







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

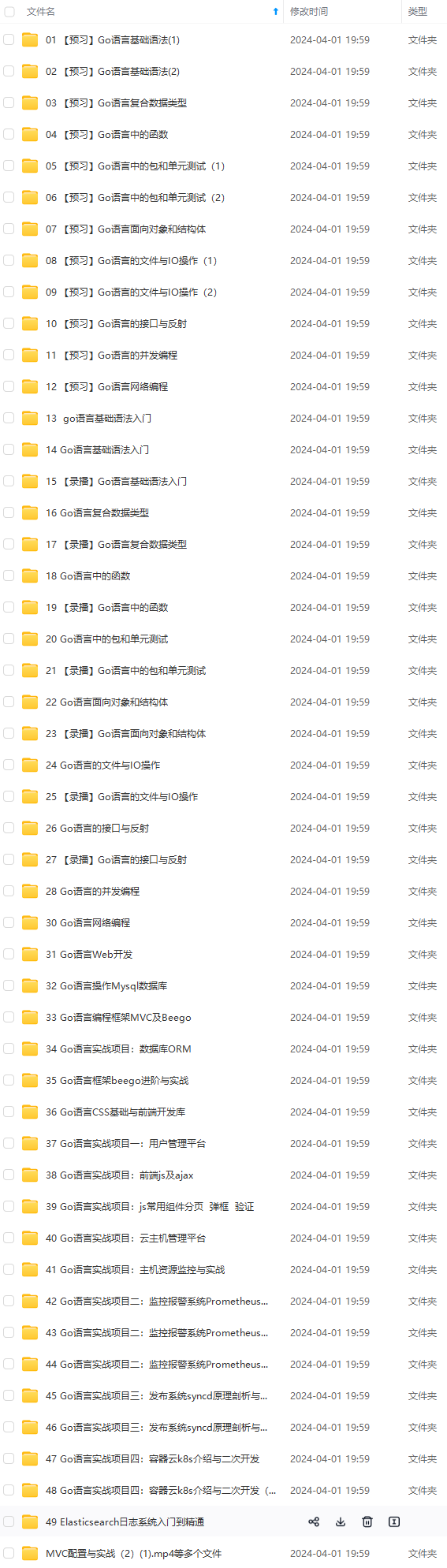
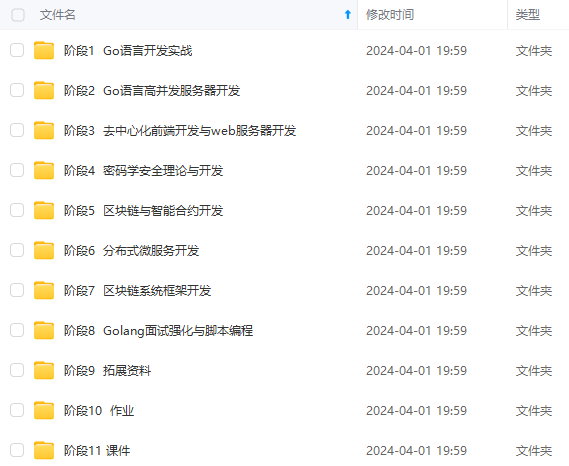
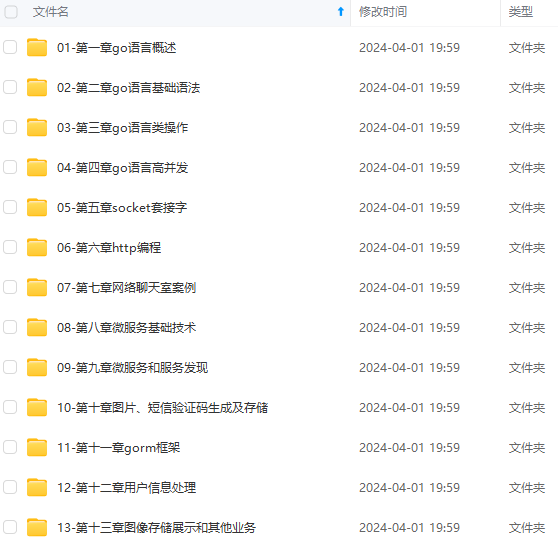
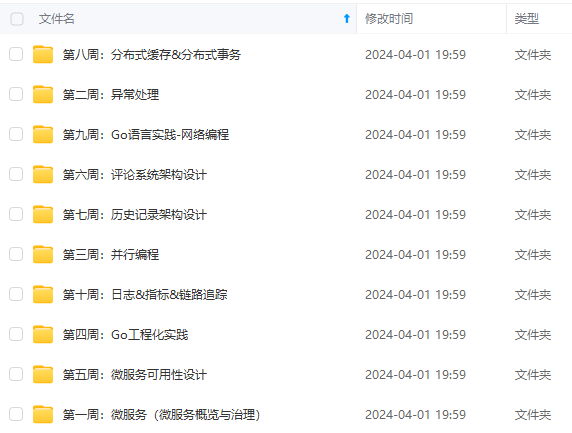
