







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
多年来,由于蓬勃发展的开源社区和商业公司支持该项目,一个全面的 Kafka 生态系统已经形成。许多大大小小的企业都认可了 Kafka,这充分说明了它作为一个产品的成熟度。
虽然 Kafka 的简单架构使其能够快速发展并抢占先机,但它也为适应不同场景的潜在困难留下了空间。其中一些挑战包括:
- 重新平衡的痛苦
- 难以扩展代理、主题、分区和副本
- 代理故障处理
- 延迟和抖动
- 企业级功能
- 云迁移
Kafka 出现在 2010 年左右,当时正值大数据的最初爆炸式增长时期。随着数据量在随后的几年中持续增长,功能要求和易用性变得越来越重要。更重要的是,“云原生”的概念开始受到关注,这预示着 Kafka 的新挑战者,Apache Pulsar 就是其中的佼佼者。
Pulsar:为云原生而生
Kafka 的经典架构启发了许多后继者,包括 Apache Pulsar。作为面向云原生环境的下一代消息传递平台,Pulsar 拥有用于计算和存储的解耦架构。
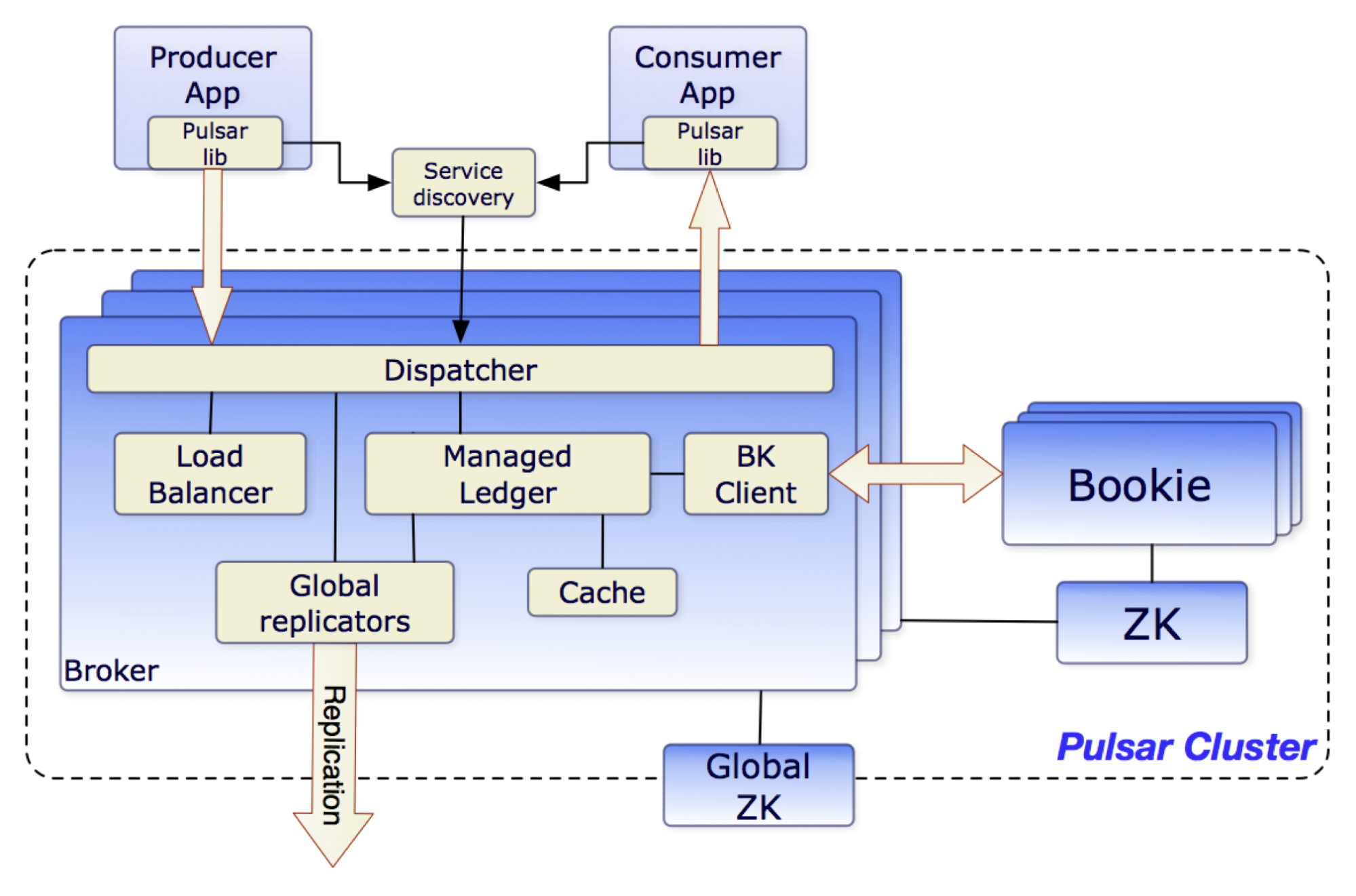
