







学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
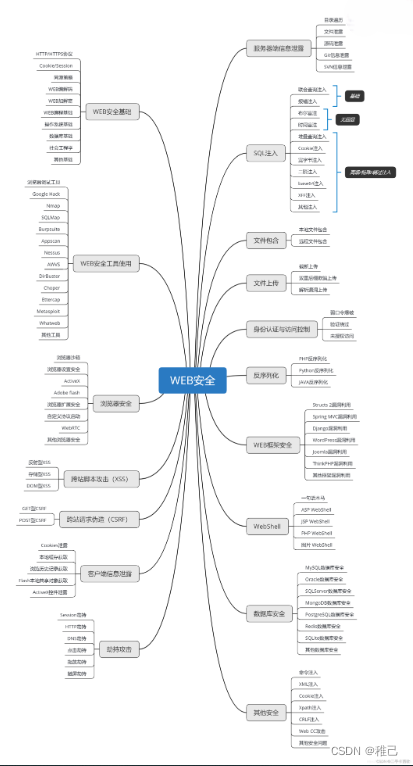
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
#### 返回布尔值
function getTotal2(one: number, two: number): boolean {
return Boolean(one + two);
}
const total2 = getTotal(1, 2);
// 返回值为布尔类型
#### 返回字符串
function getTotal2(one: string, two: string): string{
return Bone + two;
}
const total2 = getTotal(‘1’, ‘2’);
// 返回值为字符串
#### 返回对象
function getObj(name: string, age: number): { name: string, age: number } {
return {name,age}
}
getObj(‘小红’,16)
// 返回值为对象
#### 返回数组
function getArr(arr: number[]) :number[]{
let newArr = […arr]
return newArr
}
getArr([1,2,3,4])
// 返回值为数组
#### 函数返回值为underfinde,仅仅时为了在内部实现某个功能,我们就可以给他一个类型注解void,代表没有任何返回值,
function sayName() {
console.log(‘hello,world’)
}
修改后:
function sayName1(): void {
console.log(‘无返回值’)
}
#### 当函数没有返回值时
// 因为总是抛出异常,所以 error 将不会有返回值
// never 类型表示永远不会有值的一种类型
function error(message: string): never {
throw new Error(message);
