







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
前言:
兄弟们,你们心心念念的python全栈系列4-4系类就出完了,其实python全栈系列我本来是准备写一个整个系列的,完全不止现在这么4篇幅文章,但是这样又太过于耗时间,细心的小伙伴应该就发现了,凡哥把python全栈接口测试系列,每一个知识点按照顺序写了下去,其实python全栈4-3后面,凡哥就开始写接口自动化测试了,

【python之smtplib模块发送邮件】
虽然一般自动化持续集成中都用Jenkins来发送邮件,但了解掌握一下python的smtplib模块发送邮件也是必要的。
先明确一下发邮件的步骤:
1.确定邮件服务商:网易、qq等
2.登录邮箱:用户名/密码(密码一般是授权码)
3.编辑邮件主题、内容、附件
4.发送邮件
最简单的实现:
| 1 2 3 4 5 6 7 8 | server``= smtplib.SMTP(``'smtp.163.com'``,``25``) server.login(emailname,emailpwd)``# 登录 # 邮件内容 msg``= '''\\From: xia Subject: Hello World This is a test ''' # 发送邮件 server.sendmail(emailname,``'18551052425@163.com'``,msg) |
如上代码创建一个实例化对象server,调用SMTP类下的login方法,采用163邮件服务,默认端口是25,emailname和emailpwd分别为发送邮件的用户名和授权码。
实际在发邮件的时候,我们通常使用加密模式。简单的两种加密方法:

1.tls模式加密
| 1 2 3 4 5 6 7 8 9 10 11 | server``= smtplib.SMTP(``'smtp.163.com'``,``25``) server.login(emailname,emailpwd)``# 登录 context``= ssl.create_default_context() server.starttls(context``=``context) # 邮件内容 msg = '''\\ From: xia Subject: Hello World This``is a test ''' # 发送邮件 server.sendmail(emailname,``'18551052425@163.com'``,msg) server.quit() |
2.ssl加密,默认加密端口是465
| 1 2 3 4 5 6 7 8 9 10 | server``= smtplib.SMTP_SSL(``'smtp.163.com'``,``465``) server.login(emailname,emailpwd)``# 登录 # 邮件内容 msg``= '''\\ From: xia Subject: Hello World This is a test ''' # 发送邮件 server.sendmail(emailname,``'18551052425@163.com'``,msg) server.quit() |
创建server后,要记得quit关闭。也可以使用上下文管理器,防止忘记关闭邮件:
| 1 2 3 4 5 6 7 8 9 | with smtplib.SMTP_SSL(``'smtp.163.com'``,``465``) as server: server.login(emailname,emailpwd)``# 登录 # 邮件内容 msg``= '''\\ From: xia Subject: Hello World This is a test ''' # 发送邮件 server.sendmail(emailname,``'18551052425@163.com'``,msg) |
但是实际应用中,不可能会发送这么简单的邮件。我们需要丰富邮件主题、内容和附件。
这就需要引入3个模块:

