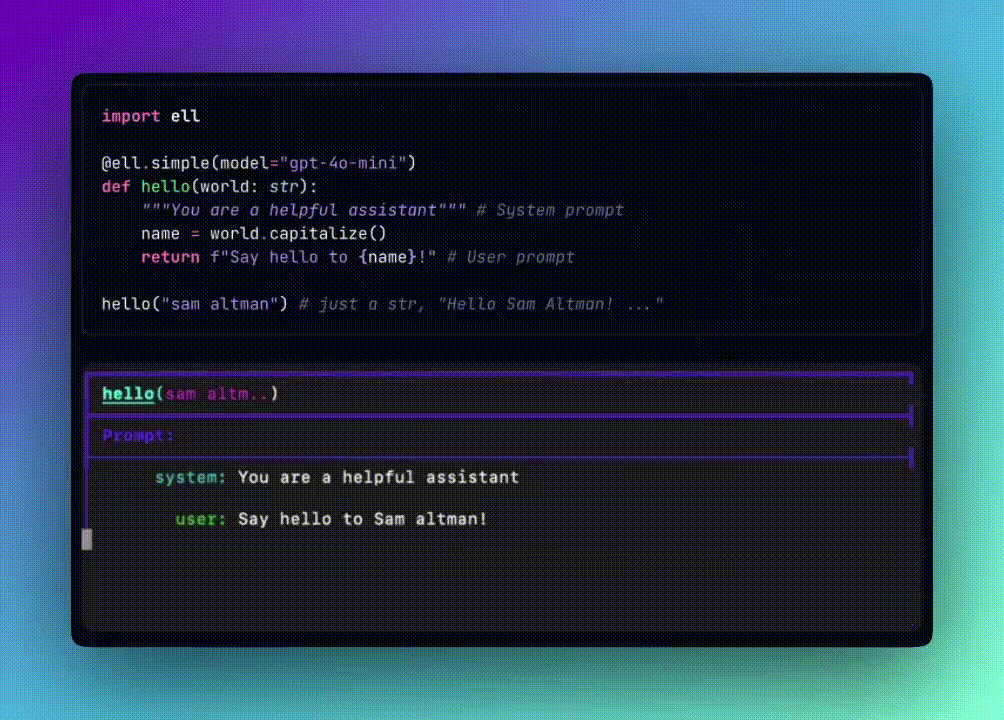
我从 Ell 的文档中开始一个基本的提示实现。
在 Ell 里,提示本质上是一个函数,然后使用装饰器来指定用于处理其输出的语言模型。
在这个例子中,我首先定义了要使用的基础模型客户端(OpenAI),然后将其与要使用的模型一起传递给 @ell.simpledecorator。就是这么简单。
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
@ell.simple(model="gpt-4o-mini", client=client)
def hello(world: str):
"""You are a helpful assistant""" # System prompt
name = world.capitalize()
return f"Say hello to {name}!" # User prompt
print(hello("sam altman"))
这是我得到的响应:

在运行第一个程序后,我开始质疑使用函数来定义提示的合理性。当然,在函数内部,你可以使用文档字符串来定义系统提示,而该函数返回用户提示。但除此之外,我并不清楚将提示定义为函数而非简单字符串有什么好处。
对我来说,一个真正有用的函数应当包括提示、对 LLM 的调用、LLM 的响应,以及基于该响应的一些后处理。但我们暂时先不下判断。
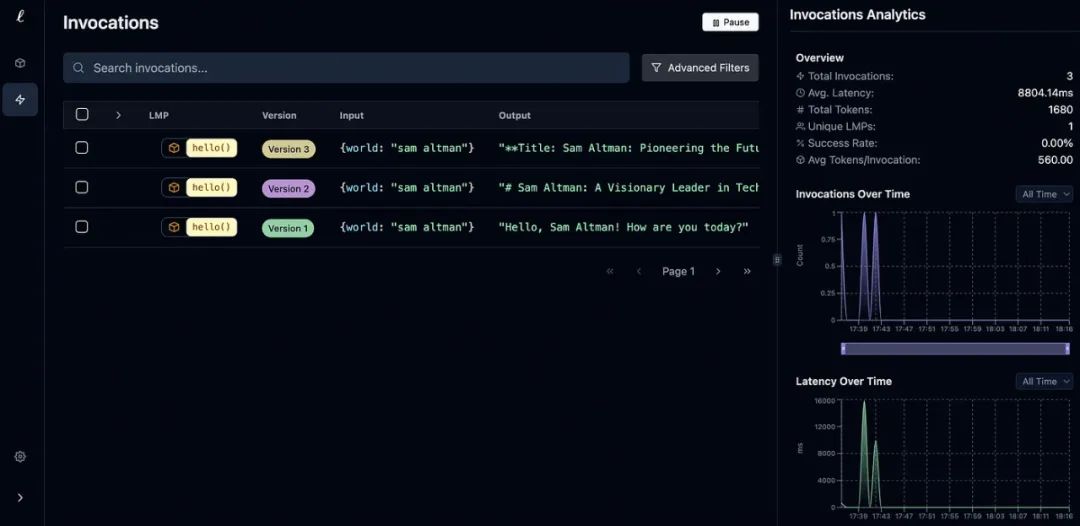
监控
Ell 的一个有趣方面是它允许你监控和版本控制提示,以及可视化延迟和 Token 使用等指标。而且这一切都是本地的,因此你的数据不会存储在第三方数据库中,不像 LangSmith 等解决方案。你只需用类似于:ell.init(store=’./logdir’) 的命令初始化本地数据库。
这是一个不错的功能,但也许只是我和我开发 AI 应用方式的问题 —— 我从未觉得需要跟踪提示的变化以改善它们。我常常觉得直觉就足够了。
例如,知道与某个提示相关的延迟如何帮助精炼它?如果延迟很高,通常只是意味着输入正在促使更长的响应(就像我让模型写文章时)。解决方案是指定诸如 “写一篇简短的文章” 之类的内容,而不是详细的内容,但我仅通过查看输出就能解决这个问题,而无需复杂的监控。同样的逻辑适用于 Token 使用。图表很好看,但我还没看到它们比直觉更有用的地方。
我敢打赌这些图表对于咨询来说很棒,对不熟悉生成式 AI 的客户来说也很有吸引力。根据我的经验,客户往往喜欢可交付的成果 ——PPT、报告、图表或详细的 Notion 演示文稿 —— 因为这让他们感觉做了一些有用的事情,即使实际上并没有。这类似于大多数人对沉默的感觉不适。如果会议中有长时间的沉默,他们会对体验做出负面评价,而如果有不断的聊天 —— 即使是肤浅或误导性的 —— 他们的评价会更高。人们喜欢噪音,我觉得所有这些对提示变化的监控不过是装扮成科学方法的噪音。