}
## 6. 平时工作中有是否有接触linux系统?说说常用到linux命令?
### 1、常用的目录操作命令
>
> 创建目录 mkdir <目录名称>
> 删除目录 rm <目录名称>
> 定位目录 cd <目录名称>
> 查看目录文件 ls ll
> 修改目录名 mv <目录名称> <新目录名称>
> 拷贝目录 cp <目录名称> <新目录名称>
>
>
>
### 2、常用的文件操作命令
>
> 创建文件 touch <文件名称> vi <文件名称>
> 删除文件 rm <文件名称>
> 修改文件名 mv <文件名称> <新文件名称>
> 拷贝文件 cp <文件名称> <新文件名称>
>
>
>
### 3、常用的文件内容操作命令
>
> 查看文件 cat <文件名称> head <文件名称> tail <文件名称>
> 编辑文件内容 vi <文件名称>
> 查找文件内容 grep ‘关键字’ <文件名称>
>
>
>
## 7. 常见的 HTTP Method 有哪些? GET/POST 区别?
### 1、常见的HTTP方法
>
> GET:获取资源
> POST:传输资源
> PUT:更新资源
> DELETE:删除资源
> HEAD:获得报文首部
>
>
>
### 2、GET/POST的区别
>
> GET在浏览器回退时是无害的,而POST会再次提交请求
> GET请求会被浏览器主动缓存,而POST不会,除非手动设置
> GET请求参数会被完整保留在浏览器的历史记录里,而POST中的参数不会被保留
> GET请求在URL中传送的参数是有长度限制的,而POST没有限制
> GET参数通过URL传递,POST放在Request body中
> GET请求只能进行 url 编码,而POST支持多种编码方式
> GET产生的URL地址可以被收藏,而POST不可以
> 对参数的数据类型,GET只接受ASCII字符,而POST没有限制
> GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息
>
>
>
## 8. vue打包内存过大,怎么使用webpack来进行优化
### 开放式题目
#### 打包优化的目的
>
> 1、优化项目启动速度,和性能
>
>
> 2、必要的清理数据
>
>
> 3、性能优化的主要方向
>
>
>
>
> #### cdn加载
>
>
> -压缩js
>
>
> 减少项目在首次加载的时长(首屏加载优化)
>
>
>
>
> 4、目前的解决方向
>
>
> cdn加载不比多说,就是改为引入外部js路径
>
>
>
#### 首屏加载优化方面主要其实就两点
**第一:**
尽可能的减少首次加载的文件体积,和进行分布加载
**第二:**
首屏加载最好的解决方案就是ssr(服务端渲染),还利于seo
但是一般情况下没太多人选择ssr,因为只要不需要seo,ssr更多的是增加了项目开销和技术难度的。
1、路由懒加载
在 Webpack 中,我们可以使用动态 import语法来定义代码分块点 (split point): import(’./Fee.vue’) // 返回 Promise如果您使用的是 Babel,你将需要添加 syntax-dynamic-import 插件,才能使 Babel 可以正确地解析语法。
结合这两者,这就是如何定义一个能够被 Webpack 自动代码分割的异步组件。
const Fee = () => import(‘./Fee.vue’)
在路由配置中什么都不需要改变,只需要像往常一样使用 Foo:
const router = new VueRouter({
routes: [
{ path: ‘/fee’, component: Fee }
]
})
2、服务器和webpack打包同时配置Gzip
Gzip是GNU zip的缩写,顾名思义是一种压缩技术。它将浏览器请求的文件先在服务器端进行压缩,然后传递给浏览器,浏览器解压之后再进行页面的解析工作。在服务端开启Gzip支持后,我们前端需要提供资源压缩包,通过Compression-Webpack-Plugin插件build提供压缩
需要后端配置,这里提供nginx方式:
http:{
gzip on; #开启或关闭gzip on off
gzip_disable “msie6”; #不使用gzip IE6
gzip_min_length 100k; #gzip压缩最小文件大小,超出进行压缩(自行调节)
gzip_buffers 4 16k; #buffer 不用修改
gzip_comp_level 8; #压缩级别:1-10,数字越大压缩的越好,时间也越长
gzip_types text/plain application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; # 压缩文件类型
}
// 安装插件
$ cnpm i --save-dev compression-webpack-plugin
// 在vue-config.js 中加入
const CompressionWebpackPlugin = require(‘compression-webpack-plugin’);
const productionGzipExtensions = [
“js”,
“css”,
“svg”,
“woff”,
“ttf”,
“json”,
“html”
];
const isProduction = process.env.NODE_ENV === ‘production’;
…
module.exports = {
…
// 配置webpack
configureWebpack: config => {
if (isProduction) {
// 开启gzip压缩
config.plugins.push(new CompressionWebpackPlugin({
algorithm: ‘gzip’,
test: /.js
∣
h
˙
t
m
l
|\.html
∣h˙tml|.json$|.css/,
threshold: 10240,
minRatio: 0.8
}))
}
}
}
3、优化打包chunk-vendor.js文件体积过大
当我们运行项目并且打包的时候,会发现chunk-vendors.js这个文件非常大,那是因为webpack将所有的依赖全都压缩到了这个文件里面,这时我们可以将其拆分,将所有的依赖都打包成单独的js。
// 在vue-config.js 中加入
…
module.exports = {
…
// 配置webpack
configureWebpack: config => {
if (isProduction) {
// 开启分离js
config.optimization = {
runtimeChunk: ‘single’,
splitChunks: {
chunks: ‘all’,
maxInitialRequests: Infinity,
minSize: 20000,
cacheGroups: {
vendor: {
test: /[\/]node_modules[\/]/,
name (module) {
// get the name. E.g. node_modules/packageName/not/this/part.js
// or node_modules/packageName
const packageName = module.context.match(/[\/]node_modules\/([\/]|
)
/
)
[
1
]
/
/
n
p
m
p
a
c
k
a
g
e
n
a
m
e
s
a
r
e
U
R
L
−
s
a
f
e
,
b
u
t
s
o
m
e
s
e
r
v
e
r
s
d
o
n
′
t
l
i
k
e
@
s
y
m
b
o
l
s
r
e
t
u
r
n
‘
n
p
m
.
)/)[1] // npm package names are URL-safe, but some servers don't like @ symbols return `npm.
