







- 第一趟,找到数组中最小的元素1,将它和数组的第一个元素交换位置。
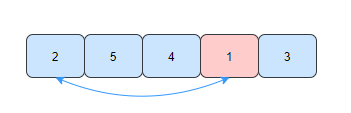
- 第二趟,在未排序的元素中找到最小的元素2,和数组的第二个元素交换位置。
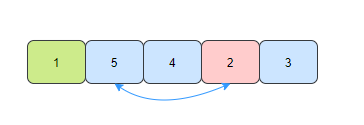
- 第三趟,在未排序的元素中找到最小的元素3,和数组的第三个元素交换位置。
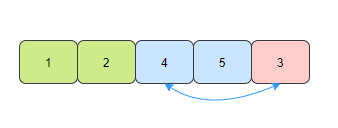
- 第四趟,在未排序的元素中找到最小的元素4,和数组的第四个元素交换位置。
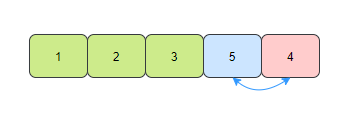
那么到这,我们的数组就是有序的了。
选择排序代码实现
选择排序的思路很简单,实现起来也不难。
public void sort(int[] nums) {
int min = 0;
for (int i = 0; i < nums.length - 1; i++) {
for (int j = i + 1; j < nums.length; j++) {
//寻找最小的数
if (nums[j] < nums[min]) {
min = j;
}
}
//交换
int temp = nums[i];
nums[i] = nums[min];
nums[min] = temp;
}
}
选择排序性能分析
选择排序稳定吗?
答案是不稳定的,因为在未排序序列中找到最小值之后,和排序序列的末尾元素交换。
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
插入排序
插入排序原理
关于插入排序,有一个非常形象的比喻。斗地主——摸到的牌都是乱的,我们会把摸到的牌插到合适的位置。
它的思路:将一个元素插入到已经排好序的有序序列中,从而得到一个新的有序序列。
动图如下(来源参考3):
还是以数组[2,5,4,1,3]为例:
- 第一趟:从未排序的序列将元素5插入到已排序的序列的合适位置

- 第二趟:接着从未排序的序列中,将元素4插入到已经排序的序列的合适位置,需要遍历有序序列,找到合适的位置

- 第三趟:继续,把1插入到合适的位置

- 第五趟:继续,把3插入到合适的位置

OK,排序结束。
插入排序代码实现
找到插入元素的位置,移动其它元素。
public void sort(int[] nums) {
//无序序列从1开始
for (int i = 1; i < nums.length; i++) {
//需要插入有序序列的元素
int value = nums[i];
int j = 0;
for (j = i - 1; j >= 0; j--) {
//移动数据
if (nums[j] > value) {
nums[j + 1] = nums[j];
} else {
break;
}
}
//插入元素
nums[j + 1] = value;
}
}
插入排序性能分析
插入排序智慧移动比插入元素大的元素,所以相同元素相对位置不变,是稳定的。
从代码里我们可以看出,如果找到了合适的位置,就不会再进行比较了,所以最好情况时间复杂度是O(n)。
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 插入排序 | O(n) | O(n²) | O(n²) | O(1) | 稳定 |
希尔排序
希尔排序原理
希尔排序,名字来自它的发明者Shell。它是直接插入排序的改进版。
希尔排序的思路是:把整个待排序的记录序列分割成若干个子序列,分别进行插入排序。
我们知道直接插入排序在面对大量无序数据的时候不太理想,希尔排序就是通过跳跃性地移动,来达到数组元素地基本有序,再接着用直接插入排序。
希尔排序动图(动图来源参考[1]):

