






回顾了近900个最受欢迎的开源AI LLM工具(keyword:llm/gpt/generative ai,star:500+),从中分析得到了一些意外、有益的结论:
截止8月3日,累计952个最受欢迎的开源AI工具,托管在llama-polic,更新/6小时
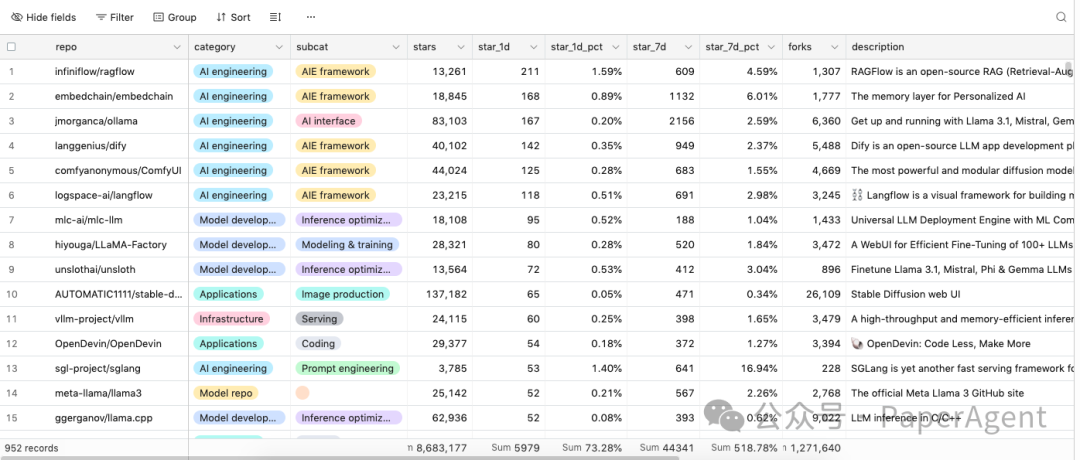
-
AI技术栈分为三层:基础设施、模型开发和应用开发。
-
2023年,特别是Stable Diffusion和ChatGPT引入后,新工具的数量激增。
-
2023年是AI工程的一年,出现了多种工具和框架。
-
模型开发在ChatGPT之前占主导地位,2023年对推理优化、评估和参数高效微调的兴趣增加。
-
基础设施层相对稳定,尽管引入了向量数据库等新类别。
-
开源AI开发者遵循长尾分布,少数账户控制着大部分仓库。
-
中国的开源生态系统正在增长,许多流行的AI仓库针对中国受众。
-
许多仓库迅速获得关注然后迅速沉寂,称之为“炒作曲线(hype curve)”。
数据
使用关键词gpt、llm和generative ai在GitHub上进行了搜索。如果AI现在感觉如此压倒性,那是因为它确实是。仅gpt就有118K的结果。
将搜索限制在至少有500颗星的仓库。llm有590个结果,gpt有531个,generative ai有38个。也偶尔检查GitHub趋势和社交媒体上的新仓库。
经过许多小时,找到了896个仓库。其中,51个是教程(例如dair-ai/Prompt-Engineering-Guide)和聚合列表(例如f/awesome-chatgpt-prompts)。最终分析是使用845个软件仓库进行的。
这是一个痛苦但有回报的过程。更好地了解了人们正在做什么,开源社区的协作程度等等。
