






目录
2. 无监督学习(Unsupervised Learning)
3. 强化学习(Reinforcement Learning)
3. 线性变换(Linear Transformation)
5. 特征值 & 特征向量(Eigenvalues & Eigenvectors)
8. 正定矩阵(Positive Definite Matrix)
概率与统计(Probability & Statistics)
2. 条件概率(Conditional Probability)
4. 期望与方差(Expectation & Variance)
6. 中心极限定理(Central Limit Theorem)
机器学习概念笔记
- 模式识别与泛化
机器学习的核心目标是从数据中学习规律,并能够 泛化 到未见过的数据。无论是监督学习、无监督学习,还是强化学习,本质上都是在寻找数据中的模式并进行预测或决策。 - 概率与统计
机器学习很多方法都基于概率模型,比如朴素贝叶斯、隐马尔可夫模型、生成模型(如GAN、扩散模型)等。即使是深度学习,其优化过程也常涉及最大似然估计(MLE)或贝叶斯推断。因此,可以说概率是机器学习的基础之一。 - 优化与迭代
机器学习模型通常会定义一个目标函数(如损失函数),并通过 优化算法(如梯度下降、牛顿法等)进行迭代优化,以最小化误差,提高模型的预测能力。 - 数据驱动
机器学习的核心动力是数据,模型的能力取决于数据的质量、数量以及特征表示的方式。即使是相同的算法,在不同数据集上的表现可能会大相径庭。 - 函数逼近
本质上,机器学习可以看作是一个 从数据到函数的逼近过程。如神经网络通过不断调整参数来逼近一个复杂的非线性函数,使其能更好地映射输入到输出。
定义Definition
在机器学习中,主要有三种学习范式:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning),它们的主要区别在于数据是否带标签以及学习的目标。
1. 监督学习(Supervised Learning)
定义
监督学习是一种机器学习方法,训练数据包括输入(特征)和已知的标签(输出),模型通过学习输入与输出之间的映射关系,从而预测新数据的标签。目标是建立一个函数,将输入映射到输出。
任务类型
- 分类(Classification):输出为离散标签,通常用于分类问题。
- 示例:垃圾邮件识别(垃圾邮件/非垃圾邮件)、手写数字识别。
- 评价指标:准确率、精确率、召回率、F1分数、ROC曲线、AUC。
- 回归(Regression):输出为连续数值,通常用于预测任务。
- 示例:房价预测、股票价格预测。
- 评价指标:均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、R²。
常见算法
- 线性回归(Linear Regression):适用于线性关系的回归任务。
- 逻辑回归(Logistic Regression):适用于二分类问题,输出概率值。
- 决策树(Decision Tree):通过分裂特征来进行分类或回归。
- 支持向量机(SVM):适用于高维数据,能找到最优分类边界。
- 随机森林(Random Forest):由多棵决策树组成,抗过拟合能力强。
- K近邻算法(KNN):基于样本相似度进行分类或回归。
- 神经网络(Neural Networks):适用于复杂非线性任务,如图像分类、语音识别。
关键概念
- 特征工程:包括特征选择、特征提取和特征缩放(标准化、归一化),直接影响模型性能。
- 过拟合与欠拟合:过拟合是模型在训练集上表现好,但泛化能力差;欠拟合是模型过于简单,无法学习数据的模式。
- 正则化:如L1(Lasso)和L2(Ridge)正则化,可以防止过拟合。
应用
- 计算机视觉:图像分类、人脸识别。
- 自然语言处理:情感分析、文本分类。
- 医疗诊断:疾病预测、药物反应预测。
- 金融:信用评分、风险预测。
基础概念解释
- Logistic Function(逻辑回归函数)

- Sigmoid vs. Logistic Function

简单理解
Sigmoid 是一个数学函数,可以用于各种场景。
Logistic Function 是 Sigmoid 的应用,主要用于逻辑回归和二分类问题。
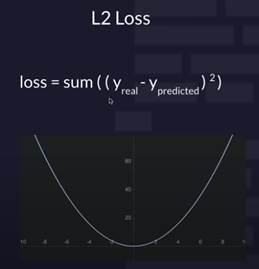
损失函数(Loss Function)概念
损失函数是机器学习中用于衡量模型预测与真实值之间差距的函数。它是优化过程中一个非常重要的组成部分,决定了模型学习的目标。通过最小化损失函数的值,模型能够在训练数据上找到最优的参数,从而提高其在新数据上的预测能力。
1. 损失函数的作用
- 衡量预测的准确性:损失函数用来计算模型预测的结果与实际标签(目标值)之间的误差。误差越小,模型的预测效果越好。
- 指导模型优化:在训练过程中,算法通过反向传播(或类似的优化方法)来最小化损失函数的值,从而提高模型的性能。
2. 损失函数的类型
根据任务的不同,损失函数可以有不同的形式:
2.1. 回归任务中的损失函数
回归任务的目标是预测一个连续的数值,因此常见的损失函数是:


3. 损失函数的选择
损失函数的选择通常取决于任务的性质:
- 回归问题:常使用MSE或MAE。
- 分类问题:使用交叉熵损失,尤其在神经网络中非常常见。
- 对抗性样本:在某些情况下,可能使用对抗损失来提高模型的鲁棒性。
4. 损失函数与优化
- 梯度下降(Gradient Descent):模型训练时,损失函数的梯度会被计算并用来调整模型参数,目标是通过最小化损失函数来使模型性能更好。常用的梯度下降优化方法包括随机梯度下降(SGD)、Adam、RMSprop等。
- 损失函数的微分:对于许多优化方法,损失函数必须是可微的,这样才能计算梯度并执行反向传播。
总结
损失函数在机器学习模型的训练过程中起着至关重要的作用,它量化了模型的预测误差,并通过最小化损失函数来调整模型的参数。损失函数的选择依赖于具体的任务和数据的特性。对于回归任务,常使用均方误差(MSE)或平均绝对误差(MAE);对于分类任务,常使用交叉熵损失。在实际应用中,优化算法会通过最小化损失函数来提高模型的预测精度。

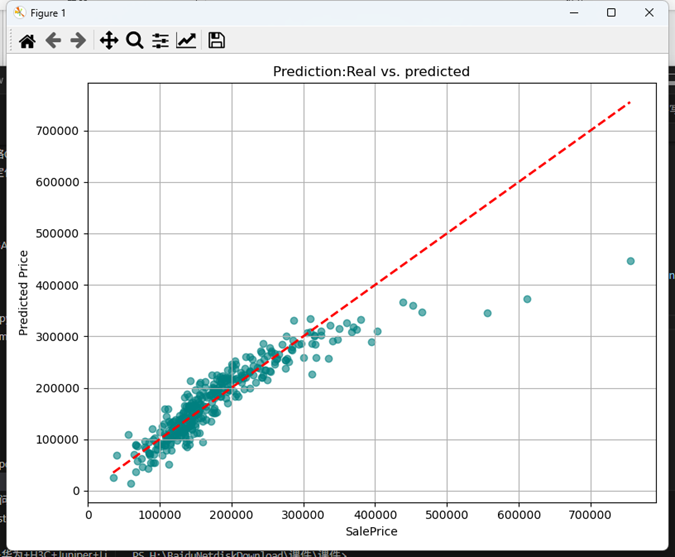
1.线性回归(Linear Regression)

-
优缺点:
-
优点:训练速度快、易于解释;
-
缺点:只能捕捉线性关系,对异常值敏感;
-
-
典型应用:房价预测、销售额预测、时间序列的线性趋势建模。
-
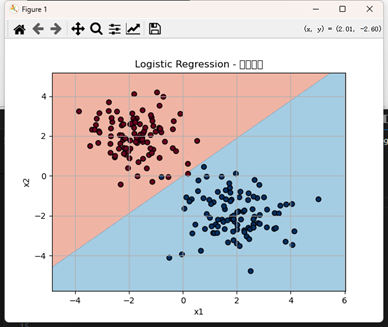
2. 逻辑回归(Logistic Regression)

