






1. 节点嵌入-传统的图表示学习
1.1 图表示学习
图表示学习目的是将高维稀疏的图结构转化为低维稠密的向量化表示,同时保留节点间的拓扑关系、语义信息和属性特征,有效的应用在节点分类、链接预测和图分类等下游任务中。图表征学习方法大致分为四类:基于距离翻译、基于语义匹配、基于随机游走、基于图传播的方法。
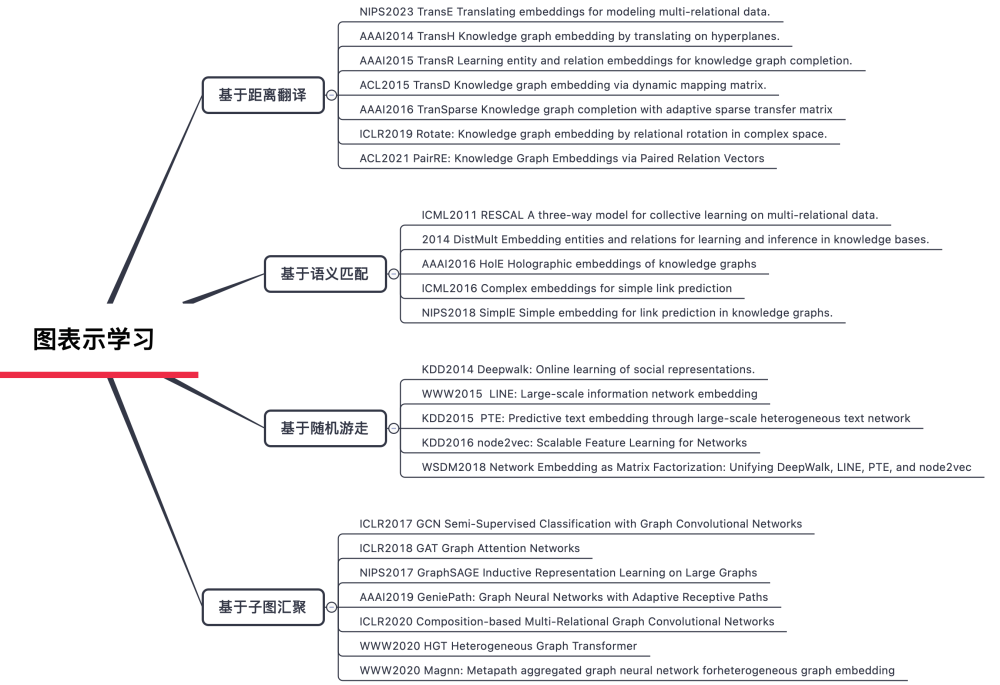
图表示学习是图谱推理模型的基石,传统图推理算法(如路径排序算法、关联规则挖掘)依赖人工设计的特征工程,而在图表示学习的方法出现后,图推理模型可直接利用图表征进行概率预测或逻辑推断。
1.2 长程图学习
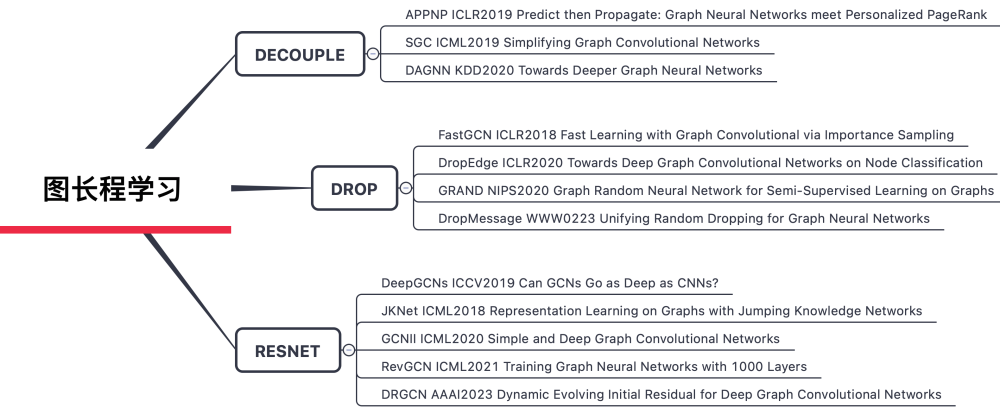
图学习的主流方法是通过消息传递机制(message passing)实现节点、边及全局信息的交互。具体而言,每个节点通过聚合邻居节点的特征信息更新自身表示,边函数则负责传递节点间的关系特征。长程学习指的是在节点汇聚时,扩大感受野使用多跳(≥2 hop)的邻居节点来更新节点自身表示。在特征稀疏或标签稀疏时,长程学习可以有效获取到更多的特征和结构信息进行节点表征。但是,长程学习的难点在于,随着图神经网络层数逐渐变深,会出现Over-Smoothing问题,即节点的表征会逐渐趋于相似以至于无法区分。
我们将图长程学习的解决方法分为三大类,分别是基于解耦、基于Drop、基于残差连接的方案。
1.在图卷积过程中解耦Transformation和Propagation操作;
2.在图数据预处理阶段中执行DropNode、DropEdge等操作;
3.使用多种方式的残差链接机制,让模型具有记忆缓解深度GNN的过平滑和过压缩的现象。
1.3 图带噪学习
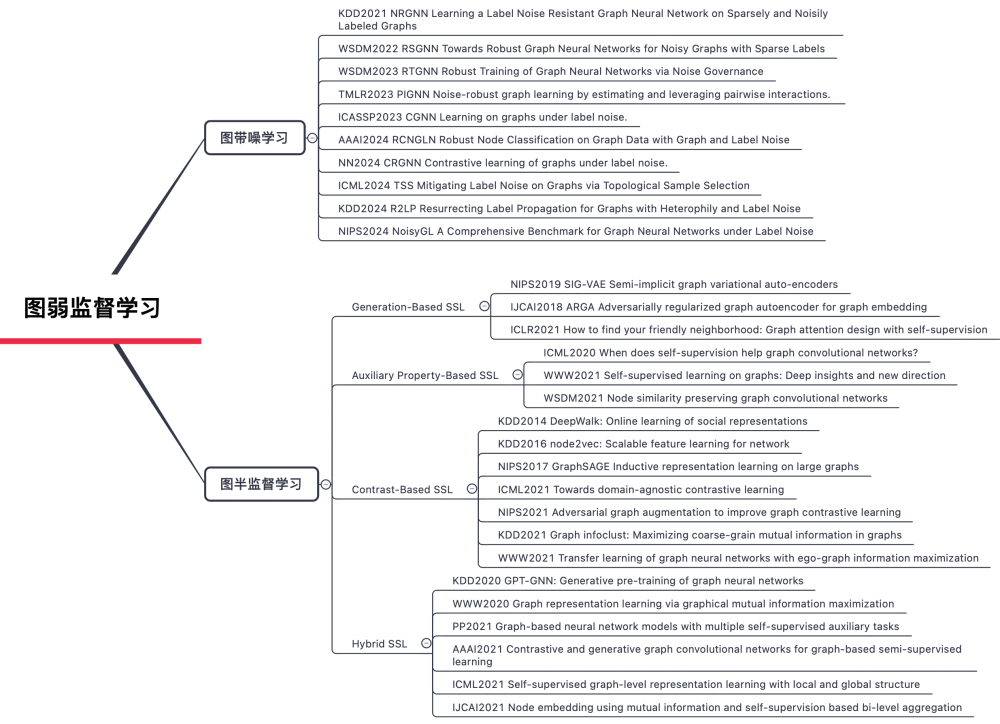
现实业务中获取到的图关系数据往往存在(1)数据不完全:用户外部行为数据缺失,收集渠道受限;(2)数据带噪:数据采集过程存在噪音,标记信息不准确。然而,噪声的存在会显著降低图神经网络的泛化能力,导致过拟合或误判。图带噪学习(Graph Learning with Noisy Data)便是旨在解决图结构数据中普遍存在的噪声干扰问题。
1.4 图结构学习
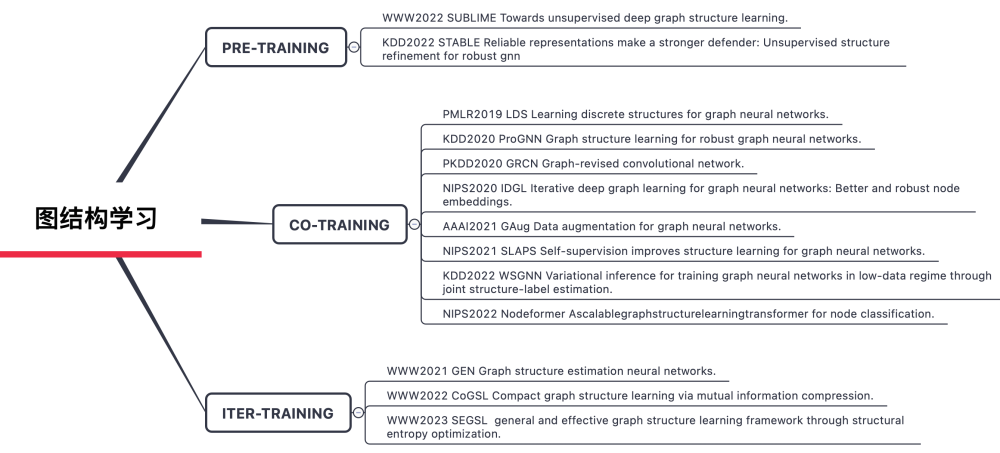
从图谱结构特征和图结构学习方法两个角度给出总结,其中,图谱结构特征刻画了节点之间的连接情况,是图谱上非常重要且很有特色的一类特征。结构特征有很多,包括:度信息、PageRank值、点聚类系数、紧密中心性、本征向量中心性、共同邻居指标、Katz指标、随机游走相似性等等。

图结构学习策略可以分为以下三类:Pre-training, Co-training和Iter-training。
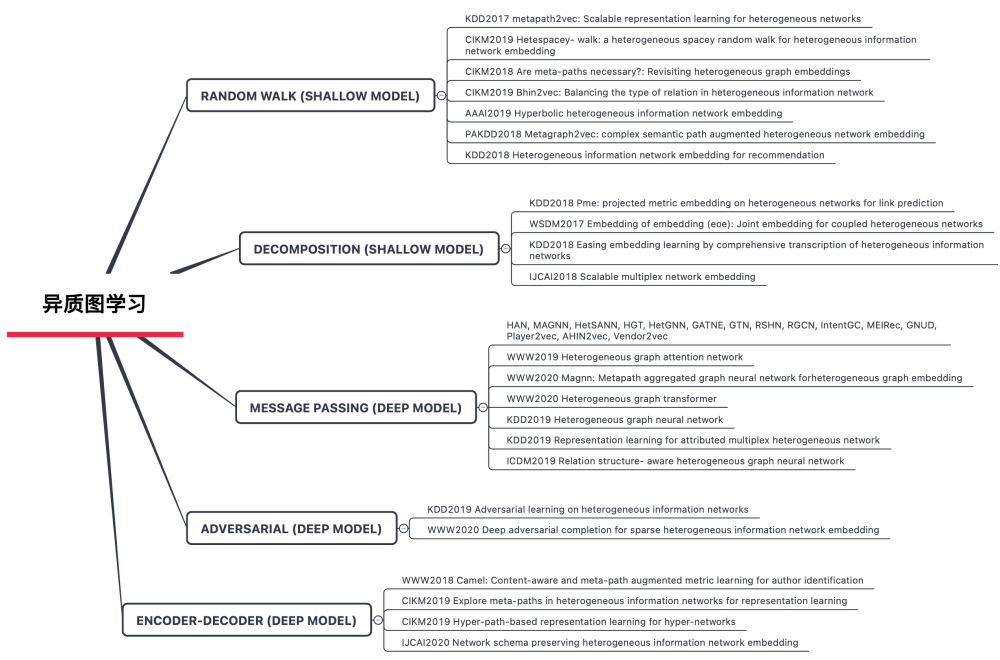
1.5 异质图学习
同质图中只有一种类型的节点和边,相应的异质图通过包含多种类型的节点和边,能够更自然地建模现实世界中复杂的交互系统。相较于传统的同质图,异质图通过丰富的语义结构和类型信息,为高阶关系推理和细粒度特征学习提供了更具表达力的数据基础。
然而,异质图的复杂性也带来了独特的挑战。传统图神经网络(GNNs)基于同质性和局部邻域假设的设计,难以有效处理异质图中节点类型多样性、关系语义差异性以及高阶交互异构性等问题。针对这些挑战,将现有的异质图方案梳理成以下5类。
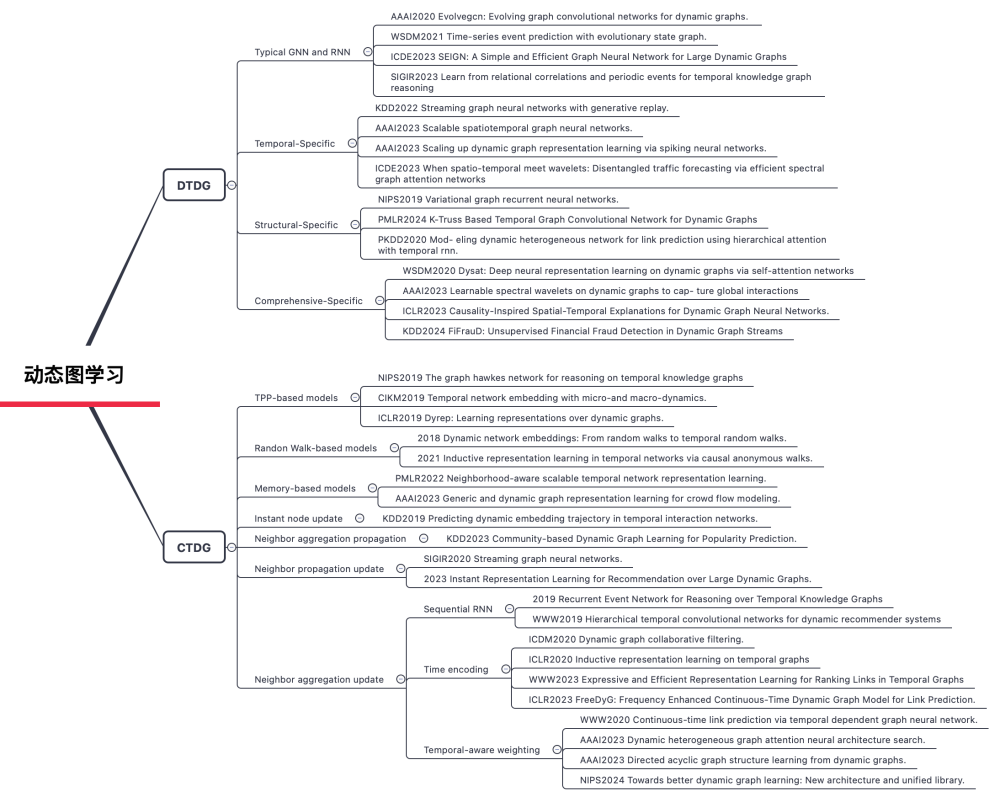
1.6 动态图学习