The New AI Stack
AI技术栈由三层组成:基础设施、模型开发和应用开发。

1. Infrastructure
在技术栈的最底层是基础设施,包括服务工具(vllm, NVIDIA的Triton)、计算管理(skypilot)、向量搜索和数据库(faiss, milvus, qdrant, lancedb)等。
2.Model development
这一层提供开发模型的工具,包括建模和训练框架(transformers, pytorch, DeepSpeed)、推理优化(ggml, openai/triton)、数据集工程、评估等。任何涉及改变模型权重的事情都发生在这一层,包括微调。
3. Application development
有了现成的模型,任何人都可以在它们的基础上开发应用程序。这是在过去两年中动作最多的一层,并且仍在快速发展。这一层也被称为AI工程。
应用开发涉及提示工程、RAG、AI接口等。
在这三个层次之外,还有另外两个类别:
-
Model repos,由公司和研究人员创建,用于分享与他们的模型相关的代码。这一类别的仓库示例包括CompVis/stable-diffusion、openai/whisper和facebookresearch/llama。
-
基于现有模型构建的应用程序。最受欢迎的应用程序类型是编码、工作流程自动化、信息聚合等。
AI stack over time
绘制了每个月每个类别仓库数量的累积图。在Stable Diffusion和ChatGPT引入后的2023年,新工具的数量爆炸性增长。曲线在2023年9月似乎趋于平缓,可能有以下三个原因。
-
只在分析中包括至少有500颗星的仓库,而仓库获得这么多星需要时间。
-