还是以数组[2,5,6,1,7,9,3,8,4]为例,我们来看一下希尔排序的过程:
- 数组元素个数为9,取7/2=4为下标差值,将下标差值为4的元素分为一组

- 组内进行插入排序,构成有序序列
- 再取4/2=2为 下标差值,将下标差值为2的元素分为一组

- 组内插入排序,构成有序序列
- 下标差值=2/2=1,将剩余的元素插入排序
希尔排序代码实现
可以看看前面的插入排序,希尔排序
只是一个有步长的直接插入排序。
public void sort(int[] nums){
//下标差
int step=nums.length;
while (step>0){
//这个是可选的,也可以是3
step=step/2;
//分组进行插入排序
for (int i=0;i<step;i++){
//分组内的元素,从第二个开始
for (int j=i+step;j<nums.length;j+=step){
//要插入的元素
int value=nums[j];
int k;
for (k=j-step;k>=0;k-=step){
if (nums[k]>value){
//移动组内元素
nums[k+step]=nums[k];
}else {
break;
}
}
//插入元素
nums[k+step]=value;
}
}
}
}
希尔排序性能分析
- 稳定度分析
希尔排序是直接插入排序的变形,但是和直接插入排序不同,它进行了分组,所以不同组的相同元素的相对位置可能会发生改变,所以它是不稳定的。
- 时间复杂度分析
希尔排序的时间复杂度跟增量序列的选择有关,范围为 O(n^(1.3-2)) 在此之前的排序算法时间复杂度基本都是 O(n²),希尔排序是突破这个时间复杂度的第一批算法之一。
| 算法名称 | 时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|
| 希尔排序 | O(n^(1.3-2)) | O(1) | 不稳定 |
归并排序
归并排序原理
归并排序是建立在归并操作上的一种有效的排序算法,归并,就是合并的意思,在数据结构上的定义就是把把若干个有序序列合并成一个新的有序序列。
归并排序是分治法的典型应用,分治什么意思呢?就是把一个大的问题分解成若干个小的问题来解决。
归并排序的步骤,是把一个数组切分成两个,接着递归,一直到单个元素,然后再合并,单个元素合并成小数组,小数组合并成大数组。
动图如下(来源参考[4]):
我们以数组[2,5,6,1,7,3,8,4] 为例,来看一下归并排序的过程:
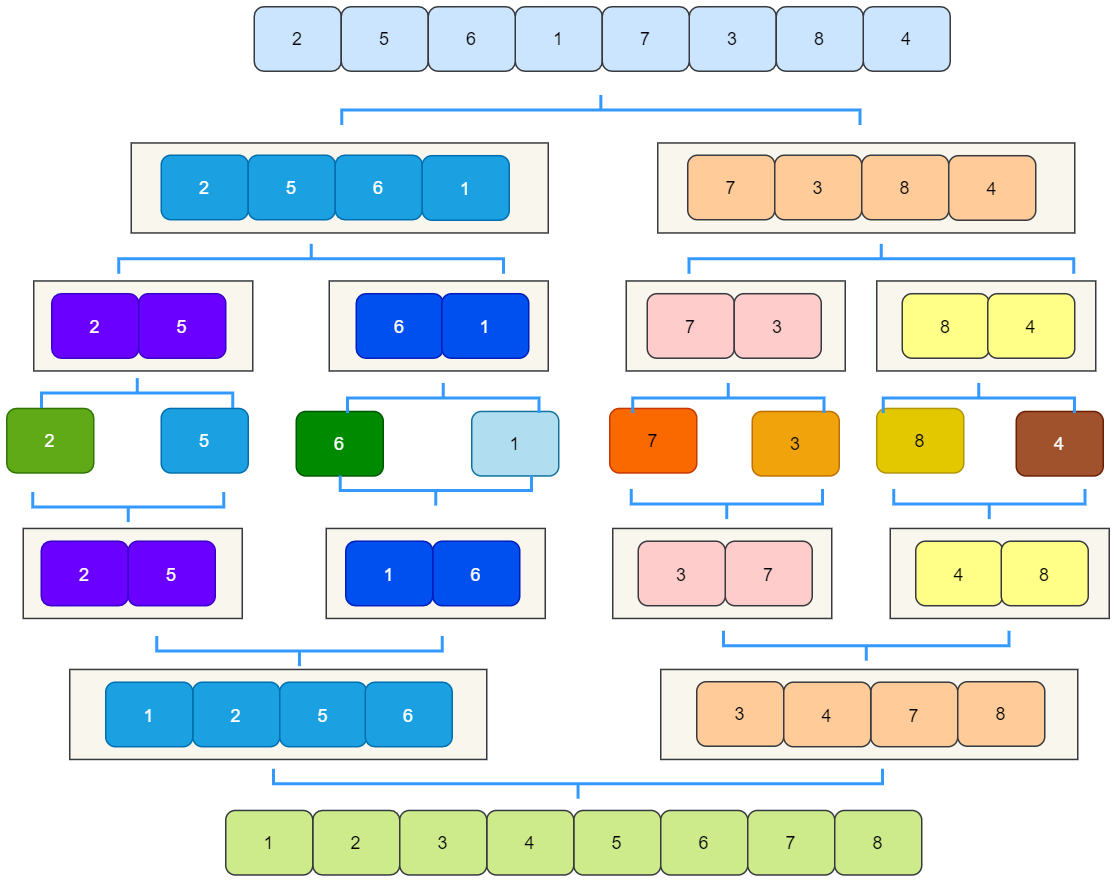
拆分就不用多讲了,我们看看怎么合并。
归并排序代码实现
这里使用递归来实现归并排序:
- 递归终止条件
递归起始位置小于终止位置
- 递归返回结果
直接对传入的数组序列进行排序,所以无返回值
- 递归逻辑
将当前数组分成两组,分别分解两组,最后归并
代码如下:
public class MergeSort {
public void sortArray(int[] nums) {
sort(nums, 0, nums.length - 1);
}
/\*\*
\* 归并排序
\*
\* @param nums
\* @param left
\* @param right
\*/
public void sort(int[] nums, int left, int right) {
//递归结束条件
if (left >= right) {
return;
}
int mid = left + (right - left) / 2;
//递归当前序列左半部分
sort(nums, left, mid);
//递归当前序列右半部分
sort(nums, mid + 1, right);
//归并结果