)/)[1]//npmpackagenamesareURL−safe,butsomeserversdon′tlike@symbolsreturn‘npm.{packageName.replace(‘@’, ‘’)}`
}
}
}
}
};
}
}
}
// 至此,你会发现原先的vender文件没有了,同时多了好几个依赖的js文件
4、启用CDN加速
用Gzip已把文件的大小减少了三分之二了,但这个还是得不到满足。那我们就把那些不太可能改动的代码或者库分离出来,继续减小单个chunk-vendors,然后通过CDN加载进行加速加载资源。
// 修改vue.config.js 分离不常用代码库
// 如果不配置webpack也可直接在index.html引入
module.exports = {
configureWebpack: config => {
if (isProduction) {
config.externals = {
‘vue’: ‘Vue’,
‘vue-router’: ‘VueRouter’,
‘moment’: ‘moment’
}
}
}
}
// 在public文件夹的index.html 加载
5、完整vue.config.js代码
const path = require(‘path’)
// 在vue-config.js 中加入
// 开启gzip压缩
const CompressionWebpackPlugin = require(‘compression-webpack-plugin’);
// 判断开发环境
const isProduction = process.env.NODE_ENV === ‘production’;
const resolve = dir => {
return path.join(__dirname, dir)
}
// 项目部署基础
// 默认情况下,我们假设你的应用将被部署在域的根目录下,
// 例如:https://www.my-app.com/
// 默认:‘/’
// 如果您的应用程序部署在子路径中,则需要在这指定子路径
// 例如:https://www.foobar.com/my-app/
// 需要将它改为’/my-app/’
// iview-admin线上演示打包路径: https://file.iviewui.com/admin-dist/
const BASE_URL = process.env.NODE_ENV === ‘production’
? ‘/’
: ‘/’
module.exports = {
//webpack配置
configureWebpack:config => {
// 开启gzip压缩
if (isProduction) {
config.plugins.push(new CompressionWebpackPlugin({
algorithm: ‘gzip’,
test: /.js
∣
h
˙
t
m
l
|\.html
∣h˙tml|.jsonKaTeX parse error: Expected 'EOF', got '}' at position 70: …o: 0.8 }̲)); // …)/)[1]
// npm package names are URL-safe, but some servers don’t like @ symbols
return npm.${packageName.replace('@', '')}
}
}
}
}
};
// 取消webpack警告的性能提示
config.performance = {
hints:‘warning’,
//入口起点的最大体积
maxEntrypointSize: 50000000,
//生成文件的最大体积
maxAssetSize: 30000000,
//只给出 js 文件的性能提示
assetFilter: function(assetFilename) {
return assetFilename.endsWith(‘.js’);
}
}
}
},
// Project deployment base
// By default we assume your app will be deployed at the root of a domain,
// e.g. https://www.my-app.com/
// If your app is deployed at a sub-path, you will need to specify that
// sub-path here. For example, if your app is deployed at
// https://www.foobar.com/my-app/
// then change this to ‘/my-app/’
publicPath: BASE_URL,
// tweak internal webpack configuration.
// see https://github.com/vuejs/vue-cli/blob/dev/docs/webpack.md
devServer: {
host: ‘localhost’,
port: 8080, // 端口号
hotOnly: false,
https: false, // https:{type:Boolean}
open: true, //配置自动启动浏览器
proxy:null // 配置跨域处理,只有一个代理
},
// 如果你不需要使用eslint,把lintOnSave设为false即可
lintOnSave: true,
css:{
loaderOptions:{
less:{
javascriptEnabled:true
}
},
extract: true,// 是否使用css分离插件 ExtractTextPlugin
sourceMap: false,// 开启 CSS source maps
modules: false// 启用 CSS modules for all css / pre-processor files.
},
chainWebpack: config => {
config.resolve.alias
.set('@', resolve('src')) // key,value自行定义,比如.set('@@', resolve('src/components'))
.set('@c', resolve('src/components'))
},
// 打包时不生成.map文件
productionSourceMap: false
// 这里写你调用接口的基础路径,来解决跨域,如果设置了代理,那你本地开发环境的axios的baseUrl要写为 '' ,即空字符串
// devServer: {
// proxy: 'localhost:3000'
// }
}
## 9. git经常用哪些指令
### 产生代码库
新建一个git代码库
git init
下载远程项目和它的整个代码历史
git clone 远程仓库地址
### 配置
显示配置
git config --list [–global]
编辑配置
git config -e [–global]
设置用户信息
git config [–global] user.name “名”
git config [–global] user.email “邮箱地址”
### 暂存区文件操作
增加文件到暂存区
1.添加当前目录的所有文件到暂存区
git add .