| 1 2 3 | from email.mime.multipart``import MIMEMultipart from email.mime.text``import MIMEText from email.mime.application``import MIMEApplication |
首先创建一个带附件的实例MIMEMultipart(),设置邮件主题,from,to信息:
| 1 2 3 4 | msg_total``= MIMEMultipart() msg_total[``'subject'``]``= Header(``self``.subject,``'utf-8'``) msg_total[``'From'``]``= emailname msg_total[``'To'``]``= tolist |
添加邮件正文内容,这里添加html格式的内容:
| 1 2 | content``= '''<p style="color:red">你好,我是一份测试邮件。</p>''' msg_total.attach(MIMEText(content,``'html'``,``'utf-8'``)) |
也可以读取某个文件内容作为邮件正文:
| 1 2 3 | with``open``(``file``,``'rb'``) as f: content``= f.read() msg_total.attach(MIMEText(content,``'html'``,``'utf-8'``)) |
添加附件的话,MIMEText模块和MIMEAplication模块都可以添加,只不过看源码发现,MIMEApplication比MIMEText要简单一些,需要配置的参数少一些。
MIMEText模块添加附件:
| 1 2 3 4 5 6 7 | with``open``(``file``,``'rb'``) as f: mail_attach``= f.read() att``= MIMEText(mail_attach,``'base64'``,``'utf-8'``) att[``"Content-Type"``]``= 'application/octet-stream' # 这里的filename可以任意写,写什么名字,邮件中显示什么名字 att[``"Content-Disposition"``]``= 'attachment; filename="测试报告"' msg_total.attach(att) |
MIMEApplication模块添加附件:
| 1 2 3 4 5 6 | with``open``(file_new,``'rb'``) as f: mail_attach``= f.read() att2``= MIMEApplication(mail_attach) # 添加附件的头信息 att2.add_header(``'content-disposition'``,``'attachment'``, filename``=``'{}'``.``format``(file_name)) msg_total.attach(att2) |
对比代码也可以发现,MIMEapplication模块添加附件更方便一些。
上面邮件正文和附件文件都是写死的,一般在应用中,我们可以获取当前最新的测试执行报告作为附件:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | file = os.listdir(report_path)``# 列出目录的下所有文件和文件夹 file``.sort(key``=``lambda fn: os.path.getmtime(report_path``+ "\\" + fn))``# 按时间排序 file_name``= file``[``-``1``] file_new``= os.path.join(report_path,``file``[``-``1``])``# 获取最新的文件保存到file_new # 添加文件内容作为正文模块 with``open``(file_new,``'rb'``) as f: content``= f.read() msg_total.attach(MIMEText(content,``'html'``,``'utf-8'``)) # 附件模块 with``open``(file_new,``'rb'``) as f: mail_attach``= f.read() att``= MIMEText(mail_attach,``'base64'``,``'utf-8'``) att[``"Content-Type"``]``= 'application/octet-stream' # 这里的filename可以任意写,写什么名字,邮件中显示什么名字 att[``"Content-Disposition"``]``= 'attachment; filename="{}"'``.``format``(file_name) msg_total.attach(att) |
整合以上邮件主题、内容、附件,加上异常处理,并封装成一个类,便于后续调用。完整代码如下:

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | import smtplib from python15.class_email.conf``import * from email.mime.multipart``import MIMEMultipart from email.mime.text``import MIMEText from email.mime.application``import MIMEApplication from email.header``import Header import os class MyEmail: def __init__(``self``,host,port,tolist,subject,content``=``None``): self``.host``= host``#邮件服务地址 self``.port``= port``# 邮件服务端口 self``.tolist``= tolist``# 接收人 self``.subject``= subject``# 邮件主题 self``.content``= content``# 邮件内容 def send_email(``self``): # 总的邮件内容,创建一个带附件的实例 msg_total``= MIMEMultipart() msg_total[``'subject'``]``= Header(``self``.subject,``'utf-8'``) msg_total[``'From'``]``= emailname msg_total[``'To'``]``= self``.tolist # 添加普通正文模块 # msg_total.attach(MIMEText(self.content, 'html','utf-8')) file = os.listdir(report_path)``# 列出目录的下所有文件和文件夹 file``.sort(key``=``lambda fn: os.path.getmtime(report_path``+ "\\" + fn))``# 按时间排序 file_name``= file``[``-``1``] file_new``= os.path.join(report_path,``file``[``-``1``])``# 获取最新的文件保存到file_new # 添加文件内容作为正文模块 with``open``(file_new,``'rb'``) as f: content``= f.read() msg_total.attach(MIMEText(content,``'html'``,``'utf-8'``)) # 附件模块1 MIMEText添加附件 with``open``(file_new,``'rb'``) as f: mail_attach``= f.read() att1``= MIMEText(mail_attach,``'base64'``,``'utf-8'``) att1[``"Content-Type"``]``= 'application/octet-stream' # 这里的filename可以任意写,写什么名字,邮件中显示什么名字 att1[``"Content-Disposition"``]``= 'attachment; filename="{}"'``.``format``(file_name) msg_total.attach(att1) # 附件模块2 MIMEApplication模块添加附件 with``open``(file_new,``'rb'``) as f: mail_attach``= f.read() att2``= MIMEApplication(mail_attach) # 添加附件的头信息 att2.add_header(``'content-disposition'``,``'attachment'``, filename``=``'{}'``.``format``(file_name)) msg_total.attach(att2) try``: self``.server``= smtplib.SMTP_SSL(``self``.host,``self``.port) self``.server.login(emailname, emailpwd) self``.server.sendmail(emailname,``self``.tolist, msg_total.as_string()) print``(``"邮件发送成功"``) except smtplib.SMTPException as e: print``(``"邮件发送失败"``,e) finally``: self``.server.quit() |
【python编程之ini文件处理-configparser模块应用】
一、configparser模块是什么
- 可以用来操作后缀为 .ini 的配置文件;
- python标准库(就是python自带的意思,无需安装)
二、configparser模块基本使用
- 2.1 读取 ini 配置文件
存在config.ini配置文件,内容如下:
#config.ini
[DEFAULT]
excel_path = ../test_cases/case_data.xlsx
log_path = ../logs/test.log
log_level = 1
[email]
user_name = 32@qq.com
password = 123456
使用configparser模块读取配置文件
import configparser
#创建配置文件对象
conf = configparser.ConfigParser()
#读取配置文件
conf.read('config.ini', encoding="utf-8")
#列表方式返回配置文件所有的section
print( config.sections() ) #结果:['default', 'email']
#列表方式返回配置文件email 这个section下的所有键名称
print( conf.options('email') ) #结果:['user_name', 'password']
#以[(),()]格式返回 email 这个section下的所有键值对
print( conf.items('email') ) #结果:[('user_name', '32@qq.com'), ('password', '123456')]
#使用get方法获取配置文件具体的值,get方法:参数1-->section(节) 参数2-->key(键名)
value = conf.get('default', 'excel_path')
print(value)
import configparser
#创建配置文件对象
conf = configparser.ConfigParser()
#'DEFAULT'为section的名称,值中的字典为section下的键值对
conf["DEFAULT"] = {'excel_path' : '../test_cases/case_data.xlsx' , 'log_path' : '../logs/test.log'}
conf["email"] = {'user_name':'32@qq.com','password':'123456'}
#把设置的conf对象内容写入config.ini文件
with open('config.ini', 'w') as configfile:
conf.write(configfile)
import configparser
#创建配置文件对象
conf = configparser.ConfigParser()
#读取配置文件
conf.read('config.ini', encoding="utf-8")
#在conf对象中新增section
conf.add_section('webserver')
#在section对象中新增键值对
conf.set('webserver','ip','127.0.0.1')
conf.set('webserver','port','80')
#修改'DEFAULT'中键为'log_path'的值,如没有该键,则新建
conf.set('DEFAULT','log_path','test.log')
#删除指定section
conf.remove_section('email')
#删除指定键值对
conf.remove_option('DEFAULT','excel_path')
#写入config.ini文件
with open('config.ini', 'w') as f:
conf.write(f)
上述3个例子基本阐述了configparser模块的核心功能项;
例1:中,encoding="utf-8"为了放置读取的适合中文乱码;
例2:你可以理解为在字典中新增数据,键:配置文件的section,字符串格式;值:section的键值对,字典格式;
例3:中在使用add_section方法时,如果配置文件存在section,则会报错;而set方法在使用时,有则修改,无则新建。
【Python logging日志处理模块】
在程序中使用logging日志,方便记录并定位问题。
一、日志处理模块导入
import logging
二、日志等级
- NOSET,0,等于没写,废话
- DEBUG ,10,调试,一些额外信息、备注等,往往和主体功能无关
- INFO,20,主体功能的信息,比如记录做了什么
- WARNING,30,警告,可能有错误
- ERROR,40,错误
- CRITICAL,50,极其严重
一般来说,直接使用logging会有以下问题:1、日志只能在运行过程中,从控制台查看;2、等级为INFO及以下的日志信息没有被打印;3、无法查看运行时间、位置等信息。因此,建议不要使用logging.info()等操作。
三、日志定制
1、获取日志收集器logger

