







首先,我们也从亚马逊获得了50,000条评论的数据集。正面和负面该数据集的评论已被标记。作为我们的机器学习培训集。这个过程是大概是这样的:形成训练集中所有单词的词汇表。例如,我们现在有一个“非常好”的评论,然后该评论被标记为1(1是一个正数,0是一个负数),因此假设此句子的每个单词,他的标签向量为[1]在此词汇表中排名2,555,666,8988,则相对词汇表的值向量这句话是[555,666,8988]。因为我们的数据集有50,000条评论,也就是说我们对于50,000个句子的相对字典,具有50,000个标签向量和词法值向量。因此,我们将这两个值发送给lstm进行机器学习并训练了最终模型。
下边是该模型的相关准确性和召回率

图3.2:相对精度和召回机器模型
3.3.2关于LSTM的一些知识
LSTM很详细的解释
e-init和init对象设置了LSTM权重和偏差的计算方式初始化。该演示程序创建一个Adam(“自适应矩估计”)优化器宾语。Adam是许多类型的深度神经网络的非常好的通用优化器。替代方案包括RMSprop,Adagrad和Adadelta。尽管可以输入整数-编码的句子直接传送到LSTM网络,通过转换每个句子可获得更好的结果将整数ID转换为实数值向量。例如,单词“ the”的索引值为4,但是会被转换为矢量(0.1234,0.5678,… 0.3572)。这称为单词嵌入。想法是构造向量,以便类似的词(例如“ man”和“ male”)具有向量在数字上接近。向量的长度必须通过反复试验确定。的演示使用32号大小,但对于大多数问题,矢量大小通常为100到500。为LSTM网络创建词嵌入的主要方法有三种。一种方法是使用诸如Word2Vec之类的外部工具来创建嵌入。第二种方法是使用一组预先构建的嵌入,例如GloVe(“用于词表示的全局向量”),使用Wikipedia的文字构建而成。该演示程序使用第三种方法,就是要动态创建嵌入。这些嵌入将特定于词汇表问题场景。指定Embedding()层后,演示程序将设置一个LSTM()层。LSTM是非常复杂的软件模块。你可以得到一个大概的主意通过查看图4.3中的图表,了解LSTM的工作原理。
图3.3:简化的LSTM单元
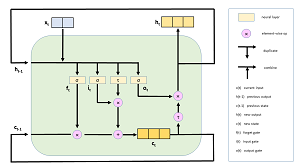
x(t)对象是在时间t的输入,它是单词嵌入。输出为h(t)。不像常规神经网络,LSTM具有状态,这使它们能够处理句子,下一个单词取决于前一个单词。在图中,c(t)是时间t的单元状态。注意输出h(t)取决于当前输入x(t)以及先前的输出h(t-1)和单元状态c(t)。出色!
