







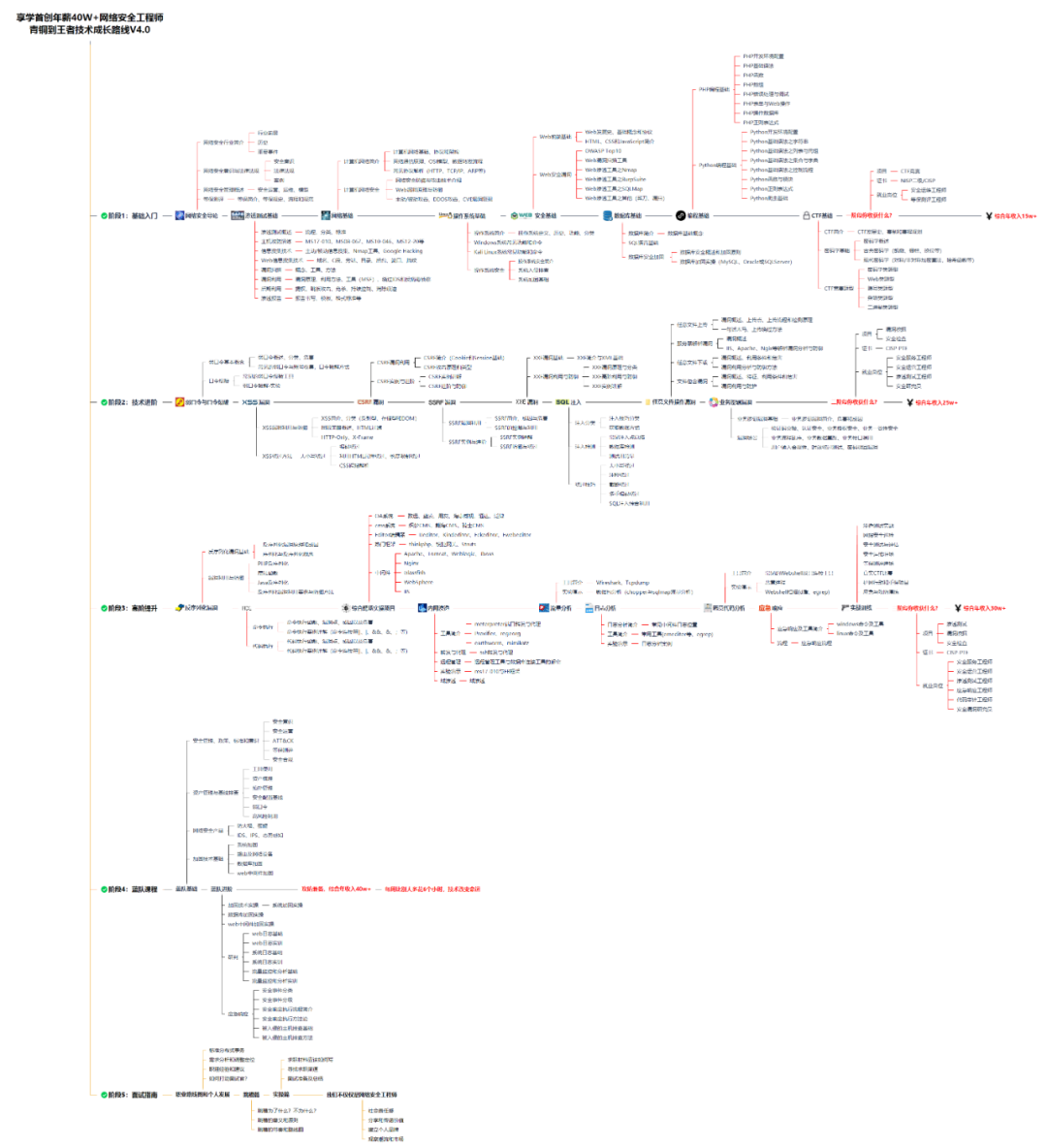
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
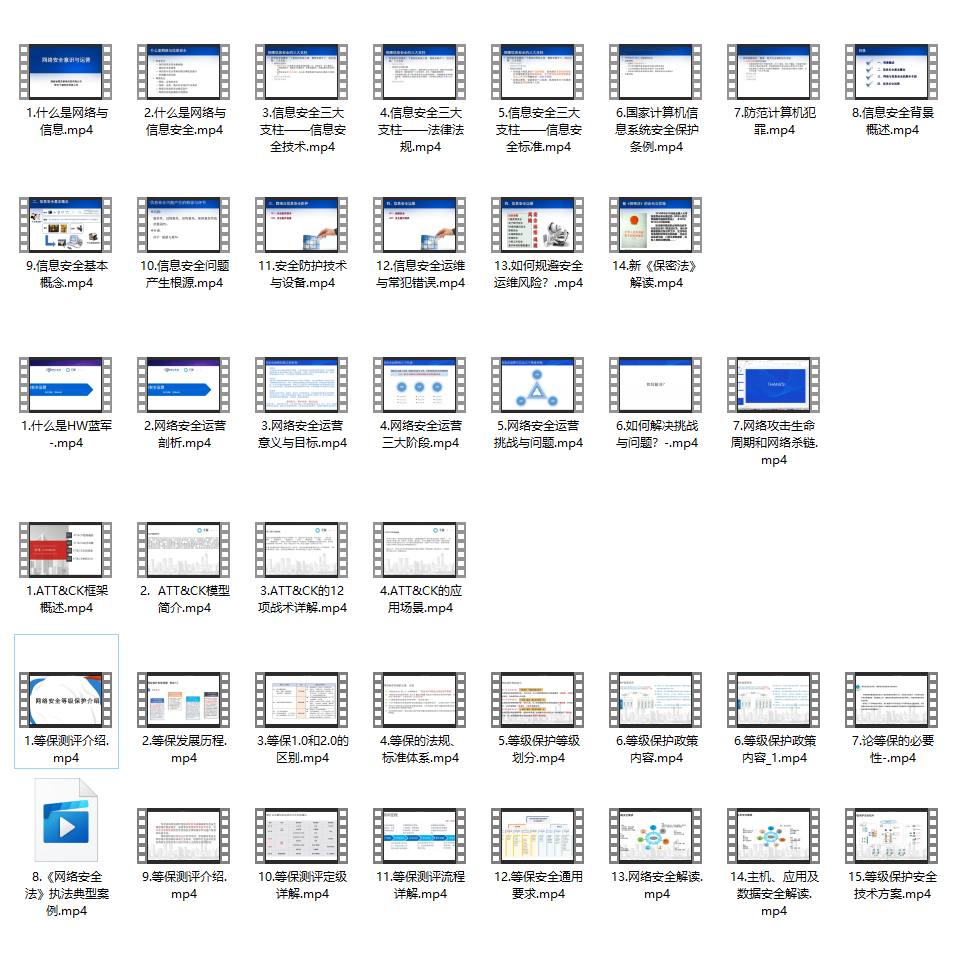
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
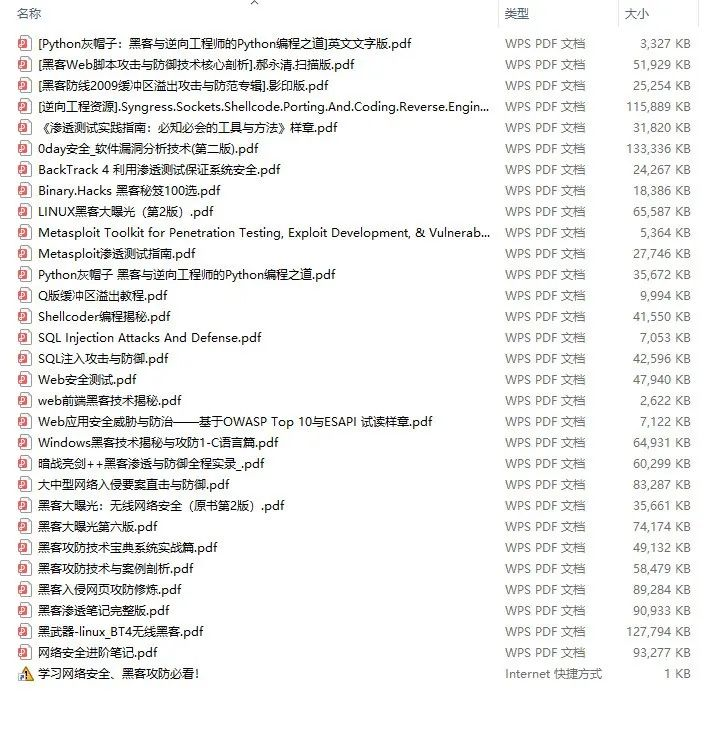