动态图神经网络(GNN)将时间信息与GNN相结合,同时捕捉动态图中的结构、时间和上下文关系,从而在各种应用中提高性能。动态图表示方法常被分为两类:离散时间动态图(DTDG)和连续时间动态图(CTDG)。离散时间动态图将时间划分为离散的时间间隔或时间步,每个时间步对应一个图的快照,表示在该时间点上的图结构。连续时间动态图将时间视为连续的,不划分为离散的时间步。它捕捉图中的所有事件流,每个事件都有一个精确的时间戳。
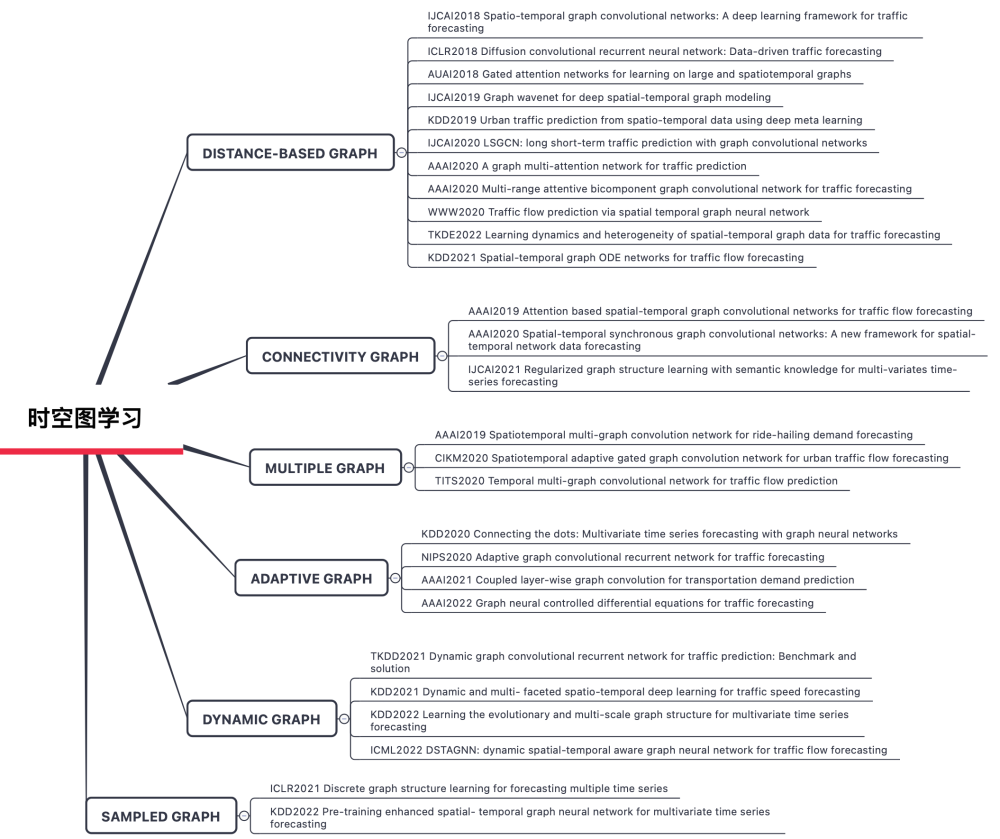
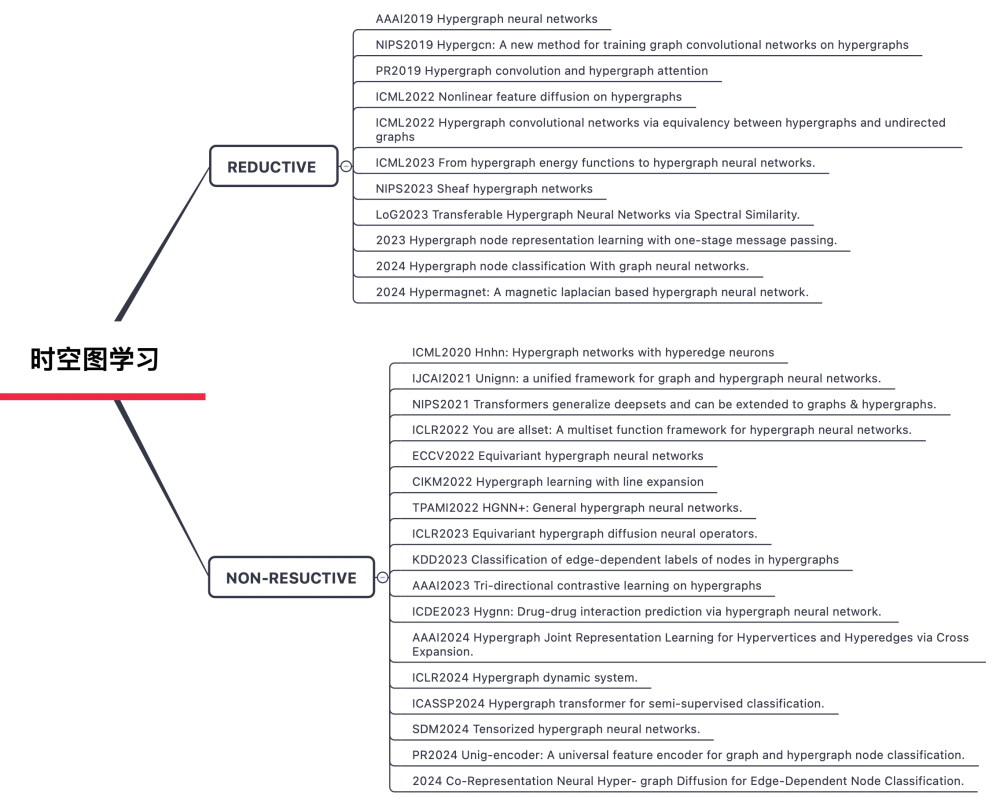
1.7 时空图学习
随着图神经网络(GNN)与深度学习技术的融合,时空图学习方法在交通流量预测、社交网络演化分析等领域展现出显著优势。时空图通过融合图结构建模与时序特征提取,能够有效表征多维异构数据中的非线性时空交互模式。其核心挑战在于同时捕捉空间维度上的拓扑依赖关系和时间维度上的序列动态特征。
1.8 超图学习
超图(Hypergraph)是指一种具有节点和超边(hyperedge)的图,其中超边包含任意个节点,节点也称作超点(hypernode)。超图通过超边连接任意数量的节点,能够更自然地表达多对象间的群体关系(如科研合作网络中的多作者论文、图像中的多区域语义关联等)。超图建模的优势:(1)高阶关系建模:超边可同时包含多个节点,适用于社交网络分析、知识图谱、多模态数据融合等场景,(2)全局语义增强:通过超图卷积等操作,能捕捉全局上下文信息;(3)动态适应性:支持动态超图结构更新,适应数据分布变化,例如推荐系统中的用户兴趣漂移。
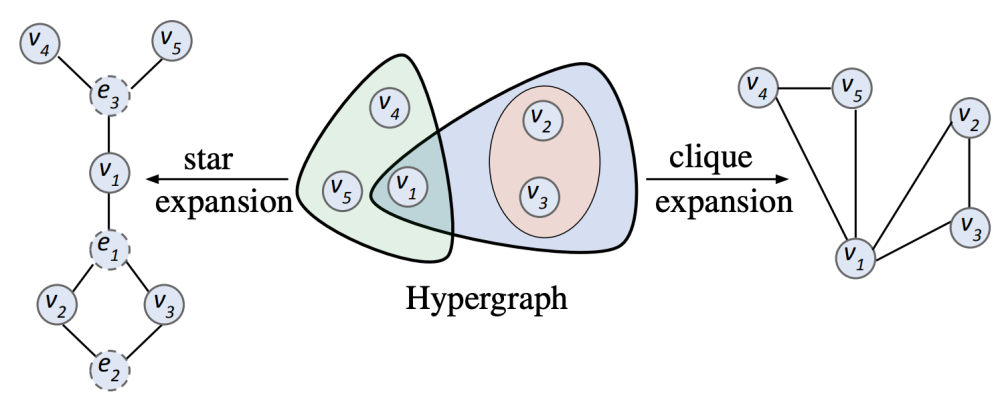
由于普通图的表征学习发展先于超图上的表征学习。以经典的半监督分类任务为代表,一开始有许多基于Expansion范式的超图表征学习算法被提出,这一类的方法首先将超图通过各种方式展开为普通图,再使用普通图上的卷积方法对节点进行表征。超图Expansion方法主要包括Star Expansion和Clique Expansion。
Clique Expansion属于Reductive Transformation方案,在这种方法中,原始超图中的每个节点都被保留为图中的一个节点,超边被转换为成对边。Star Expansion属于Non-Resuctive Transformation方案,这类方法中还包括例如Line Expansion和Tensor Representation的方式。
2. 认知跃迁-大模型时代的图学习革命
2.1 图+LLM综述
IJCAI2024 A Survey of Graph Meets Large Language Model- Progress and Future Directions
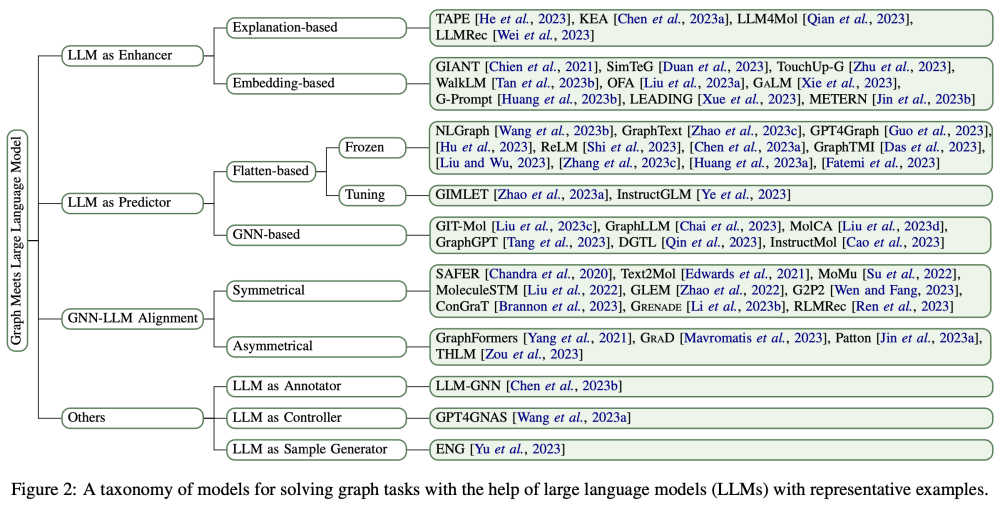
论文提出根据LLM在图任务中的角色将现有方法分为三类:
LLM作为增强器(Enhancer)
·基于解释的增强:利用LLM生成节点属性的附加解释,提升文本嵌入质量;
·基于嵌入的增强:直接通过LLM生成高质量节点嵌入,结合GNN进行训练。
LLM作为预测器(Predictor)
·基于展平策略:将图结构转换为文本序列输入LLM。
·基于GNN的预测:利用GNN提取结构特征后输入LLM,增强结构感知能力。
GNN与LLM对齐(Alignment)
·对称对齐:通过对比学习对齐图嵌入与文本嵌入。
·非对称对齐:以GNN为教师模型训练LLM,提升模型对图结构的理解