大多数容易摘取的果实已经被摘取。剩下的需要更多的努力去构建,因此能够构建它们的人更少。
-
人们意识到在生成性AI领域竞争很难,所以兴奋情绪已经平息。从传闻来看,在2023年初,所有AI对话都围绕着生成性AI,但最近的对话更加务实。一些甚至提到了scikit-learn。
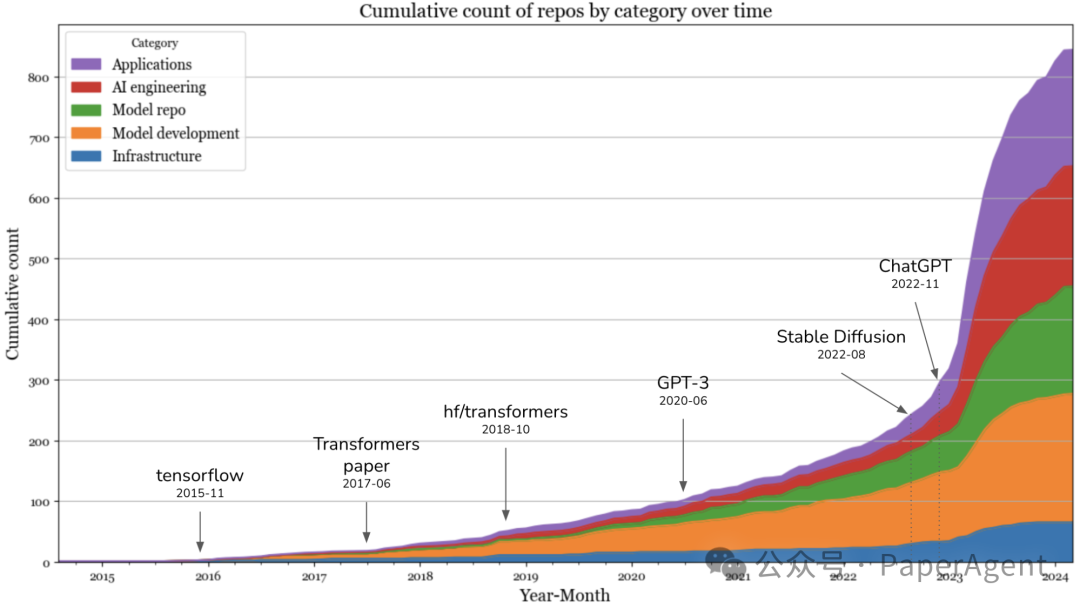
在2023年,应用和应用开发层的增长最高。基础设施层也有一些增长,但远远没有达到其他层的增长水平。
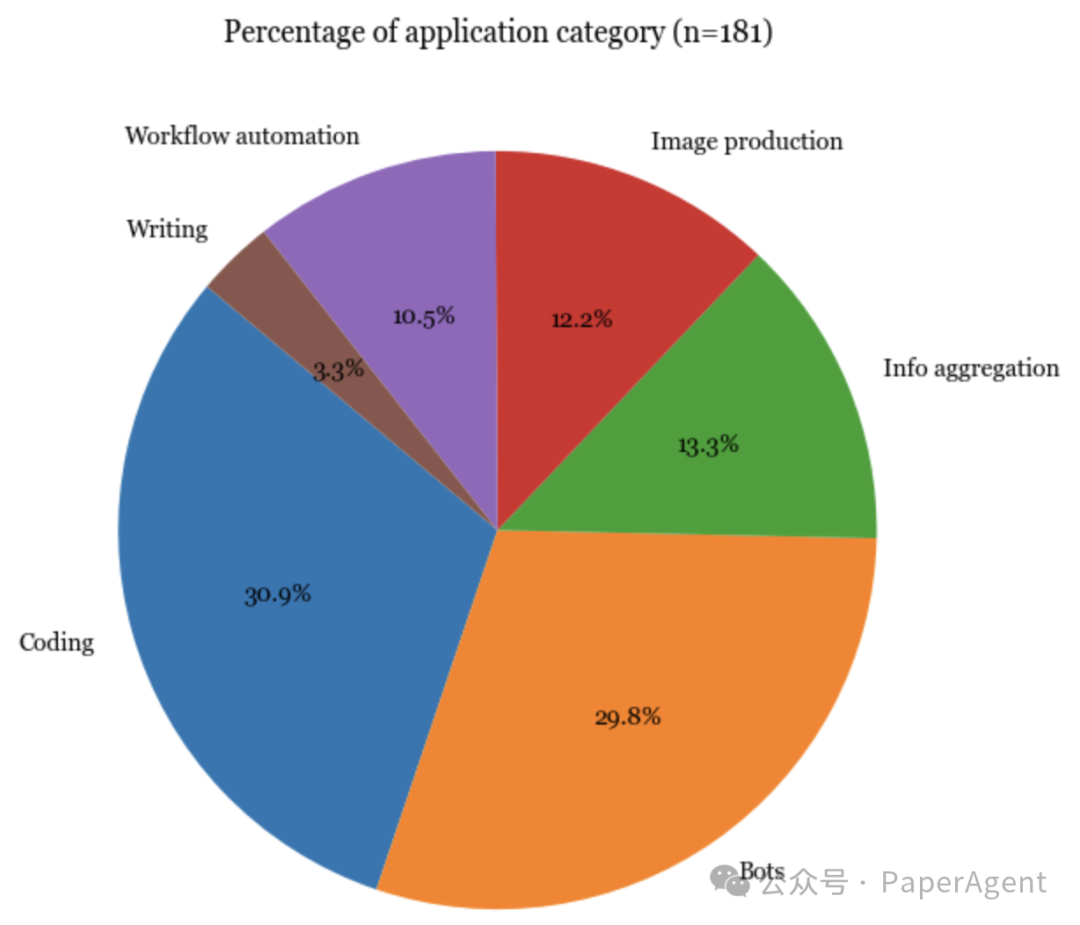
应用
毫不奇怪,最受欢迎的应用程序类型是编码、机器人(例如角色扮演、WhatsApp机器人、Slack机器人)和信息聚合(例如“让我们将其连接到我们的Slack并要求它每天总结消息”)。
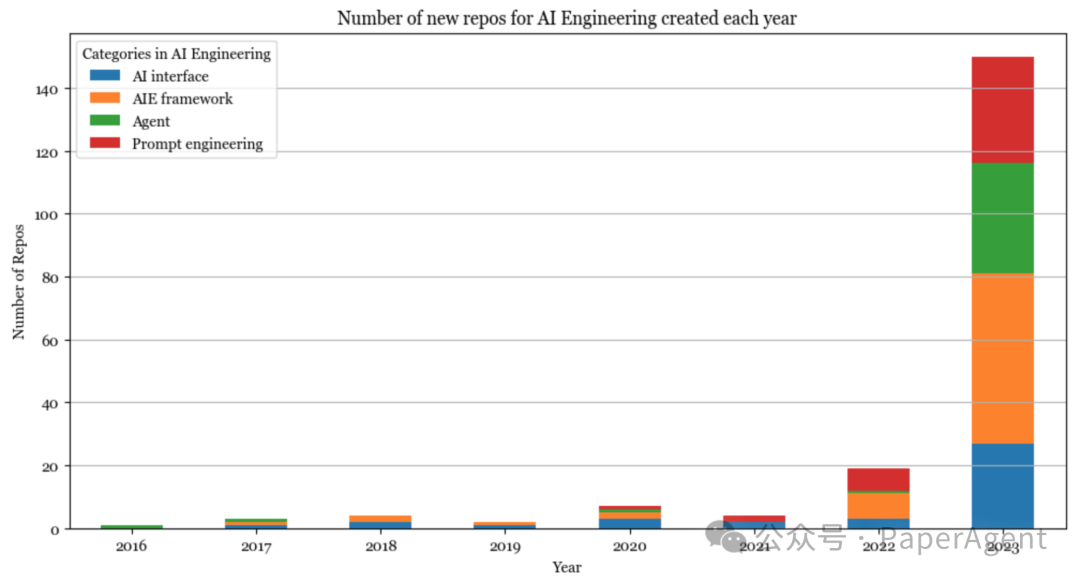
AI工程
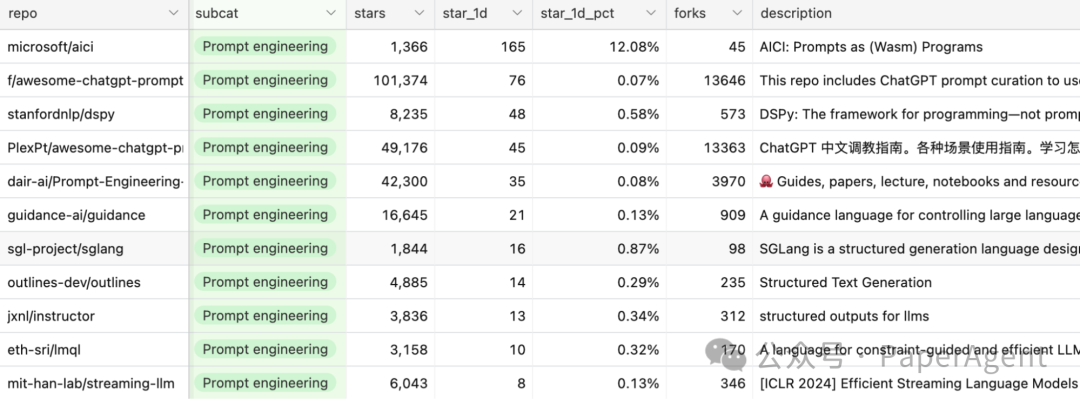
2023年是AI工程的一年。由于它们中的许多非常相似,因此很难对工具进行分类。目前将它们归入以下类别:提示工程、AI界面、代理和AI工程(AIE)框架。
提示工程远远超出了调整提示的范畴,涵盖了诸如约束抽样(结构化输出)、长期记忆管理、提示测试和评估等。
AI界面为最终用户提供了一个与您的AI应用程序交互的界面。这是最让人兴奋的类别。一些正在获得欢迎的界面包括:
-
网络和桌面应用程序。
-
允许用户在浏览时快速查询AI模型的浏览器扩展。
-
通过Slack、Discord、微信和WhatsApp等聊天应用程序的机器人。
-
允许开发人员将AI应用程序嵌入到VSCode、Shopify和Microsoft Office等应用程序的插件。插件方法对于可以使用工具完成复杂任务的AI应用程序(代理)来说很常见。