merge(nums, left, mid, right);
}
/\*\*
\* 归并
\*
\* @param arr
\* @param left
\* @param mid
\* @param right
\*/
public void merge(int[] arr, int left, int mid, int right) {
int[] tempArr = new int[right - left + 1];
//左边首位下标和右边首位下标
int l = left, r = mid + 1;
int index = 0;
//把较小的数先移到新数组中
while (l <= mid && r <= right) {
if (arr[l] <= arr[r]) {
tempArr[index++] = arr[l++];
} else {
tempArr[index++] = arr[r++];
}
}
//把左边数组剩余的数移入数组
while (l <= mid) {
tempArr[index++] = arr[l++];
}
//把右边剩余的数移入数组
while (r <= right) {
tempArr[index++] = arr[r++];
}
//将新数组的值赋给原数组
for (int i = 0; i < tempArr.length; i++) {
arr[i+left] = tempArr[i];
}
}
}
归并排序性能分析
- 时间复杂度
一趟归并,我们需要把遍历待排序序列遍历一遍,时间复杂度O(n)。
而归并排序的过程,需要把数组不断二分,这个时间复杂度是O(logn)。
所以归并排序的时间复杂度是O(nlogn)。
- 空间复杂度
使用了一个临时数组来存储合并的元素,空间复杂度O(n)。
- 稳定性
归并排序是一种稳定的排序方法。
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
快速排序
快速排序原理
快速排序是面试最高频的排序算法。
快速排序和上面的归并排序一样,都是基于分治思想的,大概过程:
- 选出一个基准数,基准值一般取序列最左边的元素
- 重新排序序列,比基准值小的放在基准值左边,比基准值大的放在基准值右边,这就是所谓的分区
快速排序动图如下:
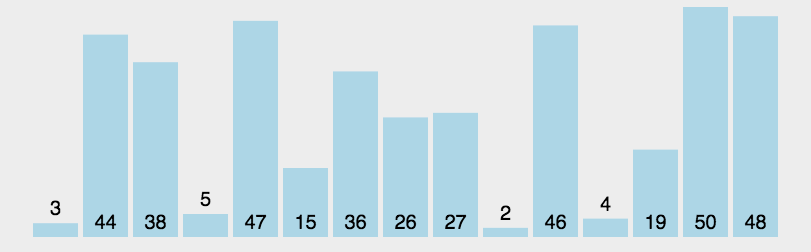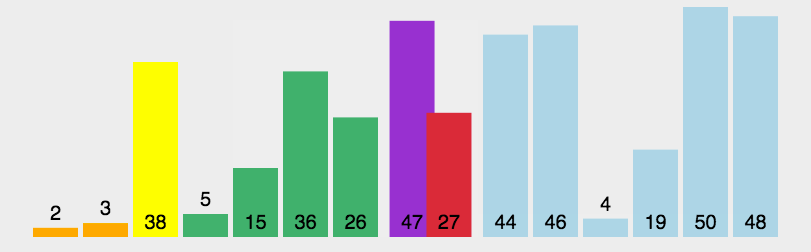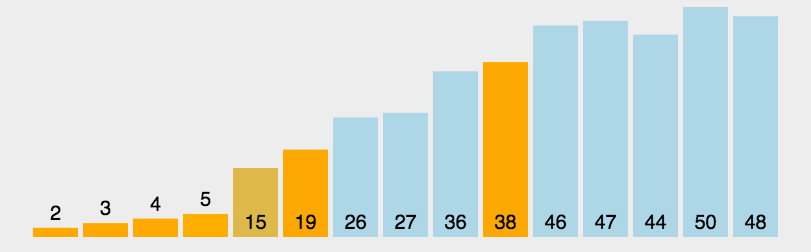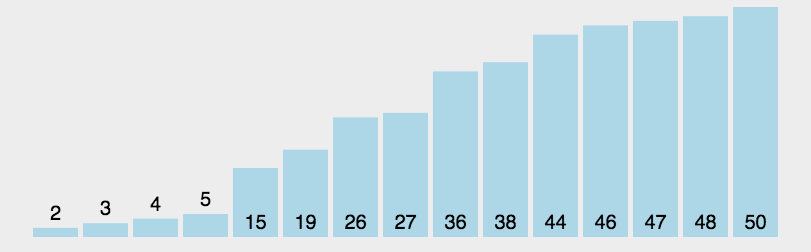
我们来看一个完整的快速排序图示:
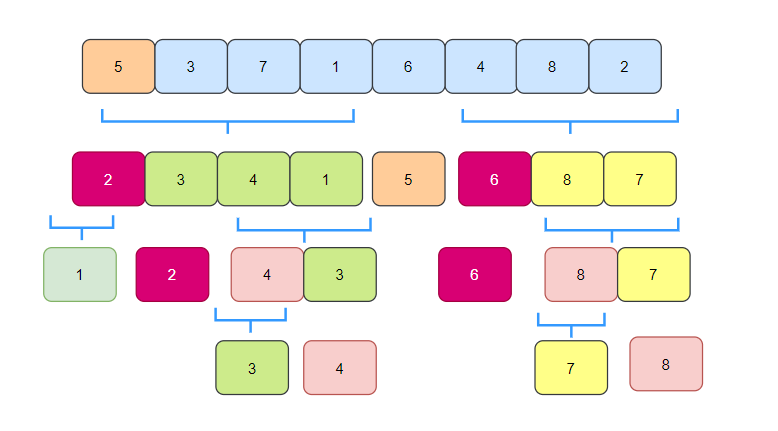
快速排序代码实现
单边扫描快速排序
选择一个数作为基准数pivot,同时设定一个标记 mark 代表左边序列最右侧的下标位置,接下来遍历数组,如果元素大于基准值,无操作,继续遍历,如果元素小于基准值,则把 mark + 1 ,再将 mark 所在位置的元素和遍历到的元素交换位置,mark 这个位置存储的是比基准值小的数据,当遍历结束后,将基准值与 mark 所在元素交换位置。
public class QuickSort0 {
public void sort(int[] nums) {
quickSort(nums, 0, nums.length - 1);
}
public void quickSort(int[] nums, int left, int right) {
//结束条件
if (left >= right) {
return;
}
//分区
int partitonIndex = partion(nums, left, right);
//递归左分区