2.添加指定目录到暂存区,包括子目录
git add [dir]
3.添加指定文件到暂存区
git add [file1] [file2] …
在暂存区中删除文件
删除工作区文件,并且将这次删除放入暂存区
git rm [file1] [file2] …
停止追踪指定文件,但该文件会保留在工作区
git rm --cached [file]
重命名暂存区文件
改名文件,并且将这个改名放入暂存区
git mv [file-original] [file-renamed]
代码提交
提交暂存区到仓库区
git commit -m [message]
分支操作
列出所有本地分支
git branch
列出所有远程分支
git branch -r
列出所有本地分支和远程分支
git branch -a
新建一个分支,但依然停留在当前分支
git branch [branch-name]
新建一个分支,并切换到该分支
git checkout -b [branch]
新建一个分支,指向指定commit
git branch [branch] [commit]
新建一个分支,与指定的远程分支建立追踪关系
git branch --track [branch] [remote-branch]
切换到指定分支,并更新工作区
git checkout [branch-name]
切换到上一个分支
git checkout -
建立追踪关系,在现有分支与指定的远程分支之间
git branch --set-upstream [branch] [remote-branch]
合并指定分支到当前分支
git merge [branch]
选择一个commit,合并进当前分支
git cherry-pick [commit]
删除分支
git branch -d [branch-name]
删除远程分支
git push origin --delete [branch-name]
git branch -dr [remote/branch]
信息查看
显示有变更的文件
git status
显示当前分支的版本历史
git log
显示commit历史,以及每次commit发生变更的文件
git log --stat
搜索提交历史,根据关键词
git log -S [keyword]
显示某个commit之后的所有变动,每个commit占据一行
git log [tag] HEAD --pretty=format:%s
显示某个commit之后的所有变动,其"提交说明"必须符合搜索条件
git log [tag] HEAD --grep feature
显示过去5次提交
git log -5 --pretty --oneline
同步操作
增加一个新的远程仓库,并命名
git remote add [shortname] [url]
取回远程仓库的变化,并与本地分支合并
git pull [remote] [branch]
上传本地指定分支到远程仓库
git push [remote] [branch]
强行推送当前分支到远程仓库,即使有冲突
git push [remote] --force
推送所有分支到远程仓库
git push [remote] --all
撤销操作
恢复暂存区的指定文件到工作区
git checkout [file]
恢复某个commit的指定文件到暂存区和工作区
git checkout [commit] [file]
恢复暂存区的所有文件到工作区
git checkout .
重置暂存区的指定文件,与上一次commit保持一致,但工作区不变
git reset [file]
重置暂存区与工作区,与上一次commit保持一致
git reset --hard
重置当前分支的指针为指定commit,同时重置暂存区,但工作区不变
git reset [commit]
重置当前分支的HEAD为指定commit,同时重置暂存区和工作区,与指定commit一致
git reset --hard [commit]
重置当前HEAD为指定commit,但保持暂存区和工作区不变
git reset --keep [commit]
新建一个commit,用来撤销指定commit
后者的所有变化都将被前者抵消,并且应用到当前分支
git revert [commit]
## 10. 协商缓存和强缓存
浏览器缓存主要分为**强强缓存(也称本地缓存)和协商缓存(也称弱缓存)**。浏览器在第一次请求发生后,再次发送请求时:
* 浏览器请求某一资源时,会先获取该资源缓存的header信息,然后根据header中的Cache-Control和Expires来判断是否过期。若没过期则直接从缓存中获取资源信息,包括缓存的header的信息,所以此次请求不会与服务器进行通信。这里判断是否过期,则是强缓存相关。后面会讲Cache-Control和Expires相关。
* 如果显示已过期,浏览器会向服务器端发送请求,这个请求会携带第一次请求返回的有关缓存的header字段信息,比如客户端会通过If-None-Match头将先前服务器端发送过来的Etag发送给服务器,服务会对比这个客户端发过来的Etag是否与服务器的相同,若相同,就将If-None-Match的值设为false,返回状态304,客户端继续使用本地缓存,不解析服务器端发回来的数据,若不相同就将If-None-Match的值设为true,返回状态为200,客户端重新机械服务器端返回的数据;客户端还会通过If-Modified-Since头将先前服务器端发过来的最后修改时间戳发送给服务器,服务器端通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回最新的内容,如果是最新的,则返回304,客户端继续使用本地缓存。
#### 强缓存
强缓存是利用http头中的Expires和Cache-Control两个字段来控制的,用来表示资源的缓存时间。强缓存中,普通刷新会忽略它,但不会清除它,需要强制刷新。浏览器强制刷新,请求会带上Cache-Control:no-cache和Pragma:no-cache
