







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
写在前面
Python爬虫可能大家都玩腻了,那就玩一下Golang的爬虫吧!
这篇文章会持续更新哒!
思维导图
想获取
原图或是.xmind格式可在文末扫描并回复Go爬虫
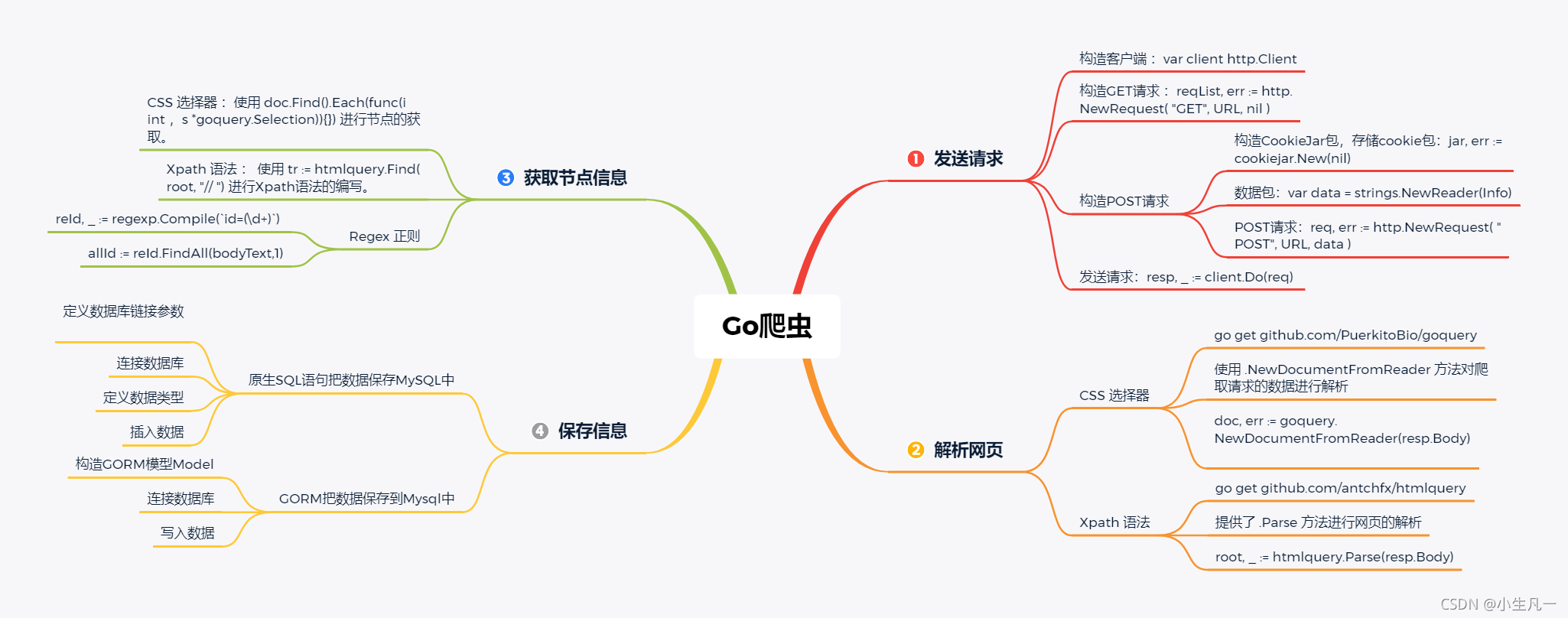
目录

Golang中提供了net/http这个包原生支持request和response。
1. 发送请求
- 构造客户端
var client http.Client
- 构造GET请求:
reqList, err := http.NewRequest(“GET”, URL, nil)
- 构造POST请求
Go中提供了一个cookiejar.New的函数方法,用于保留生成Cookie信息,这个是为了一些网站要登陆才能爬取的情况,所以我们登陆完之后,会有一个cookie,这个cookie是存储用户信息的,也就是这个信息是让服务器知道是谁进行这一次的访问!比如说登陆学校的教务处进行爬取课表,因为课表每个人都可能是不同的,所以就需要登陆,让服务器知道这是谁的课表信息,所以就需要在请求头上加上cookie进行伪装爬取。
jar, err := cookiejar.New(nil)
if err != nil {
panic(err)
}
构造POST请求的时候,可以把要传输的数据进行封装好,与URL一起构造
var client http.Client
Info :=“muser=”+muserid+“&”+“passwd=”+password
var data = strings.NewReader(Info)
req, err := http.NewRequest(“POST”, URL, data)
- 添加请求头
req.Header.Set(“Connection”, “keep-alive”)
req.Header.Set(“Pragma”, “no-cache”)
req.Header.Set(“Cache-Control”, “no-cache”)
req.Header.Set(“Upgrade-Insecure-Requests”, “1”)
req.Header.Set(“Content-Type”, “application/x-www-form-urlencoded”)
req.Header.Set(“User-Agent”, “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36”)
req.Header.Set(“Accept”, “text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9”)
req.Header.Set(“Accept-Language”, “zh-CN,zh;q=0.9”)
- 发送请求
resp, _:= client.Do(req) // 发送请求
bodyText, _ := ioutil.ReadAll(resp.Body) // 使用缓冲区读取网页内容
- 关于cookie
上文也提到了一个包,当发送完请求之后,cookie就会保存在这个client.Jar这个包中
myStr:=fmt.Sprintf(“%s”,client.Jar) //强制类型转化 指针装到string
我们处理打印出这个client.Jar这个包的信息之后,选出响应的cookie,然后放在请求头上面即可!就能处理登陆情况下的cookie问题了。
req.Header.Set(“Cookie”, “ASP.NET_SessionId=”+cook)