quickSort(nums, left, partitonIndex - 1);
//递归右分区
quickSort(nums, partitonIndex + 1, right);
}
//分区
public int partion(int[] nums, int left, int right) {
//基准值
int pivot = nums[left];
//mark标记初始下标
int mark = left;
for (int i = left + 1; i <= right; i++) {
if (nums[i] < pivot) {
//小于基准值,则mark+1,并交换位置
mark++;
int temp = nums[mark];
nums[mark] = nums[i];
nums[i] = temp;
}
}
//基准值与mark对应元素调换位置
nums[left] = nums[mark];
nums[mark] = pivot;
return mark;
}
}
双边扫描快速排序
还有另外一种双边扫描的做法。
选择一个数作为基准值,然后从数组左右两边进行扫描,先从左往右找到一个大于基准值的元素,将它填入到right指针位置,然后转到从右往左扫描,找到一个小于基准值的元素,将他填入到left指针位置。
public class QuickSort1 {
public int[] sort(int[] nums) {
quickSort(nums, 0, nums.length - 1);
return nums;
}
public void quickSort(int[] nums, int low, int high) {
if (low < high) {
int index = partition(nums, low, high);
quickSort(nums, low, index - 1);
quickSort(nums, index + 1, high);
}
}
public int partition(int[] nums, int left, int right) {
//基准值
int pivot = nums[left];
while (left < right) {
//从右往左扫描
while (left < right && nums[right] >= pivot) {
right--;
}
//找到第一个比pivot小的元素
if (left < right) nums[left] = nums[right];
//从左往右扫描
while (left < right && nums[left] <= pivot) {
left++;
}
//找到第一个比pivot大的元素
if (left < right) nums[right] = nums[left];
}
//基准数放到合适的位置
nums[left] = pivot;
return left;
}
}
快速排序性能分析
- 时间复杂度
快速排序的时间复杂度和归并排序一样,都是O(nlogn),但是这是最优的情况,也就是每次都能把数组切分到两个差不多大小的子数组。
如果出现极端情况,例如一个有序的序列[5,4,3,2,1] ,选基准值为5,那么需要切分n-1次才能完成整个快速排序的过程,这种情况时间复杂度就退化到了O(n²)。
- 空间复杂度
快速排序是一种原地排序的算法,空间复杂度是O(1)。
- 稳定性
快排的比较和交换是跳跃进行的,所以快排是一种不稳定的排序算法。
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(n²) | O(nlogn) | O(1) | 不稳定 |
堆排序
堆排序原理
还记得我们前面的简单选择排序吗?堆排序是简单选择排序的一种升级版。
在学习堆排序之前,什么是堆呢?