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

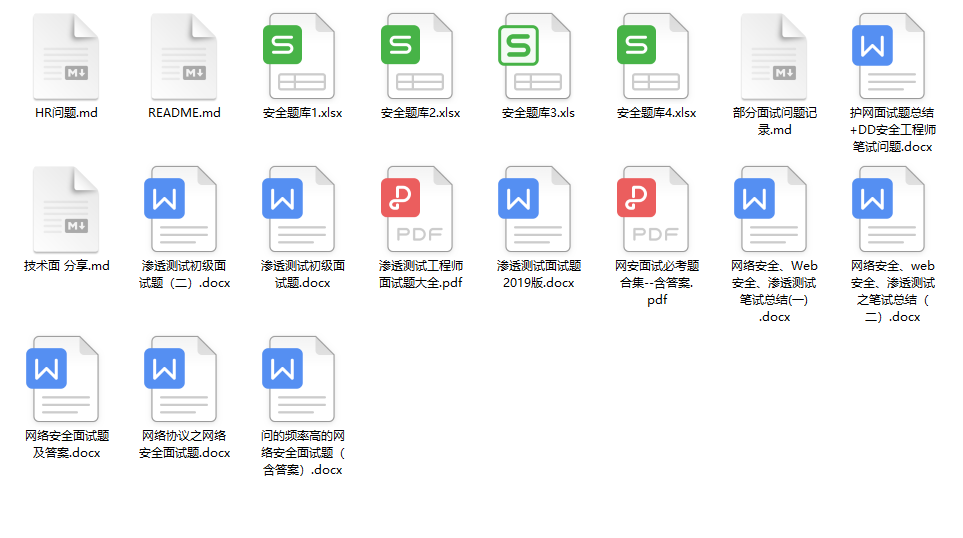
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
学习背景
由于整个HashMap底层源码实现很多,很难全部剖析,望见谅,本文主要挑选工作和面试经常遇到的一些重点和难点进行剖析即可,希望对你有所帮助!
