







 本文为网络安全初学者提供了详细的学习路径,包括科学的学习路线图、配套视频教程、工具使用教程、实战项目及面试题集,旨在帮助读者建立系统知识并提升技术能力。同时,作者强调了知识体系化的重要性。
本文为网络安全初学者提供了详细的学习路径,包括科学的学习路线图、配套视频教程、工具使用教程、实战项目及面试题集,旨在帮助读者建立系统知识并提升技术能力。同时,作者强调了知识体系化的重要性。
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。
1)API
(1)采用枚举的方式统计计数
enum MyCounter{MALFORORMED,NORMAL}
//对枚举定义的自定义计数器加1
context.getCounter(MyCounter.MALFORORMED).increment(1);
(2)采用计数器组、计数器名称的方式统计
context.getCounter(“counterGroup”, “countera”).increment(1);
组名和计数器名称随便起,但最好有意义。
(3)计数结果在程序运行后的控制台上查看。
MapReduce与Yarn
Yarn概述
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
Yarn的重要概念
1)Yarn并不清楚用户提交的程序的运行机制
2)Yarn只提供运算资源的调度(用户程序向Yarn申请资源,Yarn就负责分配资源)
3)Yarn中的主管角色叫ResourceManager
4)Yarn中具体提供运算资源的角色叫NodeManager
5)这样一来,Yarn其实就与运行的用户程序完全解耦,就意味着Yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序……
6)所以,spark、storm等运算框架都可以整合在Yarn上运行,只要他们各自的框架中有符合Yarn规范的资源请求机制即可
7)Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
Yarn工作机制
1)Yarn运行机制
2)工作机制详解
(0)Mr程序提交到客户端所在的节点
(1)yarnrunner向Resourcemanager申请一个application。
(2)rm将该应用程序的资源路径返回给yarnrunner
(3)该程序将运行所需资源提交到HDFS上
(4)程序资源提交完毕后,申请运行mrAppMaster
(5)RM将用户的请求初始化成一个task
(6)其中一个NodeManager领取到task任务。
(7)该NodeManager创建容器Container,并产生MRAppmaster
(8)Container从HDFS上拷贝资源到本地
(9)MRAppmaster向RM 申请运行maptask容器
(10)RM将运行maptask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(11)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动maptask,maptask对数据分区排序。
(12)MRAppmaster向RM申请2个容器,运行reduce task。
(13)reduce task向maptask获取相应分区的数据。
(14)程序运行完毕后,MR会向RM注销自己。
作业提交全过程
1)作业提交过程之YARN
2)作业提交过程之MapReduce