完全二叉树是堆的一个比较经典的堆实现。
我们先来了解一下什么是完全二叉树。
简答说,如果节点不满,那它不满的部分只能在最后一层的右侧。
我们来看几个示例。
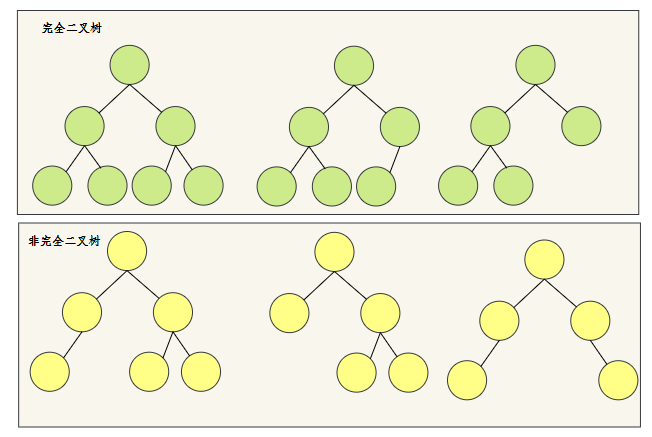
相信看了这几个示例,就清楚什么是完全二叉树,什么是非完全二叉树。
那堆又是什么呢?
- 必须是完全二叉树
- 任一节点的值必须是其子树的最大值或最小值
- 最大值时,称为“最大堆”,也称大顶堆;
- 最小值时,称为“最小堆”,也称小顶堆。
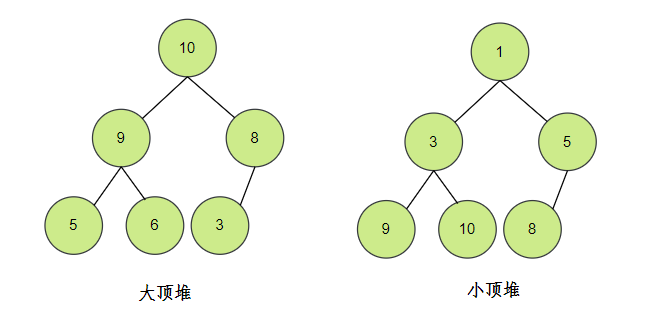
因为堆是完全二叉树,所以堆可以用数组存储。
按层来将元素存储到数组对应位置,从下标1开始存储,可以省略一些计算。
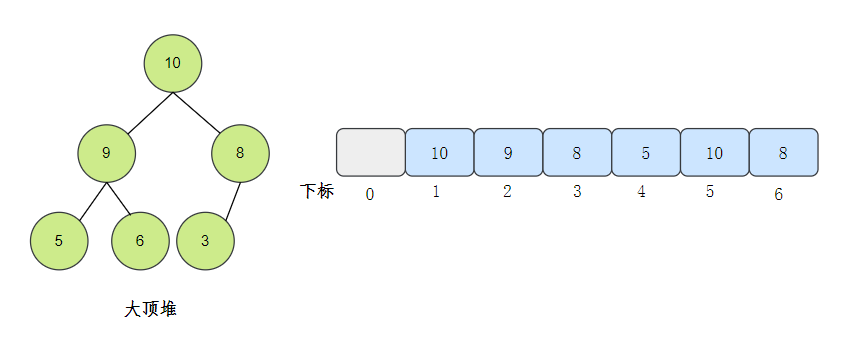
好了,我们现在对堆已经有一些了解了,我们来看一下堆排序是什么样的呢?[2]
- 建立一个大顶堆
- 将堆顶元素(最大值)插入数组末尾
- 让新的最大元素上浮到堆顶
- 重复过程,直到排序完成
动图如下(来源参考[1]):
![堆排序动图(来自参考[1])](https://img-blog.csdnimg.cn/img_convert/97f1b4c39a91149ee6a64b0d6fb47ae3.gif)
关于建堆,有两种方式,一种是上浮,一种是下沉。
上浮是什么呢?就是把子节点一层层上浮到合适的位置。
下沉是什么呢?就是把堆顶元素一层层下沉到合适的位置。
上面的动图,使用的就是下沉的方式。
堆排序代码实现
public class HeapSort {
public void sort(int[] nums) {
int len = nums.length;
//建堆
buildHeap(nums, len);
for (int i = len - 1; i > 0; i--) {
//将堆顶元素和堆末元素调换
swap(nums, 0, i);
//数组计数长度减1,隐藏堆尾元素
len--;
//将堆顶元素下沉,使最大的元素浮到堆顶来
sink(nums, 0, len);
}
}
/\*\*
\* 建堆
\*
\* @param nums
\* @param len
\*/
public void buildHeap(int[] nums, int len) {
for (int i = len / 2; i >= 1; i--) {
//下沉
sink(nums, i, len);
}
}
/\*\*
\* 下沉操作
\*
\* @param nums
\* @param index
\* @param end
\*/
public void sink(int[] nums, int index, int end) {
//左子节点下标
int leftChild = 2 \* index + 1;
//右子节点下标
int rightChild = 2 \* index + 2;
//要调整的节点下标
int current = index;
//下沉左子树
if (leftChild < end && nums[leftChild] > nums[current]) {
current = leftChild;
}
//下沉右子树
if (rightChild < end && nums[rightChild] > nums[current]) {
current = rightChild;
}
//如果下标不相等,证明调换过了
if (current!=index){
//交换值