在进入正文之前,我们知道JDK底层源码很多地方都用到了位运算以及进制相关的知识,HashMap底层也不例外,二进制是计算机底层存储格式,你电脑上所有东西,文件,视频,音乐,全部是二进制方式存储的,十进制就是我们平时的阿拉伯数字没啥可说,在学习本文时,建议先快速了解下Java几种位运算以及常见进制说明,特别是二进制的位运算,可以查看我的这篇文章进行快速了解下 https://blog.csdn.net/JustinQin/article/details/120505776
HashMap特性

- 继承AbstractMap抽象类,实现Map接口以及Cloneable, java.io.Serializable克隆和序列化
- 底层是由数组+链表组成的哈希表,JDK1.8链表长度超过8并且table数组大小大于64时才会将链表优化为红黑树
- 增删改查的效率都比较高,但多线程环境下是不安全的,可能存在问题
- 存储的元素是键值对,key键是唯一的,并且允许为key/value为null但不保证顺序
- 通过key的hash值计算出需要存放在哈希表中的数组位置index
- 默认初始化容量大小为0,第一次调用put真正给默认大小16,每次扩容oldCap << 1即原来容量的2倍
- 常用的API方法put(key,value)/get(key)/size()/isEmpty()/containsKey(key)/remove(key)
- 底层源码关键属性table、threshold、loadFactor、modCount、size
HashMap添加元素四步曲
前奏:HashMap如何添加一个元素?
HashMap底层数据结构主要通过put(K key, V value)方法添加元素,底层四步曲如下:
- 第一步曲:根据key得到hashCode值
- 第二步曲:根据hashCode值计算出hash值
- 第三步曲:根据hash值计算出哈希表数组index下标
- 第四步曲:将元素节点保存到哈希表指定数组index下标
HashMap添加元素的示例代码:
HashMap<Object, Object> map = new HashMap<>();
map.put("name","Justin");
HashMap底层put(key,value)方法源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
再看下,hash方法实现源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
接下来将解读HashMap底层源码添加元素四部曲具体实现
第一步曲:根据key得到hashCode值
以上面示例代码说明,这里key是字符串"name",String重写了计算字符串hashCode值的hashCode()方法,源码如下:
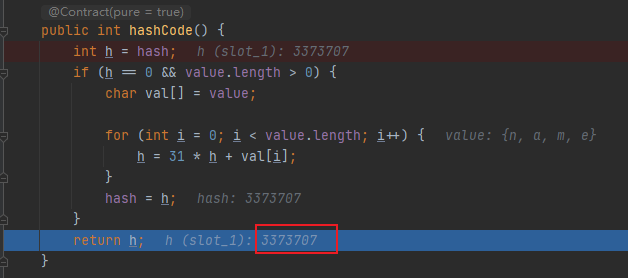
计算得到hashCode值为3373707
第二步曲:根据hashCode值计算出hash值
hash值计算的过程用到了^(异或)和>>>(无符号右移)两种位运算
(h = key.hashCode()) ^ (h >>> 16) 即 (3373707) ^ (3373707 >>> 16)
这里为了方便展示,二进制每四位使用空格格式化,位运算过程如下:

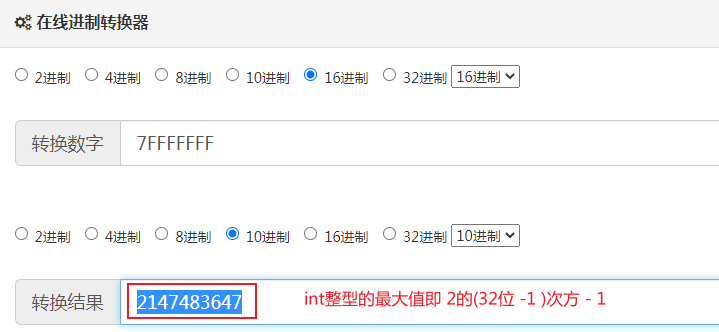
