







 本文介绍了如何利用Python库pytubes处理大量字符串数据,计算单词频率,并优化性能。作者通过实例展示了如何从十亿行数据中提取统计信息,同时探讨了谷歌的数据处理速度与自己的脚本之间的差距,以及如何改进pytubes的性能,如添加不同整型支持和过滤逻辑。最后,文章还涉及了网络安全学习路径和编程能力在该领域的关键性。
本文介绍了如何利用Python库pytubes处理大量字符串数据,计算单词频率,并优化性能。作者通过实例展示了如何从十亿行数据中提取统计信息,同时探讨了谷歌的数据处理速度与自己的脚本之间的差距,以及如何改进pytubes的性能,如添加不同整型支持和过滤逻辑。最后,文章还涉及了网络安全学习路径和编程能力在该领域的关键性。

通过提取这些信息,处理不同长度的字符串数据的额外消耗被忽略掉了,但是我们仍然需要对比不同字符串的数值来区分哪些行数据是有我们感兴趣的字段的。这就是 pytubes 可以做的工作:
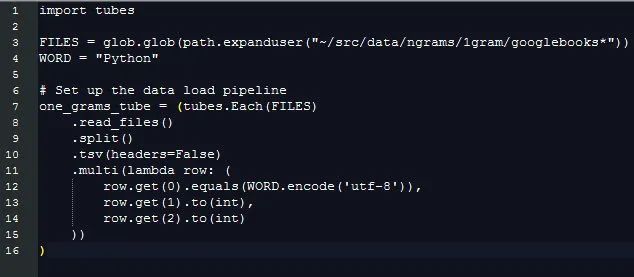
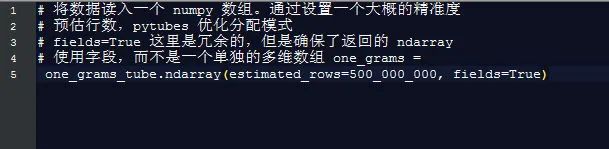
差不多 170 秒(3 分钟)之后, one_grams 是一个 numpy 数组,里面包含差不多 14 亿行数据,看起来像这样(添加表头部为了说明):
╒═══════════╤════════╤═════════╕ │ Is_Word │ Year │ Count │ ╞═══════════╪════════╪═════════╡ │ 0 │ 1799 │ 2 │ ├───────────┼────────┼─────────┤ │ 0 │ 1804 │ 1 │ ├───────────┼────────┼─────────┤ │ 0 │ 1805 │ 1 │ ├───────────┼────────┼─────────┤ │ 0 │ 1811 │ 1 │ ├───────────┼────────┼─────────┤ │ 0 │ 1820 │ … │ ╘═══════════╧════════╧═════════╛
从这开始,就只是一个用 numpy 方法来计算一些东西的问题了:
每一年的单词总使用量
谷歌展示了每一个单词出现的百分比(某个单词在这一年出现的次数/所有单词在这一年出现的总数),这比仅仅计算原单词更有用。为了计算这个百分比,我们需要知道单词总量的数目是多少。
幸运的是,numpy让这个变得十分简单:
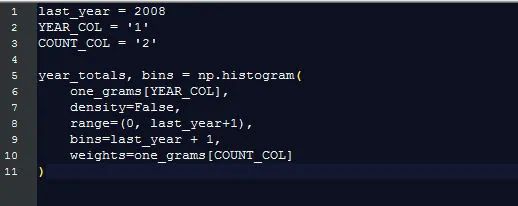
绘制出这个图来展示谷歌每年收集了多少单词:
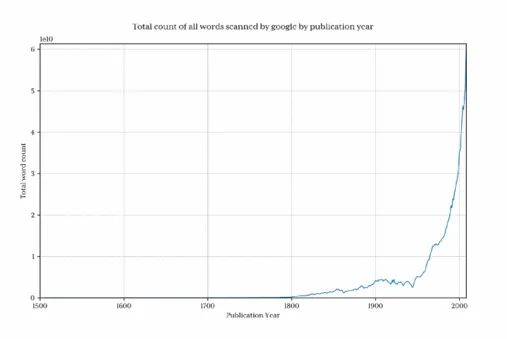
很清楚的是在 1800 年之前,数据总量下降很迅速,因此这回曲解最终结果,并且会隐藏掉我们感兴趣的模式。为了避免这个问题,我们只导入 1800 年以后的数据:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