#### Expires
Expires是http1.0的规范,它的值是一个绝对时间的GMT格式的时间字符串。如我现在这个网页的Expires值是:expires:Fri, 14 Apr 2017 10:47:02 GMT。这个时间代表这这个资源的失效时间,只要发送请求时间是在Expires之前,那么本地缓存始终有效,则在缓存中读取数据。所以这种方式有一个明显的缺点,由于失效的时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。如果同时出现Cache-Control:max-age和Expires,那么max-age优先级更高。如我主页的response headers部分如下:
cache-control:max-age=691200
expires:Fri, 14 Apr 2017 10:47:02 GMT
#### Cache-Control
Cache-Control是在http1.1中出现的,主要是利用该字段的max-age值来进行判断,它是一个相对时间,例如Cache-Control:max-age=3600,代表着资源的有效期是3600秒。cache-control除了该字段外,还有下面几个比较常用的设置值:
* no-cache:不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
* no-store:直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
* public:可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
* private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
* Cache-Control与Expires可以在服务端配置同时启用,同时启用的时候Cache-Control优先级高。
#### 协商缓存
协商缓存就是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问。
**普通刷新会启用弱缓存,忽略强缓存。只有在地址栏或收藏夹输入网址、通过链接引用资源等情况下,浏览器才会启用强缓存,** 这也是为什么有时候我们更新一张图片、一个js文件,页面内容依然是旧的,但是直接浏览器访问那个图片或文件,看到的内容却是新的。
这个主要涉及到两组header字段:Etag和If-None-Match、Last-Modified和If-Modified-Since。上面以及说得很清楚这两组怎么使用啦~复习一下:
##### Etag和If-None-Match
Etag/If-None-Match返回的是一个校验码。ETag可以保证每一个资源是唯一的,资源变化都会导致ETag变化。服务器根据浏览器上送的If-None-Match值来判断是否命中缓存。
与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,**由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。**
##### Last-Modify/If-Modify-Since
浏览器第一次请求一个资源的时候,服务器返回的header中会加上Last-Modify,Last-modify是一个时间标识该资源的最后修改时间,例如Last-Modify: Thu,31 Dec 2037 23:59:59 GMT。
当浏览器再次请求该资源时,request的请求头中会包含If-Modify-Since,该值为缓存之前返回的Last-Modify。服务器收到If-Modify-Since后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,则返回304,并且不会返回资源内容,并且不会返回Last-Modify。
#### 为什么要有Etag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
* 一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
* 某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
* 某些服务器不能精确的得到文件的最后修改时间。
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
## 11. 对Event loop的了解?
Javascript是单线程的,那么各个任务进程是按照什么样的规范来执行的呢?这就涉及到Event Loop的概念了,EventLoop是在html5规范中明确定义的;
何为eventloop,javascript中的一种运行机制,用来解决浏览器单线程的问题
**Event Loop是一个程序结构,用于等待和发送消息和事件。同步任务、异步任务、微任务、宏任务**
**javascript单线程任务从时间上分为同步任务和异步任务,而异步任务又分为宏任务(macroTask)和微任务(microTask)**
**宏任务:主代码块、setTimeOut、setInterval、script、I/O操作、UI渲染**
**微任务:promise、async/await(返回的也是一个promise)、process.nextTick**
在执行代码前,任务队列为空,所以会优先执行主代码块,再执行主代码块过程中,遇到同步任务则立即将任务放到调用栈执行任务,遇到宏任务则将任务放入宏任务队列中,遇到微任务则将任务放到微任务队列中。
主线程任务执行完之后,先检查微任务队列是否有任务,有的话则将按照先入先出的顺序将先放进来的微任务放入调用栈中执行,并将该任务从微任务队列中移除,执行完该任务后继续查看微任务队列中是否还有任务,有的话继续执行微任务,微任务队列null时,查看宏任务队列,有的话则按先进先出的顺序执行,将任务放入调用栈并将该任务从宏任务队列中移除,该任务执行完之后继续查看微任务队列,有的话则执行微任务队列,没有则继续执行宏任务队列中的任务。