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
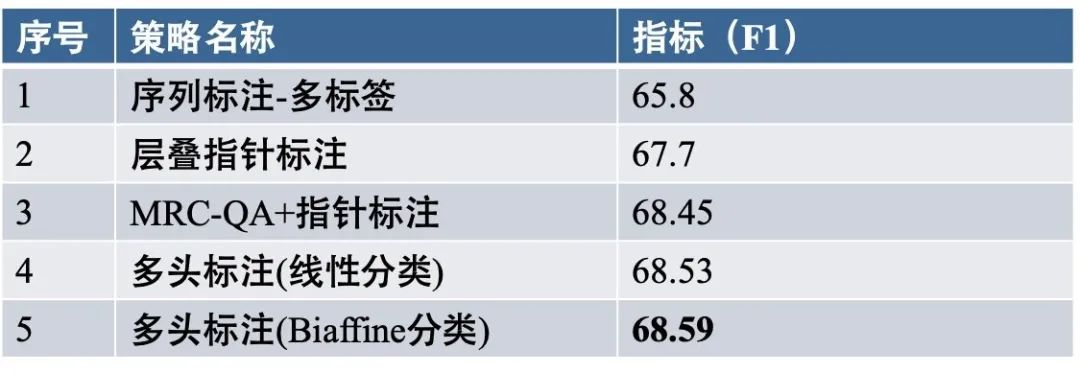
在CHIP20嵌套实体评测中,我们对比了不同标注策略下的效果(如下图),可以发现:多头标注效果最佳!
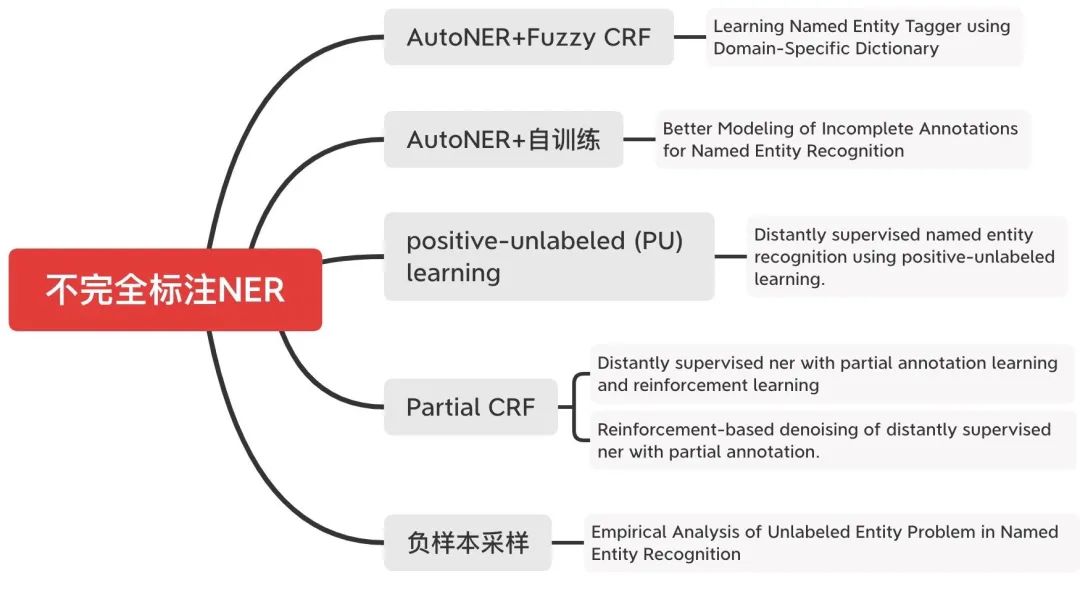
Q4:贴合真实场景的NER竞赛:如何解决不完全标注NER?