计算key="name"的hash值二进制结果是1100110111101010111000转成十进制为3373752
进制在线转换:https://c.runoob.com/front-end/58/
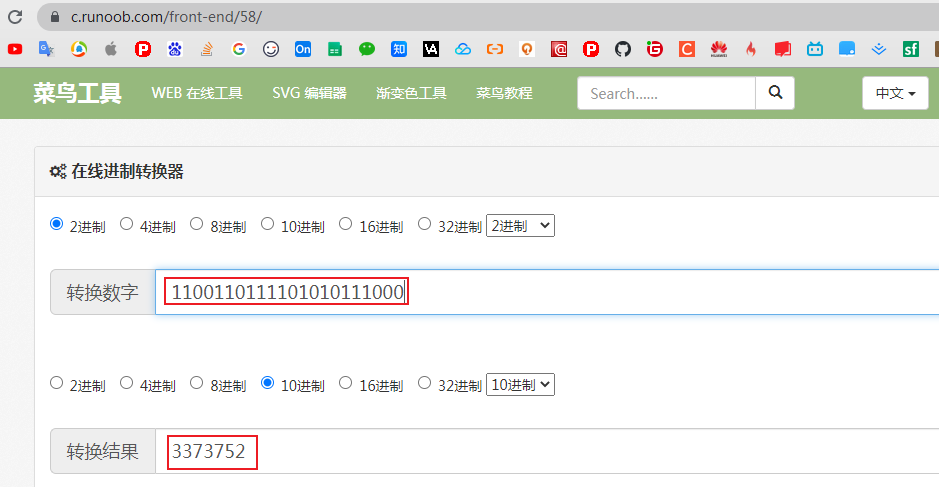
即计算key="name"的hash值为3373752,也可以debug断点往后查看hash值刚好也是这个值
第三步曲:根据hash值计算出哈希表数组index下标
公式:i = (n - 1) & hash
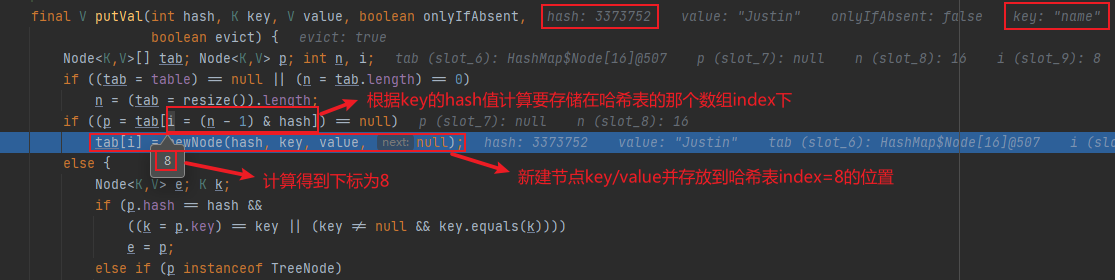
这里公式(n - 1) & hash 用到了&按位与运算(都为1则得1),奥妙之处在于n表示HashMap中的数组容量大小,并且刚好是16,32,64…2的次方,这种情况其实是等效于 hash % n 取模计算出的数组index下标值,并且下标不会超过容量(n-1)即能够保证不会数组下标越界
但是HashMap这里没有使用%取模,而是使用位运算,直接对内存数据进行操作,效率最高,如果使用%取模需要先将内存数据转成十进制再进行运算,多了这部分的性能开销,效率会变低
HashTable底层倒是用的%取模,hash值与十六进制0x7FFFFFFF做按位与运算目的是为了保证hash值始终是正数
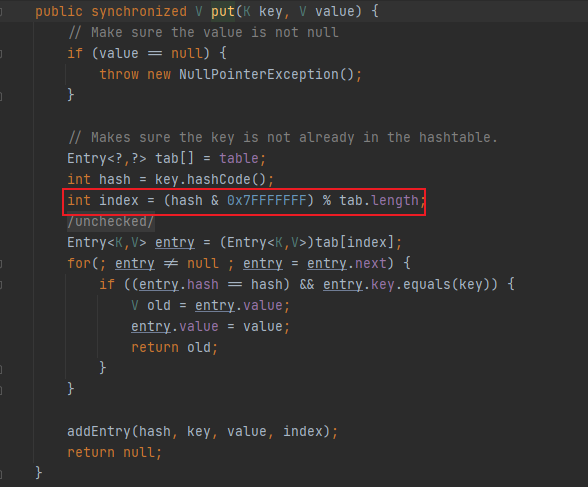
有的小伙伴可能会问了,使用%取模计算,那这里为啥HashTable还在用,我想说的是其实也可以优化,只不过HashTable本身就是主打synchronized线程安全,也就不考虑优化%取模为位运算了吧
第四步曲:将元素节点保存到哈希表指定数组index下标
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//该位置首次添加节点,则直接新建节点添加
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果节点是红黑树,调用方法进行添加元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果节点是链表,则遍历链表
for (int binCount = 0; ; ++binCount) {
//遍历链表到最后一个节点
if ((e = p.next) == null) {
//新建节点进行添加
p.next = newNode(hash, key, value, null);
//如果遍历指定位置的链表现有节点已经是大于等于8个了
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//则当前节点,需要通过该方法进行添加
//如果数组容量大于64,该过程会进行链表转化为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//HashMap对于key已经存在的处理情况是
//除非该key对应的value为null,否则一律不做任何处理
//Hashtable中则是会直接更新key对应的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//集合修改次数,没操作一次+1
++modCount;
//HashMap容量大小大于临界值,则进行resize()扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
终曲:为什么HashMap底层源码用这么多位运算?