LSTM网络具有最终的Dense()层,该层对LSTM()层的输出进行处理降低到0.0到1.0之间的单个数值。小于0.5的输出值映射到分类0表示否定,输出大于0.5表示肯定(1)审查。在您的情绪分析具有多种价值的情况下,您可以使用一键式负数=(1、0、0),中性数=(0、1、0),正数=(0、0、1)等编码。因此我们可以使用经过训练的模型进行预测:预测的结果如下(0表示差评,1表示肯定)

3.4拓扑评价模型Topsis方法
基于有限数量的评估对象与理想的目标。这是对现有对象的相对较好的评估。那里有两个理想目标,一个是积极理想目标或最佳目标,一个是消极理想目标或最坏的目标。最佳评估对象应最接近最佳目标,并且最差的目标。Topsis方法是用于理想目标相似性的顺序优化技术。这是一个非常多目标决策分析的有效方法。它使用标准化的数据标准化矩阵以找到最佳和最差的目标(以理想和反理想的解决方案代表,多个目标之间),并计算每个评估目标与理想和反理想的解决方案然后,每个目标与理想解决方案的接近度为得出理想解的紧密程度,以此作为评估的依据目标的好坏。接近度的值在0到1之间。值越接近接近1,相应的评估目标越接近最佳水平;否则,值越接近0,评估目标越接近最差水平。我们将数据分析后的五个指标传递给topsis模型,这五个指标是:星级,情绪,lstm情绪,帮助/总票数,购买数量。这五个指标将起作用作为我们判断品牌优劣的标准。指示符(因为(0 1)表示评级很好,而(-1 0)表示评级不好)。的其他是非常大的指标。例如,对于2个包装的奶嘴之一,natursuttenbpa-免费天然橡胶,圆形乳头品牌。相关数据如图3.4所示:这只是品牌的topsis计算结果。将所有数据放入topsis模型中,我们可以获取所有品牌的分数。相关图表是3.5。