标注资源少、如何降低标注量一直是真实工业场景中必须面对的问题,不同于分类任务,大规模的实体标注数据集的构建成本更高。BERT的出现本身就是一种降低标注量的方式,此外,文本增强等方式也可降低标注(PS:NER等序列标注任务的数据增强方式可能要独立适配会更好,采用常见的增强方式效果提升不明显~)。
那么,有没有一种仅仅通过积累的实体词典、来匹配标注数据的方式,这样可以不用大规模的进行人工标注了。这种方式,可以统称为「不完全标注NER问题」:这种方式最为突出一点就是漏标情况严重,而NER序列标注的方式对噪声(漏标)十分敏感。(事实上,人工标注中也会存在漏标等情况)
CHIP20的评测六-中药说明书实体识别挑战(http://cips-chip.org.cn/2020/eval6)就是对这一问题的评测。由于这个评测正在答辩环节中,JayJay也进入最后答辩了,具体方案等成绩揭晓后再与大家分享吧~下面,我们来看看学术界都有哪些解决方案:
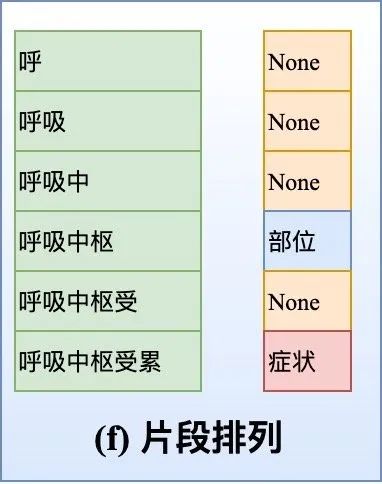
需要特别介绍的是一篇来自ICLR2021投稿的《Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition》,就是采用我们上述提到的「片段排列」标注方式,摒弃传统的CRF序列标注、与序列长度解耦,转化为一个对span的分类问题,这样更适合对负样本实体的采样;这样模型建模不会像对序列标注中的漏标过于敏感,也更好控制。
Q5:关系抽取一片红海,如何魔改标注框架?如何突破SOTA:暴漏偏差/独立编码/pipeline?
2020年以来,关系抽取SOTA就换了好几个,JayJay常常感叹:关系抽取也太卷了吧~不过仔细阅读后,发现这些SOTA其实绝大多数还是围绕“标注框架”进行魔改,只要我们掌握Q1中提到的4种万能标注,登顶SOTA也不是不可能!
本文所提到的「关系抽取」就是实体关系抽取,不同于「关系分类」。
关系抽取范式主要有两大类:
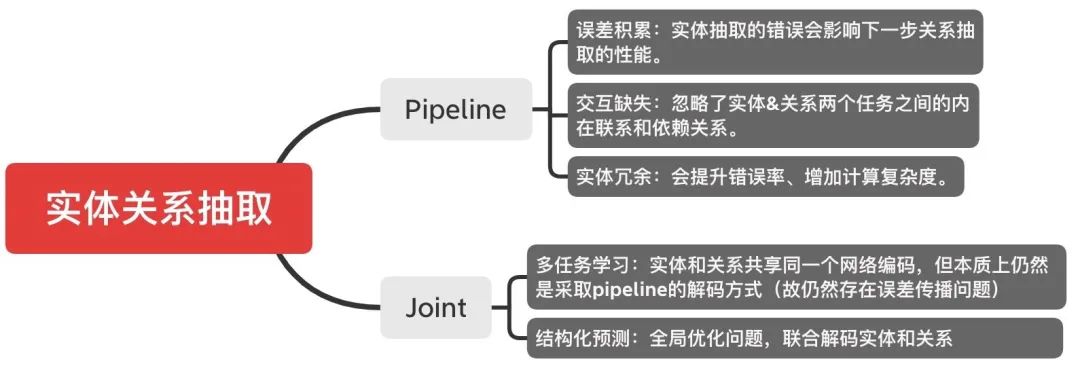
JayJay也有一段时间痴迷于各种联合抽取的joint魔改模型,如果大家有兴趣可以在知乎上直接搜索阅读JayJay的这篇文章《nlp中的实体关系抽取方法总结》。由于篇幅限制,这里简单给出一个总结图:

结合上图,我们可以发现未来突破SOTA的方向可能是:
- 打破Joint好于Pipeline的刻板印象:Pipeline是否一定就好于Joint,我们不能一概而论,特别是看过“女神的新SOTA”上一篇推文《陈丹琦“简单到令人沮丧”的屠榜之作:关系抽取新SOTA!》之后。
- 共享编码可能过于直接了:使用单独的编码器确实可以学习独立的特定任务特征,对于实体和关系确实需要特定的特征编码,在构建joint模型时如果只是简单的强行共享编码,真的可能会适得其反。这表明:针对一项任务提取的特征可能与针对另一项任务提取的特征一致或冲突,从而使学习模型混乱。所以,接下来怎么更好地去设计既可以共享、又可以任务独立的特征吧。
- 解决暴漏偏差,迫在眉睫:最近COLING2020的一篇paper[7]为了缓解这个问题,提出了一种单阶段的联合提取模型TPLinker,其不包含任何相互依赖的抽取步骤,因此避免了在训练时依赖于gold的情况,从而实现了训练和测试的一致性。
Q6:如何登顶关系抽取冠军宝座:强大的标注策略+词汇增强/对抗训练/远程监督/假阴性降噪/交替训练?