关于位运算的使用,文中在介绍第三步曲时,也提到了HashMap计算数组下标使用%取模和位运算的问题,使用于位运算的奥妙之处在直接从内存读取数据进行计算,不需要转成十进制,如果使用%取模需要先转成十进制,有性能开销,效率比较低
HashMap底层除了文中提到的^按位异或、>>>无符号右移、&按位与位运算,其实在HashMap的扩容机制resize()中,还用到了<<左移运算
oldCap << 1
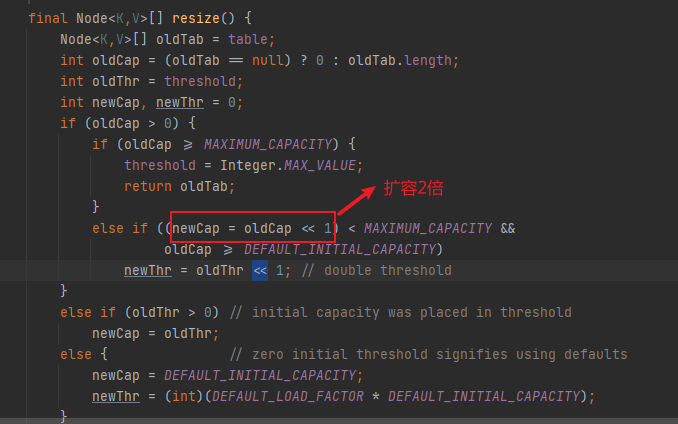
这里oldCap << 1刚好是两倍,可以总结的说一个数与n进行左移运算,结果为这个数乘以2的n次方
oldCap << 1 等值 oldCap = oldCap * (2的n次方)
同理,一个数与n进行右移运算结果为这个数除以2的n次方
oldCap >> 1 等值 oldCap = oldCap / (2的n次方)
**
HashMap链表转为红黑树
红黑树结构
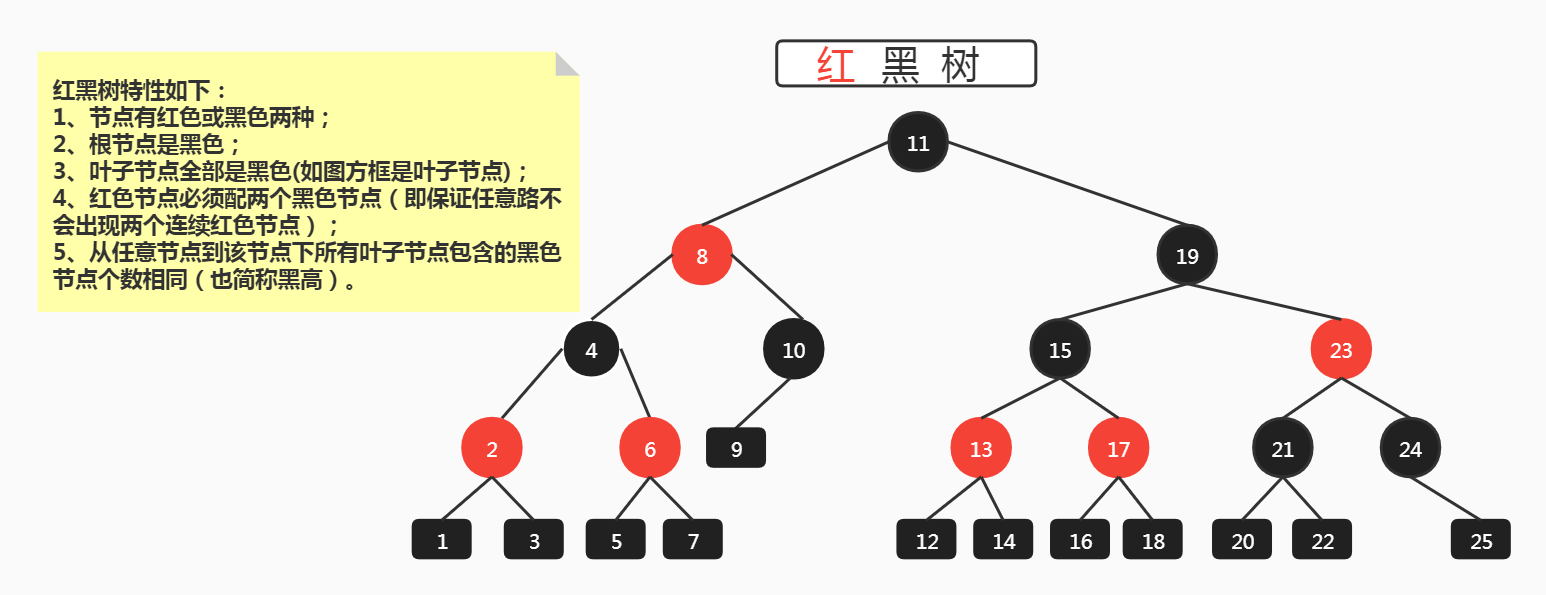
红黑树五大特性
- 节点有红色或黑色两种;
- 根节点是黑色;
- 叶子节点全部是黑色(如图方框是叶子节点);
- 红色节点必须配两个黑色节点(即保证任意路不会出现两个连续红色节点);
- 从任意节点到该节点下所有叶子节点包含的黑色节点个数相同(也简称黑高)。
HashMap链表转为红黑树过程
代码示例:
public class Test {