swap(nums,index,current);
//继续下沉
sink(nums,current,end);
}
}
public void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
堆排序性能分析
- 时间复杂度
堆排的时间复杂度和快排的时间复杂度一样,都是O(nlogn)。
- 空间复杂度
堆排没有引入新的空间,原地排序,空间复杂度O(1)。
- 稳定性
堆顶的元素不断下沉,交换,会改变相同元素的相对位置,所以堆排是不稳定的。
| 算法名称 | 时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|
| 堆排序 | O(nlogn) | O(1) | 不稳定 |
计数排序
文章开始我们说了,排序分为比较类和非比较类,计数排序是一种非比较类的排序方法。
计数排序是一种线性时间复杂度的排序,利用空间来换时间,我们来看看计数排序是怎么实现的吧。
计数排序原理
计数排序的大致过程[4]:
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组arr的第i项;
- 对所有的计数累加(从arr中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第arr(i)项,每放一个元素就将arr(i)减去1。
我们看一下动图演示(来自参考[4]):
![计数排序动图,来自参考[4]](https://img-blog.csdnimg.cn/img_convert/abc8b11c17175cafd5182bdbb222ebdd.gif)
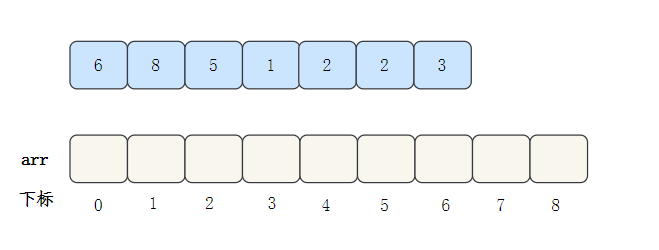
我们拿一个数组来看一下完整过程:[6,8,5,1,2,2,3]
- 首先,找到数组中最大的数,也就是8,创建一个最大下标为8的空数组arr
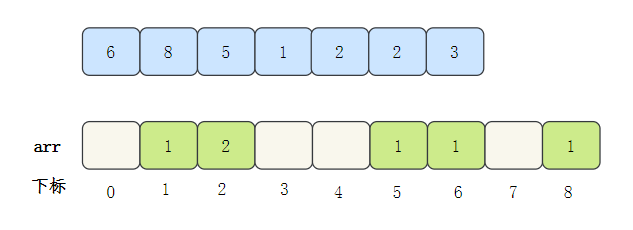
- 遍历数据,将数据的出现次数填入arr对应的下标位置中
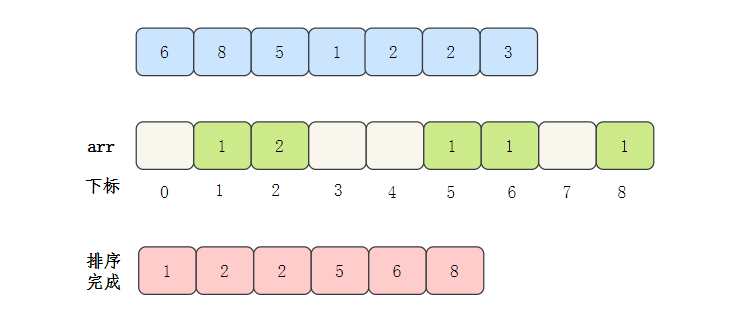
- 然后输出数组元素的下标值,元素的值是几,就输出几次
计数排序代码实现
public class CountSort {
public void sort(int[] nums) {
//查找最大值
int max = findMax(nums);
//创建统计次数新数组
int[] countNums = new int[max + 1];
//将nums元素出现次数存入对应下标
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
countNums[num]++;
nums[i] = 0;
}
//排序
int index = 0;
for (int i = 0; i < countNums.length; i++) {
while (countNums[i] > 0) {
nums[index++] = i;
countNums[i]--;
}
}
}
public int findMax(int[] nums) {
int max = nums[0];
for (int i = 0; i < nums.length; i++) {
if (nums[i] > max) {
max = nums[i];
}
}
return max;
}
}
OK,乍一看没啥问题,但是仔细想想,其实还是有些毛病的,毛病在哪呢?