-
优缺点:
-
优点:概率输出,可解释性强;
-
缺点:对线性可分假设依赖较强,易欠拟合复杂关系;
-
-
典型应用:肿瘤良恶性分类、垃圾邮件识别、信用风险评估。
-
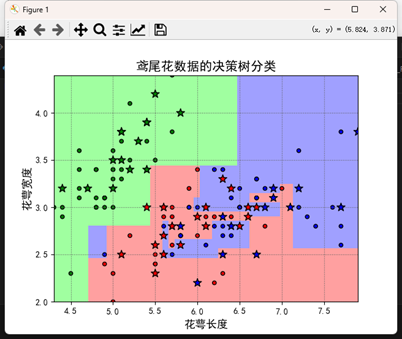
3. 决策树(Decision Tree)
-
核心思想:通过对特征的“二分(或多分)”划分,不断生成树状分支结构,使得叶子节点上的数据尽可能“纯净”。
-
模型形式:一棵树由节点(Node)和分支(Branch)组成,每次选取一个特征和阈值,将样本集分成左右子集,直到满足停止条件(如深度、样本数下限)。
-
训练目标:每次分裂时,选择能够最大化“信息增益”或“基尼系数减少”的特征/阈值。
-
优缺点:
-
优点:易于可视化和解释;无需特征缩放;
-
缺点:容易过拟合,需要剪枝或限制深度;
-
-
典型应用:信用评分(分类)、房价区间预测(回归)、医疗诊断辅助。
-
4. 支持向量机(SVM)
-
核心思想:在特征空间中寻找一个“最优超平面”,使得不同类别之间的“间隔(margin)”最大化,边界上的支持向量对模型决定性最大。
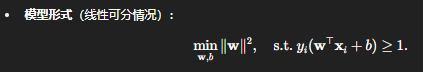
-
对于非线性问题,通过核函数(Kernel)映射到高维空间。
-
训练目标:最大化几何间隔,同时可通过松弛变量允许少量误分类(软间隔 SVM)。
-
优缺点:
-
优点:在高维空间效果好,能处理非线性;
-
缺点:对大规模数据训练慢,核函数和参数选择敏感;
-
-
典型应用:文本分类、人脸识别、生物信息学中的基因分类。
-
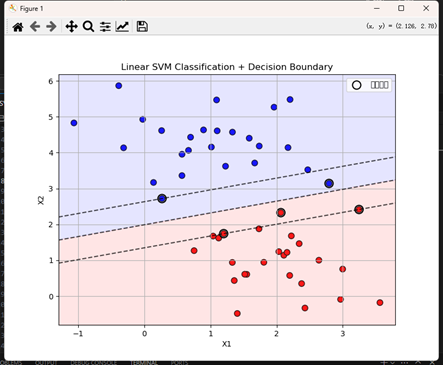
5. 随机森林(Random Forest)
-
核心思想:通过“Bagging”(自助采样)生成多棵决策树,并对多棵树的输出进行投票(分类)或平均(回归),降低单棵树过拟合风险。
-
模型形式:
-
从原始样本集中有放回地采样生成 BBB 个子集;
-
每个子集训练一棵决策树,分裂时仅在随机选取的 mmm 个特征中寻优;
-
集成所有树的预测结果。
-
-
训练目标:降低模型方差,提升鲁棒性。
-
优缺点:
-
优点:抗过拟合能力强,对缺失值和异常值不敏感;
-
缺点:当树很多时,模型较大,推断速度稍慢;
-
-
典型应用:特征丰富的结构化数据分类(客户流失预测)、回归(房价预测)。
-
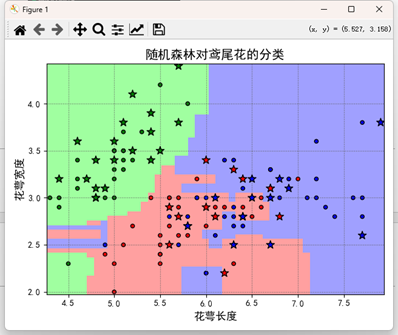
6. K近邻算法(KNN)
-
核心思想:对于待预测样本,在训练集中找到距离最近的 KKK 个邻居,依据邻居的标签进行投票(分类)或平均(回归)。
-
模型形式:无显式训练阶段,只在预测时计算样本间距离(常用欧氏距离、曼哈顿距离等)。
-
训练目标:直接利用数据分布,实现简单的“记忆式”学习。
-
优缺点:
-
优点:实现简单,无参数训练;
-
缺点:预测阶段计算量大、对数据维度和距离度量敏感;
-
-
典型应用:推荐系统的“协同过滤”、手写数字识别、医学症状相似性匹配。
-
7. 神经网络(Neural Networks)
-
核心思想:由多层“神经元”组成的网络结构,通过“前向传播”计算输出,通过“反向传播”调整权重,使输出逼近目标。可自动提取复杂特征,拟合高度非线性函数。

-
最后一层根据任务使用 Softmax(分类)或线性输出(回归)。
-
训练目标:最小化损失函数(如交叉熵、MSE),使用梯度下降及其变种(Adam、RMSProp 等)。
-
优缺点:
-
优点:强大的表达能力,可处理图像、语音、文本等多模态复杂任务;
-
缺点:需要大量数据、计算资源,调参复杂,模型不易解释;
-
-
典型应用:图像分类(卷积神经网络)、语言模型(循环/Transformer 网络)、语音识别、强化学习。
神经网络(Neural Networks, NN)是一种模仿人脑神经元连接的数学模型,广泛用于模式识别、计算机视觉、自然语言处理等任务。下面是几个常见的神经网络算法,并附带它们的概率解释。
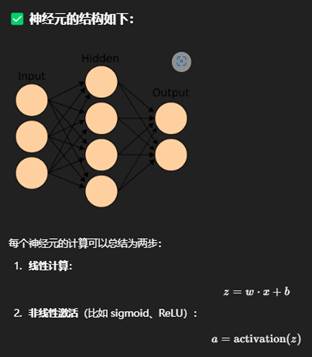
🧩 神经网络的基本结构
一个典型的神经网络分为几层(layer):
scss
输入层(Input Layer) → 隐藏层(Hidden Layer) → 输出层(Output Layer)
每一层包含多个神经元(neurons),神经元之间通过**权重(weights)**连接。
🧮 神经网络如何“学习”?
1. 前向传播(Forward Propagation):
输入数据一层一层传递到输出层,计算预测值。
2. 损失函数(Loss Function):
衡量预测结果与真实值之间的误差(比如均方误差、交叉熵等)。
3. 反向传播(Backpropagation):
根据损失计算梯度,使用链式法则更新每一层的权重。
4. 优化器(Optimizer):
使用梯度下降等算法来更新权重,比如:
- SGD(随机梯度下降)
- Adam(自适应学习率优化)