public static void main(String[] args) {
HashMap<Object, Object> map = new HashMap<Object, Object>();
//下标为0
map.put(null, "Justin");
map.put(16, "Justin");
//下标为8
map.put(8, "Justin"); //链表第1个节点
map.put(24, "Justin"); //链表第2个节点
map.put(40, "Justin"); //链表第3个节点
map.put(56, "Justin"); //链表第4个节点
map.put(72, "Justin"); //链表第5个节点
map.put(88, "Justin"); //链表第6个节点
map.put(104, "Justin"); //链表第7个节点
map.put(120, "Justin"); //链表第8个节点
map.put("name", "Justin"); //在添加第9个节点时,链表会被转换为红黑树
}
}
上述代码添加元素完成后,大多数人认为,底层哈希表的数据结构如下:
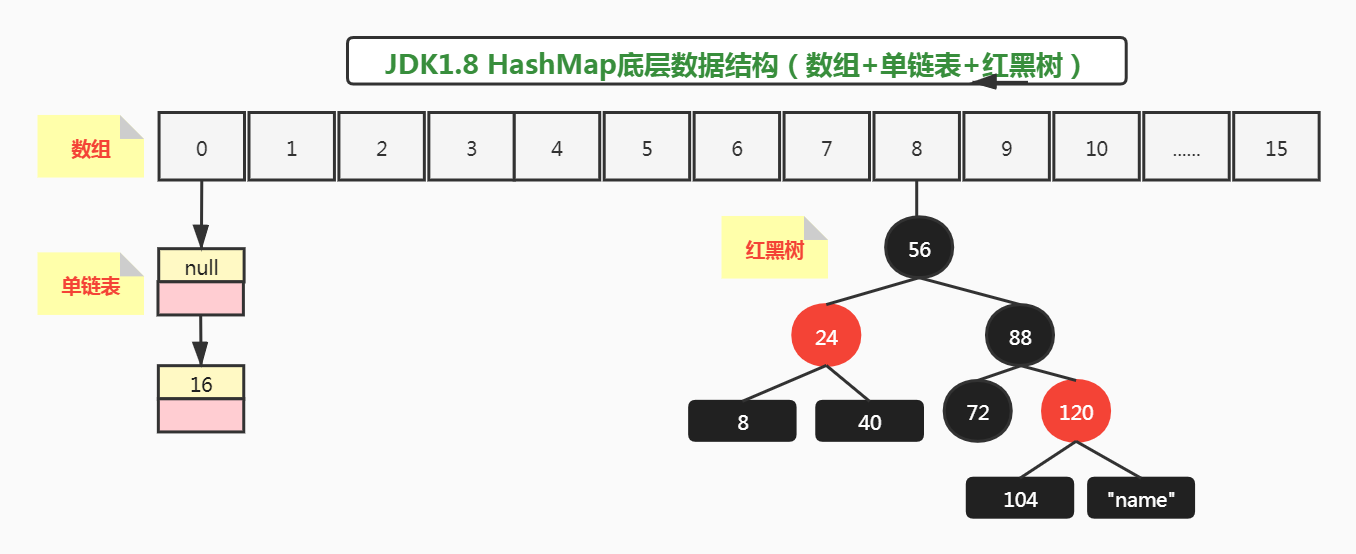
看起来好像没啥毛病,但实际哈希表index=8的位置链表并不会转成红黑树,原因如下:
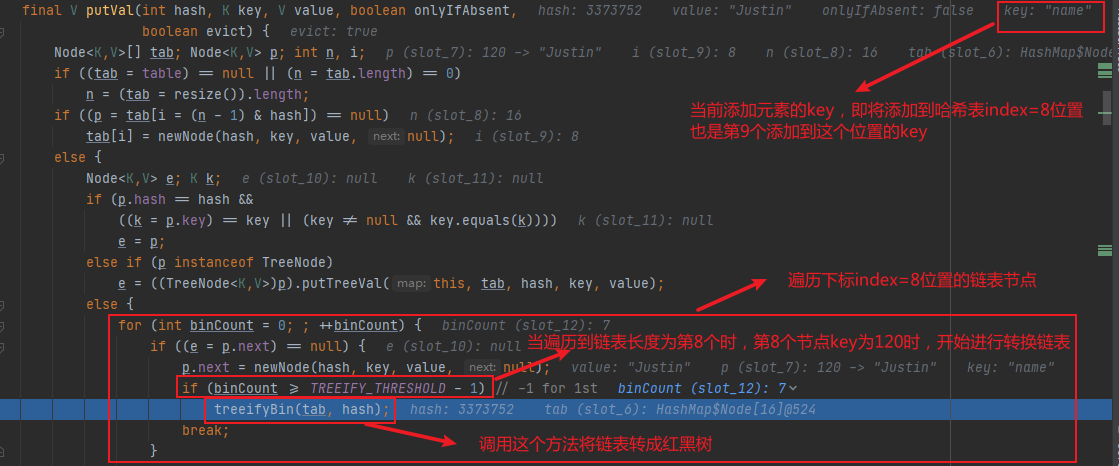
再来看下treeifyBin(tab,hash)为什么不将链表转成红黑树?