**需要注意的是:每次调用栈执行完一个宏任务之后,都会去查看微任务队列,如果microtask queue不为空,则会执行微任务队列中的任务,直到微任务队列为空再返回去查看执行宏任务队列中的任务**
console.log(‘script start’)
async function async1() {
await async2()
console.log(‘async1 end’)
}
async function async2() {
console.log(‘async2 end’)
}
async1()
setTimeout(function() {
console.log(‘setTimeout’)
}, 0)
new Promise(resolve => {
console.log(‘Promise’)
resolve()
})
.then(function() {
console.log(‘promise1’)
})
.then(function() {
console.log(‘promise2’)
})
console.log(‘script end’)
最终输出
script start
VM70:8 async2 end
VM70:17 Promise
VM70:27 script end
VM70:5 async1 end
VM70:21 promise1
VM70:24 promise2
undefined
VM70:13 setTimeout
解析:
在说返回结果之前,先说一下async/await,async 返回的是一个promise,而await则等待一个promise对象执行,await之后的代码则相当于promise.then()
async function async1() {
await async2()
console.log(‘async1 end’)
}
async function async2() {
console.log(‘async2 end’)
}
//等价于
new Promise(resolve =>
resolve(console.log(‘async2 end’))
).then(res => {
console.log(‘async1 end’)
})
整体分析:先执行同步任务 script start -> async2 end -> await之后的console被放入微任务队列中 -> setTimeOut被放入宏任务队列中 ->promise -> promise.then被放入微任务队列中 -> script end -> 同步任务执行完毕,查看微任务队列 --> async1 end -> promise1 -> promise2 --> 微任务队列执行完毕,执行宏任务队列打印setTimeout
## 12. node.js如何导出页面数据形成报表
node.js如何导出页面数据形成报表
生成报表并下载是作为web应用中的一个传统功能,在实际项目中有广范的应用,实现原理也很简单,以NodeJS导出数据的方法为例,就是拿到页面数据对应id,然后根据id查询数据库,拿到所需数据后格式化为特点格式的数据,最后导出文件。
在nodejs中,也提供了很多的第三方库来实现这一功能,以node-xlsx导出excel文件为例,实现步骤如下:
1. 下载node-xlsx
npm install node-xlsx
2. 编写接口
>
> 以下代码使用express编写,调用接口实现下载功能
>
>
>
const fs = require('fs');
const path = require('path');
const xlsx = require('node-xlsx');
const express = require('express');
const router = express.Router();
const mongo = require('../db');
router.post('/export', async (req, res) => {
const { ids } = req.body;
const query = {
_id: { $in: ids }
}
// 查询数据库获取数据
let result = await mongo.find(colName, query);
// 设置表头
const keys = Object.keys(Object.assign({}, ...result));
rows[0] = keys;
// 设置表格数据
const rows = []
result.map(item => {
const values = []
keys.forEach((key, idx) => {
if (item[key] === undefined) {
values[idx] = null;
} else {
values[idx] = item[key];
}
})
rows.push(values);
});
let data = xlsx.build([{ name: "商品列表", data: rows }]);
const downloadPath = path.join(__dirname, '../../public/download');
const filePath = `${downloadPath}/goodslist.xlsx`;
fs.writeFileSync(filePath, data);
res.download(filePath, `商品列表.xlsx`, (err) => {
console.log('download err', err);
});
})
## 13. 说说你对nodejs的了解
>
> 我们从以下几方面来看nodejs.
>
>
>
### 什么是nodejs?
Node.js 是一个开源与跨平台的 JavaScript 运行时环境, 在浏览器外运行 V8 JavaScript 引擎(Google Chrome 的内核),利用事件驱动、非阻塞和异步输入输出模型等技术提高性能.