1.Sigmoid Function(S 型激活函数)

应用
- 神经网络的激活函数(特别是二分类问题)
- 概率预测(输出值可以看作是类别为 1 的概率)
- 逻辑回归(作为输出层激活函数)
卷积神经网络
卷积神经网络(CNN,Convolutional Neural Network)是什么?
卷积神经网络(CNN)是一种专门用于处理图像和类似数据的深度学习模型。它通过卷积(Convolution)、**池化(Pooling)和全连接层(Fully Connected Layer)**来自动提取特征,并进行分类或其他任务。
为什么 CNN 适用于图像?
普通的神经网络(如 MLP,全连接网络)处理图像时,每个像素都作为一个独立的输入,这会导致:
- 参数太多:比如一张 256×256 的彩色图片,输入大小是 256×256×3=196,608256 \times 256 \times 3 = 196,608256×256×3=196,608,参数数量巨大。
- 空间结构丢失:像素之间的局部关系(如边缘、纹理)在普通全连接网络中无法很好地利用。
CNN 通过卷积操作解决了这些问题:
- 只关注局部区域,而不是整个图像
- 共享权重(减少参数数量)
- 能够自动学习边缘、颜色、形状等特征
CNN 的基本结构
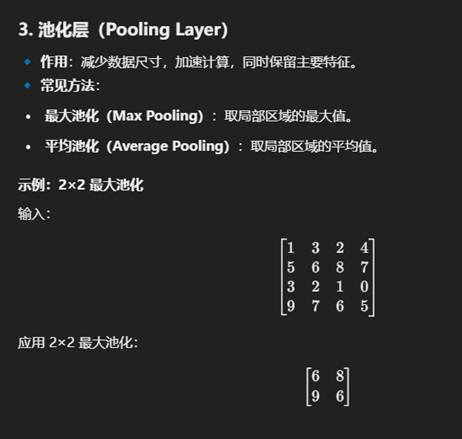
1. 卷积层(Convolutional Layer)
🔹 作用:提取图像中的局部特征,如边缘、纹理、形状等。
🔹 做法:使用卷积核(filter 或 kernel)在图像上滑动,每次计算一个卷积(加权求和)。