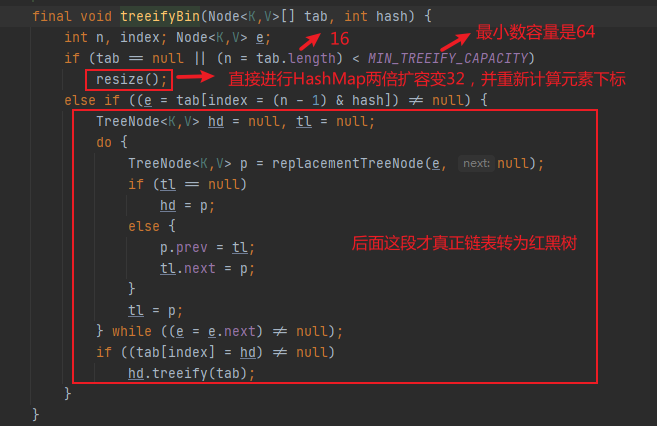
其中tab.length < MIN_TREEIFY_CAPACITY表示只要哈希表数组大小于64容量的,不可能会发生链表树化的过程,所以示例代码中,在哈希表数组下标index=8位置,添加第9个key="name"元素时,此时哈希表大小只有16, tab.length < MIN_TREEIFY_CAPACITY即16 < 64 接进行resize()扩容并重新计算各个元素存储的位置了,并不会走后面的链表转红黑树的过程。
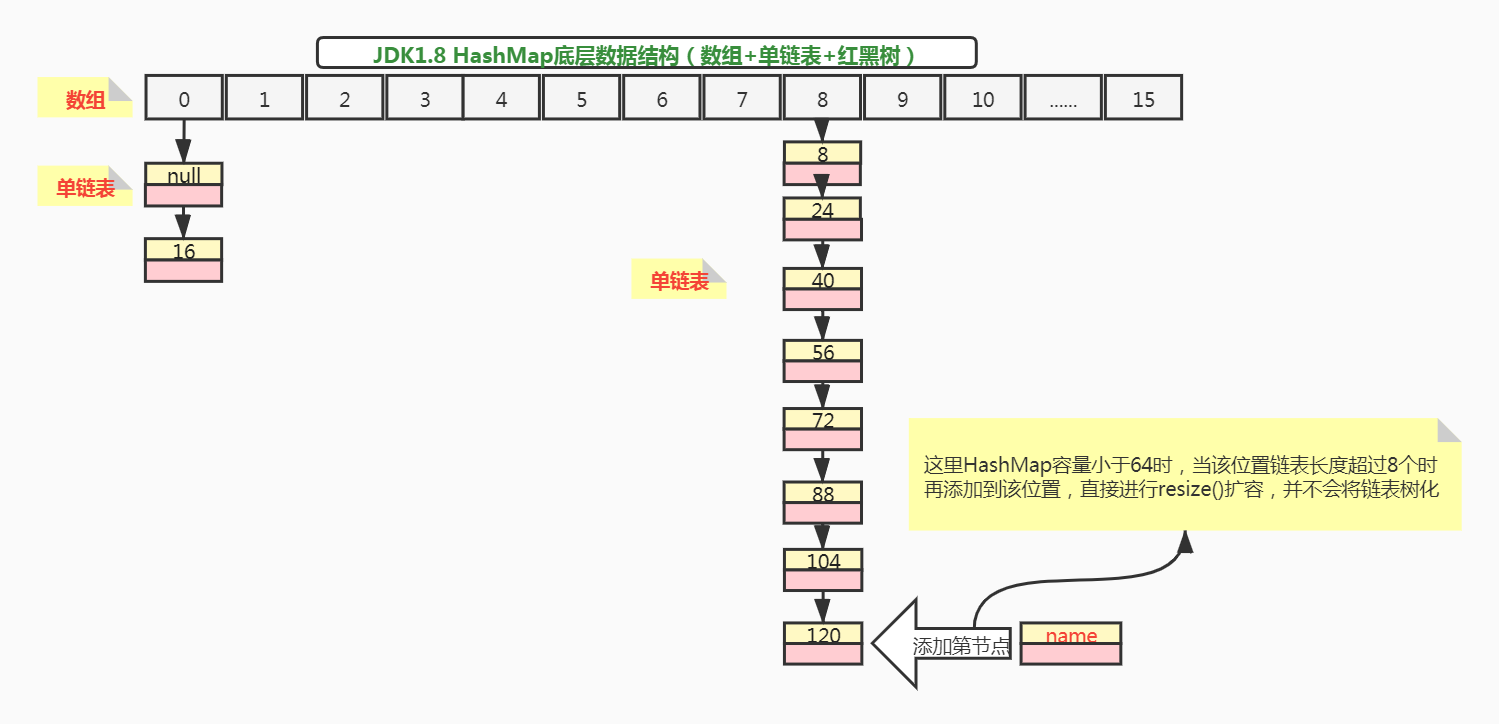
当添加key="name"节点时,会进行扩容,容量大小由16变为32,此时oldMap数据迁移到newMap后数据排列如何呢?
这里比较简单,没涉及到红黑树的拆分,而且链表长度都是大于1个的,直接由(hash & oldCap)重新计算位置:
public class Test {
public static void main(String[] args) {
cal(null,0);
cal(16,0);
cal(8,8);
cal(24,8);
cal(40,8);
cal(56,8);
cal(88,8);
cal(72,8);
cal(104,8);
cal(120,8);
cal("name",8);
}
static void cal(Object key,int oldIndex) {
//将oldMap容量和节点hash值进行&按位与运算
if( (16 & hash(key)) == 0){//结果为0,节点放到newMap位置与在oldMap下标index位置一样
System.out.println("原key=" + key + ",迁移到newMap数组下标位置为:" + oldIndex);
}else{//结果不为0,节点放到newMap位置刚好等于oldMap下标index位置 + oldMap数组容量大小
System.out.println("原key=" + key + ",迁移到newMap数组下标位置为:" + (oldIndex + 16));
}
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
