







学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
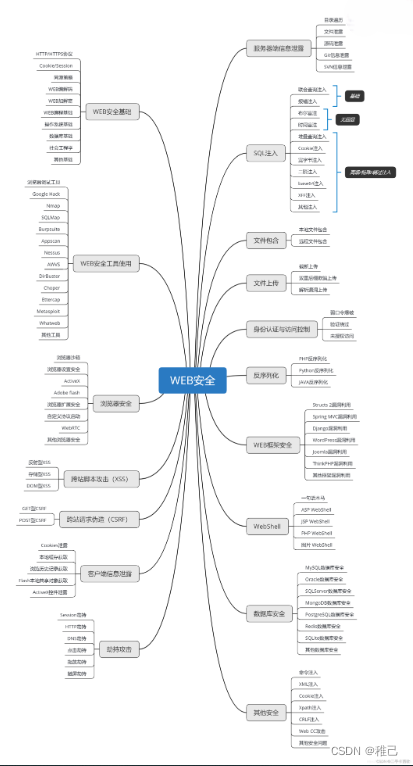
需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
static {
addDeprecatedKeys();
// adds the default resources
Configuration.addDefaultResource("hdfs-default.xml"); //#加载hdfs模块的默认配置文件
Configuration.addDefaultResource("hdfs-site.xml"); //加载个人配置的hdfs配置文件
}
}
那么,今天,我们就来了解一下hadoop的默认配置文件(core-default.xml、hdfs-default.xml、mapred-default.xml、yarn-default.xml)里的内容
### 一、core-default.xml
### 1、hadoop.tmp.dir
打开这个文件后,有这样一个属性:hadoop.tmp.dir,默认设置的值为/tmp/hadoop-${user.name}。
/tmp/hadoop-hyxy
----dfs #与hdfs有关的文件存储位置
----name
----data
----mapred #与mr有关的文件存储位置
而将路径设置在/tmp下很不安全,Linux在重新启动时,很可能就删除这个路径下的文件。因此在安全分布式集群下,我们都会在etc/hadoop/core-site.xml重新设置这个路径。
2、fs.defaultFS
在来看core-default.xml中的另一个比较重要的属性:fs.defaultFS
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
</property>
这个属性的作用就是定义hdfs文件系统的主机和端口号的。不管在是伪分布式下,还是在完全分布式下,我们都会在etc/hadoop/core-site.xml配置文件里重新定义它的值。主机名可以使用ip,也可以使用主机名称。端口号我们可以自定义,不过在hadoop1.x版本默认使用的是9000,而在hadoop2.x中默认使用的是8020。value的值可以这样设置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://[ip|hostname]:port</value> #配置时,请使用真实的ip、hostname、port
</property>
或者
<property>
<name>fs.defaultFS</name>
<value>hdfs://[ip|hostname]/</value> #这种写法就会使用默认端口号
</property>
3、io.file.buffer.size
<!-- i/o properties -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
这个属性设置的是集群在进行读写操作时,缓冲区的大小。默认是4K。
core-default.xml内的其余的属性,可以自行查看,这里不做讲解了。
二、hdfs-default.xml
1、dfs.namenode.name.dir
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
我们可以借助有道翻译,将每个属性的描述翻译一下,而这个属性,有道是这样翻译的:确定DFS名称节点应该在本地文件系统的何处存储名称表(fsimage)。如果这是一个以逗号分隔的目录列表,那么name表将复制到所有目录中,以实现冗余。这样的解释应该很清楚了吧,而且用到了core-default.xml/core-site.xml里的属性hadoop.tmp.dir。当然我们可以在etc/hadoop/hdfs-site.xml进行指定设置。
2、dfs.datanode.data.dir
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
用于定义DFS数据节点应将其块存储在本地文件系统的何处。如果这是一个以逗号分隔的目录列表,那么数据将存储在所有命名的目录中,通常存储在不同的设备上。对于HDFS存储策略,应该用相应的存储类型([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK])标记目录。如果目录没有显式标记存储类型,则默认存储类型为磁盘。如果本地文件系统权限允许,将创建不存在的目录。
可以在etc/hadoop/hdfs-site.xml进行指定设置。