4. 全连接层(Fully Connected Layer, FC)
🔹 作用:把 CNN 提取的特征转换成分类结果。
🔹 结构:类似于普通神经网络,每个神经元和前一层所有神经元相连。
例如:
- 卷积层提取到 "猫耳朵"、"胡须" 等特征
- FC 层最终分类出 "这是一只猫" 🐱
CNN 的整体流程
假设我们用 CNN 识别手写数字(0-9):
- 输入层:28×28 灰度图
- 卷积层 1(Conv1):提取低级特征(边缘)
- 池化层 1(Pool1):缩小尺寸
- 卷积层 2(Conv2):提取高级特征(形状)
- 池化层 2(Pool2):进一步缩小尺寸
- 展平(Flatten):变成一维向量
- 全连接层(FC):学习复杂关系
- 输出层(Softmax):输出 10 类(0-9)
Python 代码实现
用 TensorFlow 搭建一个简单 CNN 来识别 MNIST 手写数字:
import tensorflow as tf
from tensorflow import keras
import numpy as np
# 1. 加载数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
# 2. CNN 模型
model = keras.Sequential([
keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)), # 卷积层
keras.layers.MaxPooling2D((2,2)), # 池化层
keras.layers.Conv2D(64, (3,3), activation='relu'), # 卷积层
keras.layers.MaxPooling2D((2,2)), # 池化层
keras.layers.Flatten(), # 展平
keras.layers.Dense(64, activation='relu'), # 全连接层
keras.layers.Dense(10, activation='softmax') # 输出层(10 个类别)
])
# 3. 编译和训练
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
# 4. 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print("测试准确率:", test_acc)总结
✅ CNN 通过卷积和池化高效提取图像特征,比传统神经网络更适合处理图像。
✅ 主要组成部分:卷积层 → ReLU → 池化层 → 全连接层。
✅ CNN 广泛应用于图像分类、目标检测、语音识别等任务。
2. 无监督学习(Unsupervised Learning)
定义
无监督学习是一种机器学习方法,训练数据没有标签(没有明确的目标输出),模型通过数据内部的结构、模式或关系来进行学习和推理。目标是发现数据的内在模式或数据之间的关系。
任务类型
- 聚类(Clustering):将数据分成若干个相似的组,组内的样本具有较高的相似度,组间的样本具有较大差异。
- 示例:客户分类、市场分割、社交网络分析。
- 降维(Dimensionality Reduction):将高维数据映射到低维空间,以便更好地理解数据结构或进行可视化。
- 示例:主成分分析(PCA)、t-SNE。
- 异常检测(Anomaly Detection):识别不符合正常模式的样本,通常用于检测稀有事件或异常行为。
- 示例:欺诈检测、网络入侵检测。
- 关联规则学习(Association Rule Learning):寻找数据项之间的相关性或规律。
- 示例:购物篮分析(如:购买面包的人通常也买牛奶)。
常见算法
- K-Means:一种常见的聚类算法,简单而高效。
- DBSCAN:基于密度的聚类算法,能发现任意形状的聚类。
- PCA(主成分分析):通过线性变换降维,保留数据中最重要的特征。
- t-SNE:非线性降维方法,适合高维数据可视化。
- 自编码器(Autoencoder):通过神经网络进行降维或异常检测。
评估方法
- 轮廓系数(Silhouette Score):用于评估聚类的质量。
- DBI指数(Davies-Bouldin Index):衡量聚类的紧密度和分离度。
- 可视化方法:如PCA或t-SNE,帮助评估降维效果和聚类效果。
应用
- 客户细分:市场营销、用户画像。
- 文本分析:主题建模、文本聚类。
- 推荐系统:商品或电影推荐。
- 异常检测:网络安全、金融欺诈。
3. 强化学习(Reinforcement Learning)
定义
强化学习是一种通过与环境的交互,基于奖励信号来学习最优策略的机器学习方法。智能体(Agent)执行动作(Action),从环境(Environment)中获得奖励(Reward),并通过试错方式优化自己的行为策略。
关键概念
- 智能体(Agent):进行决策和执行动作的主体(如自动驾驶汽车、游戏AI)。
- 环境(Environment):智能体所处的世界,状态随着智能体的行为而变化。
- 状态(State, S):描述环境的特定信息,代表环境的当前情况。