Pulsar broker 作为计算层,而存储则由另一个 Apache 顶级项目 Apache BookKeeper 支持,Apache BookKeeper 是一个分布式预写日志 (WAL) 系统。BookKeeper 可以有效地处理大量数据存储任务,元数据来源于 ZooKeeper。
Pulsar 的分层架构、云原生兼容性以及多租户等开源企业特性,为用户在生产中提供了更多的可能性。然而,其复杂的结构也意味着更高的学习成本和就业市场上缺乏人才。这也是为什么像腾讯这样的大型科技公司已经认可了Pulsar,但较小的公司一直在努力采用它的原因。
与 Kafka 相比,Pulsar 还有很长的路要走,尤其是在其生态系统方面,但它自成立以来一直保持着强劲的势头。
- 2012 年:雅虎内部开发!
- 2016 年:在 Apache 2.0 许可下开源
- 2018 年:成为 Apache 顶级项目 (TLP)
- 2023:600+ 贡献者,12.5K+ Stars,3.3K+ Forks
2021 年,Pulsar 的月活跃贡献者数量超过了 Kafka。在成为 TLP 的相差 5 年的情况下(2013 年的 Kafka 和 2018 年的 Pulsar),Pulsar 如何解决 Kafka 的痛点?它们之间有哪些主要区别?有了上面的背景信息,让我们更详细地回顾一下这些问题。
代理和分区:是否解耦
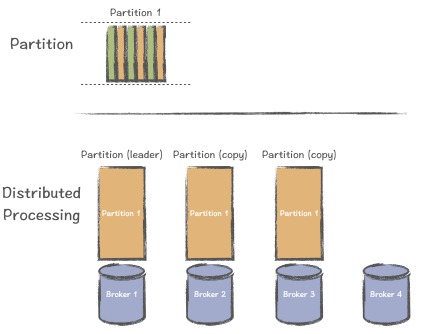
第一个主要区别是两个系统如何处理代理和分区之间的关系。Kafka 的分区和代理是紧密耦合的。当生产者将数据发布到 Kafka 集群时,数据会写入分区。每个分区都有一个领导节点,该节点具有多个(或零个)跟随节点,这些节点在领导节点发生故障时复制数据。
这种做法最困难的部分是分区的数据迁移。如果 Kafka 分区中有大量数据,则迁移过程可能是一场噩梦。分区和代理之间的强耦合关系,在某种程度上导致了 Kafka 中的一系列其他问题。
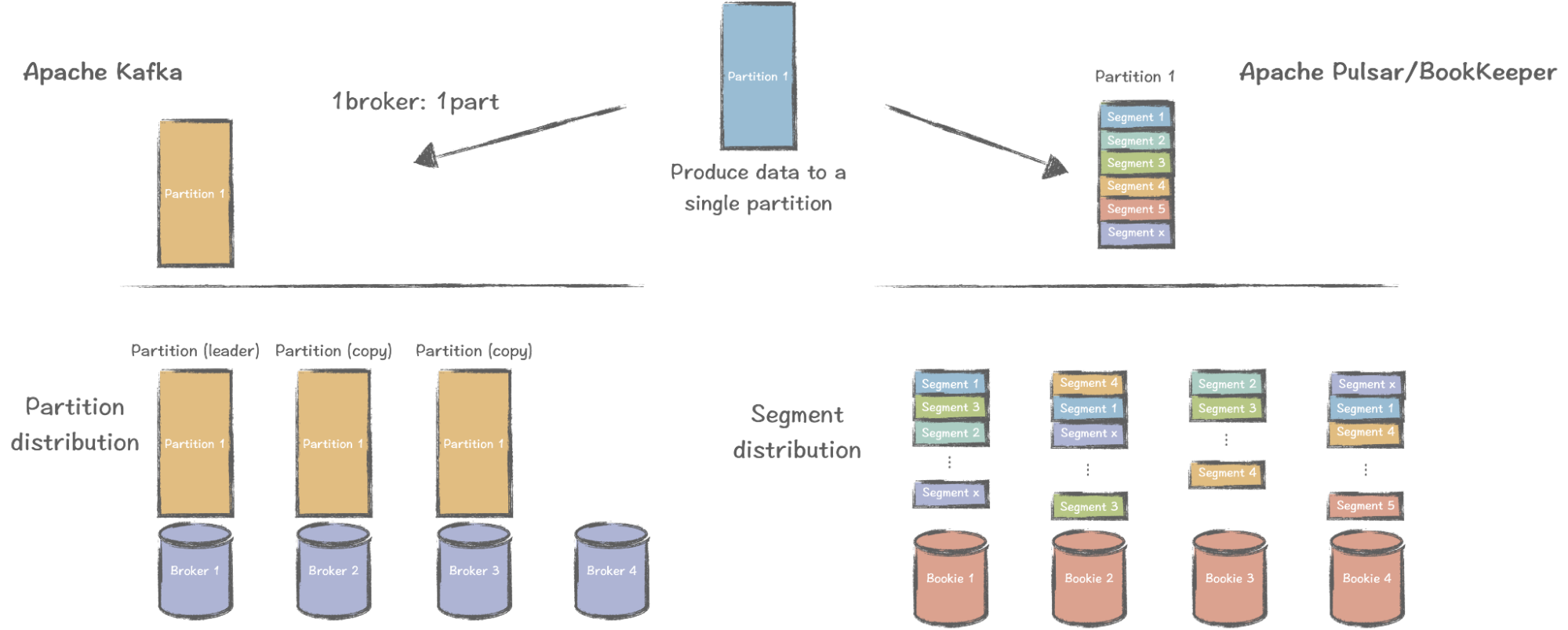
相比之下,分区和代理在 Pulsar 中是松散耦合的。一个分区可以进一步划分为多个段,这允许跨多个存储节点(i.e. bookies)对条目进行条带化。换句话说,单个分区中的数据可以存储在具有多个副本的多个节点中。
