







url = ‘https://www.bilibili.com/v/popular/rank/all’
headers = {
“cookie”: “_uuid=7D3DFA6C-6EB1-F72A-632B-C9AF9B9AD4C627183infoc; buvid3=D25672DE-BD2D-4E7C-B79E-DB356316D023167639infoc; sid=aylq5kgg; fingerprint=84acc3579a53d0eba78d769e71574df6; buvid_fp=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; buvid_fp_plain=BA184AFC-F4DC-408A-8897-D0EDEA653CE5148812infoc; DedeUserID=434541726; DedeUserID__ckMd5=448fda6ab5098e5e; SESSDATA=78a505c8%2C1643594982%2Cdfa35*81; bili_jct=1d9f4e960fb0ae7fe1de53663029874b; bsource=search_baidu; CURRENT_FNVAL=80; blackside_state=1; rpdid=|(u)YJRR)m0J’uYk)ku)~~)”,
“referer”: “https://www.bilibili.com/”,
“user-agent”: “Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.8 Safari/537.36”
}
resp = requests.get(url, headers = headers, timeout=15)
ic(resp.text)
获取浏览器响应信息

接下来我们使用xpath获取标签内部的信息
for li in lis:
排名
sort = li.xpath(“./div[@class=‘num’]/text()”)
sort = ‘’.join(sort)
作者
author = li.xpath(“./div[@class=‘content’]/div[@class=‘info’]/div[@class=‘detail’]/a/span[@class=‘data-box up-name’]/text()”)
author = ‘’.join(author).strip()
综合得分
score = li.xpath(“./div[@class=‘content’]/div[@class=‘info’]/div[@class=‘pts’]/div/text()”)
score = ‘’.join(score)
视频标题
title = li.xpath(“./div[@class=‘content’]/div[@class=‘info’]/a[@class=‘title’]/text()”)
title = ‘’.join(title)
视频链接
links = li.xpath(“./div[@class=‘content’]/div[@class=‘img’]/a/@href”)
links = ‘’.join(links).strip()[2:]
播放数量
video_num = li.xpath(“./div[@class=‘content’]/div[@class=‘info’]/div[@class=‘detail’]/span[@class=‘data-box’][1]/text()”)
video_num = ‘’.join(video_num).strip()
弹幕数量
barrage_num = li.xpath(“./div[@class=‘content’]/div[@class=‘info’]/div[@class=‘detail’]/span[@class=‘data-box’][2]/text()”)
barrage_num = ‘’.join(barrage_num).strip()
作者详情
detail_auth = li.xpath(“.//div[@class=‘content’]/div[@class=‘info’]/div[@class=‘detail’]/a/@href”)
detail_auth = [‘https:’ + i for i in detail_auth]
detail_auth = ‘’.join(detail_auth)
ic(sort, author, score, title,links, video_num, barrage_num, detail_auth)
部分信息如下:
 数据保存
数据保存
接下来我们使用openpyxl模块将获取到的这些信息保存到excel中、
便于后续的数据处理和可视化
ws = op.Workbook()
wb = ws.create_sheet(index=0)
wb.cell(row=1, column=1, value=‘排名’)
wb.cell(row=1, column=2, value=‘作者’)
wb.cell(row=1, column=3, value=‘综合得分’)
wb.cell(row=1, column=4, value=‘视频标题’)
wb.cell(row=1, column=5, value=‘视频链接’)
wb.cell(row=1, column=6, value=‘播放数量’)
wb.cell(row=1, column=7, value=‘弹幕数量’)
wb.cell(row=1, column=8, value=‘作者详情’)
ws.save(‘哔哩哔哩Top100.xlsx’)


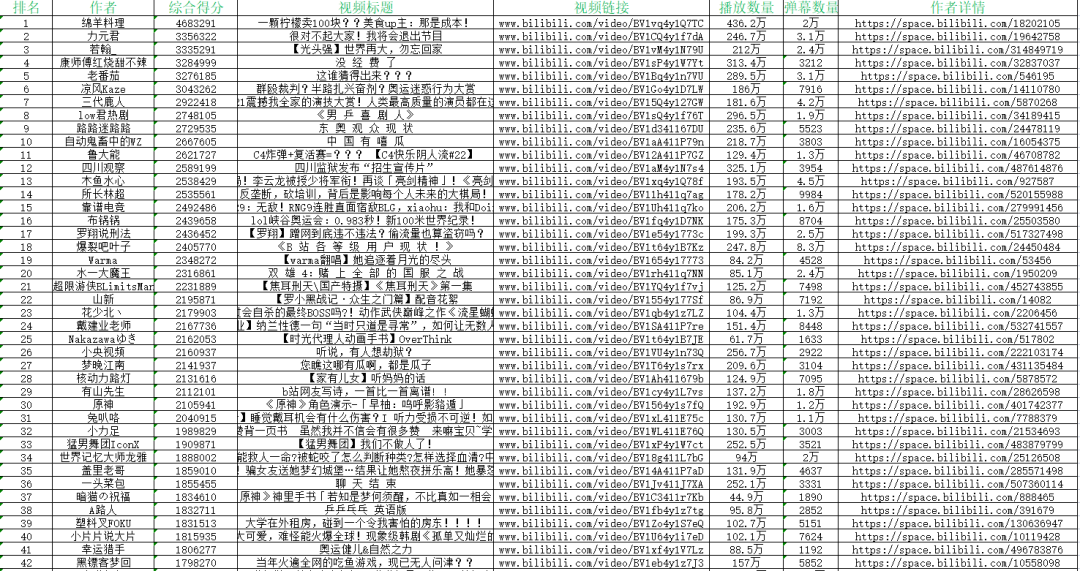

数据处理
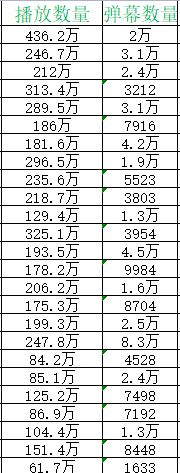
我们在处理数据的时候发现,有些数据的单位格式是不一致的,如下:
有些是个为单位,有些是以万为单位。
并且我们要将数字后面的’万‘字去掉,将字符串格式的数字转为数字类型的才便于后续的可视化操作。

里我们处理数据使用的是pandas,有不明白的小伙伴可以看看这份教程,这个是我自己总结的一份实用性很高的熊猫文档。
读取数据
df = pd.read_excel(‘哔哩哔哩Top100.xlsx’)
删除空格
pd_data = df.dropna(subset=[‘播放数量’, ‘弹幕数量’])
格式化数据播放数量
去除’万‘
pd_data[‘播放数量’] = pd_data[‘播放数量’].str.replace(‘万’, ‘’)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

9f49b566129f47b8a67243c1008edf79.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-vQ4bI0x3-1712789213770)]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









