







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
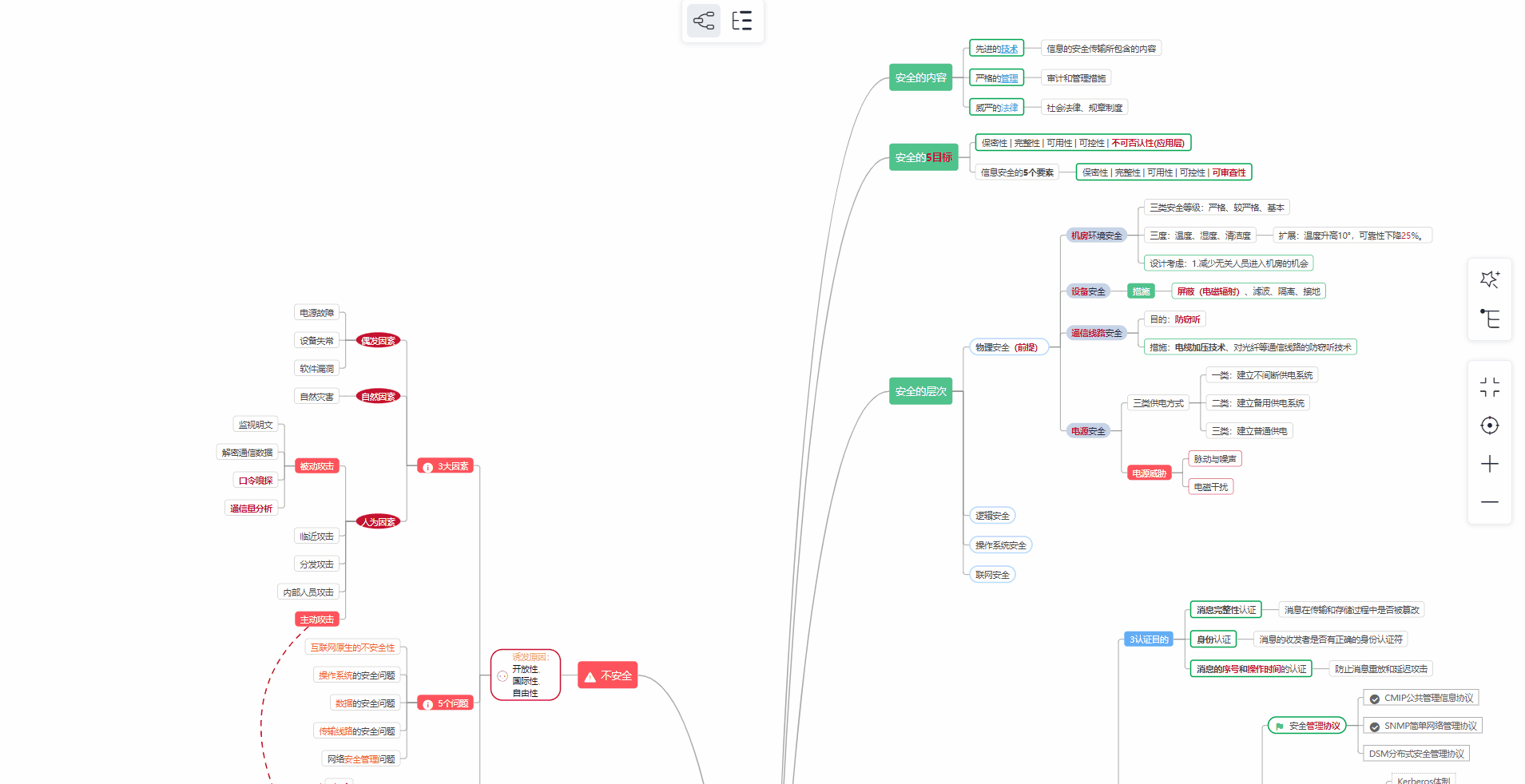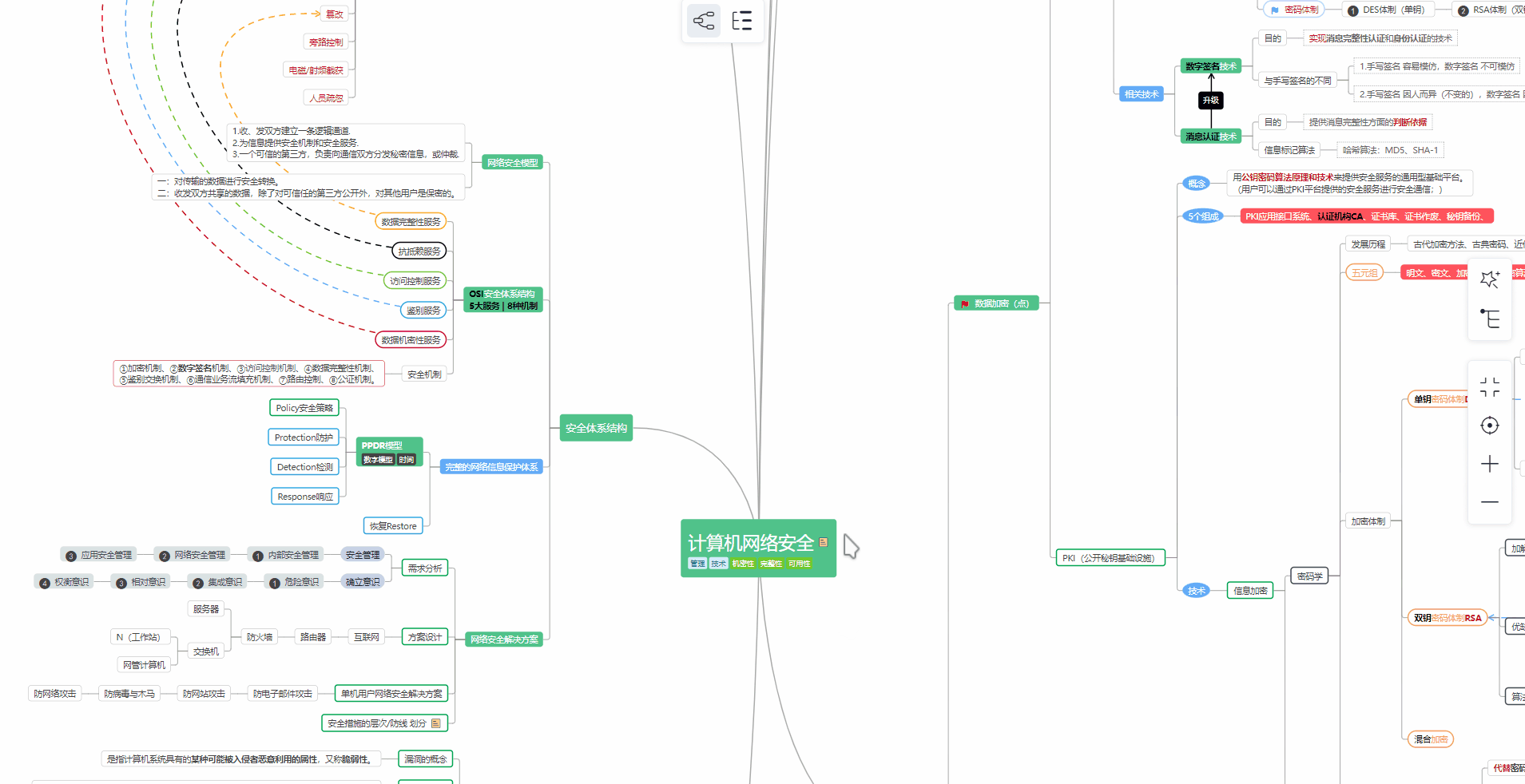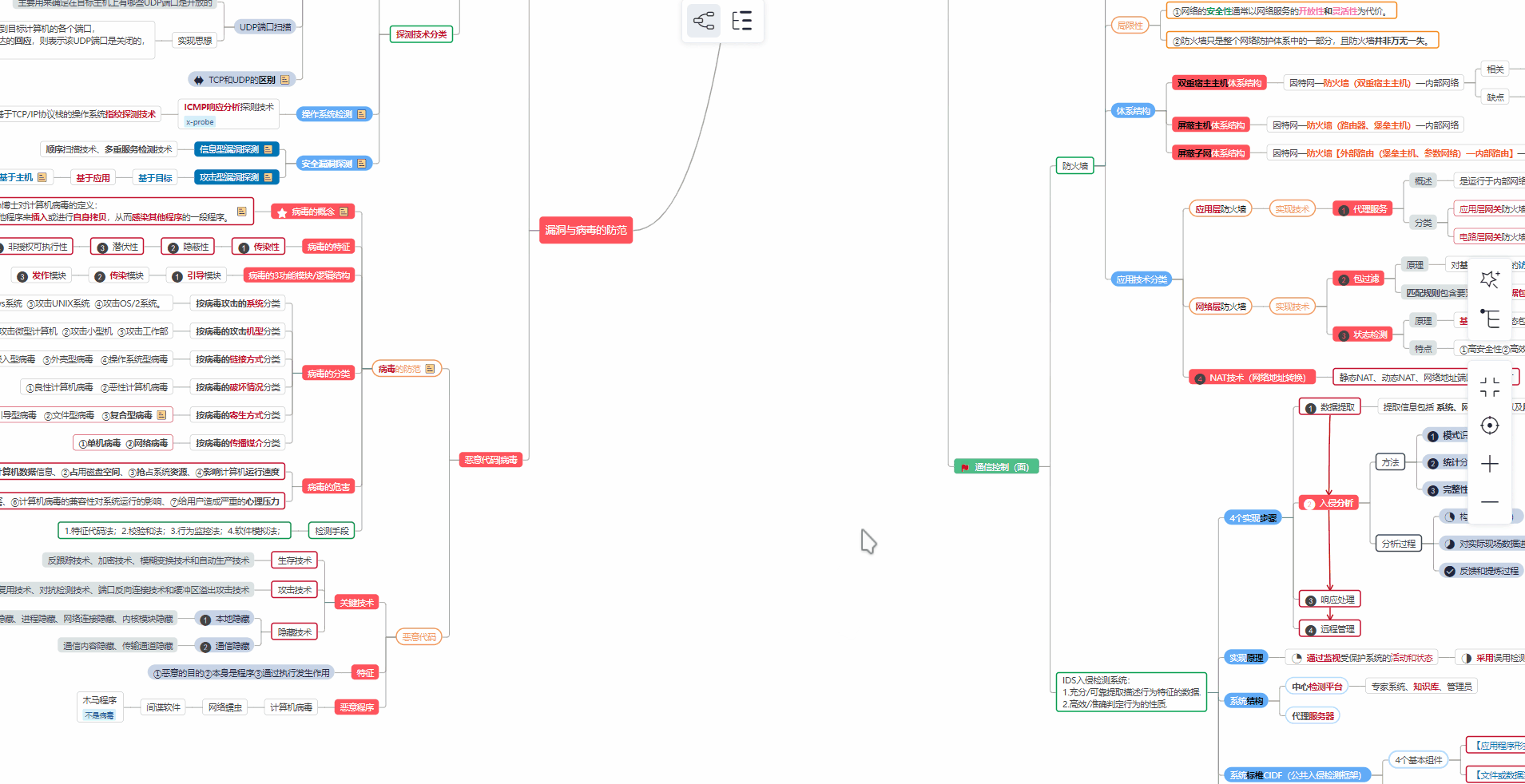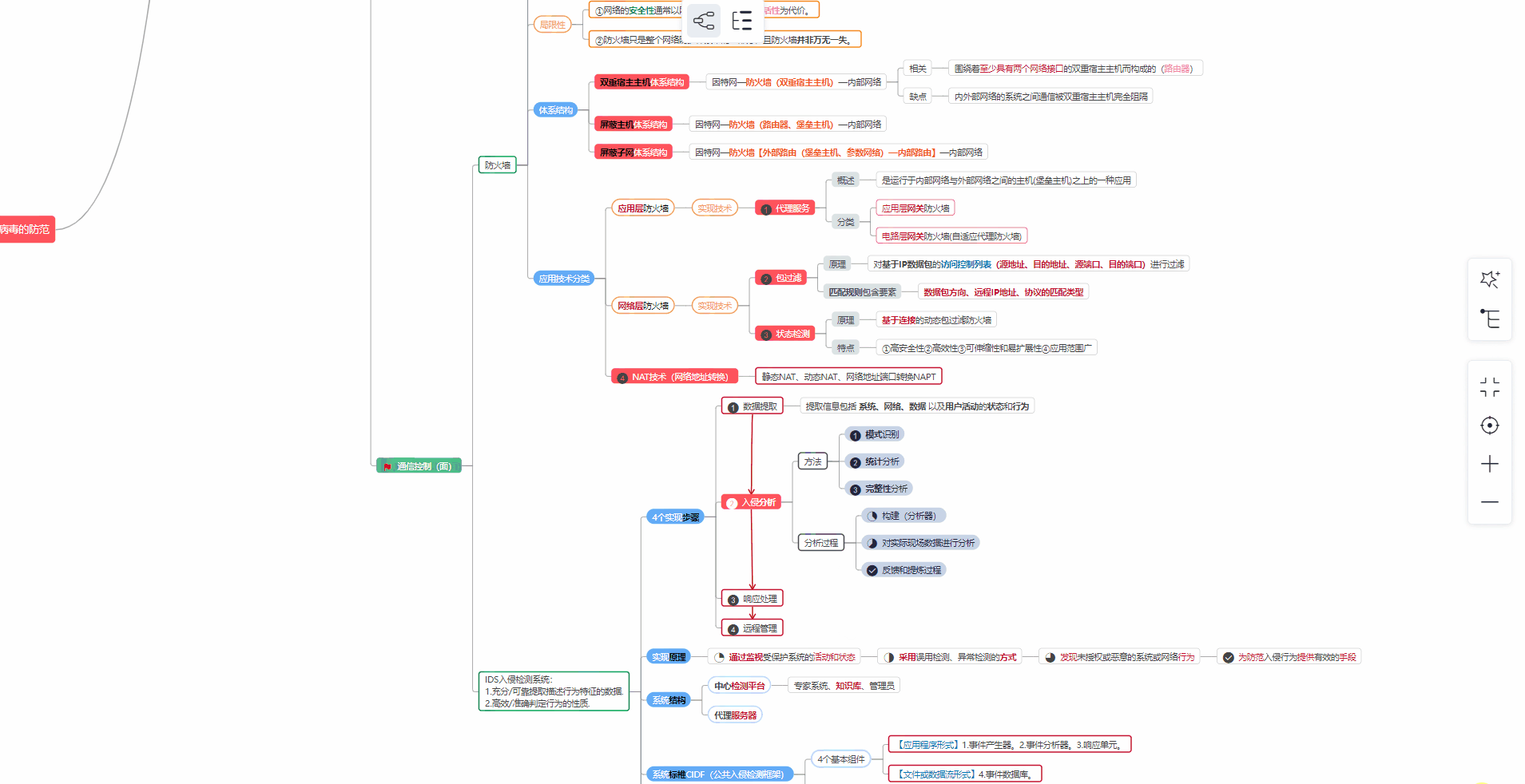
93道网络安全面试题
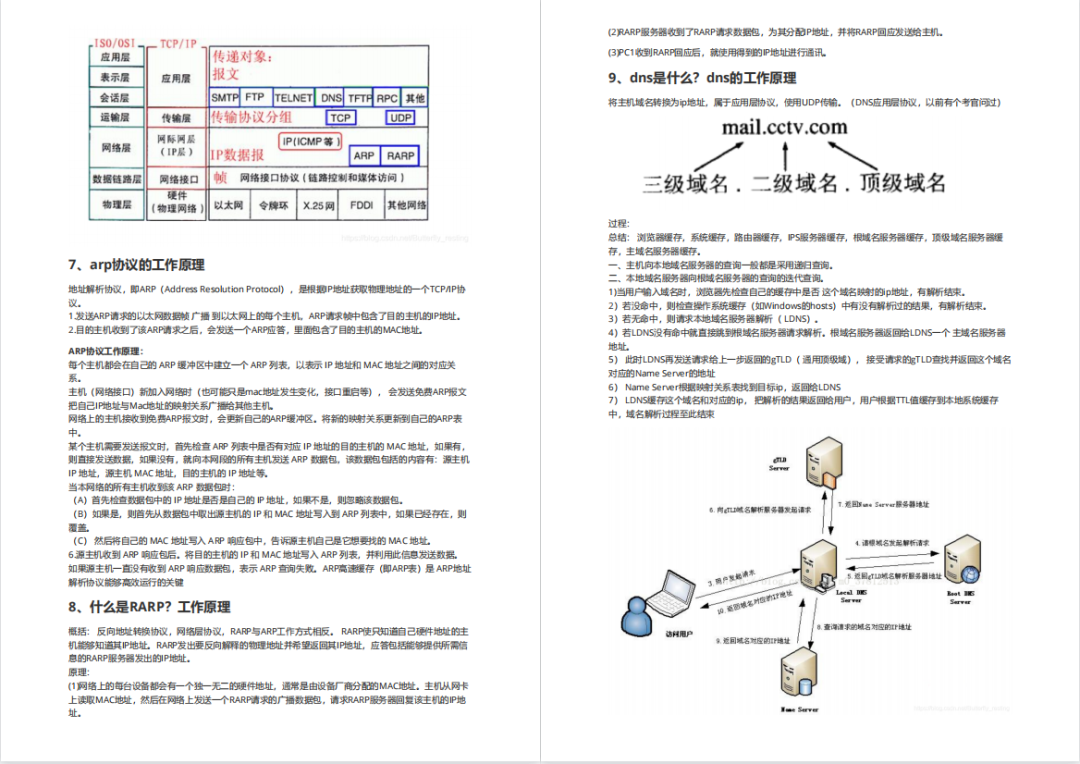


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
多用于本地测试,如在eclipse,idea中写程序测试等。
Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark 实现了这个接口,所以可以基于Yarn。
Mesos
资源调度框架。
SparkCore
RDD概念
RDD(Resilient Distributed Dateset),弹性分布式数据集。
RDD的五大特性
1、RDD是由一系列的partition组成的。(partition个数与HDFS中block个数对应)
2、函数是作用在每一个partition(split)上的。
3、RDD之间有一系列的依赖关系。
4、分区器是作用在K,V格式的RDD上。
5、RDD提供一系列最佳的计算位置。