在上图中,分区 1 中有许多剥离的数据段,段 1 在 Bookie 1、Bookie 2 和 Bookie 4 中可能有副本。如果其中一个 Broker 失败,对分区的影响是微不足道的,因为它可能只影响一个或几个部分。此外,与整个分区的数据丢失相比,恢复过程要快得多。
当 Kafka 在十多年前发展起来时,它需要快速增长,并没有优先考虑细粒度的数据存储和管理。相比之下,Pulsar 在这方面提供了更复杂的方式,为其未来的增长带来了更大的空间。
可扩展性
可伸缩性是区分这两种邮件系统的另一个关键因素。
在 Kafka 中,您有多个代理来接收数据(一个领导者具有多个 ISR)。如果发生节点故障,则该代理上的分区将丢失。它需要手动维护(或脚本)进行恢复,并且逻辑相对复杂。您不能简单地将其替换为新的代理,并且以前的代理 ID 无法自动转移。
另一个麻烦是,新代理无法立即处理旧代理的流量,因为新代理没有分区。您需要手动将旧分区迁移到代理。但是,如果数据量很大,则迁移可能会很麻烦,如上一节所述。
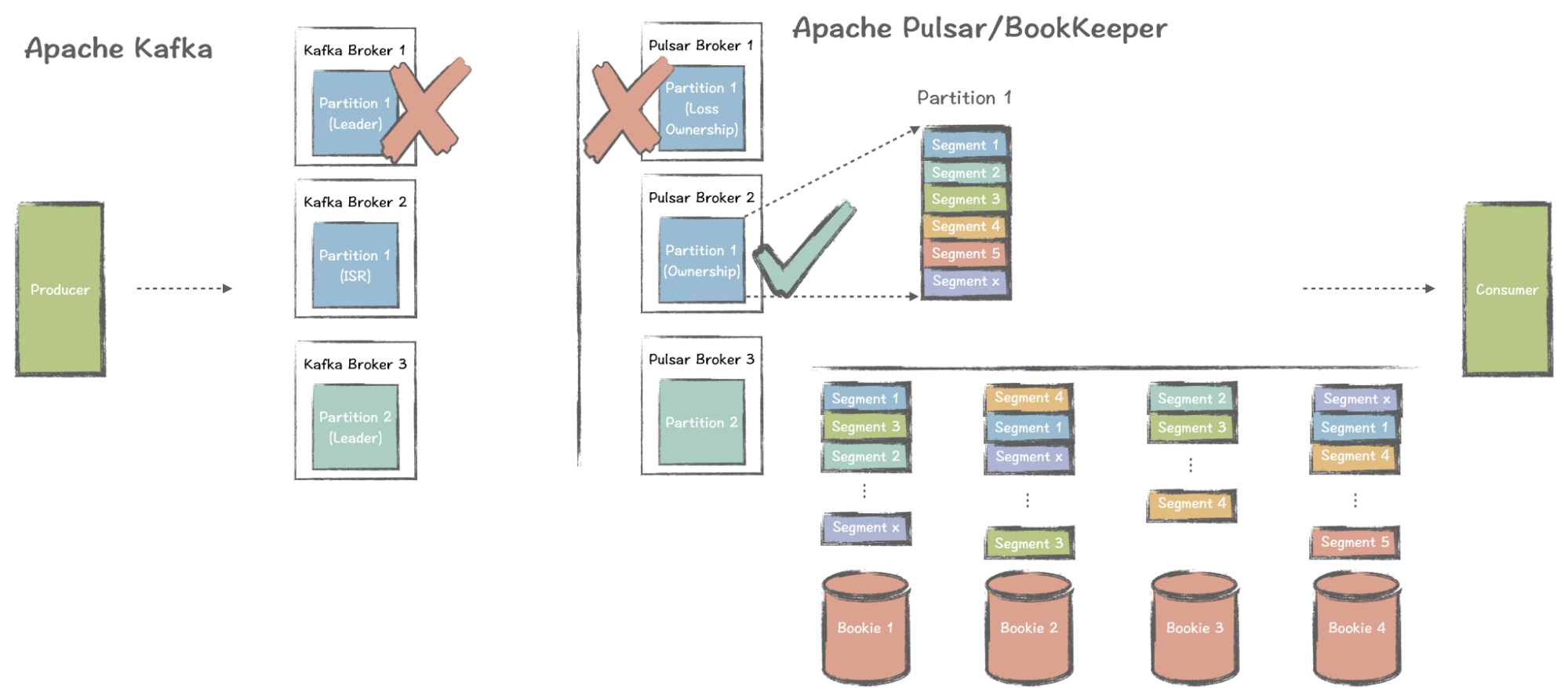
那么,Pulsar 是如何处理同样问题的呢?