废话不说,下面直接来介绍CHIP20中的关系抽取评测。这个评测任务来源于中文医学信息抽取数据集CMeIE(http://cmekg.pcl.ac.cn/),是目前最大的中文医学关系数据集,共包含近7.5万三元组数据,2.8万疾病语句和53种定义好的schema,共44种关系,如下图所示(图片来自于腾讯天衍实验室):

这个关系评测任务是一个SPO抽取问题:

看到这个任务介绍后,如何快速构建强大的baseline呢?可以直接套用Q1给出的4种通用框架:
策略1:基于主语感知的层叠式指针网络(指针标注),抽取过程:先抽取主语subject,再抽取谓语predicate和宾语object,主要参考自ACL20的CasRel[8],JayJay做了以下几点改进(网络架构如下图所示):
- 没有随机选择主语(subject),⽽是遍历所有不同主语的标注样本构建训练集。
- 对subject的感知表征,引入conditional LayerNorm进⾏。
- 对于医疗⽂本中,中英⽂和特殊标点同时出现的特殊情况,改进bert的分词器,以更好提取英⽂专有名词等。

策略2:多头选择机制(多头标注),是基于文献[9]的改进,最重要的就是关系分类器的构造,即是实体pair的一个线性分类器,每个实体pair只选取当前实体span的最后⼀个字符进⾏关系预测,如下图:

关系分类器通过构建
的矩阵得到(其中N为序列长度,C为关系类别总数),然后通过sigmoid进行loss计算,JayJay做了以下几点改进:
- 针对nested NER问题,序列标注CRF替换为指针标注;并将实体的label embedding传入关系分类器;
- 将LSTM编码层⽤BERT等预训练模型进行替代;
- 调节实体和关系间的loss,实体的loss是关系loss的10倍;
策略3:融合BERT与多头选择机制通过上述两个策略的探索后,可以发现多头标注的两个关键问题:
- 多头选择机制的关键是在于如何更好地构造关系分类矩阵;
- BERT等预训练语言模型,如何更好地适配于多头选择机制;
基于以上两点,我们尝试将BERT最后两层编码进⾏Biaffine计算,得到关系矩阵,同时引入「CLS」全局编码信息,如下图所示:
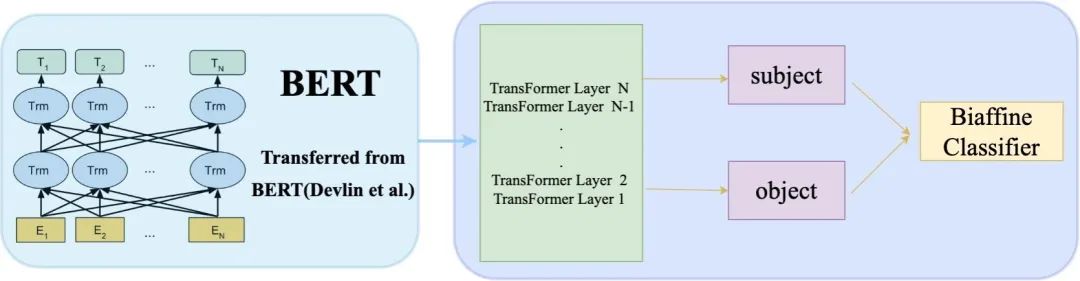
下图对比了上述三种不同策略的指标表现:
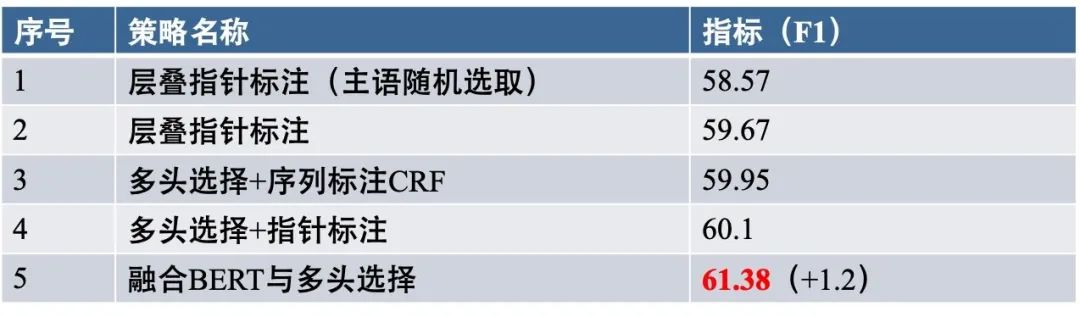