但我也很想听听不同的观点(欢迎在评论中分享你的想法)。
我确实觉得将提示 - 响应对存储在数据库中有些用处,因为这可以帮助创建微调数据集。然而,重要的是要考虑那些防止基于输出训练模型的规则。我觉得这很虚伪,尤其是来自那些在 “合理使用” 下抓取网络内容的公司,现在却声称使用他们的输出是不公平的。
我很好奇 Ell Studio 是如何构建的。前端使用 React,这一点很明显。

至于后端,刚开始我还不确定。我刚开始猜测它可能是 FastAPI,但我得检查一下才能确定。果然,后端是 FastAPI。这做得相当不错,我很喜欢这种方式。
工具使用
Ell 还支持工具使用 —— 只需使用 @ell。complex 装饰器。我尝试使用它进行 SERPAPI 搜索,但失败了。即使使用文档中的确切示例,我也无法让它工作。我明白了;这个库仍处于早期阶段,所以这可能只是一个简单的错误,稍后会修复。
这是我尝试的代码:
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
import requests
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define a tool to search on the internet using SERPAPI
@ell.tool()
def search_on_internet(query: str) -> str:
search_url = "https://serpapi.com/search"
params = {
"q": query,
"api_key": os.getenv("SERPAPI_API_KEY"),
}
response = requests.get(search_url, params=params)
if response.status_code == 200:
data = response.json()
if "organic_results" in data:
results = data["organic_results"][:3]
text = results[0]["snippet"] if results else "No snippet available"
final = {
"results": results,
"text": text
}
return f"Top 3 results: {final['results']}\n\nText: {final['text']}"
else:
return "No results found."