未来的研究方向
·非文本属性图处理:探索LLM在缺乏文本信息的图中的应用;
·迁移能力提升:开发跨领域统一框架,增强模型泛化性;
·可解释性增强:结合思维链等技术,生成用户友好的推理过程;
·效率优化:采用参数高效微调、轻量级对齐投影器降低计算成本。
KDD2024 A Survey of Large Language Models for Graphs
图是表示复杂关系(的关键工具,传统图神经网络依赖浅层嵌入,限制了节点特征的表达能力。大型语言模型在文本理解上表现好,但缺乏对图结构信息的捕捉能力。两者的结合可互补优势:GNN擅长结构分析,LLM擅长语义理解。
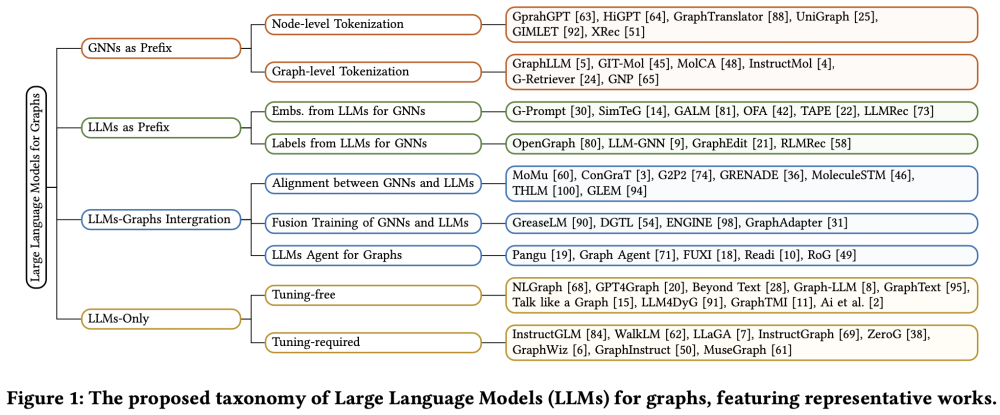
论文提出根据LLM在图任务中的角色将现有方法分为四类:
·GNN作为前缀:GNN处理图结构信息后输入LLM,增强LLM的结构感知能力,在文本属性图(TAG)中提升LLM的结构理解能力,但需解决输入长度限制。
·LLM作为前缀:LLM生成嵌入或标签优化GNN训练。通过生成伪标签或解释增强GNN训练,但面临API调用成本高的问题。
·LLM与图集成:通过联合训练或对齐技术融合LLM与GNN(如GraphGPT模型)。在分子分析、推荐系统中实现跨模态对齐
·仅用LLM:直接通过文本序列描述图结构,依赖LLM的推理能力(如GPT4Graph模型)。在零样本任务中表现优异,但难以捕捉长程依赖关系。
Large Language Models on Graphs- A Comprehensive Survey
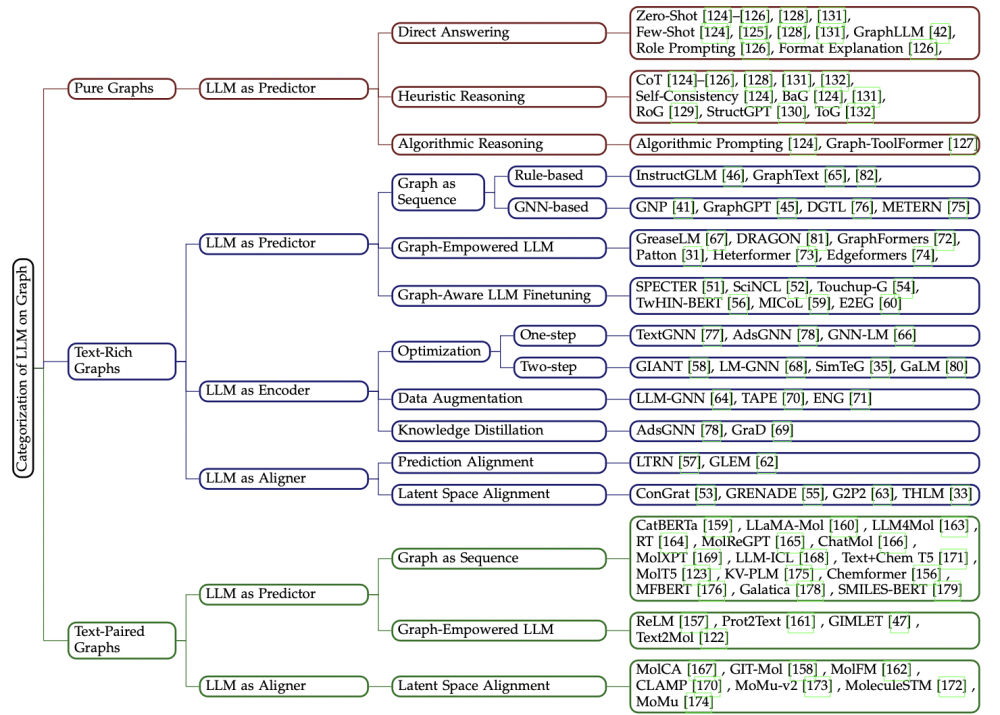

TKDE2024 Unifying Large Language Models and Knowledge Graphs- A Roadmap
论文提出三种图和大模型结合的框架
·KG增强的LLM:在预训练阶段,将KG三元组转化为文本输入LLM,或设计知识感知训练目标;在推理阶段阶段,动态检索KG知识辅助生成,或通过图神经网络增强LLM的结构感知能力
·LLM增强的KG:KG构建时,利用LLM从文本中抽取实体和关系;KG补全时,LLM作为编码器生成实体嵌入(如KG-BERT),或作为生成器直接预测缺失实体(如GenKGC)。KG问答(KBQA):LLM解析问题并检索KG路径(如StructGPT结合ChatGPT与KG推理)。
·协同LLM+KG:知识表示:联合对齐文本与图谱嵌入;双向推理:LLM生成逻辑查询,KG提供结构化验证。
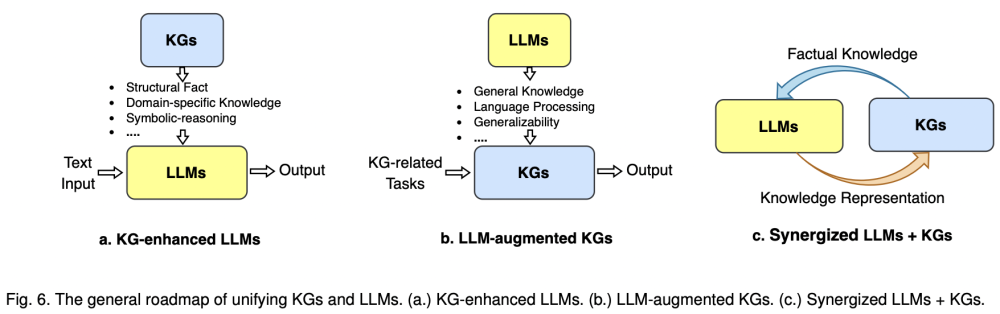
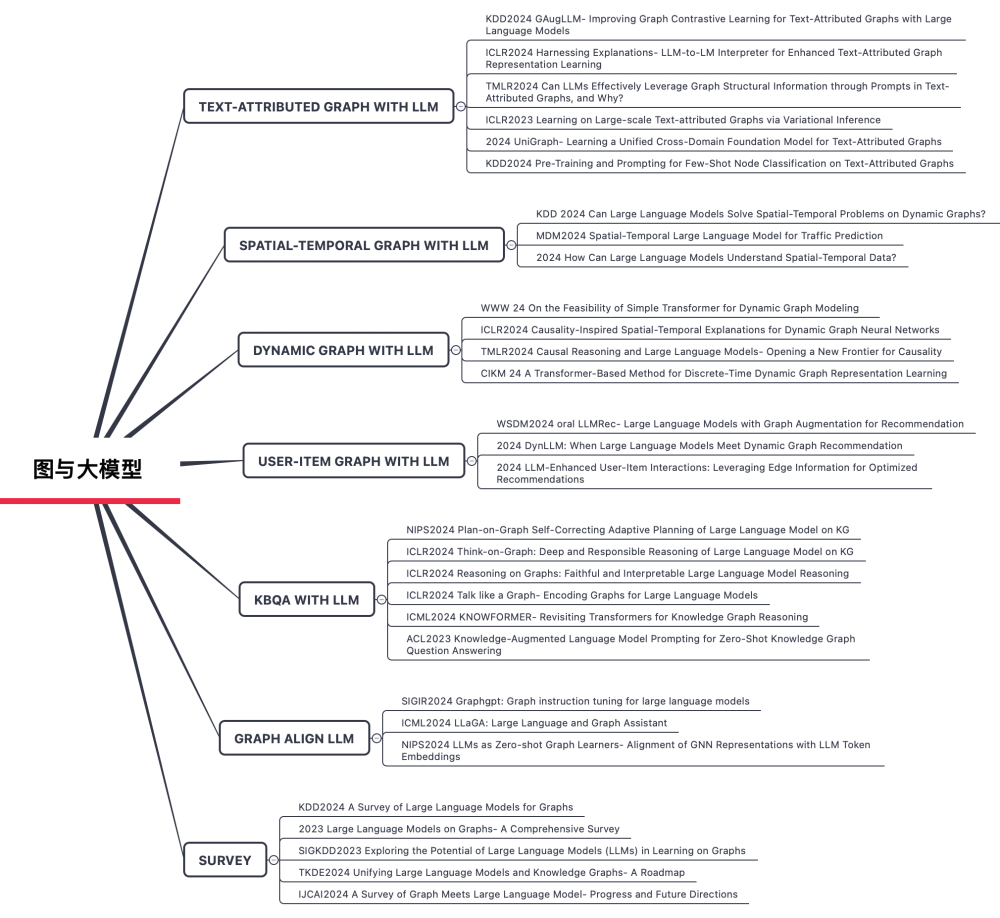
2.2 文本属性图+LLM
KDD2024 GAugLLM- Improving Graph Contrastive Learning for Text-Attributed Graphs with Large Language Models
基于表格数据的预训练大模型,Generative Tabular Learning (GTL), a novel framework that integrates the advanced functionalities of large language models (LLMs)—such as prompt-based zero-shot generalization and in-context learning—into tabular deep learning.