至此,发送请求部分就完全完成了!
2. 解析网页
2.1 CSS选择器
github.com/PuerkitoBio/goquery 提供了.NewDocumentFromReader方法进行网页的解析。
doc, err := goquery.NewDocumentFromReader(resp.Body)
2.2 Xpath 语法
github.com/antchfx/htmlquery 提供了.Parse方法进行网页的解析
root, _ := htmlquery.Parse(resp.Body)
2.3 Regex 正则
reId, _ := regexp.Compile(id=(\d+)) // 正则匹配
allId := reId.FindAll(bodyText,1)
for _,item := range allId {
id=string(item)
}
3. 获取节点信息
3.1 CSS 选择器
通过2.1,我们拿到上一步解析出来的doc之后,可以进行css选择器语法,进行结点的选择。
doc.Find(“#main > div.right > div.detail_main_content”).
Each(func(i int, s *goquery.Selection) {
Data.title = s.Find(“p”).Text()
Data.time = s.Find(“#fbsj”).Text()
Data.author = s.Find(“#author”).Text()
Data.count = Read_Count(Read_Id)
fmt.Println(Data.title, Data.time, Data.author,Data.count)
})
doc.Find(“#news_content_display”).Each(func(i int, s *goquery.Selection) {
Data.content = s.Find(“p”).Text()
fmt.Println(Data.content)
})
3.2 Xpath 语法
通过3.2,我们拿到上一步解析出来的root之后,可以进行Xpath语法的编写,进行结点的选择。
tr := htmlquery.Find(root, “//*[@id=‘LB_kb’]/table/tbody/tr/td”) //使用Xpath进行结点信息的获取
for _, row := range tr { //len(tr)=13
classNames := htmlquery.Find(row, “./font”)
classPosistions := htmlquery.Find(row,“./text()[4]”)
classTeachers := htmlquery.Find(row,“./text()[5]”)
if len(classNames)!=0 {
className = htmlquery.InnerText(classNames[0])
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
es[0])
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-2SvrsnpE-1713435455084)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1762
1762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