可以理解为 Node.js 就是一个服务器端的、非阻塞式I/O的、事件驱动的JavaScript运行环境
#### 非阻塞异步
Nodejs采用了非阻塞型I/O机制,在做I/O操作的时候不会造成任何的阻塞,当完成之后,以时间的形式通知执行操作
例如在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率
#### 事件驱动
事件驱动就是当进来一个新的请求的时,请求将会被压入一个事件队列中,然后通过一个循环来检测队列中的事件状态变化,如果检测到有状态变化的事件,那么就执行该事件对应的处理代码,一般都是回调函数
### 优缺点
#### 优点:
处理高并发场景性能更佳
适合I/O密集型应用,指的是应用在运行极限时,CPU占用率仍然比较低,大部分时间是在做 I/O硬盘内存读写操作
因为Nodejs是单线程
#### 缺点:
不适合CPU密集型应用
只支持单核CPU,不能充分利用CPU
可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
#### 应用场景
借助Nodejs的特点和弊端,其应用场景分类如下:
>
> 善于I/O,不善于计算。因为Nodejs是一个单线程,如果计算(同步)太多,则会阻塞这个线程
> 大量并发的I/O,应用程序内部并不需要进行非常复杂的处理
> 与 websocket 配合,开发长连接的实时交互应用程序
>
>
>
##### 具体场景可以表现为如下:
>
> 第一大类:用户表单收集系统、后台管理系统、实时交互系统、考试系统、联网软件、高并发量的web应用程>序
> 第二大类:基于web、canvas等多人联网游戏
> 第三大类:基于web的多人实时聊天客户端、聊天室、图文直播
> 第四大类:单页面浏览器应用程序
> 第五大类:操作数据库、为前端和移动端提供基于json的API
>
>
>
## 14. useRef与createRef的区别
1、useRef是针对函数组件的,如果是类组件则使用React.createRef()。
2、React.createRef()也可以在函数组件中使用。useRef只能在react hooks中使用
3、createRef每次都会返回个新的引用;而useRef不会随着组件的更新而重新创建
## 15.createSelector的使用场景
`createSelector`函数主要用于优化React应用程序中的性能,特别是在具有大量数据的情况下。它的主要用途是创建输出选择器函数,该函数将`redux store`中的多个状态组合并到单个值中,并将该值缓存以提高性能
### 1、过滤和排序数据
通过`createSelector`函数,可以根据多个条件从`Redux store`中选择数据,并使用JavaScript函数对其进行过滤、排序等处理。
### 2、转换数据格式
通过`createSelector`函数,可以将`Redux store`中的原始数据转换为更易于处理的格式,如图表数据,饼状图数据等。
### 3、避免不必要的渲染
使用`createSelector`函数可以避免不必要的渲染。当`createSelector`函数的输入参数未更改时,将从缓存中返回结果。只有当输入参数更改时,`createSelector`函数才会重新计算其输出,并在React组件中触发渲染。
### 4、避免重复计算
在Redux store中包含大量数据时,使用`createSelector`函数可以避免不必要的计算。例如,可以通过创建一个选择器函数,该函数选择一个对象数组并返回其长度来避免在每次计算数组长度时进行重复的大量计算
## 16. 代码分割(路由懒加载)
React Router 在使用时,会把所有路由相关的组件都打包进同一个 JavaScript 文件中,这会导致整个应用的体积变得很大,加载时间变长。为了解决这个问题,我们可以使用代码分割(code splitting)技术,将不同的路由组件分别打包成不同的 JavaScript 文件,实现按需加载。
## 17. redux-thunk的工作原理
源码解读
function thunkMiddleware({ dispatch, getState }) {
return next => action => {
// 如果 action 是一个函数,那么调用它,并传递 dispatch 和 getState 函数作为参数
if (typeof action === ‘function’) {
return action(dispatch, getState);
}
// 否则,调用下一个中间件
return next(action);
};
}
## 18. 什么是Concurrent React
并发可以理解为同时执行大量任务的能力。并发并不是一个特性。相反,它是一个幕后功能,它允许 React 同时(并发地)准备许多 UI 实例。
并发涉及同时执行多个状态更新,这可以说是 React 18 中最重要的特性。除了并发之外,React 18 还引入了两个新的钩子,称为 useTransition() 和 useDeferredValue() 钩子。
它们都有助于降低状态更新的优先级
## 19. useDeferredValue vs useTransition
### 1、相同点
useDeferredValue 本质上和内部实现与 useTransition 一样都是把任务标记成了过渡更新任务。
### 2、不同点
useTransition 是把 startTransition 内部的更新任务变成了过渡任务transtion,而 useDeferredValue 是把原值通过过渡任务得到新的值,这个值作为延时状态。 也就是说一个是处理一段逻辑,另一个是生产一个新的状态。
useDeferredValue 还有一个不同点就是这个任务,本质上在 useEffect 内部执行,而 useEffect 内部逻辑是异步执行的 ,所以它一定程度上更滞后于 useTransition。可以理解成useDeferredValue = useEffect + transtion