图3.4:
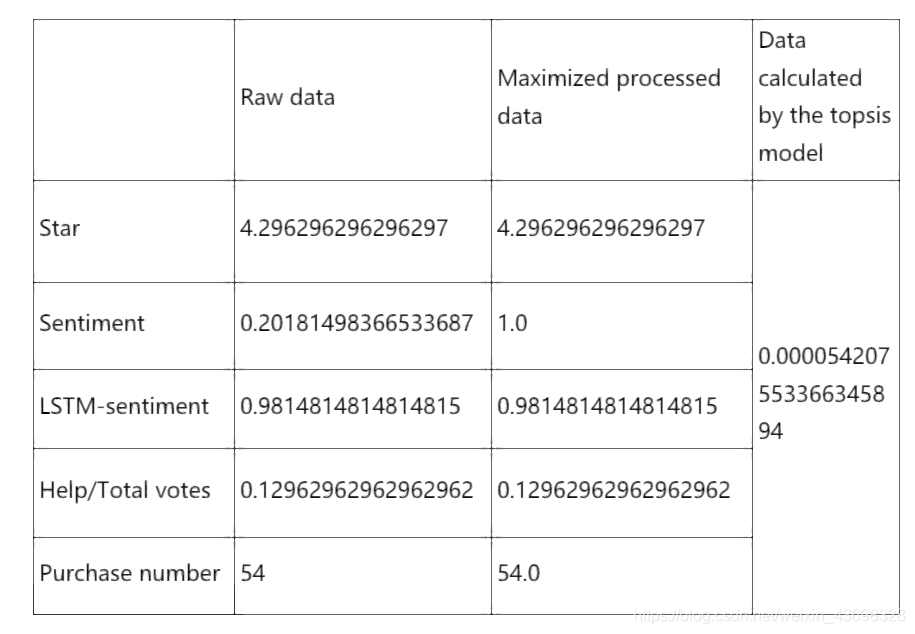
图3.5:
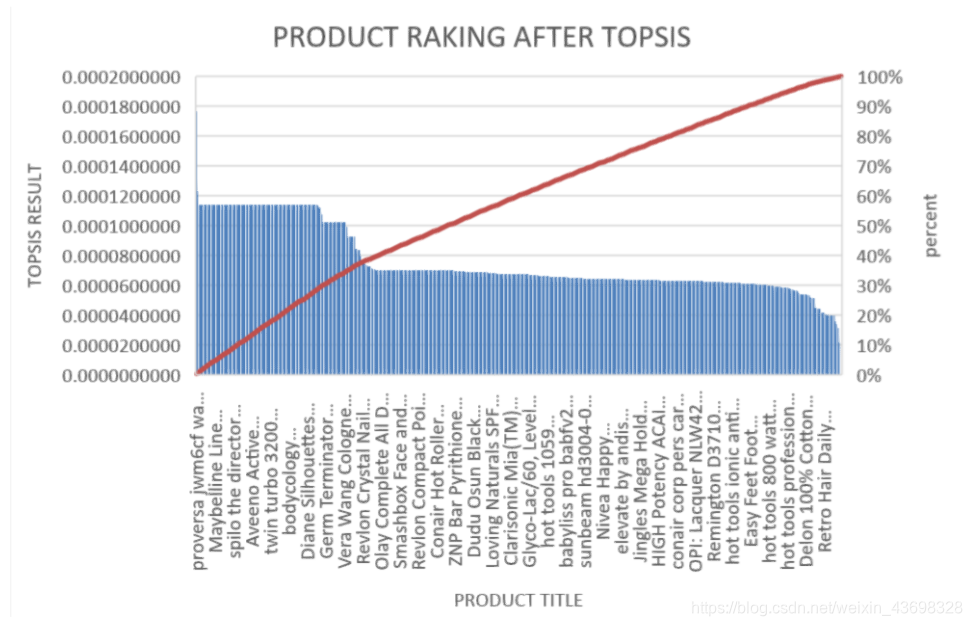
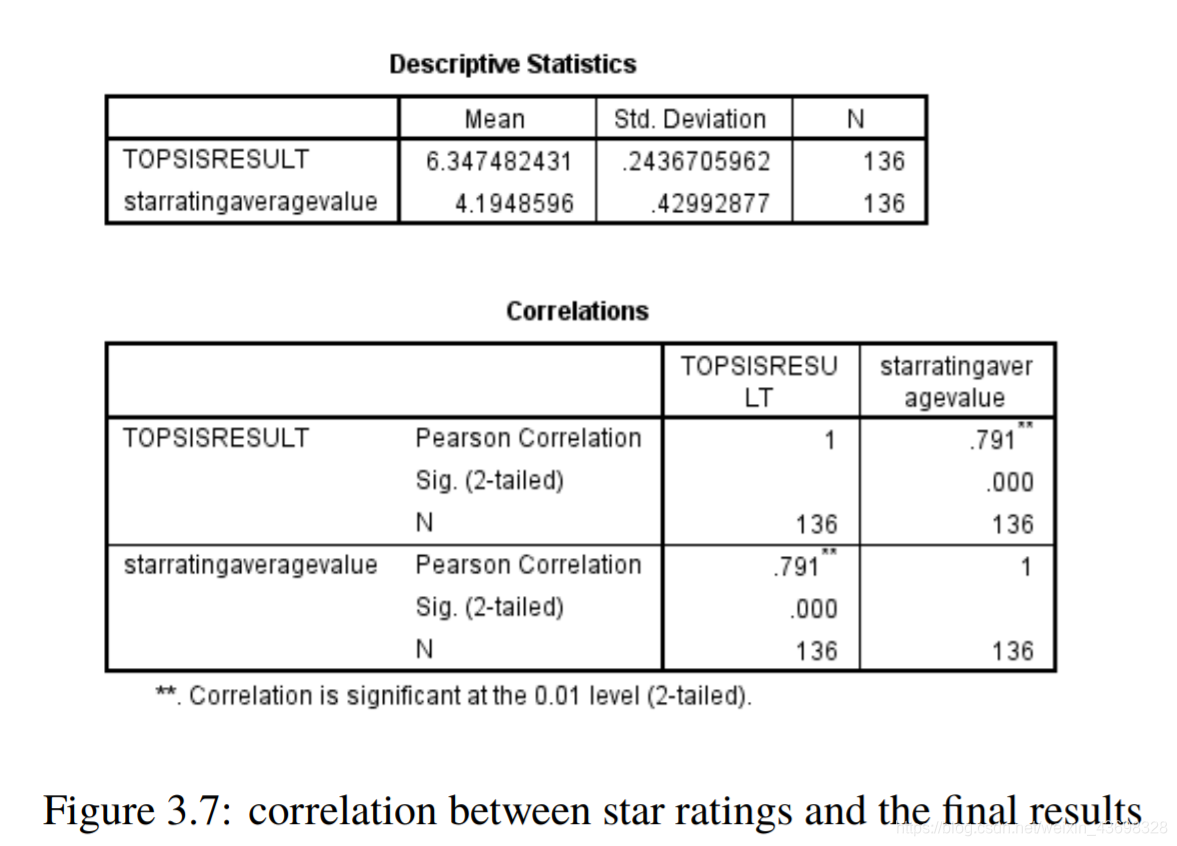
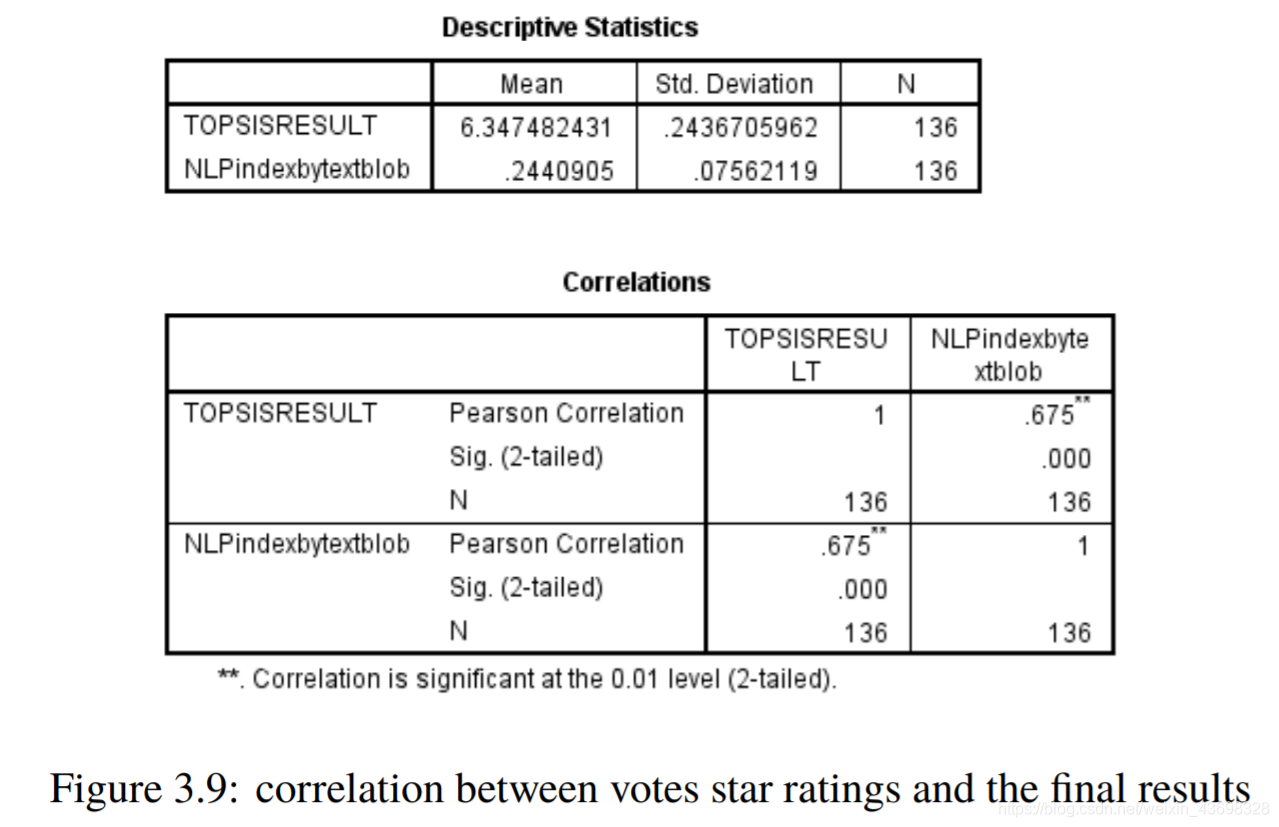
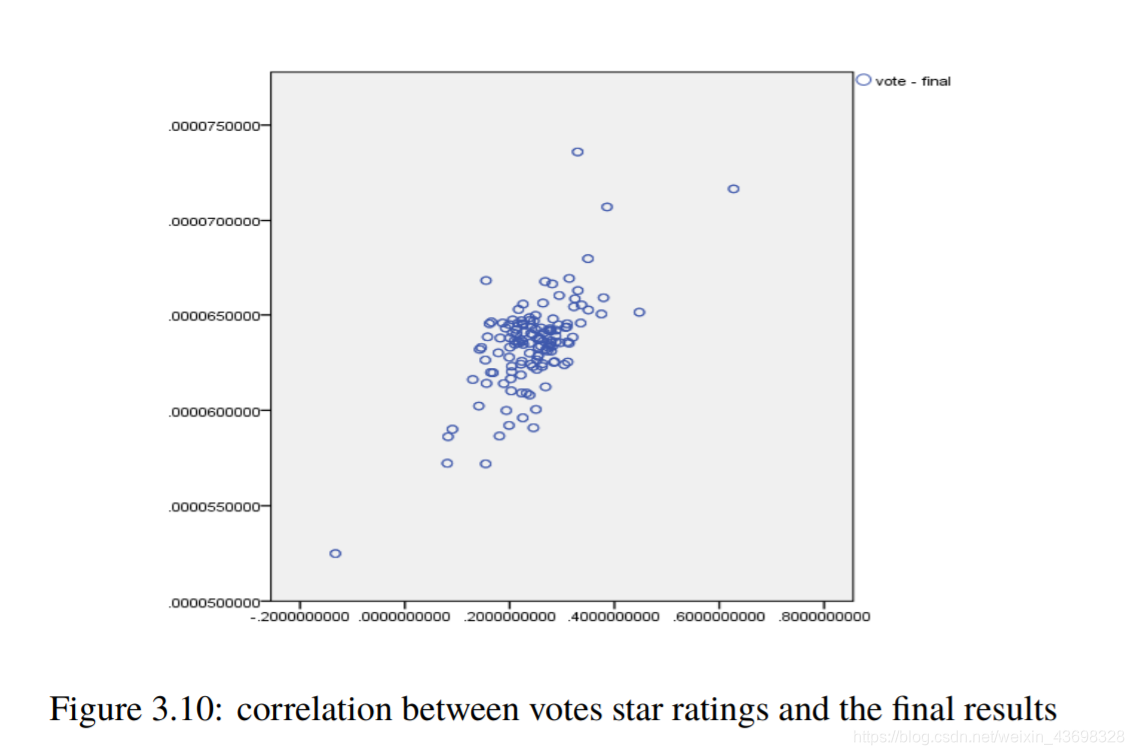
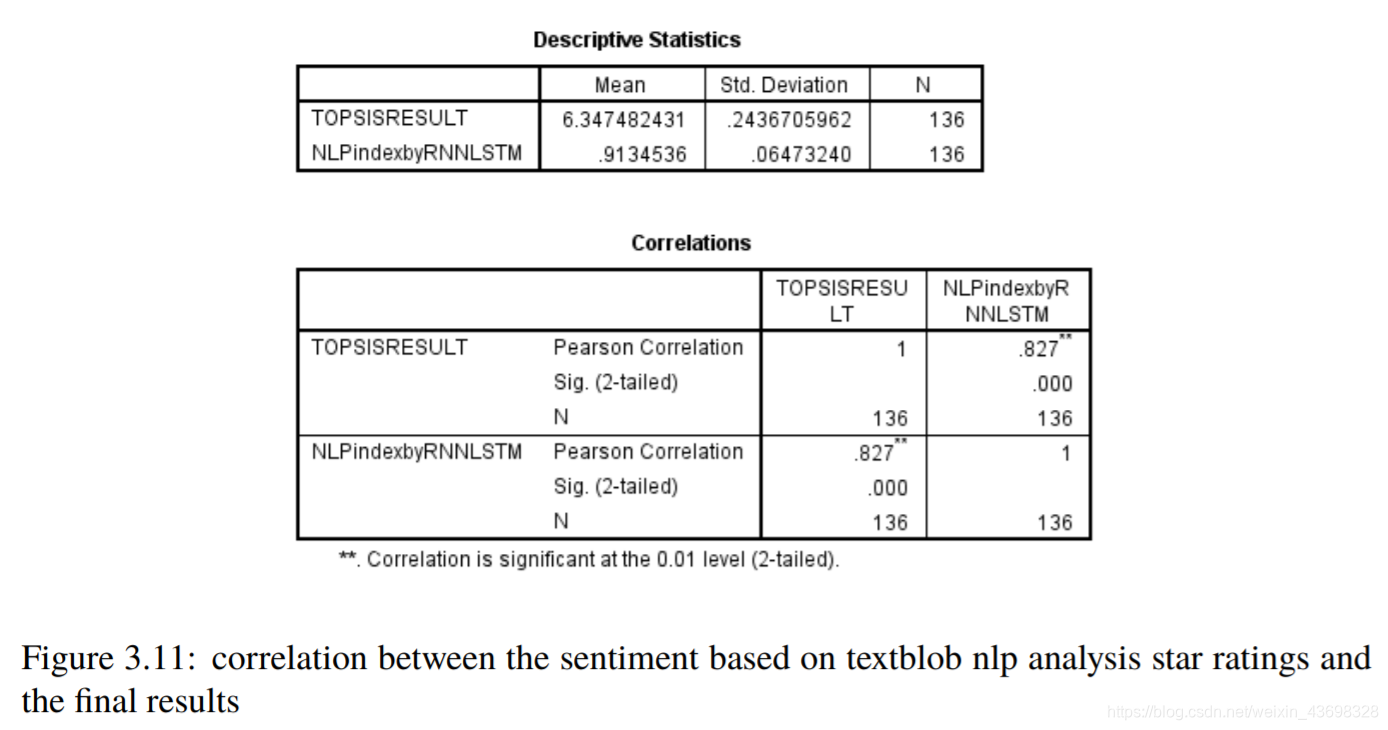
所有品牌吹风机的Topsis得分结果3.5相关分析通过topsis获得品牌的计算结果后,以检验结果的相关性,我们使用SPSS对结果进行相关性分析。首先我们检查星级与最终结果之间是否存在相关性。