else:
return f"Error fetching search results: {response.status_code}"
# Define a complex task using ell and GPT model
@ell.complex(model="gpt-4o-mini", client=client, tools=[search_on_internet])
def article(country: str):
"""You are a helpful assistant""" # System prompt
name = country.capitalize()
return f"Who is the president of {name} in 2024?" # User prompt
# Test the function
print(article("united states"))
注意:如果使用 Ell 的最新版本,它现在可以工作了。
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
import requests
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define a tool to search on the internet using SERPAPI
@ell.tool()
def search_on_internet(query: str) -> str:
search_url = "https://serpapi.com/search"
params = {
"q": query,
"api_key": os.getenv("SERPAPI_API_KEY"),
}
response = requests.get(search_url, params=params)
if response.status_code == 200:
data = response.json()
if "organic_results" in data:
results = data["organic_results"][:3]
text = results[0]["snippet"] if results else "No snippet available"
final = {
"results": results,
"text": text
}
return f"Top 3 results: {final['results']}\n\nText: {final['text']}"
else:
return "No results found."
else:
return f"Error fetching search results: {response.status_code}"
# Define a complex task using ell and GPT model
@ell.complex(model="gpt-4o-mini", client=client, tools=[search_on_internet])
def article(country: str):
"""You are a helpful assistant""" # System prompt
name = country.capitalize()
return f"Who is the president of {name} in 2024?" # User prompt
# Test the function
output = article("united states")
if output.tool_calls:
print(output.tool_calls[0]())
多模态是头等公民
我喜欢 Ell 将多模态作为一流特性。这开启了广泛的用例,我对此感到非常兴奋。能够上传图像并根据这些图像提问非常酷。
这是我使用的代码:
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
from PIL import Image
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
@ell.simple(model="gpt-4o", client=client)
def describe_activity(image: Image.Image):
return [
ell.system("You are VisionGPT. Answer <5 words all lower case."),
ell.user(["Describe the content of the image:", image])
]
# Load Image
img = Image.open("product_2.jpg")
# desc
print(describe_activity(img))
我得到的结果相当准确。你可以看看这里:
结构化输出
我喜欢 Ell 支持结构化输出。不幸的是,这一功能仅对特定版本的 GPT-4 模型可用。由于许多库如 Instructor 提供更广泛的覆盖,我觉得 Ell 需要更多地支持所有可用模型的结构化输出。这可以通过 Instructor 实现的基本重试逻辑来完成。
我首先测试了文档中提供的代码。以下是代码:
from pydantic import BaseModel, Field
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
class MovieReview(BaseModel):
title: str = Field(description="The title of the movie")
rating: int = Field(description="The rating of the movie out of 10")
summary: str = Field(description="A brief summary of the movie")
@ell.complex(model="gpt-4o-2024-08-06", client=client, response_format=MovieReview)
def generate_movie_review(movie: str) -> MovieReview:
"""You are a movie review generator. Given the name of a movie, you need to return a structured review."""
return f"generate a review for the movie {movie}"
然后我想到了构建一个合成数据生成器。生成器以公司名称为输入,并为该公司生成合成员工。相当酷吧?这只是众多潜在用例中的一个。你可以想象使用这种结构化输出生成功能构建一个金融分析师 Agent 或国际象棋 Agent。
from pydantic import BaseModel, Field
import ell
from dotenv import load_dotenv
from openai import OpenAI
import os
# Load environment variables
load_dotenv()
# Initialize ell logging store
ell.init(store='./logdir')
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# Define your desired output structure
class Employee(BaseModel):
name: str
position: str
department: str
hire_date: str
salary: int
@ell.complex(model="gpt-4o-2024-08-06", client=client, response_format=Employee, n=10)
def generate_synthetic_data(company: str) -> list[Employee]:
""""""
return f"generate employees for this company: {company}"
for employee in generate_synthetic_data("Nebius"):
print(employee.parsed)
#01
总结
总的来说,我很喜欢尝试 Ell,看到不同的抽象被构建来与 LLM 一起工作真是太棒了。我并不认同所有的抽象,但软件总是有其偏见 —— 对我来说不完美的东西可能对别人来说正合适。
Ell 的成熟度不如 DSPy,因此实现诸如 RAG 之类的功能可能需要更多工作去做。Ell 也没有 LangChain 提供的广泛集成。但随着时间的推移,事情会发生变化,说实话,谁还需要另一个偏见强烈的集成工具呢?
我鼓励大家尝试 Ell 并形成自己的看法。
有时,我在想当输入只是字符串而输出是字符串加上一些元数据时,我们是否真的需要在 API 调用之上添加抽象。如果需要,正确的抽象级别应该是什么?这又扯到另外一个话题上了。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