文本属性图,使用对比学习进行自监督学习,不过这里利用大模型进行 图数据增强。
1.Feature Augmentation:mixture of prompt experts(主要从节点角度进行文本增强) 多个专家模块
2.Structure Augmentation:collaborative edge modifier(增加边或删除边)
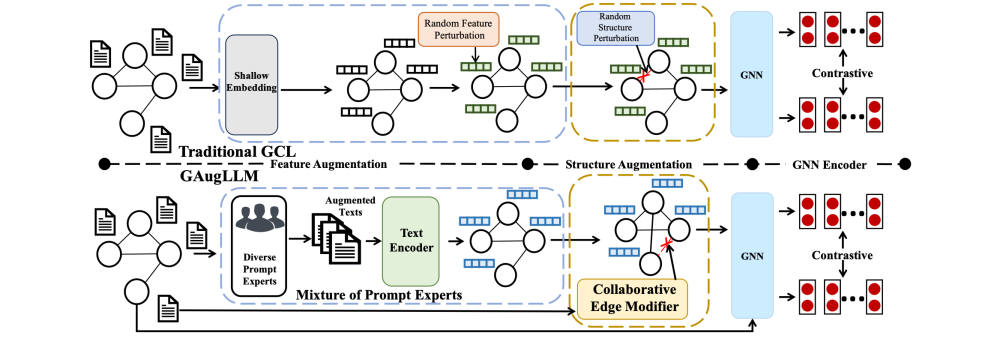
节点特征增强利用大模型设计了多个专家模块,抽取各个维度的文本信息,每一个专家对应了不同的提问方式,也就是设计了不同的指令instruction
1.Structure-Aware Summary Expert
2.Independent Reasoning Expert
3.Structure-Aware Reasoning Expert

ICLR2024 Harnessing Explanations- LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning
本篇文章的核心思路和上一篇GAugLLM类似,都是利用大模型进行文本属性图中的文本的理解,但本文中,利用大模型产生新数据后,在小的语言模型上进行fine-tune二次学习,然后利用GNN进行结构学习。
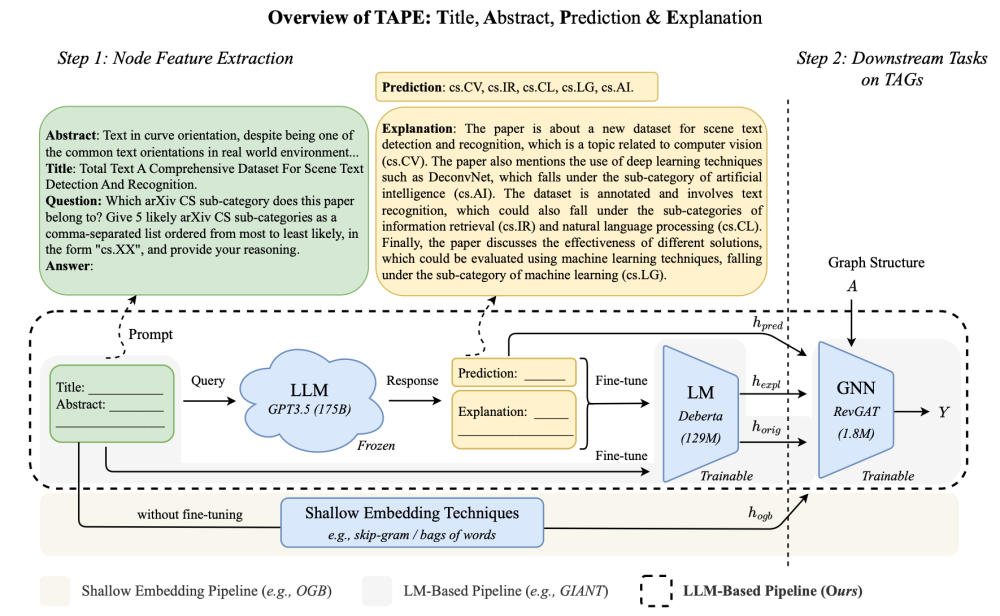
对于将llm的文本建模能力与gnn的结构学习能力相结合的技术的需求越来越大。
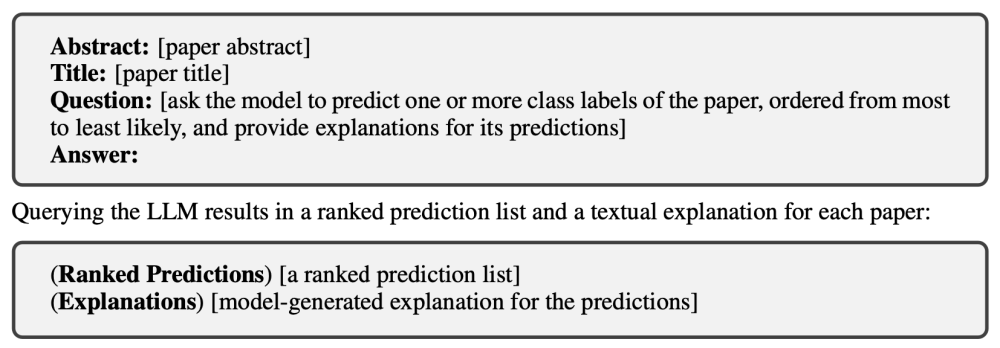
TMLR2024 Can LLMs Effectively Leverage Graph Structural Information through Prompts in Text-Attributed Graphs, and Why?
本文主要在探讨 大模型能否理解利用 prompt中提供的图结构信息?文中提供了多种prompt来验证
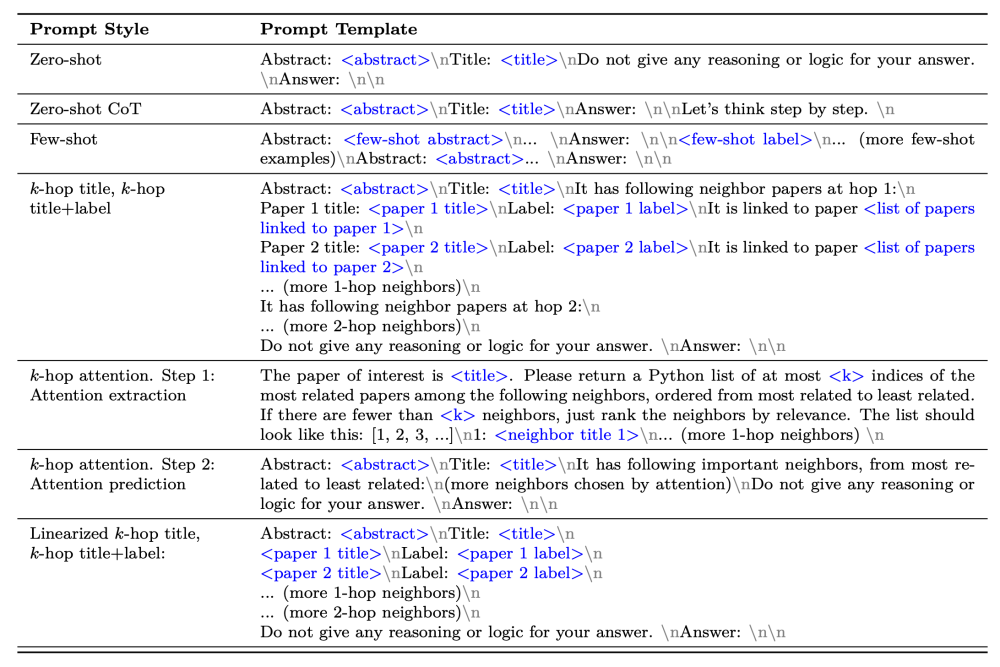
先说结论
1.大模型将prompt更多的仅仅是理解成contextual paragraphs而不是graph structures;
2.在邻居信息中更有用的信息是与标签相关的短语,而不是所谓的图结构(因此同质图会更受益邻居节点信息)

线性化描述的prompt和图结构化描述的prompt,在实验效果上没有明显差异,表明大模型更多的是将prompt作为线性的段落处理,而无法理解所谓的结构信息描述。 文中还设计了另一个实验
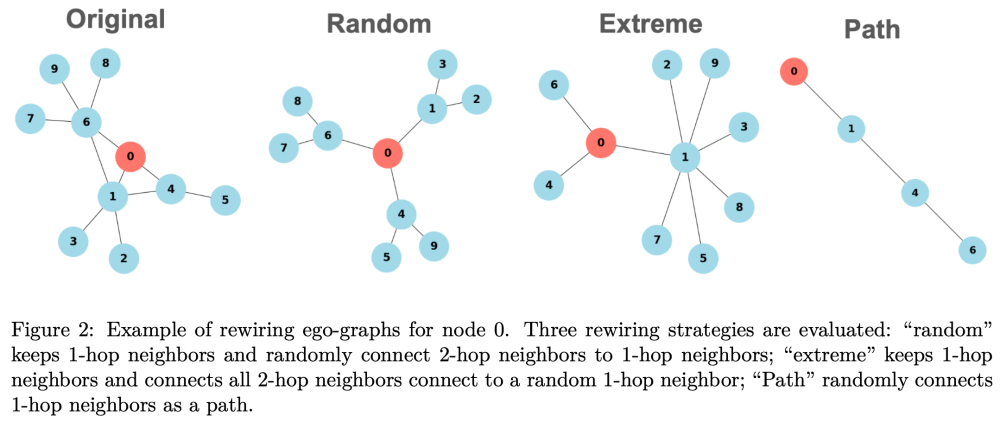
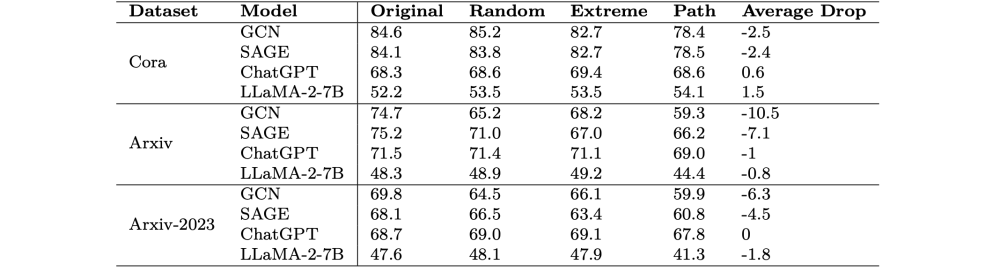
从上表的结果可以看出,结构信息的变化,对大模型对prompt的理解基本没有太大的差异。
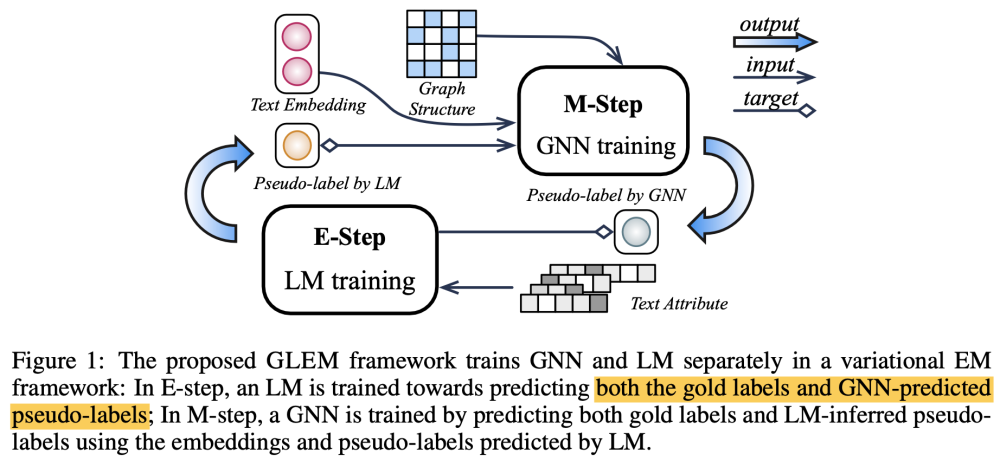
ICLR2023 Learning on Large-scale Text-attributed Graphs via Variational Inference
将图训练和LM-training结合起来,使用EM结构针对文本属性图进行学习
2.3 时空图+LLM
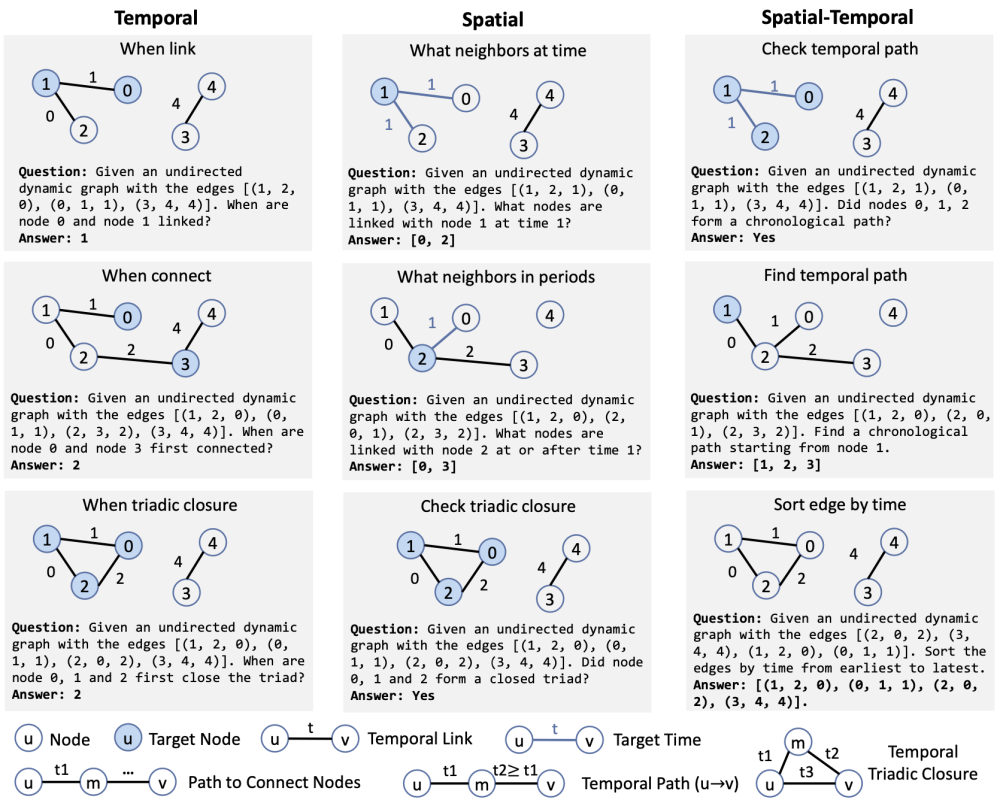