AIE框架是一个涵盖所有帮助您开发AI应用程序的平台的总称。它们中的许多都是围绕RAG构建的,但它们也提供了其他工具,如监控、评估等。
Agent是一个奇怪的类别,因为许多Agent工具只是复杂的提示工程,可能具有约束生成(例如,模型只能输出预定的操作)和插件集成(例如,让智能体使用工具)。
模型开发
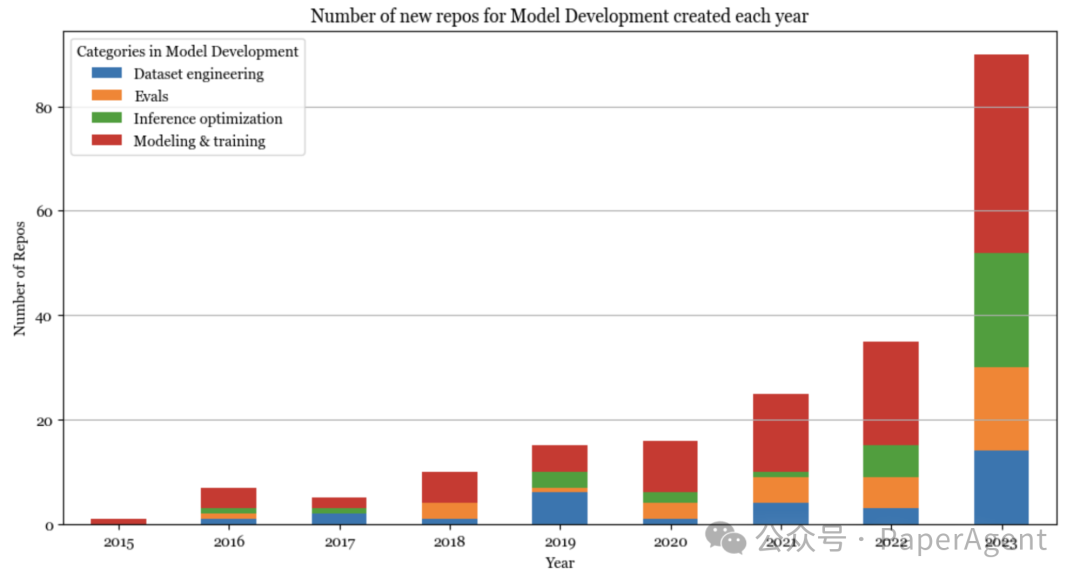
在ChatGPT之前,AI技术栈由模型开发主导。模型开发在2023年的最大增长来自于**对推理优化、评估和参数高效微调(归入建模和训练)**的日益增长的兴趣。
推理优化一直很重要,但如今基础模型的规模使其对延迟和成本至关重要。优化的核心方法保持不变(量化、低秩分解、剪枝、蒸馏),但许多新技术特别是针对变换器架构和新一代硬件已经开发出来。例如,在2020年,16位量化被认为是最先进的。今天,我们看到了2位量化甚至低于2位的量化。
同样,评估一直很重要,但随着许多人将模型视为黑箱,评估变得更加重要。有许多新的评估基准和评估方法,如比较评估(见Chatbot Arena)和AI作为评委。
基础设施
基础设施是关于管理数据、计算和服务于监控和其他平台工作的工具。尽管生成性AI带来了所有变化,开源AI基础设施层基本上保持不变。这也可能是因为基础设施产品通常不是开源的。
这一层的最新类别是向量数据库,有像Qdrant、Pinecone和LanceDB这样的公司。然而,许多人认为这根本就不应该成为一个类别。向量搜索已经存在很长时间了。与其为向量搜索构建新数据库,现有的数据库公司如DataStax和Redis正在将向量搜索引入数据已经存在的地方。
开源AI开发者
开源软件,像许多事物一样,遵循长尾分布。少数账户控制着大部分仓库。
一个人的十亿美元公司?