- 动作(Action, A):智能体在某个状态下可以采取的行为。
- 奖励(Reward, R):智能体执行某个动作后获得的反馈,通常是一个数值。
- 策略(Policy, π):智能体从某个状态出发选择动作的规则或函数。
- 价值函数(Value Function, V):估计在某个状态下,智能体未来能够获得的总奖励。
- Q值(Q-Value, Q(s,a)):评估在某个状态下执行某个动作的长期回报。
常见算法
- Q-Learning:基于值的强化学习算法,使用Q值函数来优化决策。
- 深度Q网络(DQN):使用深度神经网络近似Q值,适用于复杂的状态空间。
- 近端策略优化(PPO):基于策略的强化学习算法,稳定性好。
- A3C(Actor-Critic):结合了值和策略的方法。
- SAC(Soft Actor-Critic):适用于连续动作空间的强化学习算法。
探索与利用
- 探索(Exploration):智能体尝试新的动作,以发现更好的策略。
- 利用(Exploitation):智能体利用已知的最佳动作来获得奖励。
应用
- 游戏AI:AlphaGo、Dota2 AI。
- 自动驾驶:路径规划、决策控制。
- 机器人控制:机械臂抓取、动作学习。
- 智能推荐系统:个性化推荐、动态调整。
总结
| 类别 | 定义 | 任务类型 | 常见算法 | 应用 |
| 监督学习 | 使用已标记的数据进行训练,目标是预测标签。 | 分类、回归 | 线性回归、SVM、随机森林、神经网络 | 图像识别、语音识别、医疗诊断、金融分析 |
| 无监督学习 | 数据没有标签,模型自动发现结构或模式。 | 聚类、降维、异常检测 | K-Means、PCA、DBSCAN、自编码器 | 客户细分、市场分析、推荐系统、异常检测 |
| 强化学习 | 智能体通过与环境交互学习最优策略,最大化长期奖励。 | 游戏AI、自动驾驶、机器人控制 | Q-Learning、DQN、PPO、SAC | 自动驾驶、游戏AI、机器人控制、智能推荐 |
数学Mathematics
介绍
1. 线性代数(Linear Algebra)
机器学习中大部分数据都是以矩阵和向量的形式存储和计算的,因此线性代数是核心基础。
必学内容:
- 向量和矩阵(加法、乘法、转置)
- 矩阵分解(特征分解、奇异值分解 SVD)
- 特征值与特征向量(PCA 降维的基础)
- 逆矩阵和伪逆(用于求解最小二乘问题)
- 正定矩阵(优化问题中常见)
👉 应用: PCA 降维、神经网络计算、推荐系统(SVD)
2. 概率与统计(Probability & Statistics)
机器学习很多模型都是基于概率的,理解数据分布、随机变量和推断方法至关重要。
必学内容:
- 概率分布(正态分布、高斯分布、伯努利分布、泊松分布等)
- 条件概率和贝叶斯定理(朴素贝叶斯分类器的核心)
- 最大似然估计(MLE)和最大后验估计(MAP)
- 期望、方差、协方差(衡量数据分布和相关性)
- 信息熵和交叉熵(决策树、神经网络的损失函数)
👉 应用: 朴素贝叶斯分类、隐马尔可夫模型、生成模型(如 GAN)
3. 微积分(Calculus)
机器学习中的优化(如梯度下降)涉及大量微积分知识。
必学内容:
- 导数和偏导数(用于优化模型参数)
- 梯度下降法(神经网络的核心训练算法)
- 链式法则(反向传播的基础)
- 泰勒展开(用于近似复杂函数)
- 积分(贝叶斯推理和期望计算)
👉 应用: 反向传播、优化损失函数、卷积神经网络(CNN)
4. 优化理论(Optimization)
模型训练的核心是优化目标函数,使损失最小化。
必学内容:
- 凸优化(许多优化问题都是凸函数)
- 拉格朗日乘子法(用于约束优化)
- 随机梯度下降(SGD)和变种(Adam, RMSprop)
- 牛顿法和二阶优化方法
👉 应用: 深度学习模型训练、正则化方法(L1/L2 正则)
5. 数值分析(Numerical Analysis)
数值计算会影响机器学习算法的稳定性和精度。
必学内容:
- 求解线性方程组(LU 分解、QR 分解)
- 迭代法(Jacobi, Gauss-Seidel)
- 梯度消失和梯度爆炸问题
👉 应用: 机器学习算法的数值稳定性、模型收敛问题
6. 信息论(Information Theory)
衡量数据不确定性和模型质量的重要工具。
必学内容:
- 熵(Entropy)(度量数据不确定性)
- 交叉熵(Cross-Entropy)(用于分类任务)
- KL 散度(Kullback-Leibler Divergence)(衡量两个分布的相似性)
👉 应用: 决策树、深度学习损失函数、变分自编码器(VAE)
7. 图论(Graph Theory)(可选)
用于一些特定的机器学习任务,如图神经网络(GNN)。
必学内容:
- 图的基本概念(节点、边、邻接矩阵)
- 最短路径算法(Dijkstra、Floyd)
- 马尔可夫决策过程(MDP)
👉 应用: 推荐系统(知识图谱)、社交网络分析、强化学习
线性代数(Linear Algebra)
1. 向量(Vector)
向量是 一组有序的数值,可以表示位置、速度、特征等。
例如,假设你有一个人的身高(170 cm)、体重(65 kg)和年龄(25 岁):