KDD 2024 LLM4DyG: Can Large Language Models Solve Spatial-Temporal Problems on Dynamic Graphs?
九个动态图任务,评估LLMs在考虑时间和空间维度方面的能力。
1.时间任务:何时链接;何时连接;何时三元闭合。
2.空间任务:给定时间点的邻居;给定时间段内的邻居;检查三元闭合。
3.时空任务:检查时间路径;查找时间路径;按时间排序边。
基线:采用随机基线,均匀选择一个可能的解决方案作为答案。任务的随机基线准确率可以通过正确解决方案的数量与可能解决方案的总数的比率计算。
采用各种提示方法,包括零样本提示、少样本提示[5]、思维链提示(COT)[69]和少样本提示与COT。
·LLMs在动态图上具有初步的时空理解能力。 如表2所示,GPT-3.5在所有任务上平均显著优于基线(从+9.8%到+73.0%),这表明LLMs确实理解了动态图和任务中的问题,并能够利用时空信息给出正确答案,而不是通过输出随机生成的答案进行猜测。
·时间信息增加了LLMs在静态图比较中的额外难度。 如图4所示,当时间跨度T从1增加到2时,GPT-3.5的性能急剧下降。可能的原因是任务从静态变为动态,设置更具挑战性,因为模型必须捕捉额外的时间信息。与图3的结果类似,当任务已经是动态图问题时,模型性能对时间跨度不敏感。
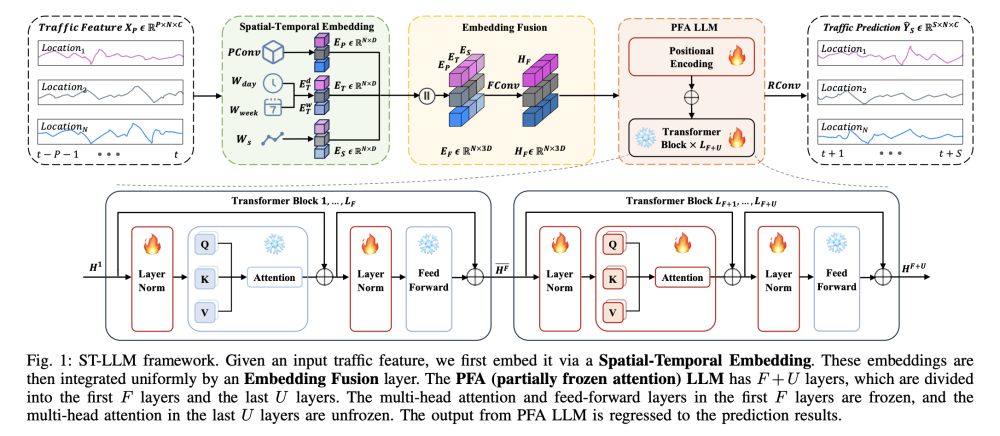
MDM2024 Spatial-Temporal Large Language Model for Traffic Prediction
·ST-LLM将位置的时间步定义为一个token,这些token通过专门设计的空间-时间嵌入层进行转换,以强调空间位置和全局时间模式。Ep 是 token embedding,Et 是 temporal representation,是hour-of-day embedding和day-of-week embedding之和,Es 是 spatial embedding。
接下来,引入了部分冻结注意力LLM,以有效捕捉交通预测中的全局时空依赖性。部分冻结的注意力的 LLM有F + U层,前F层中的多头注意力和前馈层被冻结,最后U层的多头注意力被解冻。
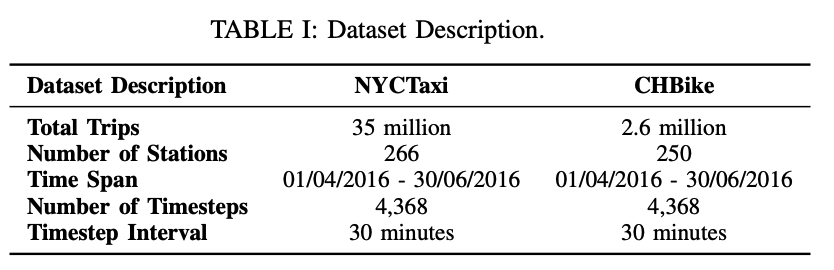
·NYCTaxi:包含纽约市约3500万条的出租车出行记录。时间跨度为2016年4月1日至2016年4月至6月30日。包含以下的信息:上车时间,送达时间,上车经度,上车纬度,下车经度,下车纬度,行程距离。NYC Bike数据集是有站式的,每一个仓库都被视为一个车站。将点单较少的站点过滤了,最终留下订单最多的250个站点。
·NYCBike:包含纽约市人们每天使用的共享自行车订单记录。交易时间为2016年4月1日至2016年4月至6月30日共91天。数据集包含以下信息:自行车驱车点,自行车落车点,自行车取车时间,自行车落车时间,行程持续时间等。NYC Taxi数据集是无站式的,这类交通运输往往没有固定的车站,旅客达到离开的地点是离散的。但他们通常聚集在特定的地方。对于无站点式交通运输,采用基于密度峰值聚类(DPC)的方法,最终构造出266个虚拟车站。
预处理后,两个数据集的时间戳均为0.5小时。每个站点的特征维数D为2,分别为上车需求和下车需求。
How Can Large Language Models Understand Spatial-Temporal Data?