845个仓库托管在594个独特的GitHub账户上。有20个账户至少有4个仓库。这些前20个账户托管了195个仓库,或者说是列表上所有仓库的23%。这195个仓库总共获得了1,650,000颗星。
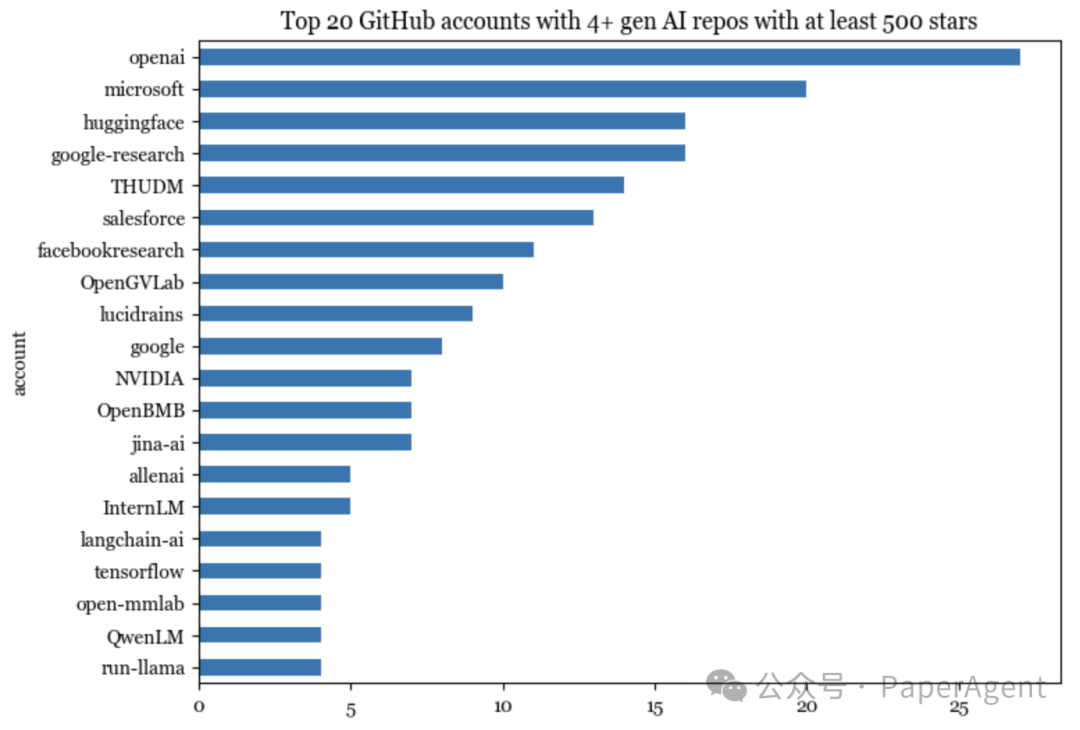
在GitHub上,一个账户可以是组织或个人。前20个账户中有19个是组织。其中,3个属于Google:google-research、google、tensorflow。
在这些前20个账户中,唯一的个人账户是lucidrains。在拥有最多星的前20个账户中(仅计算生成AI仓库),有4个是个人账户:
-
lucidrains(Phil Wang):能够以惊人的速度实现最先进的模型。
-
ggerganov(Georgi Gerganov):一个来自物理背景的优化之神。
-
Illyasviel(Lyumin Zhang):Foocus和ControlNet的创造者,目前是斯坦福大学的博士生。
-
xtekky:一个全栈开发者,创建了gpt4free。
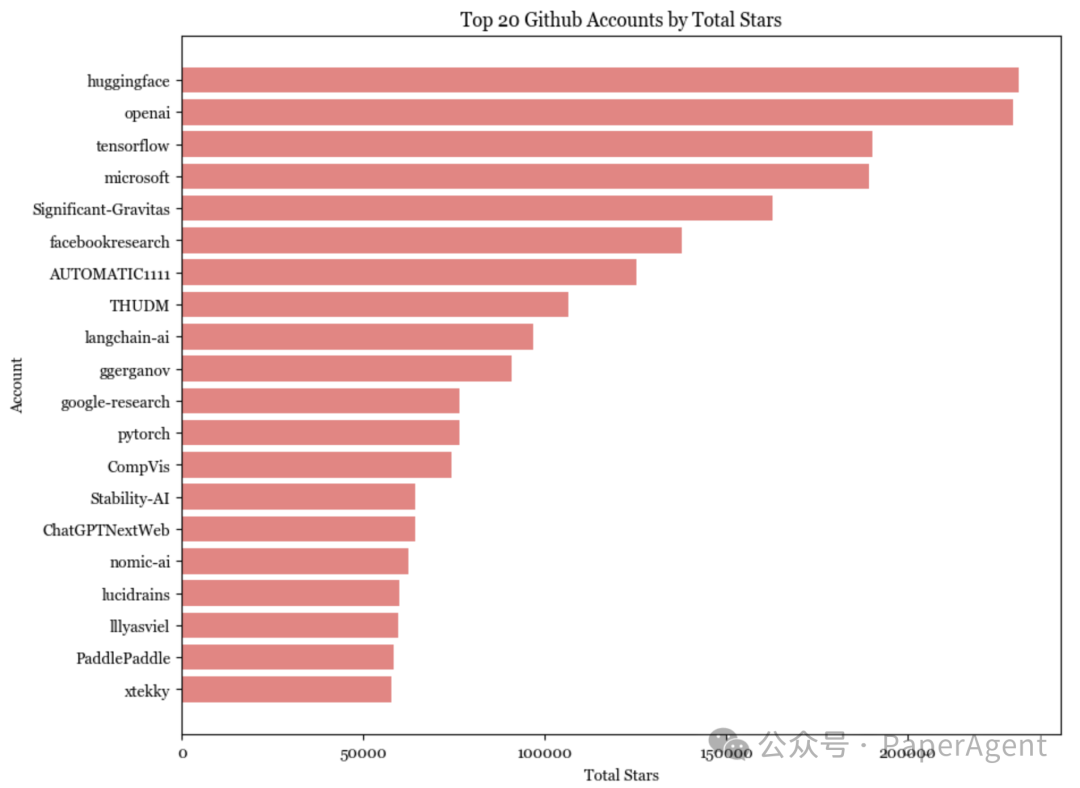
