






优化后的代码实现了一个完整的机器学习项目流程,涵盖了数据处理、特征工程、模型训练和结果输出等多个环节。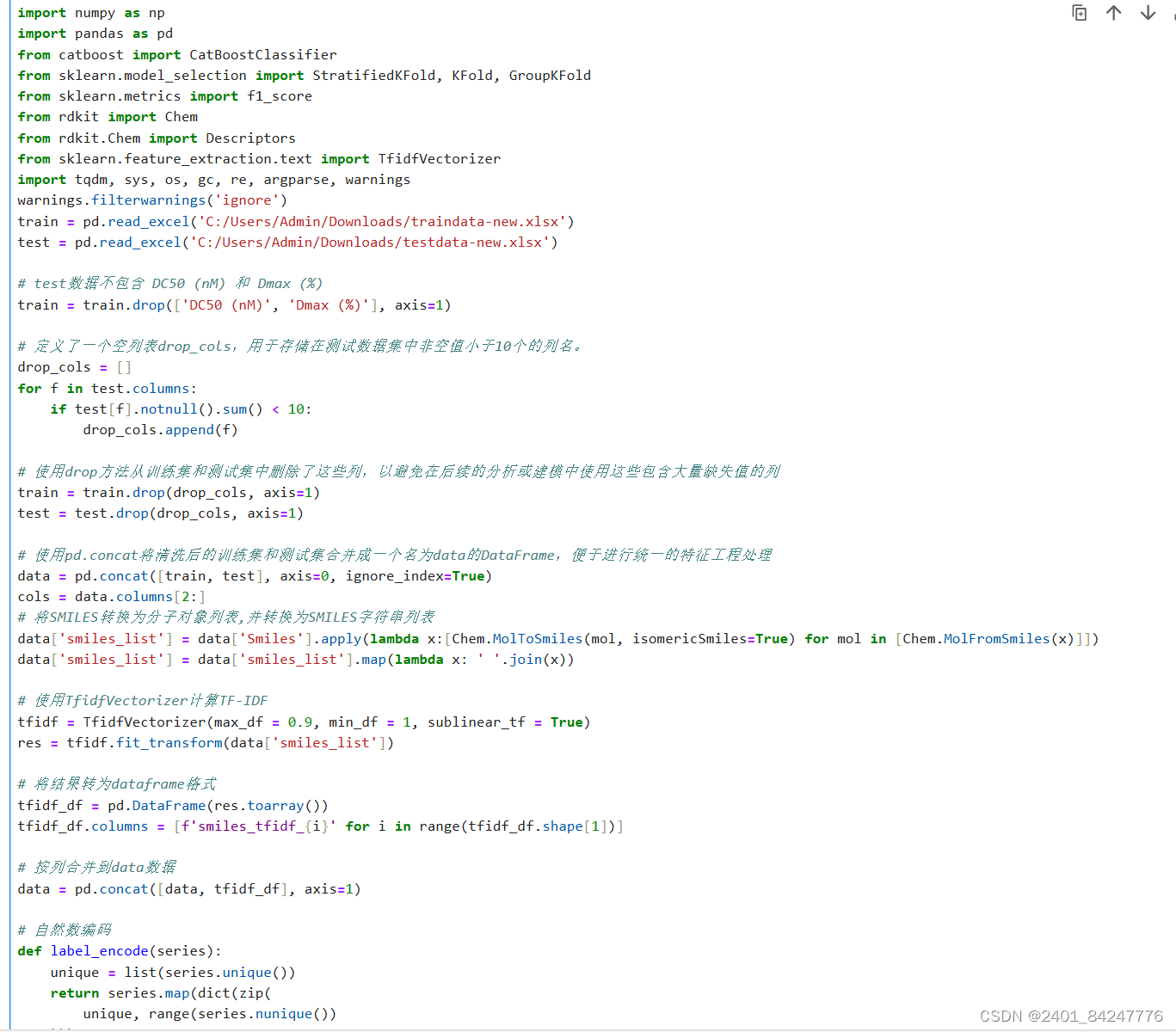
首先,代码开始导入必要的库和模块,包括 numpy、pandas、sklearn 中的 model_selection 模块和 metrics 模块,以及 CatBoost 库。这些库提供了丰富的功能和工具,用于数据处理、模型训练和评估等任务。
接着代码从 Excel 文件中读取训练数据和测试数据,分别存储为 train_data 和 test_data 变量。这两个数据集是机器学习任务的基础,通过对它们进行处理和建模,可以实现对化学结构数据的预测和分类。
然后,在数据处理部分,代码对数据进行了一系列预处理操作。首先,根据数据中的列名是否为 "test",将数据分为训练集和测试集,并分别存储为 train_df 和 test_df。接着代码对数据进行了清洗和处理,包括丢弃缺失值较多的列、重命名列名等操作,以确保数据的质量和完整性。
接着对化学结构 SMILES 数据进行处理,将其转换为分子对象列表 mol_list,并将分子对象转换为 SMILES 字符串列表 smiles_list。通过 TfidfVectorizer 对 SMILES 列进行 TF-IDF 计算,得到词频-逆文档频率的结果,并将其转换为 DataFrame 格式。这些操作旨在对化学结构数据进行特征提取和处理,为后续的建模和训练提供有力支持。
接下来对数据中的对象类型特征进行自然数编码,将类别型数据转换为数值型数据。通过 LabelEncoder 对对象类型列进行编码,将类别映射为数字,以便模型训练过程中能够处理这些特征。
在特征工程部分,代码进行了特征筛选和数据集划分的操作。首先根据数据的特征列和标签列,选择用于训练的特征,构建训练集和测试集的特征数据。然后将特征集合和标签集合拆分为训练特征、测试特征、训练标签和测试标签,供模型训练和评估使用。