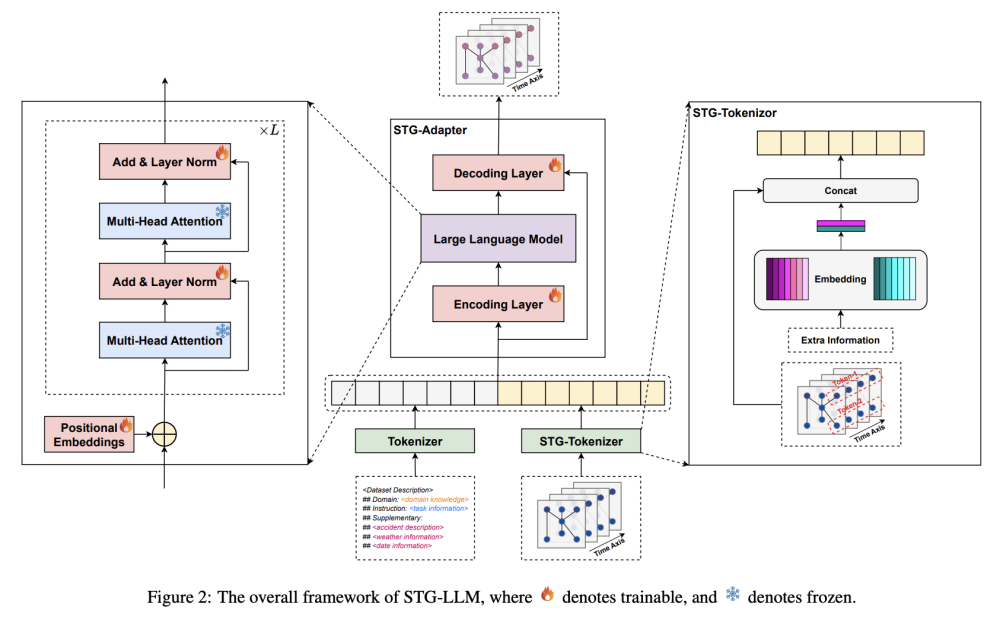
·提出 STG-LLM 方法,设计了一个时空图分词器(STG-Tokenizer),可以将时空数据转换为后来可以被LLM理解的标记。提出了一个时空图适配器(STG-Adapter),通过微调少量参数使LLM理解标记的语义。
·将文本分词器从提示生成的标记Tp和STG-Tokenizer从时空数据生成的标记Tq结合作为输入,其中Tg 是时空数据的 token,Etd 是 time-of-day embedding,Edw 是 day-of-week embedding。
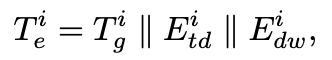
·多头注意力模块可以有效地捕捉标记之间的空间语义,而前馈模块可以有效地捕捉每个标记内的时间语义。为了保留LLMs原有的自然语言理解能力并减少微调的成本,选择在微调时冻结多头注意力模块和前馈模块。为了增强LLMs捕捉时空依赖性的能力,选择对位置嵌入和层归一化层进行微调。
两篇文章的做法都是手工提取特征,再输入 LLM 进行微调,提特征的方式与交通预测密切相关,不适用于营销场景。
2.4 动态图+LLM
WWW 24 On the Feasibility of Simple Transformer for Dynamic Graph Modeling
本文的方法属于处理 CTDG 中的时间感知加权模型。本文利用 Transformer 处理动态图。Transformer 架构具有两大优势:(时域层面)自然支持连续数据序列,无需离散快照;(空域层面)自注意力机制有助于捕捉长期依赖关系。
挑战及对策
保留历史演变的计算成本问题:由于自注意力机制的计算成本较高,现有基于 Transformer 的图模型仅适用于小型图,限制了对大型动态图的处理。我们引入一种新颖的策略,将每个节点的历史交互图看作 ego graph,大幅减小计算成本并保留完整的动态交互历史。通过将 ego graph tokenize 为适用于 Transformer 输入的序列,我们实现了对整个时间线的信息保留,无需修改原始 Transformer 架构。
输入序列之间的时间信息对齐问题:在动态图中,不同 ego 节点的输入序列享有一个共同的时间域, 然而在语言建模或静态图的序列中缺乏这样的通用时间域,在很大程度上可以将它们视为相互独立的。如果不对原始序列进行时间上的对齐,将无法区分不同时间间隔和频率信息。为了解决这一挑战,我们精心设计了特殊的时间 token,并将其整合到输入序列中,在实现全局对齐的同时,每个节点的局部序列仍然保留着时间顺序。
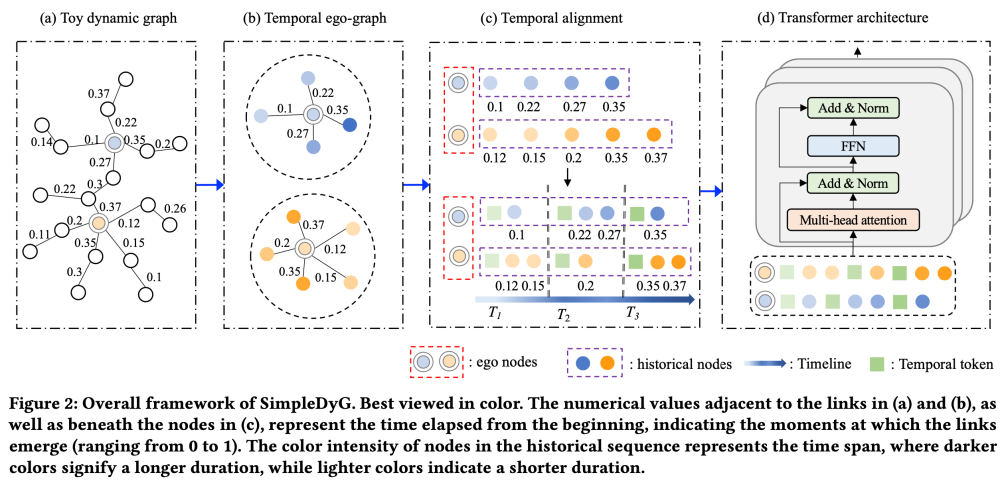
做法:首先,针对每个节点,提取以其为中心的时序 ego-graph,涵盖整个历史交互(见图 2(b)),将提取的 ego-graph 转换为序列,同时保留时间顺序。
其次,为了在不同 ego-graph 之间实现时间对齐,将时间线划分为具有相同时间间隔的跨度,如图 2(c) 所示。在 ego 序列中添加特殊的时间 token,使模型能够识别不同时间跨度。
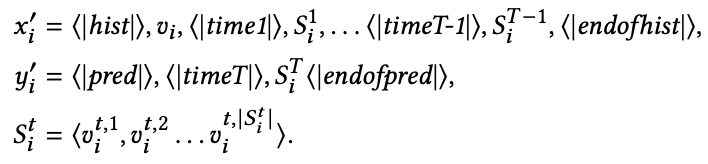
最后,将处理后的序列输入到 Transformer 架构中,用于执行各种下游任务。
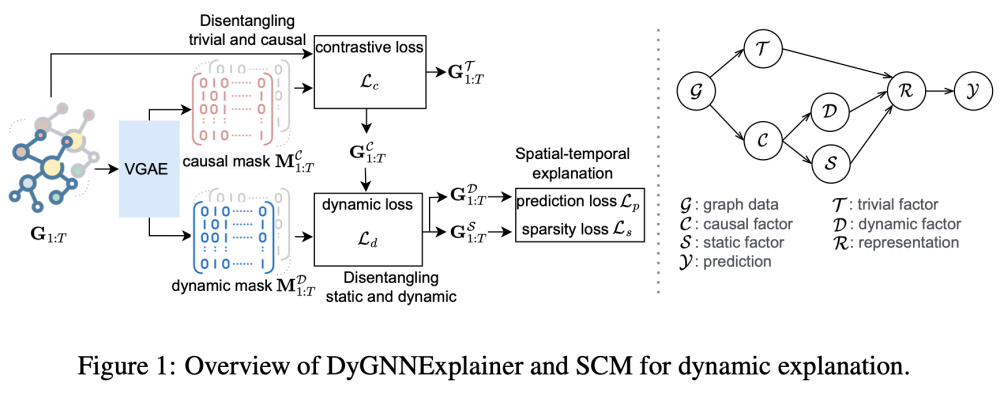
ICLR2024 Causality-Inspired Spatial-Temporal Explanations for Dynamic Graph Neural Networks
We propose an innovative causality-inspired generative model based on structural causal model (SCM), which explores the underlying philosophies of DyGNN predictions by identifying the trivial, static, and dynamic causal relationships.
1.disentangling the complex causal relationships,
2.fitting the spatial-temporal explanations of DyGNNs in the SCM architecture.