毫不奇怪,在技术栈中越往下走,个人构建就越难。基础设施层的软件最不可能由个人账户启动和托管,而超过一半的应用是由个人托管的。
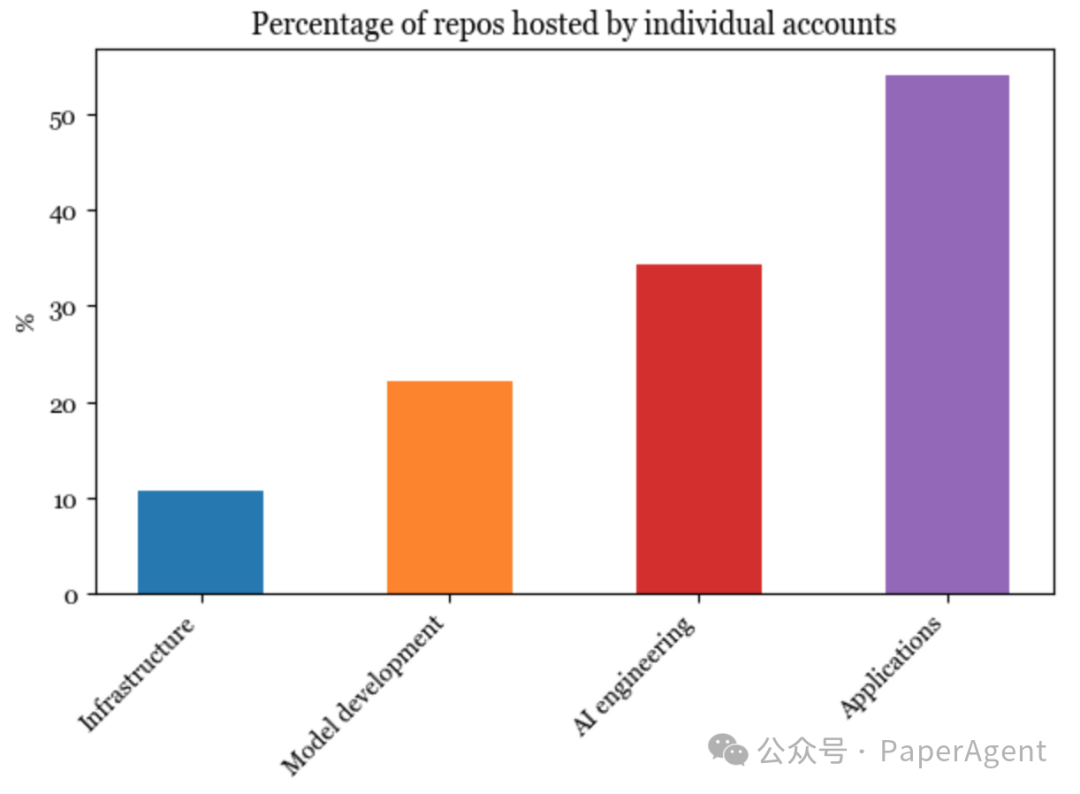
由个人启动的应用平均获得了比由组织启动的应用更多的星。一些人推测我们将看到许多非常有价值的一个人的公司(见Sam Altman的采访和Reddit讨论)。
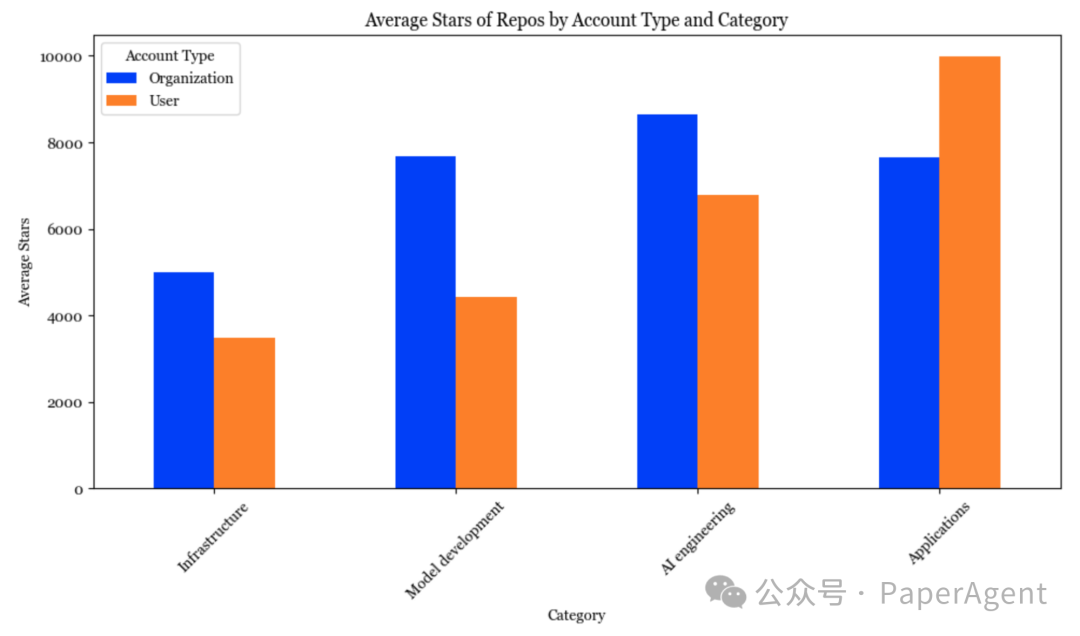
100万次提交
超过20,000名开发者为这845个仓库做出了贡献。他们总共做出了近100万次贡献!