通过实验对比,可以发现:
- 对于层叠指针标注,不对主语随机选择,指标有1%的提升;
- 对于多头选择机制,将序列标注替换为指针标注,指标也有了提升;
- 而融合BERT与多头选择机制后,达到最优效果;
综上,我们将「融合BERT与多头选择」作为一个较强的baseline。有了baseline后,又该通过哪些辅助策略稳步迭代提升呢?其实,信息抽取类的竞赛套路都差不多,比如:
-
词汇增强:即引入词汇信息,并适配于所对应的标注策略;这种词汇增强的方式常见于NER问题中,具体可参见JayJay之前的推文《FLAT:中文NER屠榜之作!》。这种方式的关键在于如何引入具体的知识库信息(实体信息);
-
对抗训练:聚焦于提高鲁棒性,已经成为NLP各大竞赛的提分利器、标配动作!常用的比如FGM、PGD等,具体可参见博客[10]。
-
远程监督:即将训练集中的三元组当作知识库,然后将其作为知识特征引入模型中。
-
解决标注不平衡 由于指针标注或多头标注中存在0-1不平衡问题(稀疏问题),可采取focal loss或者幂次惩罚。
-
假阴性降噪:通常的信息抽取数据集是通过远程监督+人工check构建的,指标通常会呈现出高准确、低召回的情况,对于这种情况,我们通常要清洗训练集中存在的“假阴性”问题,我们可以借鉴Postive Unlabel Learning的思想,通过交叉验证对训练集进行清洗&重训练,采取以下两种方式:
- 只对高频出现的三元组进行回标;
- 高频三元组进行loss计算;中频三元组不进行loss计算;低频drop;
-
伪标降噪:如果手头或者主办方能够提供无标注数据,我们可以进行伪标,但比较棘手的一个问题就是如何降噪,这里给出两种简单的方式:
- 通过置信度判别模型,通过阈值来过滤噪声样本;
- 通过交叉验证,通过投票过滤噪声样本;
-
交替训练:遵循联合抽取中“硬共享编码不一定奏效的思想”,我们可以对实体和关系两个子任务进行拆解,根据多任务学习中的交替训练机制进行。
JayJay将上述辅助策略在关系评测任务中进行了尝试,部分实验结果如下:
可以看出:
- 词汇增强方式,对于总的指标是下降的,但实体指标得到了提升;
- 对抗训练、Postive Unlabel Learning、伪标降噪等策略均有了稳步提升;
在最终提交结果中,也比第2、3名高了1%:
Q7:NER的最后一步:负样本为王,实体标准化!