原来所有key,迁移到newMap后数组index下标位置如下:
原key=null,迁移到newMap数组下标位置为:0
原key=16,迁移到newMap数组下标位置为:16
原key=8,迁移到newMap数组下标位置为:8
原key=24,迁移到newMap数组下标位置为:24
原key=40,迁移到newMap数组下标位置为:8
原key=56,迁移到newMap数组下标位置为:24
原key=88,迁移到newMap数组下标位置为:24
原key=72,迁移到newMap数组下标位置为:8
原key=104,迁移到newMap数组下标位置为:8
原key=120,迁移到newMap数组下标位置为:24
原key=name,迁移到newMap数组下标位置为:24
所以示例代码,添加元素后,正确的数据结构应该是这样的:
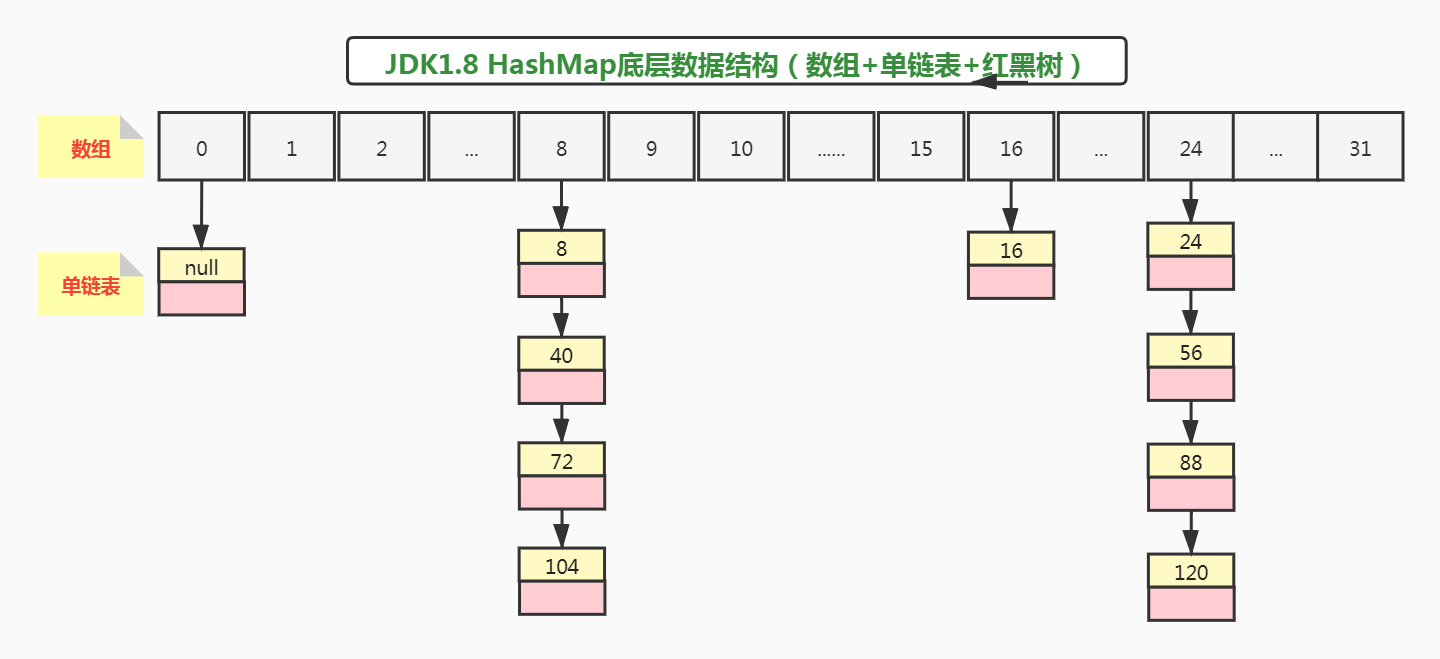
通过debug断点,也可以看到扩容后节点主要被分配到了8、16、24这个三个数组下标位置:
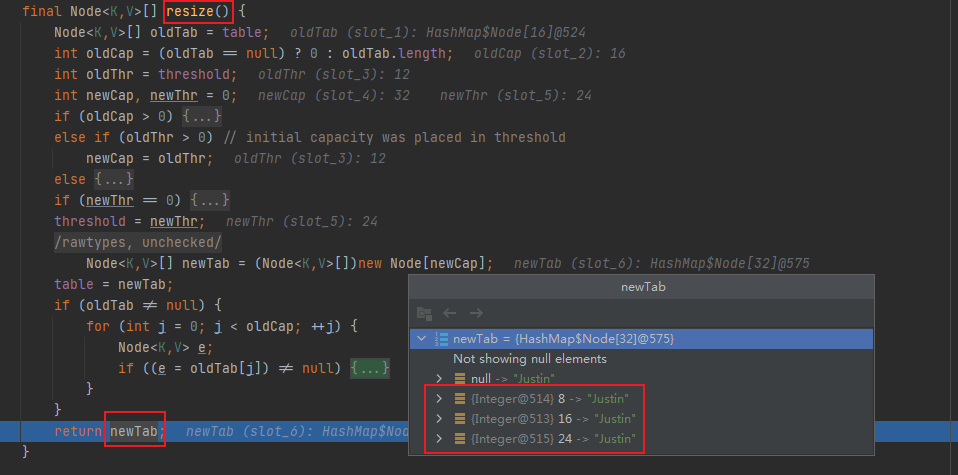
不过一般情况下,HashMap扩容是发生在添加元素时,最后通过++size > threshold判断容量大于临界值时,才进行resize()扩容
HashMap扩容机制
- 扩容情况1:第一次添加元素会进行扩容,默认初始化容量为16
- 扩容情况2:哈希表容量小于64时,链表长度每次大于8,都会进行resize()扩容
- 扩容情况3:HashMap容量大于临界值时
几种扩容情况的源码如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//扩容情况1:第一次添加元素会进行扩容,默认初始化容量为16
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//扩容情况2:见treeifyBin方法说明
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
**网络安全源码合集+工具包**

**所有资料共282G**,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