- 如果我们要排序的元素有0怎么办呢?例如
[0,0,5,2,1,3,4],arr初始都为0,怎么排呢?
这个很难解决,有一种办法,就是计数的时候原数组先加10,[-1,0,2],排序写回去的时候再减,但是如果刚好碰到有-10这个元素就凉凉。
- 如果元素的范围很大呢?例如
[9992,9998,9993,9999],那我们申请一个10000个元素的数组吗?
这个可以用偏移量解决,找到最大和最小的元素,计算偏移量,例如[9992,9998,9993,9999],偏移量=9999-9992=7,我们只需要建立一个容量为8的数组就可以了。
解决第二个问题的版本如下:
public class CountSort1 {
public void sort(int[] nums) {
//查找最大值
int max = findMax(nums);
//寻找最小值
int min = findMin(nums);
//偏移量
int gap = max - min;
//创建统计次数新数组
int[] countNums = new int[gap + 1];
//将nums元素出现次数存入对应下标
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
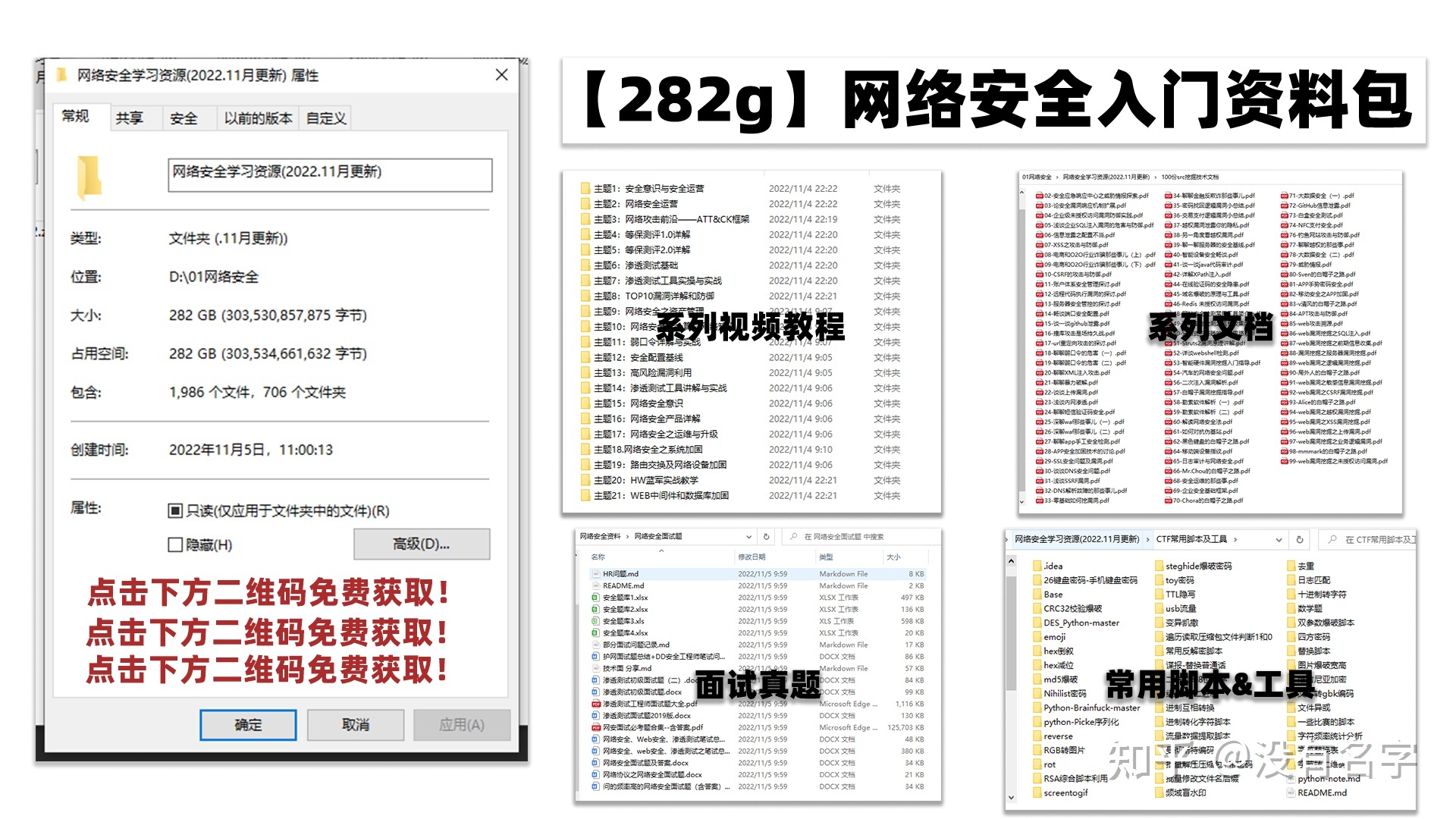
### 学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
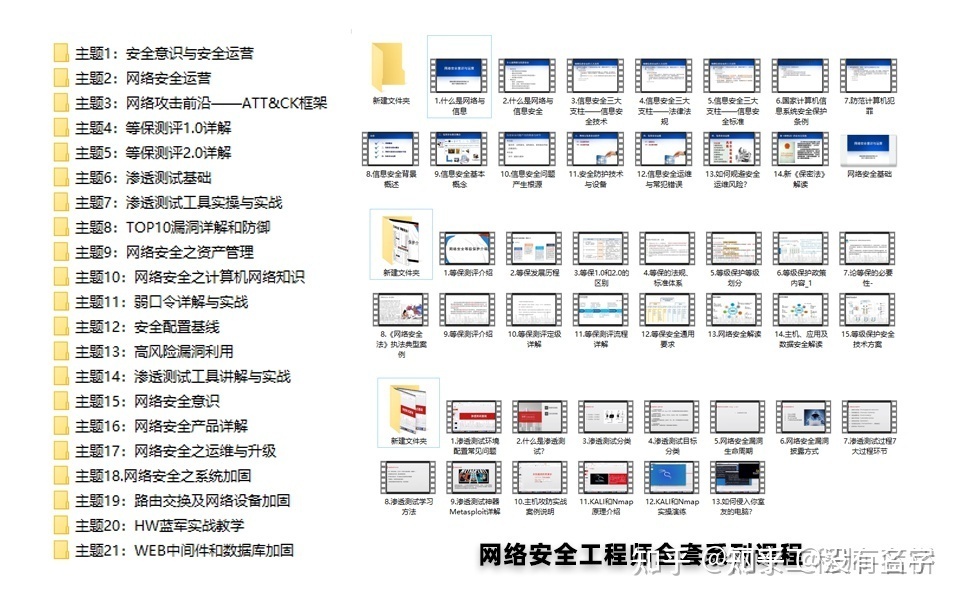
#### 网络安全工具箱
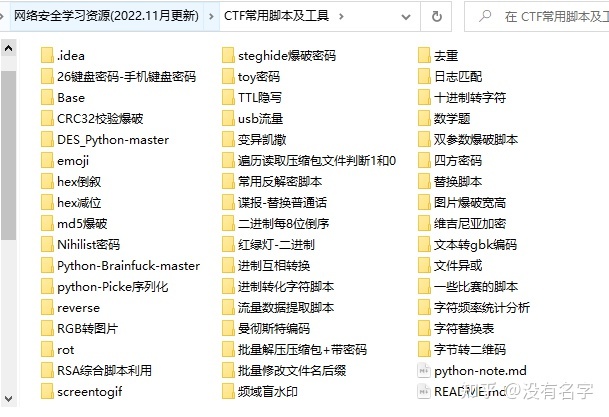
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份**我自己整理的网络安全入门工具以及使用教程和实战。**
#### 项目实战
最后就是项目实战,这里带来的是**SRC资料&HW资料**,毕竟实战是检验真理的唯一标准嘛~

#### 面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