👉 应用:计算余弦相似度,判断两个用户兴趣是否相似(推荐系统)。
🔹 Python 代码
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
dot_product = np.dot(a, b)
print("向量点积:", dot_product) # 输出 322. 矩阵(Matrix)
矩阵是 数据的表格形式,用于存储多个向量。
例如,一个包含 3 个人 身高、体重和年龄的数据矩阵:

👉 应用:神经网络的加权求和。
🔹 Python 代码
A = np.array([[170, 65, 25], [180, 75, 30], [160, 55, 20]])
P = np.array([[10], [20], [30]])
result = np.dot(A, P)
print("矩阵乘法结果:\n", result)3. 线性变换(Linear Transformation)
矩阵可以 旋转、缩放、变换 向量。
假设有一个点 (2, 1),我们应用一个变换矩阵:
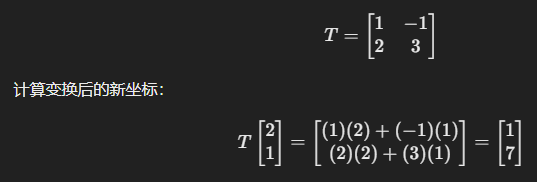
👉 应用:图像变换(旋转、缩放)、神经网络的线性层。
🔹 Python 代码
T = np.array([[1, -1], [2, 3]])
point = np.array([[2], [1]])
new_point = np.dot(T, point)
print("变换后的坐标:\n", new_point)
直观理解
矩阵 TTT 作用在点 (2,1)(2,1)(2,1) 上,改变了它的位置:
- 第一行 (1,−1)(1, -1)(1,−1) 代表 新 x 坐标 是原来的 1 倍 x - 1 倍 y。
- 第二行 (2,3)(2, 3)(2,3) 代表 新 y 坐标 是原来的 2 倍 x + 3 倍 y。
这就是 线性变换的本质:缩放 + 旋转 + 变形!
变换后的坐标:
[[1]
[7]]
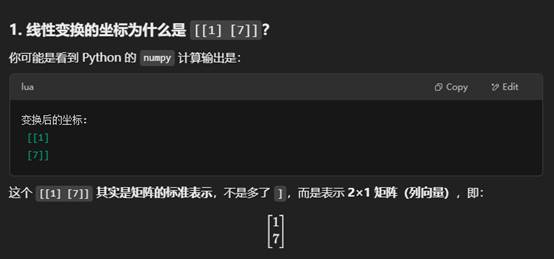
这表示:
- 1 在第一行
- 7 在第二行
所以它是一个 列向量,没有多余的 ],只是 Python numpy 的打印格式。
✅ 线性变换:
- 矩阵乘法是按行求点积,得到新的坐标。
- 变换后的坐标 = 线性变换矩阵 × 原坐标。
4. 行列式(Determinant)

👉 应用: 判断矩阵是否可逆、特征值计算等。
5. 特征值 & 特征向量(Eigenvalues & Eigenvectors)
如果一个矩阵作用在一个向量上,而这个向量 方向不变,只缩放:

👉 应用:PCA 降维(找到数据最重要的方向)。
🔹 Python 代码
A = np.array([[2, 1], [1, 2]])
eigvals, eigvecs = np.linalg.eig(A)
print("特征值:\n", eigvals)
print("特征向量:\n", eigvecs)

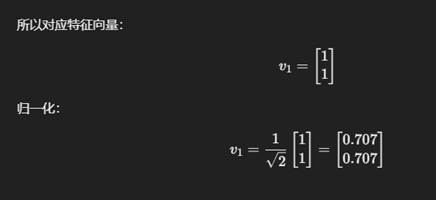





为什么要归一化?
- 避免数值误差:有时向量长度很大,归一化让它保持数值稳定。
- 方便计算:归一化的特征向量使矩阵计算更容易处理。
- 统一尺度:在神经网络、SVM等机器学习算法中,归一化保证特征值的权重一致。


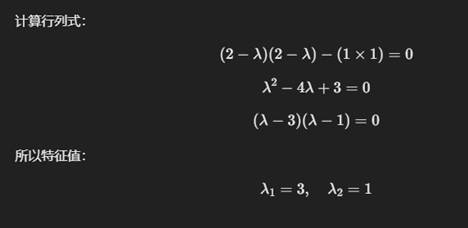

✅ 特征值 & 特征向量:
- 特征值 代表矩阵的固有缩放比例。
- 特征向量 代表变换时 不改变方向 的特殊向量。
- 通过解方程 det(A−λI)=0 求解特征值,再解 (A−λI)v=0求特征向量。
6. 奇异值分解(SVD)
SVD 分解:

👉 应用:推荐系统(Netflix 用 SVD 预测用户评分)。
🔹 Python 代码
A = np.array([[3, 2, 2], [2, 3, -2]])
U, S, VT = np.linalg.svd(A)
print("U:\n", U)
print("Sigma:\n", np.diag(S))
print("V^T:\n", VT)7. 逆矩阵(Inverse Matrix)
![]()
👉 应用:求解线性方程组、优化问题。
🔹 Python 代码
A = np.array([[4, 7], [2, 6]])
A_inv = np.linalg.inv(A)
print("A 的逆矩阵:\n", A_inv)8. 正定矩阵(Positive Definite Matrix)

👉 应用:最优化(梯度下降收敛条件)。
🔹 Python 代码
A = np.array([[2, -1], [-1, 2]])
print("是否为正定矩阵:", np.all(np.linalg.eigvals(A) > 0))总结
✅ 核心概念 + 直观示例
- 向量:特征表示(用户、商品等)
- 矩阵运算:批量数据处理
- 线性变换:图像变换、神经网络
- 特征值分解:降维(PCA)
- SVD:推荐系统、数据压缩
- 逆矩阵 & 正定矩阵:优化问题
这些知识点构成了机器学习的数学基础,理解它们能帮助你更深入地掌握算法的本质! 🚀
概率与统计(Probability & Statistics)
1. 概率(Probability)
定义:概率表示某个事件发生的可能性,取值范围是 0 到 1,0 表示不可能,1 表示必然发生。
🎯 例子:投掷硬币
投掷一枚 公平 的硬币,它落地时正面朝上的概率是多少?