结果是如图3.6和图3.7所示。可以看出,假设检验结果为0.000,相关水平为0.791,相关性很大。考虑投票与最终结果之间的相关性,以及结果如图3.8和3.9所示。可以看出,假设检验结果为0.000,相关水平为0.675,并且相关性很大。然后考虑基于textblob nlp分析的情感和与最终结果的相关性。结果如图3.10和3.11所示。可以看出,假设检验结果为0.000,相关水平为0.827,
图3.6:吹风机品牌的topsisi得分前十名结果
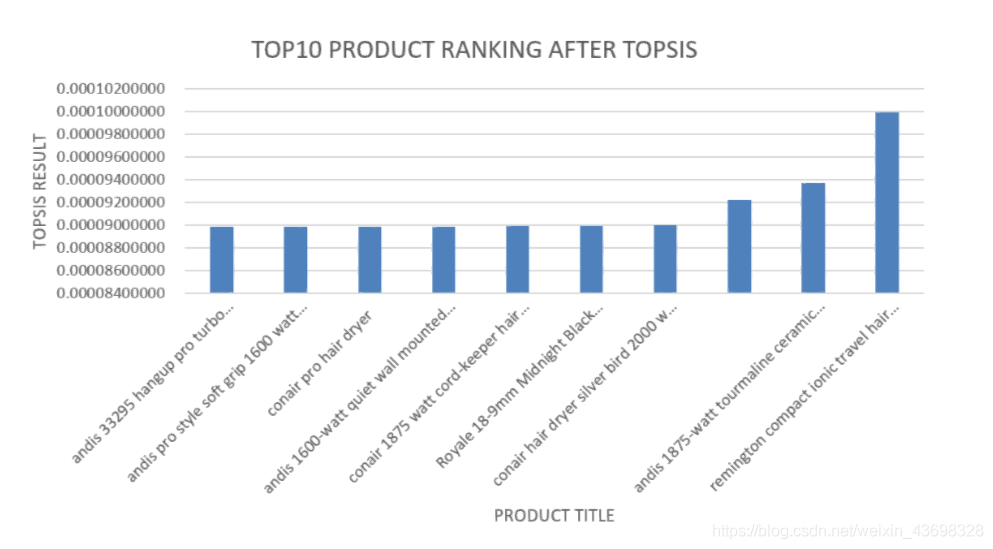
图3.7:星级与最终结果之间的相关性相关性很大。
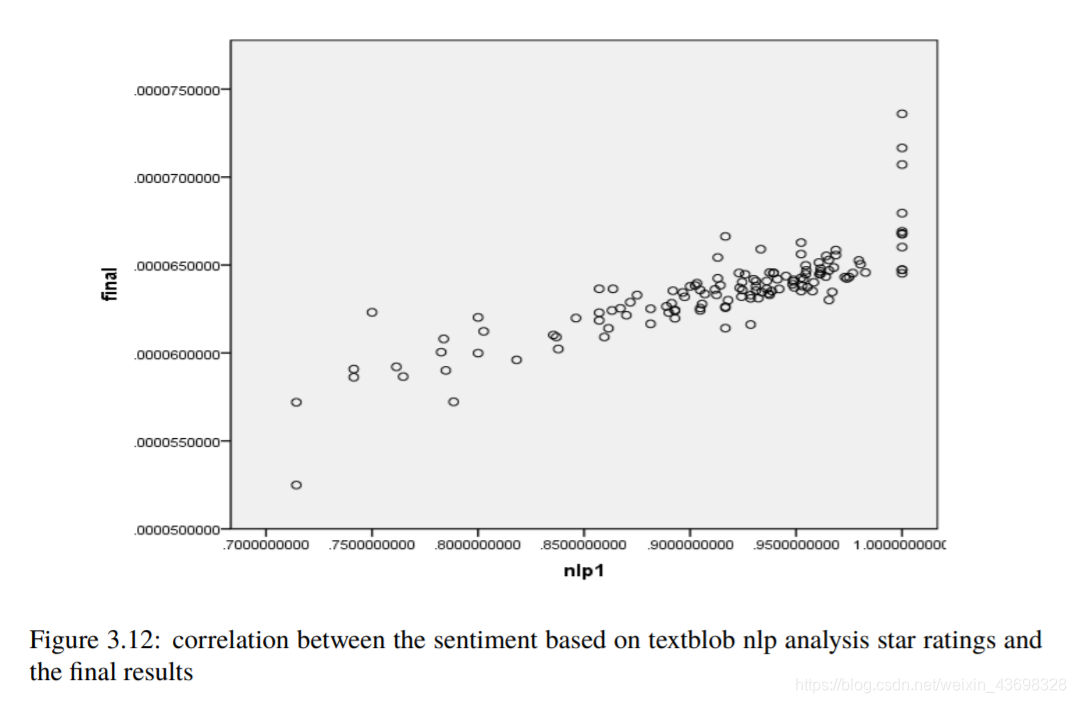