如果 Pulsar broker 发生故障,它将失去之前持有的分区的所有权,该分区的信息存储在 ZooKeeper 中。检测到更改后,其他经纪人会重新选择新的经纪人。对于整个 Pulsar 集群来说,代理故障并不是一个重大问题,因为另一个代理可以快速接管。
这个过程的效率在于 Pulsar 经纪人是无状态的。当代理出现故障时,可以立即扩展代理集群。代理不存储数据,仅作为计算层。Broker 存储数据,他们甚至不需要知道经纪人方面发生了什么。
在 Pulsar 中丢失热分区的影响远小于 Kafka,恢复速度也快得多。如果需要提升集群处理消息的能力,只需添加 broker 即可,无需担心存储层。
热点传输
在 Kafka 和 Pulsar 中,broker 处理流量热点的能力和方法不同。
在 Kafka 中,当代理的写入负载很重时,增加代理的数量无济于事,因为一次只有一个代理可以处理写入。如果代理有大量读取,则添加新的代理也不起作用,因为其中没有分区。如前所述,重新平衡流量是另一个棘手的问题。
通常,有两种解决方案可用于处理 Kafka 中的流量热点:
- 增加分区数量会带来很大的重新平衡困难。
- 扩大代理规模以提高其性能。如果代理发生故障,则需要使用另一个代理来处理繁重的流量,这也需要纵向扩展(最终是整个集群),使其成为一种成本低效的方法。
在 Pulsar 中,写入热点会导致大量剥离的段。随着写入的数据越来越多,经纪人会生成更多的细分市场,并将它们分配给多个 Broker。如有必要,Broker 集群可以简单地横向扩展以存储新添加的区段(在 BookKeeper 中也称为账本)。