💻 Python 代码
import random
# 模拟投掷硬币 10000 次
num_trials = 10000
heads = sum(random.choice(['H', 'T']) == 'H' for _ in range(num_trials))
prob_heads = heads / num_trials
print(f"投掷 {num_trials} 次后,正面朝上的概率:{prob_heads}")2. 条件概率(Conditional Probability)

💻 Python 代码
# 总共有 52 张牌,其中 13 张是红桃
total_cards = 52
hearts = 13 # 共有 13 张红桃
king_of_hearts = 1 # 其中只有 1 张是红桃 K
# 计算条件概率 P(K|红桃)
prob_K_given_hearts = king_of_hearts / hearts
print(f"在抽到红桃的情况下,它是 K 的概率:{prob_K_given_hearts:.4f}")3. 贝叶斯定理(Bayes' Theorem)

💻 Python 代码
# 先验概率
P_disease = 0.01 # P(病)
P_no_disease = 1 - P_disease # P(无病)
# 条件概率
P_positive_given_disease = 0.9 # P(阳性|病)
P_positive_given_no_disease = 0.05 # P(阳性|无病)
# 总体阳性概率 P(阳性)
P_positive = (P_positive_given_disease * P_disease) + (P_positive_given_no_disease * P_no_disease)
# 贝叶斯定理求 P(病|阳性)
P_disease_given_positive = (P_positive_given_disease * P_disease) / P_positive
print(f"检测为阳性后,实际患病的概率:{P_disease_given_positive:.4f}")🔹 结果解释:
即使检测结果是阳性,实际患病的概率 很低(<20%),因为误检率较高,说明检测并不完全可靠。
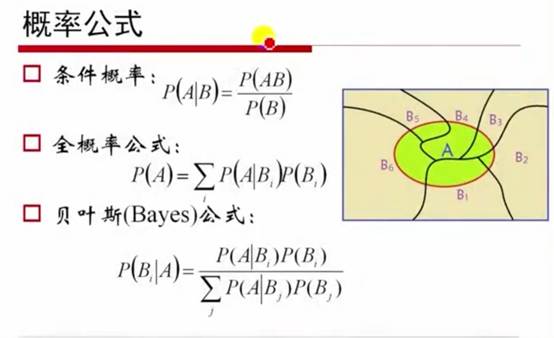

4. 期望与方差(Expectation & Variance)
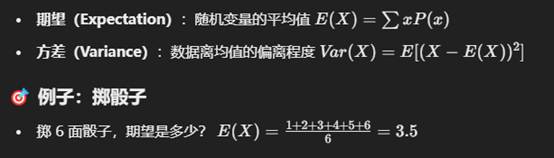
💻 Python 代码
import numpy as np
dice = np.array([1, 2, 3, 4, 5, 6])
prob = np.full(6, 1/6) # 每个点数的概率是 1/6
# 计算期望和方差
expectation = np.sum(dice * prob)
variance = np.sum((dice - expectation) ** 2 * prob)
print(f"骰子的期望:{expectation}")
print(f"骰子的方差:{variance}")5. 正态分布(Normal Distribution)

💻 Python 代码:生成正态分布的随机数
import matplotlib.pyplot as plt
import scipy.stats as stats
# 生成正态分布的随机数据
mu, sigma = 0, 1 # 均值为0,标准差为1
data = np.random.normal(mu, sigma, 1000)
# 画出概率密度函数(PDF)
x = np.linspace(-4, 4, 100)
pdf = stats.norm.pdf(x, mu, sigma)
plt.hist(data, bins=30, density=True, alpha=0.5, label="Histogram")
plt.plot(x, pdf, 'r-', label="Normal Distribution")
plt.legend()
plt.show()6. 中心极限定理(Central Limit Theorem)
中心极限定理:无论原始数据分布如何,当样本数量足够大时,样本均值的分布趋近于正态分布。
💻 Python 代码::均匀分布样本均值变成正态分布
import numpy as np
import matplotlib.pyplot as plt # ✅ 确保导入
# 中心极限定理演示
samples = 1000 # 取 1000 组样本
means = [np.mean(np.random.uniform(0, 10, 30)) for _ in range(samples)]
# 绘制直方图
plt.hist(means, bins=30, density=True, alpha=0.6, color="b")
plt.title("Central Limit Theorem in Action")
plt.xlabel("Sample Mean")
plt.ylabel("Density")
plt.show()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