3)作业提交过程之读数据
4)作业提交过程之写数据
MapReduce开发总结
mapreduce在编程的时候,基本上一个固化的模式,没有太多可灵活改变的地方,除了以下几处:
1)输入数据接口:InputFormat—>FileInputFormat(文件类型数据读取的通用抽象类) DBInputFormat (数据库数据读取的通用抽象类)
默认使用的实现类是:TextInputFormat
job.setInputFormatClass(TextInputFormat.class)
TextInputFormat的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为key,行内容作为value返回
2)逻辑处理接口: Mapper
完全需要用户自己去实现其中:map() setup() clean()
3)map输出的结果在shuffle阶段会被partition以及sort,此处有两个接口可自定义:
(1)Partitioner
有默认实现 HashPartitioner,逻辑是 根据key和numReduces来返回一个分区号; key.hashCode()&Integer.MAXVALUE % numReduces
通常情况下,用默认的这个HashPartitioner就可以,如果业务上有特别的需求,可以自定义
(2)Comparable
当我们用自定义的对象作为key来输出时,就必须要实现WritableComparable接口,override其中的compareTo()方法
**4)reduce端的数据分组比较接口:**Groupingcomparator
reduceTask拿到输入数据(一个partition的所有数据)后,首先需要对数据进行分组,其分组的默认原则是key相同,然后对每一组kv数据调用一次reduce()方法,并且将这一组kv中的第一个kv的key作为参数传给reduce的key,将这一组数据的value的迭代器传给reduce()的values参数
利用上述这个机制,我们可以实现一个高效的分组取最大值的逻辑:
自定义一个bean对象用来封装我们的数据,然后改写其compareTo方法产生倒序排序的效果
然后自定义一个Groupingcomparator,将bean对象的分组逻辑改成按照我们的业务分组id来分组(比如订单号)
这样,我们要取的最大值就是reduce()方法中传进来key
**5)逻辑处理接口:**Reducer
完全需要用户自己去实现其中 reduce() setup() clean()
**6)输出数据接口:**OutputFormat—> 有一系列子类FileOutputformat DBoutputFormat …
默认实现类是TextOutputFormat,功能逻辑是:将每一个KV对向目标文本文件中输出为一行
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
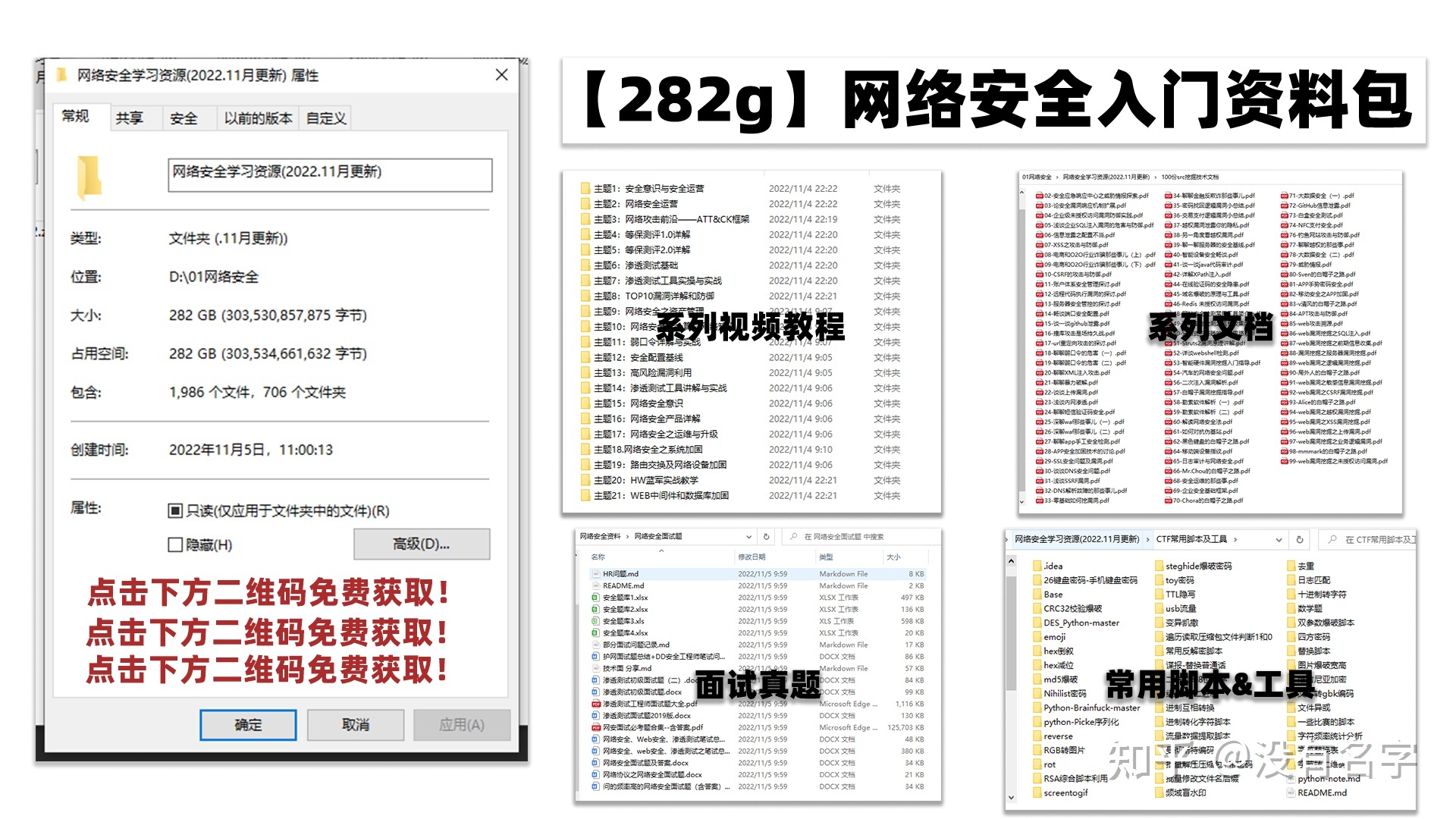
学习路线图
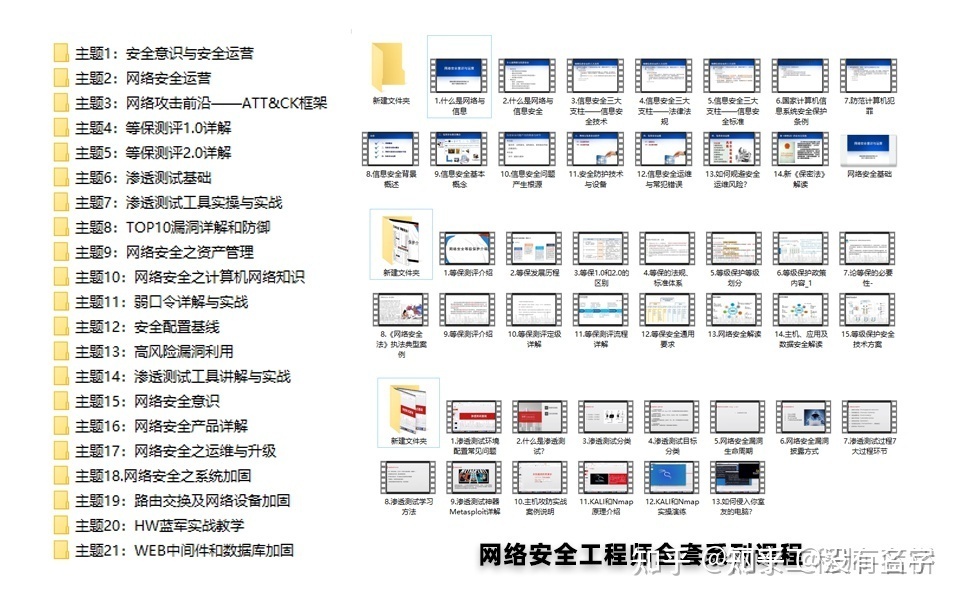
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
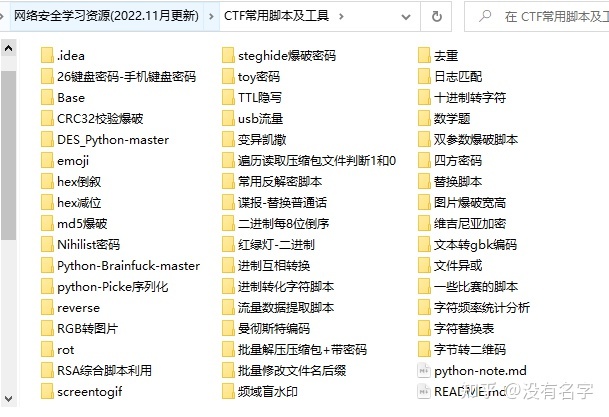
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