TMLR2024 Causal Reasoning and Large Language Models- Opening a New Frontier for Causality
CIKM 24 DTFormer: A Transformer-Based Method for Discrete-Time Dynamic Graph Representation Learning
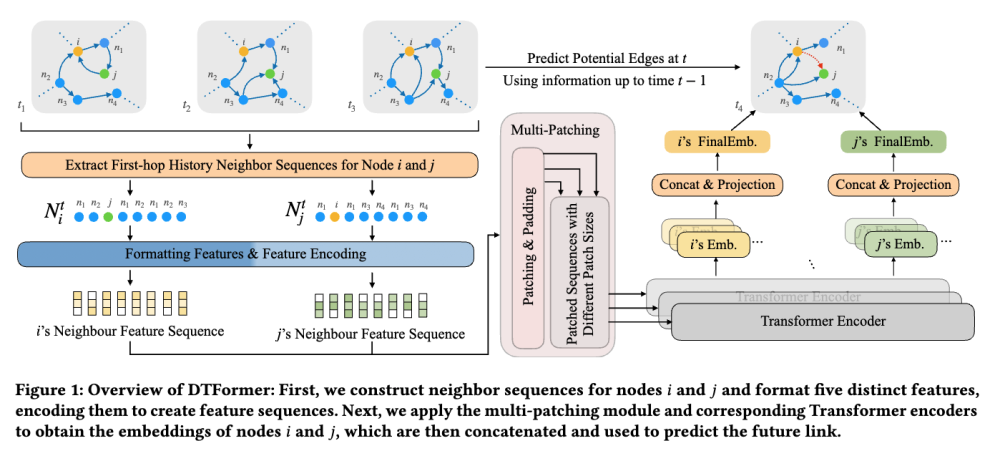
·处理离散时间动态图(DTDG)
·DTDGs中学习表示的先前方法主要采用GNN+RNN架构。GNNs面临的一个重大挑战是过平滑;RNNs常常难以捕获节点级别的长期依赖关系。
·本文提出DTFormer,从常用的GNN+RNN架构转向Transformer的架构,同时捕获时间动态和节点特定信息。首先收集希望预测未来链接的两个节点的所有历史一级邻居,然后将这些邻居的特征组织成序列给 Transformer,其中涉及五种特征:节点特征、边特征、时间快照、在给定快照中的出现频率,作为邻居在快照中的联合出现次数。最后,使用注意力机制聚合这些序列以推导节点的综合表示。
·Transformer的自注意力机制使模型能够更有效地关注相关节点,有助于缓解过平滑问题。此外,文章引入多补丁模块,有效地捕获长期和短期模式,同时减少内存空间。
2.5 User-Item图+LLM
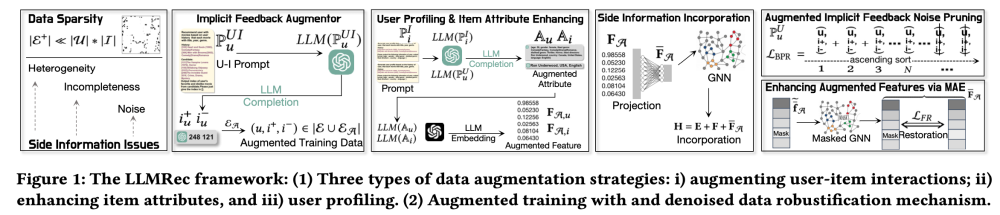
WSDM2024 oral LLMRec- Large Language Models with Graph Augmentation for Recommendation
针对推荐系统数据稀疏的问题,利用大模型进行数据增强
1.reinforcing user-item interaction edge
2.enhancing the understanding of item node attributes
3.conducting user node profiling
DynLLM: When Large Language Models Meet Dynamic Graph Recommendation
离散时间动态图(DTDGs)的一个重要挑战是如何选择最佳时间间隔,尤其是在处理大规模动态图。为了更全面地整合细粒度时间信息和拓扑图结构,引入了连续时间动态图的范式。一些工作引入功能时间编码技术和时间注意力机制,以细化细粒度时间信息的表示并聚合时间图上下文中的相邻节点消息,从而在CTDGs中取得了改进。
尽管有这些改进,静态和动态图推荐中的数据稀疏性和有限可解释性等挑战仍然存在。LLMs通过提供丰富的语言生成能力来增强推荐,有助于解决数据稀疏性并提高可解释性。遗憾的是,LLMs可能无法直接应用于动态图推荐任务,因为它们缺乏对时间信息的显式建模。
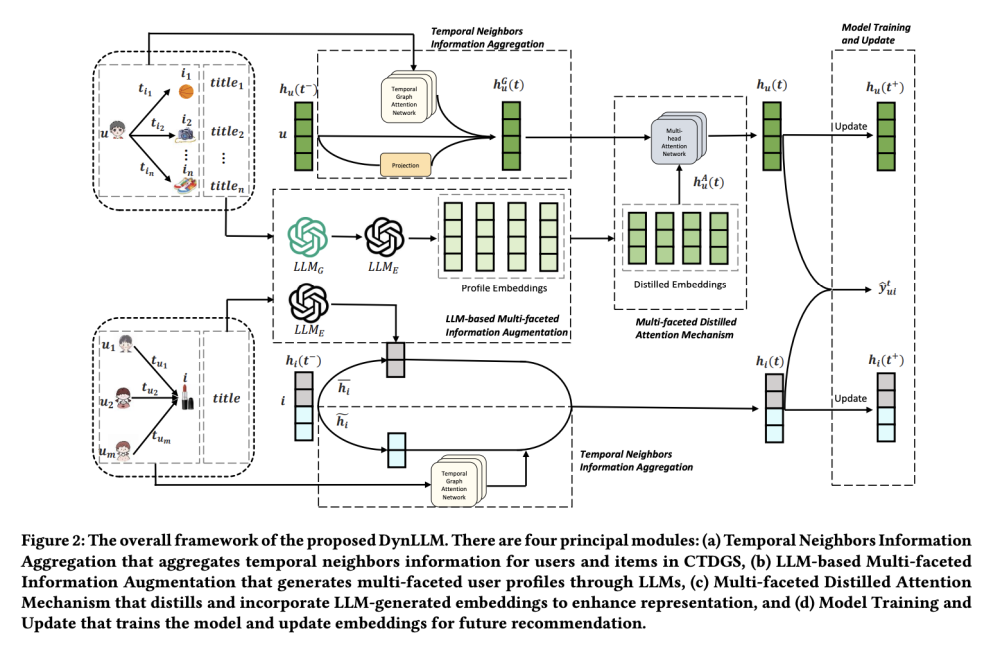
·时间邻居信息聚合:使用时间图注意力网络(TGANs)来细致地聚合CTDGs中用户和项目的时间邻居信息。
·基于LLM的多方面信息增强:利用LLMs通过历史购买项目的文本标题构建多方面用户画像,这些画像包括人群细分、个人兴趣、偏好类别和喜爱品牌等多个维度,从而从多方面角度丰富用户表示。
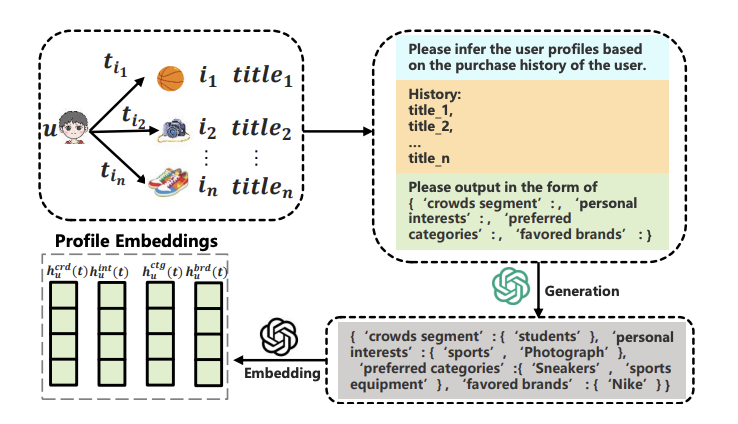
·多方面蒸馏注意力机制:引入了一种新颖的多方面蒸馏注意力机制。该机制负责蒸馏从LLMs中获得的多方面画像嵌入,确保减少生成噪声并增强信号相关性。
·模型训练与更新。用户嵌入和项目嵌入被混合用于预测,并通过门控循环单元(GRU)更新器进行更新,为下一次推荐做准备。
2.6 KBQA+LLM
NIPS2024 Plan-on-Graph- Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs
任务类型:KGQA,大模型存在的一些问题
1.out-of-date knowledge
2.hallucinations
3.opaque decision-making
知识图谱可以提供explicit and editable konwledge帮助大模型缓解上述问题
plan the adaptive breadth of reasoning paths,reflect to self-correct erroneous paths
1.Guidance
2.Memory
3.Reflection
知识图谱和大模型结合的几种方式
1.integrate kgs into llm pre-training or fine-tuning stage
2.retrieve information from kgs and deliver explicit knowledge into llms
3.treat llm as an agent to conduct graph reasoning or explore related entities and relations on kg
ICLR2024 Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph
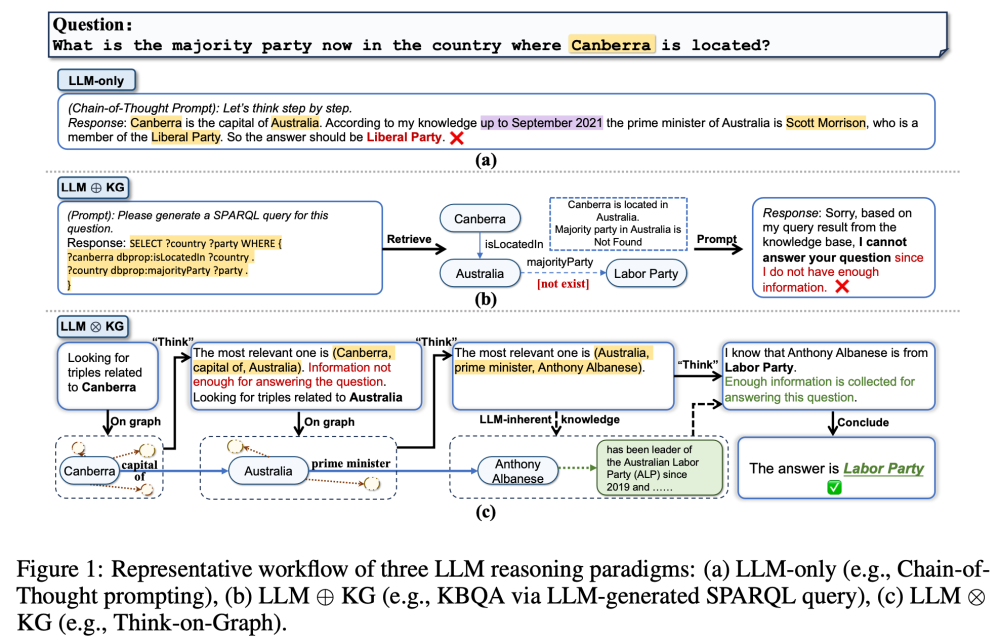
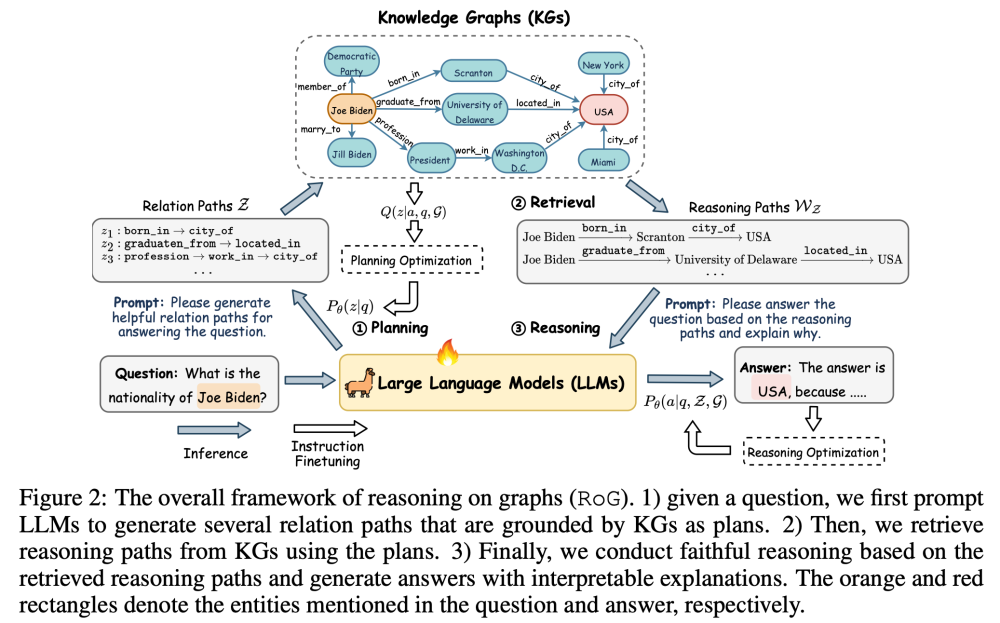
ICLR2024 Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning
ICML2024 KNOWFORMER- Revisiting Transformers for Knowledge Graph Reasoning
知识图谱推理,主要任务是链接预测,使用transform结构来进行图推理
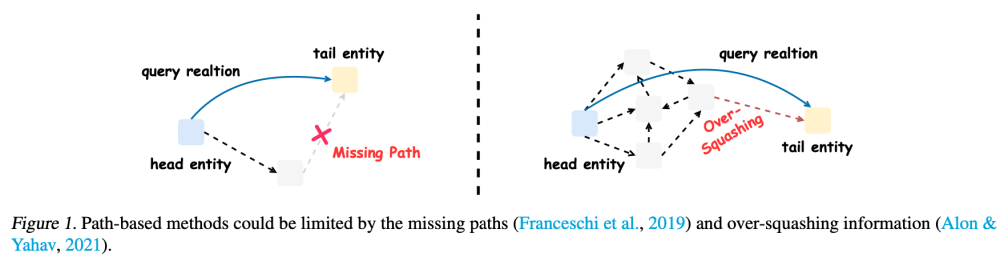
ACL2023 Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
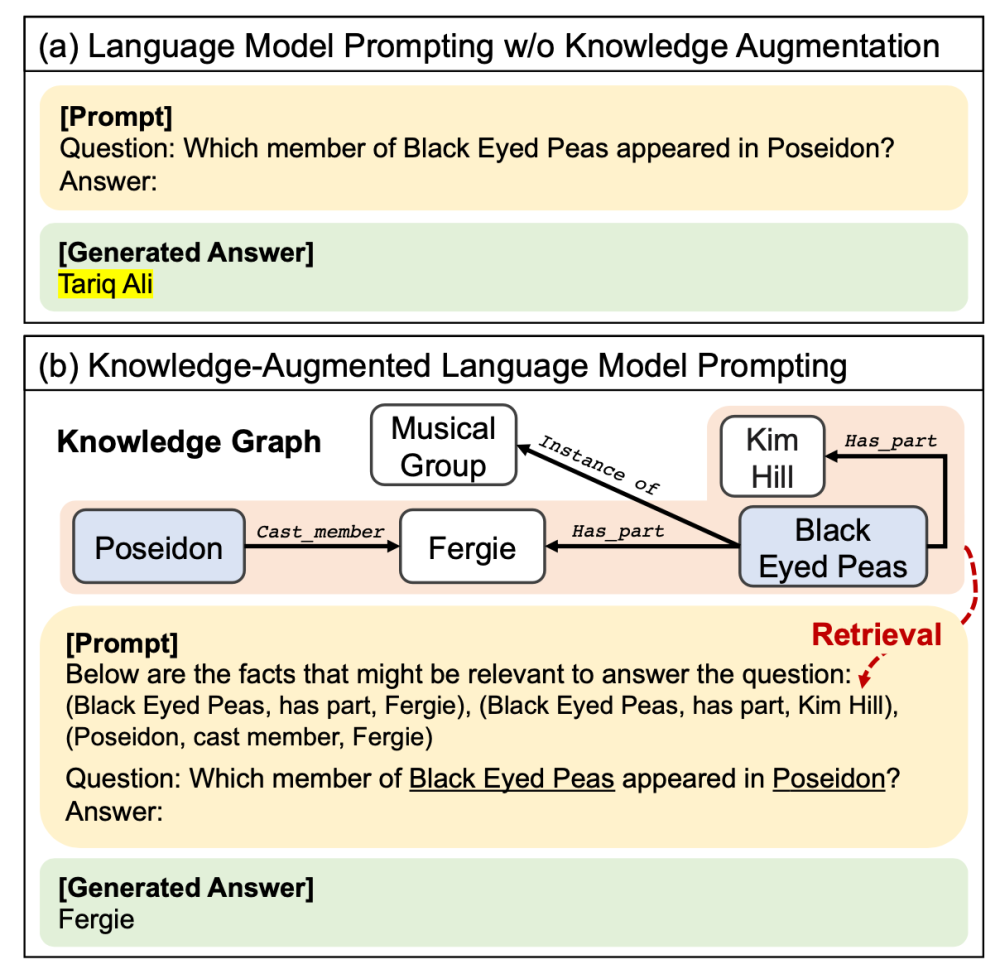
ICLR2024 Talk like a Graph- Encoding Graphs for Large Language Models
Despite the remarkable progress in automated reasoning with natural text, reasoning on graphs with large language models (LLMs) remains an understudied problem.