对于读取热点,Pulsar 依赖于 bundle,每个 bundle 包含多个主题来处理客户端请求。每个捆绑包都分配给特定的代理。捆绑包提供了一种负载平衡机制,允许将超过某些预配置阈值(例如,主题计数和带宽)的捆绑包拆分为两个新捆绑包,其中一个捆绑包将卸载到新的代理。
写入和读取实现
Kafka 和 Pulsar 如何写入和读取请求直接关系到它们的延迟和抖动,这是选择消息传递系统时的两个重要因素。
Kafka 中的写入严重依赖于操作系统的页面缓存。数据直接写入页面缓存(内存),然后异步写入磁盘。Kafka 利用零复制原则,允许数据直接从内存传输到磁盘文件。换言之,Kafka 代理不需要分配额外的单独位置来存储数据。
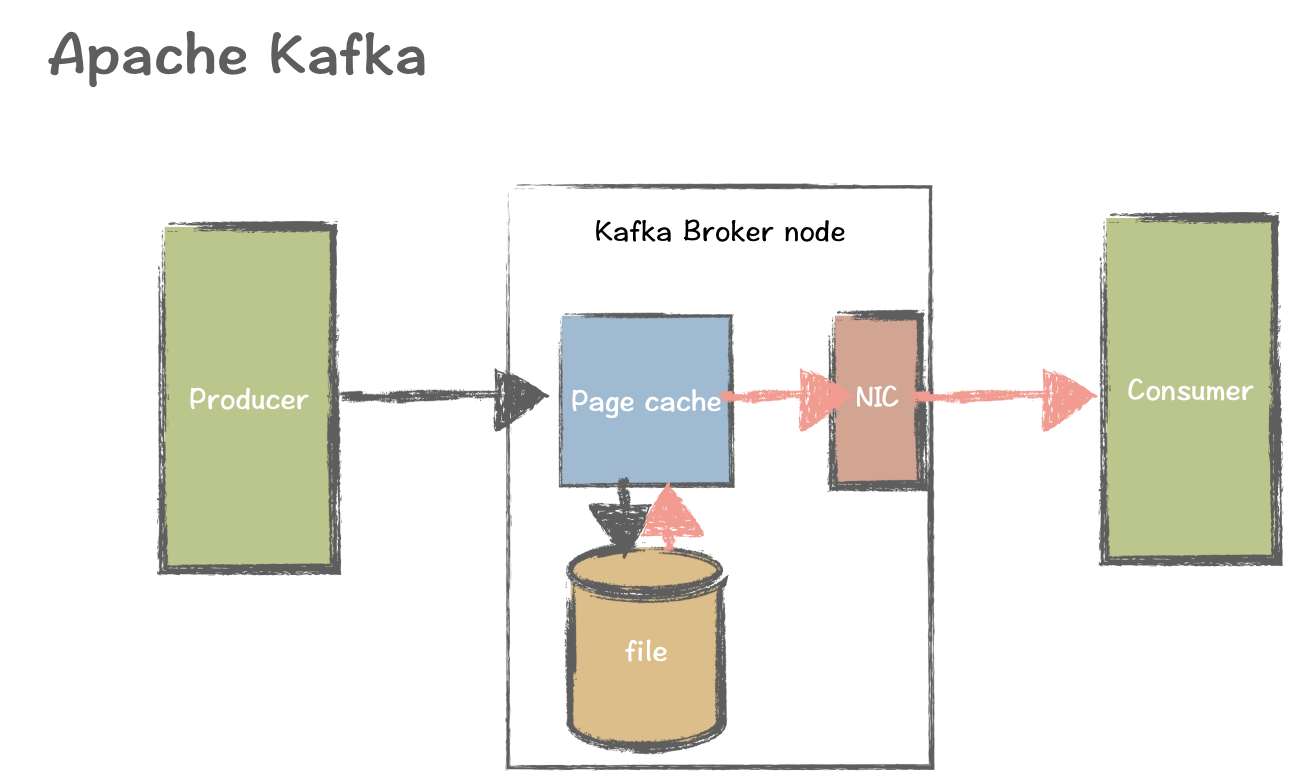
但是,Kafka 对页面缓存的严重依赖可能会导致问题。在追赶读取方案中,从文件中读取历史数据需要将数据加载回内存。这可能会从缓存中逐出未读的拖尾读取(最新数据),从而导致内存和磁盘之间的交换效率低下。这可能会影响系统稳定性、延迟和吞吐量。
Pulsar 以不同的方式处理数据读取和写入。Pulsar 代理充当 BookKeeper 客户端,将数据写入账本。该过程涉及将数据作为预写日志写入日志文件(内存),然后以异步和顺序将数据写入日志磁盘。这提供了事务管理并确保数据持久性,允许在出现问题时快速回滚。
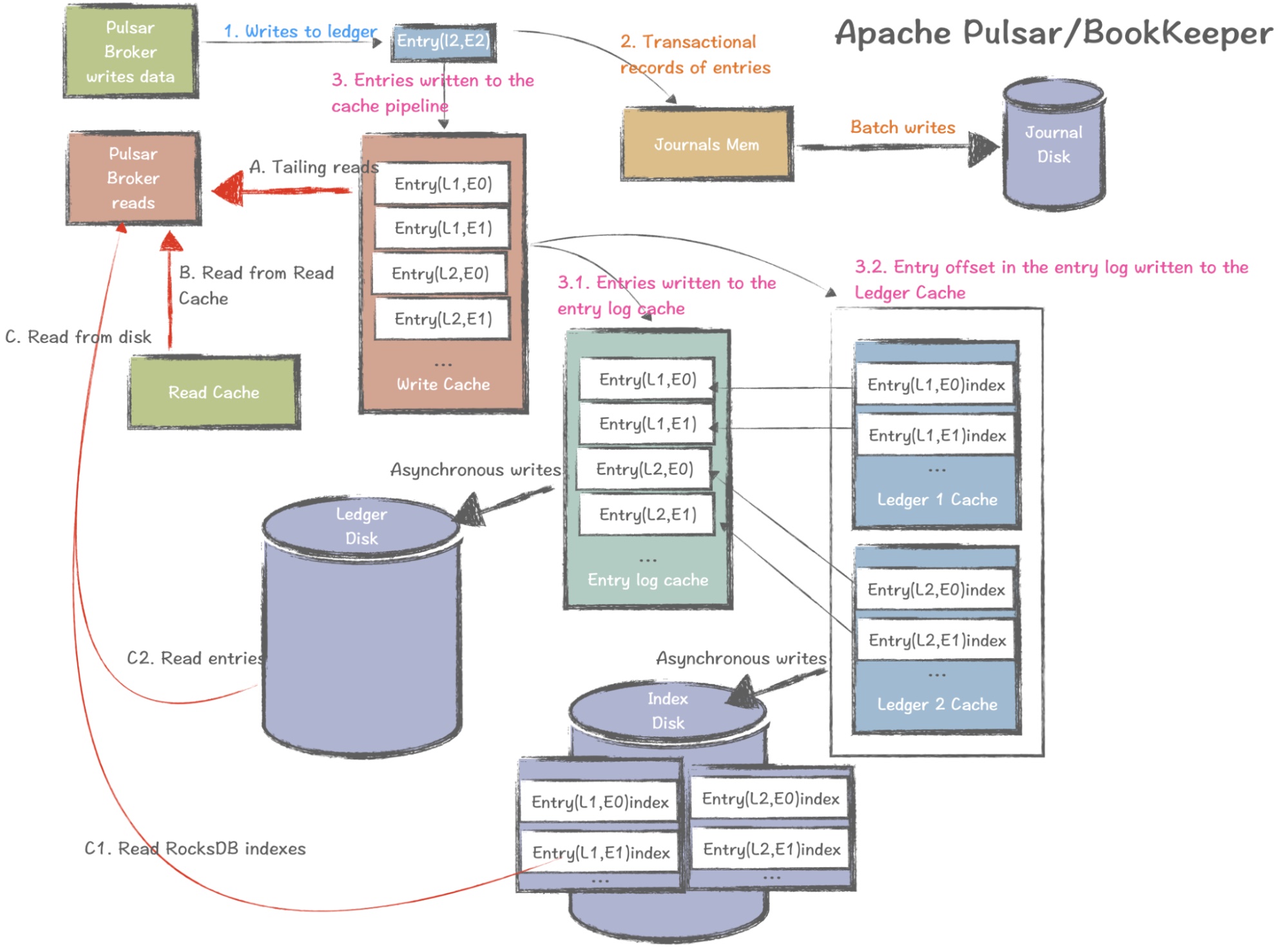
Pulsar 不使用 Zero Copy,而是依赖于 JVM 堆外内存。记录事务日志时,数据会进入写入缓存,然后存储在两个位置:条目日志缓存(数据异步写入账本磁盘)和账本缓存(数据异步写入索引磁盘(存储在 RocksDB 中)。