## 20. redux中如何使用中间件
`applyMiddleware`是 Redux 的一个高阶函数,用于向 Redux Store 应用中间件。
中间件是一个函数,它可以在 dispatch 操作执行前后,对 action 进行拦截、处理、修改等操作。例如:日志记录、错误捕获、异步请求、数据缓存等等。
使用`applyMiddleware`,你可以实现额外的功能,并且可以在不修改原始代码的情况下对其进行扩展。
## 21. context的使用场景
1、主题色切换。
2、多国语言切换。也就是国际化
3、祖孙组件之间的传值
## 22. flux架构
Flux 是一种由 Facebook 提出的前端应用程序架构,旨在解决传统的 MVC(Model-View-Controller)架构在复杂应用场景下出现的一系列问题。Flux 基于单向数据流的思想,将应用程序拆分为四个主要组件:Action、Dispatcher、Store 和 View。
## 23. 介绍一下Redux Toolkit(RTK)
#### 简化Redux的配置
Redux Toolkit提供了一个createSlice函数,可以用来快速创建Redux的action和reducer,不需要手动编写大量的模板代码。
#### 封装常用的Redux函数
Redux Toolkit提供了一些封装过的Redux函数,如createAsyncThunk、createEntityAdapter等,这些函数可以帮助开发者更加容易地处理异步操作、管理实体数据等常见任务。
#### 整合常用的中间件
Redux Toolkit默认集成了常用的中间件,如redux-thunk、redux-logger等,使得开发者可以更3加便捷地使用这些中间件,而不需要手动配置。
#### 提供默认的Redux store配置
Redux Toolkit提供了一个configureStore函数,可以用来快速创建一个Redux store,并且默认配置了许多常用的中间件和插件,减少了开发者的配置工作量。
#### 介绍一下redux-toolkit中的configureStore
configureStore是Redux Toolkit中的一个工厂函数,用于创建Redux store。它的目的是简化Redux store的设置,并提供许多默认设置和内置的中间件,使其更易于使用。
## 24. useEffect如何写在依赖
useEffect如何写在依赖
import React, { useState, useEffect } from ‘react’;
export default function hook() {
const [num, setNum] = useState(1)
/**
* 第一个参数是回调函数
* 第二个参数是依赖项
* 每次num变化时都会变化
*
* 注意初始化的时候,也会调用一次
*/
useEffect(() => {
console.log(“每次num,改变我才会触发”)
return () => {
/\*\*
* 这是卸载的回调可以执行某些操作
* 如果不想执行,则可以什么都不写
*/
console.log(“卸载当前监听”)
}
}, [num])
useEffect(() => {
console.log(“每次render页面我就会触发”)
return () => {
console.log(“卸载当前监听”)
}
})
return (
<button onClick={() => setNum(num + 1)}>+1
);
}
## 25. ReactDOM.createPorta
Portal 提供了一种将子节点渲染到存在于父组件以外 DOM 节点的方案。在 CSS 中,我们可以使用 position: fixed 等定位方式,让元素从视觉上脱离父元素。在 React 中,Portal 直接改变了组件的挂载方式,不再是挂载到上层父节点上,而是可以让用户指定一个挂载节点。一般用于模态对话框,工具提示、悬浮卡、加载动画等
## 26. 除jsx外,react还可以使用那些方式编写UI
当你不想在构建环境中配置有关 JSX 编译时,不在 React 中使用 JSX 会更加方便。每个 JSX 元素只是调用 `React.createElement(component, props, ...children)` 的语法糖。因此,使用 JSX 可以完成的任何事情都可以通过纯 JavaScript 完成
## 26. 在项目中封装过哪些组件+如何封装一个弹框组件
使用画一个弹框的UI,使用固定定位,定到屏幕中央,然后确定接收的参数,如标题,弹框内容,按钮名等,暴露出两个按钮的点击事件。最后使用ReactDOM.createPortal创建这个组件
## 27. CSS module的实现原理
CSS Modules 通过对 CSS 类名重命名,保证每个类名的唯一性,从而避免样式冲突的问题。也就是说:所有类名都具有“局部作用域”,只在当前组件内部生效。在 React 脚手架中:文件名、类名、hash(随机)三部分,只需要指定类名即可 BEM
## 28. 合成事件的优势
#### 1、进行浏览器兼容,实现更好的跨平台
React 采用的是顶层事件代理机制,能够保证冒泡一致性,可以跨浏览器执行。React 提供的合成事件用来抹平不同浏览器事件对象之间的差异,将不同平台事件模拟合成事件。
#### 2、避免垃圾回收
事件对象可能会被频繁创建和回收,因此 React 引入事件池,在事件池中获取或释放事件对象。即 React 事件对象不会被释放掉,而是存放进一个数组中,当事件触发,就从这个数组中弹出,避免频繁地去创建和销毁(垃圾回收)。
#### 进阶理解(挑战高薪)
3、方便事件统一管理和事务机制
## 29.react中样式污染产生的原因
React最终编译打包后都在一个html页面中,如果在两个组件中取一样类名分别引用在自身,那么后者会覆盖前者。默认情况下,只要导入了组件,不管组件有没有显示在页面中,组件的样式就会生效。也就是说并没有自己的局部作用域
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