在模型训练部分,代码定义了一个交叉验证函数 cv_model,用于模型的初始化、训练和评估。在该函数中使用 CatBoostClassifier 模型进行模型初始化,并调用 kf.split(train_x, train_y) 划分训练集为训练集和验证集。然后,通过模型的 fit 方法对训练集进行训练,输出训练和验证集的 AUC 评估指标,以监控模型在训练和验证集上的性能。
在模型评估部分,代码对验证集进行预测,并计算 F1 分数作为模型的评估指标。将模型预测的结果与验证集的真实标签进行比较,计算 F1 分数以衡量模型的准确性和泛化能力。通过循环执行交叉验证的过程,输出每次验证集的 F1 分数,以便评估模型在不同验证集上的表现。
最后,在结果输出部分,代码打印出每次交叉验证的 F1 分数列表,并计算 F1 分数的平均值和标准差。这些指标可以帮助评估模型的整体性能和稳定性,为进一步优化模型提供指导。同时,将模型预测的结果与测试集的 uuid 组合成 DataFrame,并输出为 CSV 文件,用于提交模型预测结果。
总体而言,优化后的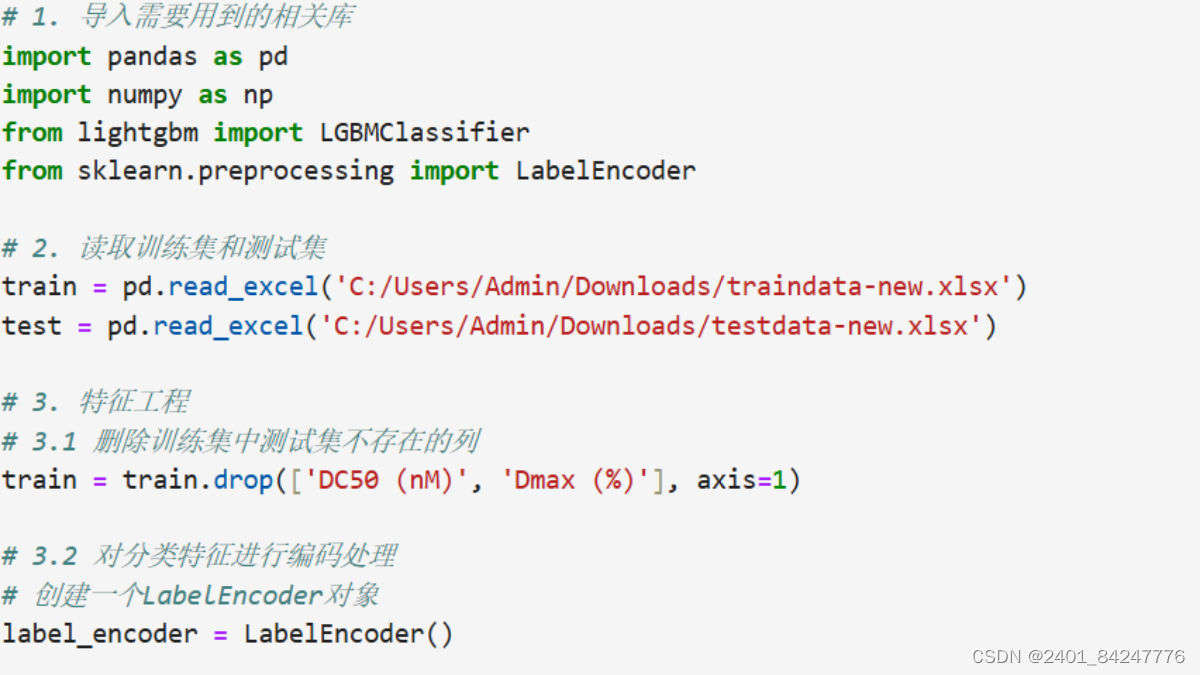 代码实现了一个完整的机器学习项目流程,涵盖了数据处理、特征工程、模型训练和评估等多个关键步骤。通过这些操作,可以有效地构建和评估机器学习模型,从而实现对化学结构数据的准确预测和分类。这种方法可以为实际问题的解决提供有力支持,帮助提高工作效率和预测准确性。
代码实现了一个完整的机器学习项目流程,涵盖了数据处理、特征工程、模型训练和评估等多个关键步骤。通过这些操作,可以有效地构建和评估机器学习模型,从而实现对化学结构数据的准确预测和分类。这种方法可以为实际问题的解决提供有力支持,帮助提高工作效率和预测准确性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