本文的核心:设计了针对图的prompt,借助大模型在图上进行推理reasoning on graphs
2.7 图结构对齐LLM表征
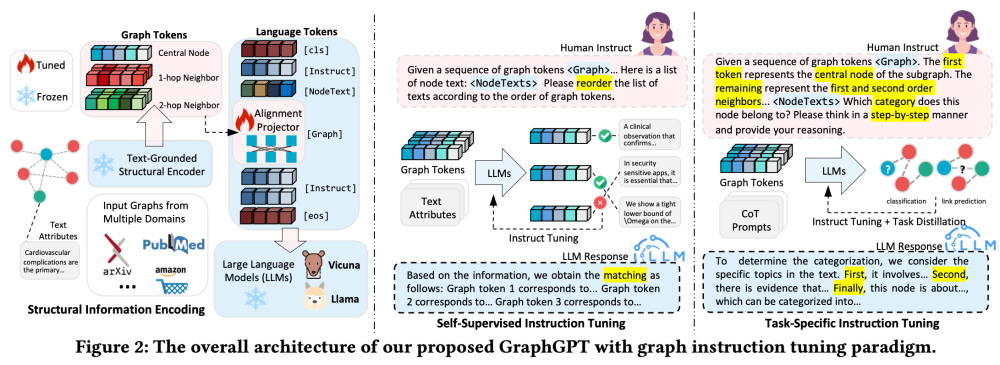
SIGIR2024 Graphgpt: Graph instruction tuning for large language models
https://github.com/HKUDS/GraphGPT ,代码框架很复杂
advancing graph model generalization in zero-shot learning environments,graph instruction tuning
1.a text-graph grounding component to link textual and graph structures
2.a dual-stage instruction tuning approach with a lightweight graph-text alignment projector
目前的GNN方法比较依赖于标签信息\监督信号,尤其是在下游任务中,需要使用监督信号微调,图模型的泛化能力受限。但是,大模型在nlp中表现了强的泛化能力,本文便考虑整合 大语言模型 到 图学习任务中,来提高图模型的泛化能力。挑战在于
1.如何有效引导LLM理解Graph structural information;
2.实线Graph structural information和language space空间上的对齐。

上面例子表明,如果仅仅将text-based graph structure扔给大模型来理解,不仅效果差而且prompt token过长。
核心的问题:如何有效的graph structural information并入到LLM学习中?
指示学习instruction learning是为了加强大模型在特定领域的适应性,本文目的是为了让llm对齐图学习任务。
Graph Tokens的获取,设计了两个指示微调的任务
1.self-supervised instruction tuning
2.task-specific instruction tuning
指令微调过程中,大模型都是冻结住的,针对graph tokens设计了一个alignment projector(mlp)
NIPS2024 LLMs as Zero-shot Graph Learners- Alignment of GNN Representations with LLM Token Embeddings
https://github.com/W-rudder/TEA-GLM,代码较简单,复现可行性高
图和大模型结合的几种方案
1.encode graph structures into text for LLM input
2.using LLMs as enhancers to generate data or node text representation for GNN prediction
3.recent efforts to user LLMs as predictors have demonstrated potential
本文指出图学习的方法,例如
1.self-supervised learning or graph prompt learning
都比较依赖fine-tuning with task-specific labels,限制了他们在zero-shot场景的有效性。
本方案的核心思想是pretrain a GNN将其的表征和the token embeddings of an LLM对齐(利用the zero-shot capabilities of instruction-fine-tuned LLMss)
设计了一个可学习的Linear Projector来学习得到Graph token embedding,接入到LLM进行预测
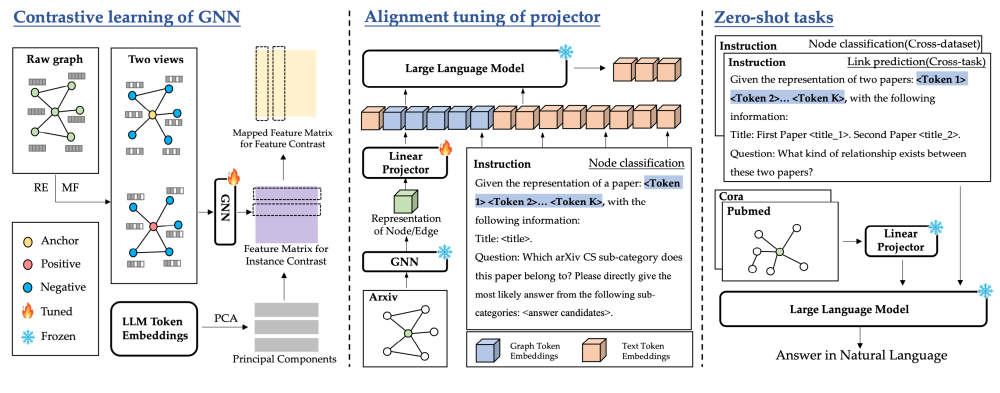
模型架构两个主要的部分
1.a Graph Neural Network to derive node representations from the graph
2.a Large Language Model to perform zero-shot tasks such as node classification and lp
第一部分的图学习使用了两个自监督的信号(实例级别、特征级别)
1.instance-wise contrastive learning with structural information
2.feature-wise contrastive learning with token embeddings
特征级别的对比学习使用了LLM产生的token embedding,有效的address the semantic space discrepancy between graph node representation and LLM token embeddings.
第二部分大模型for cross-data 多种任务,主要两个设计
1.instruction prompt的设计
2.graph token embedding(a linear projector获取,llm fix)
最终通过两阶段训练后的模型,具备cross-dataset zero-shot learning的能力。
ICML2024 LLaGA: Large Language and Graph Assistant
本文指出了图学习的缺陷是在多任务处理上的弱势,自监督有一定作用但仍然需要做task-specfic heads or tuing for downstream tasks。试图提高 图模型的泛化能力。
核心目的:大模型如何处理结构化的图数据Graph-Structured Data,如何将图数据格式与LLM输入兼容
1.指出了如果简单的describing graphs in plain texts tends to be verbose and fails to represent the intrinsic characteristics of graphs
核心问题
1.How to develop a framework that effectively encodes structural information for graphs across various tasks and domains enabling its comprehension by LLMs, while maintaining LLM's general-purpose.
LLaGA achieves this by reorganizing graph nodes to structure-aware sequences and then mapping these into the token embedding space through a versatile projector.
1.node sequences,node-lebel templates
2.versatile projectors,(node sequence -> token embedding sequence)使用多种图任务微调
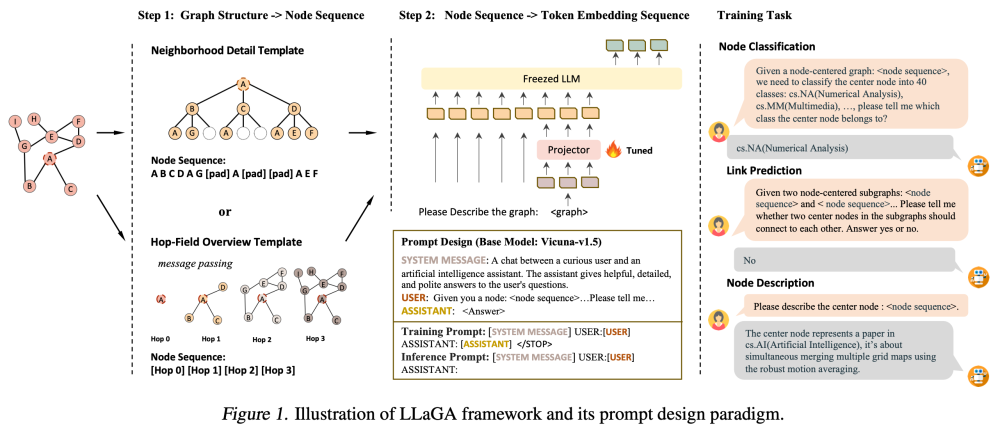
训练任务使用的都是QA-format,所以需要整理特定的训练数据,共设计了三种任务
1.node classification
2.link prediction
3.node description
本文主要创新点体现在两个方面,一个是将graph structure表示成了node sequence丢给LLM
1.neighborhodd detail template
2.hop-field overview template
第二点在于设计了三种question-answer的训练任务prompt设计。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