在医疗NLP领域,进行完NER后还不能直接作为结果供科研使用,还需要经历最后一步:医疗术语标准化,简单的讲,就是实体的标准化,这与实体链接较为类似,本质上是一个rank排序问题。
具体地讲,在医疗电子病历中,关于同一种诊断、手术、药品、检查、化验、症状等往往会有成百上千种不同的写法。在chip20评测中,医疗术语标准化就是针对「诊断」术语的标准化, 如下图所示,需要将「诊断原词」对应到「诊断标准词」,而诊断标准词来源于医疗专业知识库ICD-10.

通过对数据分析,发现有以下特点:
- 对应关系存在“一对多”:也就是对应的标准词个数不确定,如上图中的「右肺结节住院」对应1个标准词,而「右肺结节转移可能大」则对应2个标准词;此外,对应个数呈现长尾分布:1-2个是头部分布,而大于5个呈现长尾状况;
- 字面覆盖/重叠度低:比如上图中的「右肺结节住院」与「肺占位性病变」字面覆盖度就较低。
- 标准词库搜索规模大:知识库的标准词达到4w+,搜索规模较大;
根据以上数据特点,JayJay制定了召回+排序+个数预测的总体算法策略来解决:
- 对应关系存在“一对多”:通过「个数预测来」解决;
- 字面覆盖/重叠度低:文本匹配,高维语义计算;
- 标准词库搜索规模大:先召回、后排序;
总的流程图如下所示,共通过三步完成: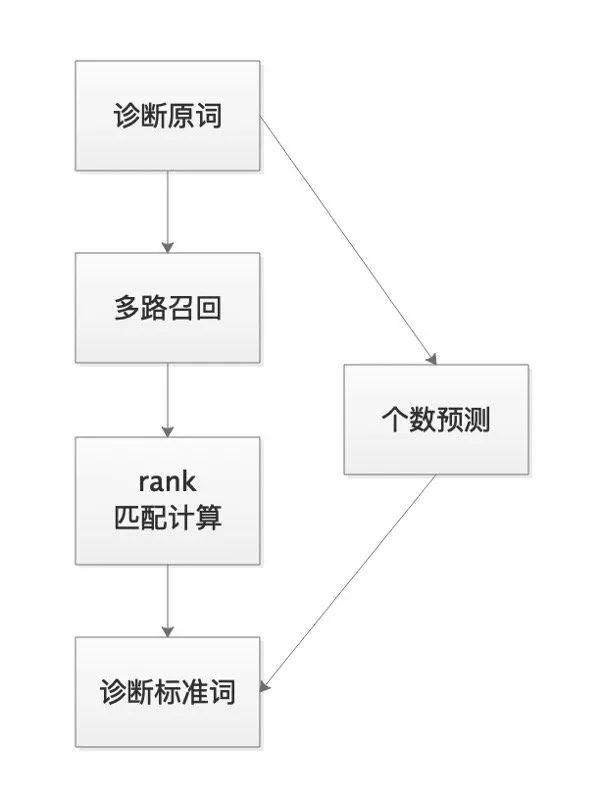
第一步:多路召回
- 标准词查询:将当前查询的诊断原词,通过与ICD-10标准词库进行TF-IDF相似度计算;
- 历史查询:将当前查询的诊断原词,通过与训练集的诊断原词进⾏TF-IDF相似度计算,返回诊断原词所对应的标准词(已标注);
- 硬匹配查询:如果标准词存在于当前查询的诊断原词中,那么返回这个标准词;
通过对比不同相似度计算(如下图),最终选取TF-IDF,召回TOP100

第二步:rank匹配计算
采取常见的文本匹配计算,基于BERT,拼接「诊断原词+候选标准词」,增加两个pooling层,进行0-1分类。
对于rank匹配最重要的一步就是负样本构造,JayJay采取以下方式进行:
- 与召回方式类似,通过TF-IDF进行相似度计算,选取TOP20;
- 增加hard negative sample数量 ,诊断原词与标准词库直接进行相似度计算;
- 解决正负样本不平衡问题,扩充正样本数量;
第三步:个数预测:
为了解决对应关系存在“一对多”的问题,很简单的一种方式就是:基于BERT,对「诊断原词」对应的标准词数⽬进⾏构建多分类模型,共设置为3个类别:0-1个;1-2个;2-大于2个;
基于以上三步,最终解码分两种情况进行:
- 个数预测<=2:直接返回top-k;
- 个数预测>2: 按照得分排序,选择阈值>0.5的标准词;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
.5的标准词;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-Gl3TNvMR-1713687382841)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