然后考虑基于lstm算法的nlp分析的情绪模型以及与最终结果的相关性。结果如图3.12和3.13所示。可以看出,假设检验结果为0.000,相关水平为0.506,相关性很大。考虑到购买数量和与最终结果的相关性,结果如图3.14和3.15所示。可以看出,假设检验结果为0.235,相关水平为-0.104,与相关性很小。4问题一4.1问题分析因为标题要求:基于评分和评论这两个指标,它们具有对阳光影响最大,确定一种数据测量方法。所以考虑这两个
图3.8:星级与最终结果之间的相关性
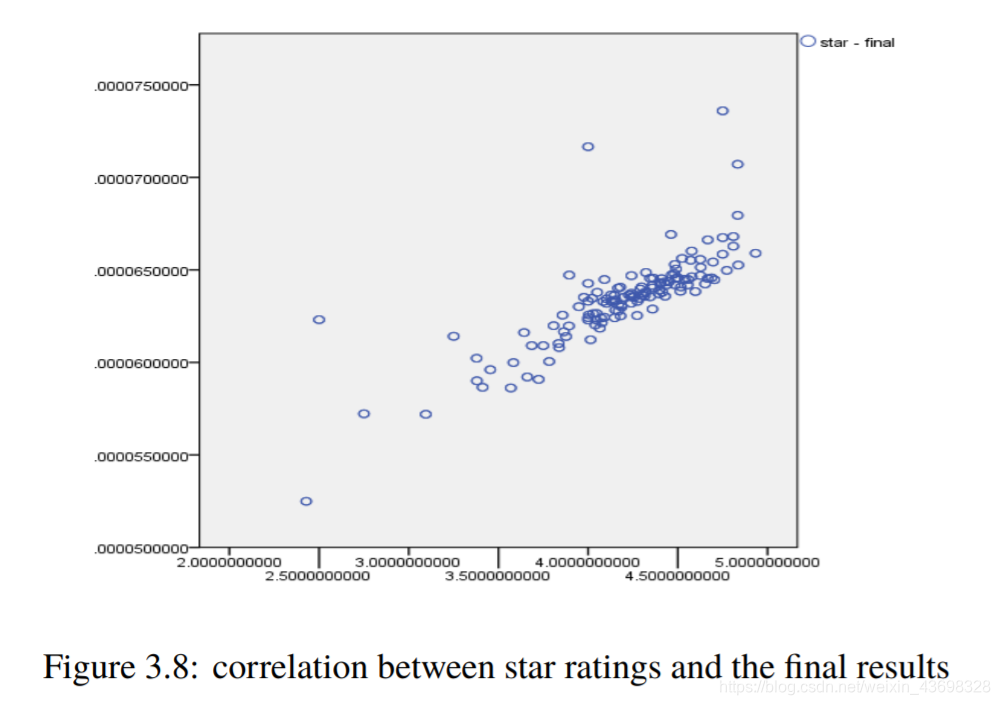
图3.9:投票星级与最终结果之间的相关性
因素:星级越高,产品越好;评论越好,越好产品; 星级越高,评论越可信。使用的topsis算法第一个问题,给出了三个指数:星级,NLP索引(按textblob)和NLP指数由LSTM。