







在学会基本的爬虫操作后,网页抓取之路并不顺畅,因为js的盛行,现在大多数数据都被加密了,遂开始了逆向的学习。这篇文章分享我自己实操的第一个案例,教程可以参考b站教学
首先观察页面https://www.qimingpian.com/innovate
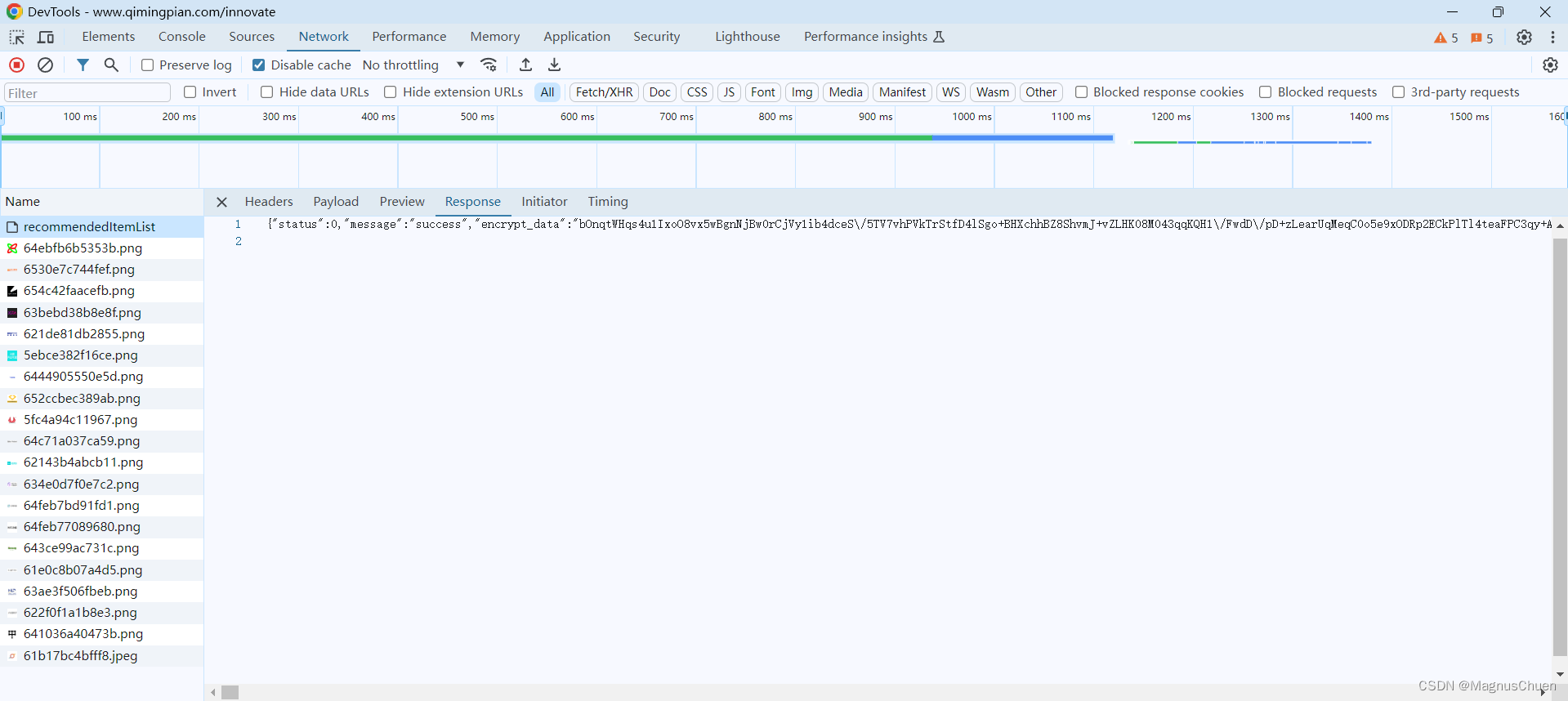 在点击加载更多之后注意到recommendeditemlist这个包,点击预览可以看到其中encrypt_data这个数据,这个就是加密过后的企业数据。
在点击加载更多之后注意到recommendeditemlist这个包,点击预览可以看到其中encrypt_data这个数据,这个就是加密过后的企业数据。
使用post请求可以得到一样的结果:
import requests
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'content-type': 'application/x-www-form-urlencoded',
'origin': 'https://www.qimingpian.com',
'pragma': 'no-cache',
'priority': 'u=1, i',
'sec-ch-ua': '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