RDD理解图
注意
textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小,每个split对应一个partition。
RDD实际上不存储数据。
什么是K,V格式的RDD?
如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
哪里体现RDD的弹性(容错)?
partition数量,大小没有限制,体现了RDD的弹性。
RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
哪里体现RDD的分布式?
RDD是由Partition组成,partition是分布在不同节点上的。
RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
Spark任务执行原理
以上图中有四个节点(机器),Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
Driver与集群节点之间有频繁的通信。
Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
Spark代码流程
1、创建SparkConf对象
可以设置Application name。
可以设置运行模式及资源需求。
2、创建SparkContext对象
3、基于Spark的上下文创建一个RDD,对RDD进行处理。
4、应用程序中要有Action类算子来触发Transformation类算子执行。
5、关闭Spark上下文对象SparkContext。
Transformations转换算子
概念:
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
Transformation类算子
filter
过滤符合条件的记录数,true保留,false过滤掉。
map
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
flatMap
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
sample
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
reduceByKey
将相同的Key根据相应的逻辑进行处理。
sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序。
Action行动算子
概念:
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
Action类算子
count
返回数据集中的元素数。会在结果计算完成后回收到Driver端。
take(n)
返回一个包含数据集前n个元素的集合。
first
first=take(1),返回数据集中的第一个元素。
foreach
循环遍历数据集中的每个元素,运行相应的逻辑。
collect
将计算结果回收到Driver端。
算子的基本使用
案例1:随机抽取words文件的数据
package com.gw.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TestSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("test");
val sc = new SparkContext(conf);
//读取文件
val lines = sc.textFile("./words");
/*
* sample算子:抽样
* 参数1:表示有无放回抽样,true表示放回
* 参数2:表示抽样比例
*/
val result = lines.sample(true, 0.1);
result.foreach(println);
sc.stop();
}
}
案例2:过滤并输出words文件中”hello hadoop”数据
package com.gw.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TestSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("test");
val sc = new SparkContext(conf);
//读取文件
val lines = sc.textFile("./words");
lines.filter(s=>{
s.equals("hello hadoop");
}).foreach(println);
sc.stop();
}
}
案例3:统计words文件中数据的数量
package com.gw.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TestSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local").setAppName("test");
val sc = new SparkContext(conf);
//读取文件
val lines = sc.textFile("./words");
val result = lines.count();
println(result);
sc.stop();
}
}
案例4:WordCount
package com.gw.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object TestSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("ScalaWordCount")
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 4102
4102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