将每个指标的数据引入topsis算法以获得结果,可以用作评分和审查两个指标的数据衡量标准。4.2模型建立与解决方案考虑以下两个因素:星级越高,产品越好;越好评论,产品越好;星级越高,评论越可信。评论和星级是产品,因此两者应保持一致,但现在将有“五星级差评”和“一星肯定评价”,这表示出现了评分和星级。不一致之处。在这种情况下,数据需要进行预处理,并且“五星级差评”和“一星赞”将被删除。在上面的第一个问题中,通过基于textblob的NLP和基于机器学习的lstm
图3.10:投票星级与最终结果之间的相关性图
3.11:基于textblob nlp分析星级评定的情绪与最终结果模型,我们已将产品评论指标转化为数据形式的两个指标:NLP按textblob索引,按LSTM索引NLP。在第一个问题中,考虑了五个指标,包括星级和NLP指数,之后按textblob的NLP指数和按LSTM的NLP指数审查情绪分析。另外两个是我们的预定价格和购买数量。因此,在第一个问题中,考虑了星级和评论评论,并且建立了基于这五个指标的topsis算法模型。但是如果根据标题的含义只能判断产品的好坏通过评级和审查,那么我们仅将topsis算法模型提供给以下三个指标:星级和NLP指数Nemo指数通过textblob,NLP指数通过LSTM进行分析。
下图4.1是topsis算法之后的数据结果排名。
图3.12:基于textblob nlp分析星级评定的情绪与最终结果
5问题b
5.1问题分析b
根据“可以预测或预测的数据”来分析和讨论“基于时间的度量和模式”表示产品的声誉会在市场中增加或减少。”该表在一段
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