3、dfs.replication
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
DFS上的数据库的副本数,缺省值是3。可以在创建文件时进行指定,如果没有指定,就使用缺省值。
4、dfs.blocksize
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
文件系统中的块大小,以字节为单位,如134217728表示128 MB。你也可以使用以下后缀(不区分大小写):k,m,g,t,p,e以指定大小(例如128k, 512m, 1g等)。
5、dfs.namenode.http-address
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
dfs namenode web ui使用的监听地址和基本端口。可以在etc/hadoop/hdfs-site.xml进行指定设置。
6、dfs.webhdfs.enabled
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
在namenode和datanode中启用WebHDFS (REST API)。false表示不启用。
hdfs-default.xml配置文件内的其他属性,可以自行查看,这里就不一一介绍了。
三、mapred-default.xml
当我们使用mapreduce程序时,hadoop集群就会读取该配置文件里的配置信息,我们来看几个比较重要的属性
1、mapreduce.framework.name
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
</property>
这个属性用于指定执行MapReduce作业的运行时框架。属性值可以是local,classic或yarn。我们可以在etc/hadoop/mapred-site.xml里来重新指定值。不过呢,在etc/hadoop/目录下没有mapred-site.xml文件,倒是有一个mapred-site.xml.template样板。我们可以复制一份,将名称改为mapred-site.xml。
2、mapreduce.jobhistory.address
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
指定了查看运行完mapreduce程序的服务器的IPC协议的主机名和端口号。可以通过mapred-site.xml进行设置
3、mapreduce.jobhistory.webapp.address
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
指定了使用webui查看mapreduce程序的主机名和端口号。可以通过mapred-site.xml进行设置。
mapred-default.xml配置文件内的其他属性,可以自行查看,这里就不一一介绍了。
四、yarn-default.xml
如果在hadoop下指定使用了yarn,那么一定会读取yarn-default.xml这个配置文件。一起来看看里面的属性吧
1、yarn.nodemanager.aux-services
<property>
<name>yarn.nodemanager.aux-services</name>
<value></value>
<!--<value>mapreduce_shuffle</value>-->
</property>
这个属性用于指定在进行mapreduce作业时,yarn使用mapreduce_shuffle混洗技术。这个混洗技术是hadoop的一个核心技术,非常重要。可以在yarn-site.xml里进行设置。
2、yarn.nodemanager.aux-services.mapreduce_shuffle.class
用于指定混洗技术对应的字节码文件。
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
3、yarn.resourcemanager.hostname
用于指定resourcemanager的主机名
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
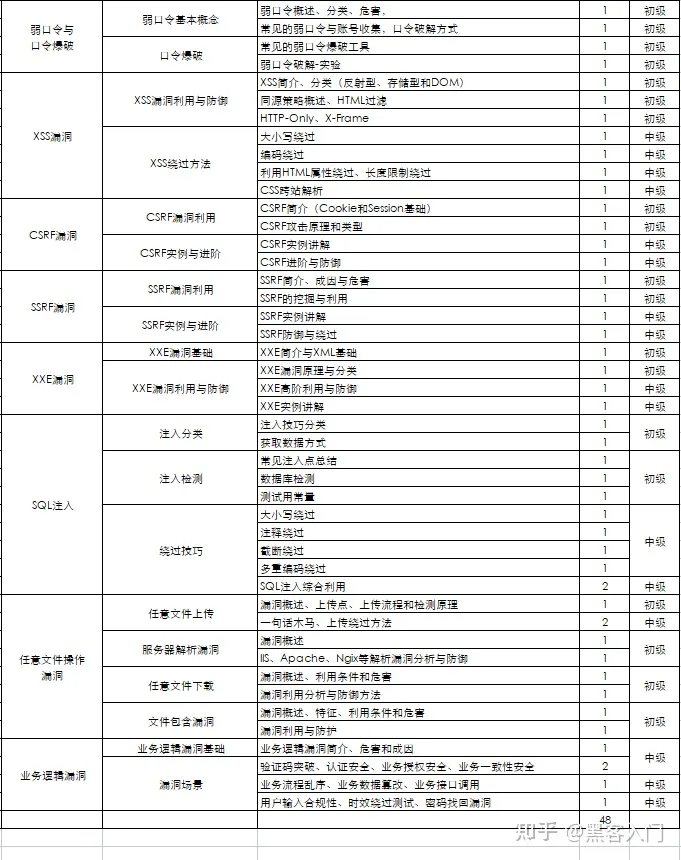
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
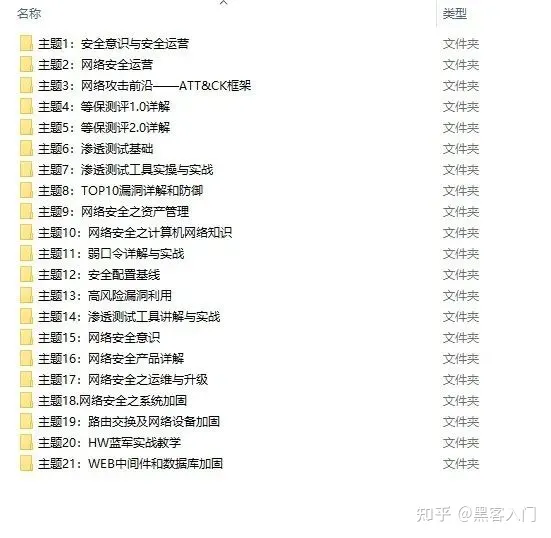
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