其中,最活跃的50名开发者做出了超过100,000次提交,平均每人超过2,000次提交。在这里查看前50名最活跃的开源开发者的完整列表。
中国开源生态系统的增长
有许多、许多针对中国受众的流行AI仓库在GitHub上,它们的描述是用中文写的。有为中国或中英开发的模型仓库,如Qwen、ChatGLM3、Chinese-LLaMA。
虽然在美国,许多研究实验室已经放弃了语言模型的RNN架构,但基于RNN的模型家族RWKV仍然很受欢迎。
还有AI工程工具提供了将AI模型集成到中国流行的产品中的方法,如微信、QQ、钉钉等。许多流行的提示工程工具也有中文镜像。
在GitHub上前20个账户中,有6个起源于中国:
-
THUDM:清华大学的知识工程组(KEG)和数据挖掘。
-
OpenGVLab:上海AI实验室的通用视觉团队。
-
OpenBMB:由ModelBest和清华大学的NLP组共同创立的大型模型基础开放实验室。
-
InternLM:来自上海AI实验室。
-
OpenMMLab:来自香港中文大学。
-
QwenLM:阿里巴巴的AI实验室,发布了Qwen模型家族。
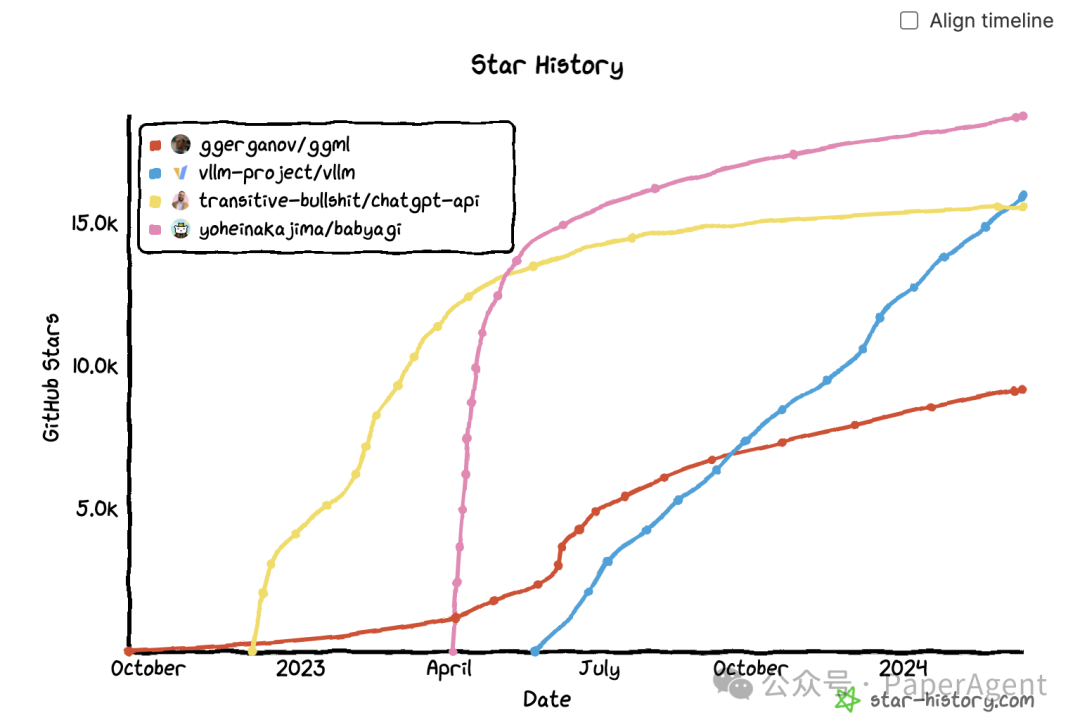
快速生活,快速死亡
去年观察到的一个模式是,许多仓库迅速获得了大量关注,然后迅速沉寂下来,称之为“炒作曲线(hype curve)”。在这些至少有500个GitHub星的845个仓库中,有158个仓库(18.8%)在过去24小时内没有获得任何新星,37个仓库(4.5%)在过去一周内没有获得任何新星。
以下是两个这样的仓库增长轨迹的例子,与两个更持久的软件增长曲线相比较。尽管这里展示的两个例子已经不再使用,但它们在向社区展示可能性方面很有价值,作者能够如此迅速地推出这些项目也很棒。
项目推荐
社区正在开发如此多的酷炫想法。以下是一些不错的项目推荐:
-
批量推理优化:FlexGen, llama.cpp
-
使用Medusa、LookaheadDecoding等技术的更快解码器
-
模型合并:mergekit
-
约束抽样:outlines, guidance, SGLang
-
看似小众但解决单一问题非常出色的工具,例如einops和safetensors。
900 AI tools https://huyenchip.com/llama-police``https://huyenchip.com/2024/03/14/ai-oss.html
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享]👈

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享👈


本文转自 https://blog.csdn.net/lhx17673139267/article/details/140918702?spm=1001.2014.3001.5501,如有侵权,请联系删除。















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