对于 Pulsar 中的读取,如果消费者需要读取数据,并且它恰好在内存中(在写入缓存中命中,这通常是拖尾读取的情况),则可以直接访问它。如果数据不在写入缓存中,则从读取缓存中读取数据。否则,会根据 RocksDB 中存储的索引从磁盘中读取数据。检索数据后,数据将写回读取缓存。这可确保下次请求数据时,很有可能在读缓存中找到该数据。
诚然,读取过程涉及许多组件,这可能会导致额外的网络开销和优化难度,有时查明有问题的组件可能具有挑战性。尽管如此,它带来的好处是相当明显的。这种多层架构允许在各个级别进行稳定的数据检索,并且其 JVM 堆外内存管理具有高度可控性(与 Kafka 相比,Pulsar 对内存的依赖更少)。
Kafka 和 Pulsar 中处理读写的不同方法导致了延迟和整个过程中的不同功能。
如下图所示,在大多数情况下,Kafka 在写入页面缓存时延迟较低,并且内存足够大来处理数据。但是,如果数据消耗速度较慢,并且内存中仍有大量数据,则需要将数据大块交换到磁盘上。如果磁盘速度无法与内存匹配(在大多数情况下都是如此),则会出现明显的延迟峰值,因为在内存数据交换到磁盘之前无法写入传入数据。这会导致抖动,这在延迟敏感的场景中可能很危险。虽然 Pulsar 的延迟可能不比 Kafka 低,但它的稳定性明显更好。即使有额外的组件和一些性能损失,Pulsar 的整体稳定性也值得权衡。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)**
[外链图片转存中…(img-FSxK3i1d-1713231743626)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2360
2360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