2、设置收集器级别
收集器级别设置后,只有级别等于或高于设置的级别才会被收集器捕捉到,比如设置为‘INFO’,NOSET和DEBUG级别的就不会被收集器收集。

3、准备日志处理器handler
有两种日志处理器,一种是控制台输出处理器StreamHandler,收集的日志直接在控制台输出,另一种是文件处理器FileHandler,收集的日志会存储到指定的文件里,方便随时查阅。
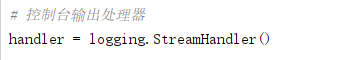

4、日志处理器设置级别

5、设置日志格式
比较常用的日志格式如下:
- asctime,%(asctime)s,表示运行时间,默认形式为 ‘2021-01-06 15:09:45,896’
- filename,%(filename)s,表示文件名,比如test.py
- name,%(name)s,表示收集器名称,用户自定义的
- levelname,%(levelname)s,表示日志的记录级别,比如‘INFO’、‘ERROR’等
- lineno,%(lineno)d,表示日志记录调用所在的源行号
- message,%(message)s,表示日志信息

6、将日志处理器添加至日志收集器

【python中MySQLdb模块用法实例】

这篇文章主要介绍了python中MySQLdb模块用法,以实例形式详细讲述了MySQLdb模块针对MySQL数据库的各种常见操作方法,非常具有实用价值,需要的朋友可以参考下
本文实例讲述了python中MySQLdb模块用法。分享给大家供大家参考。具体用法分析如下:
MySQLdb其实有点像php或asp中连接数据库的一个模式了,只是MySQLdb是针对mysql连接了接口,我们可以在python中连接MySQLdb来实现数据的各种操作。
python连接mysql的方案有oursql、PyMySQL、 myconnpy、MySQL Connector 等,不过本篇要说的确是另外一个类库MySQLdb,MySQLdb 是用于Python链接Mysql数据库的接口,它实现了 Python 数据库 API 规范 V2.0,基于 MySQL C API 上建立的。可以从:https://pypi.python.org/pypi/MySQL-python 进行获取和安装,而且很多发行版的linux源里都有该模块,可以直接通过源安装。
一、数据库连接
MySQLdb提供了connect方法用来和数据库建立连接,接收数个参数,返回连接对象:
代码如下:
conn=MySQLdb.connect(host=“localhost”,user=“root”,passwd=“jb51”,db=“test”,charset=“utf8”)
比较常用的参数包括:
host:数据库主机名.默认是用本地主机
user:数据库登陆名.默认是当前用户
passwd:数据库登陆的秘密.默认为空
db:要使用的数据库名.没有默认值
port:MySQL服务使用的TCP端口.默认是3306
charset:数据库编码
更多关于参数的信息可以查这里 http://mysql-python.sourceforge.net/MySQLdb.html
然后,这个连接对象也提供了对事务操作的支持,标准的方法:
commit() 提交
rollback() 回滚
看一个简单的查询示例如下:
代码如下:
#!/usr/bin/python
encoding: utf-8
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“root”,“361way”,“test” )
使用cursor()方法获取操作游标
cursor = db.cursor()
使用execute方法执行SQL语句
cursor.execute(“SELECT VERSION()”)
使用 fetchone() 方法获取一条数据库。
data = cursor.fetchone()
print "Database version : %s " % data
关闭数据库连接
db.close()
脚本执行结果如下:
Database version : 5.5.40
二、cursor方法执行与返回值
cursor方法提供两类操作:1.执行命令,2.接收返回值 。
cursor用来执行命令的方法
代码如下:
//用来执行存储过程,接收的参数为存储过程名和参数列表,返回值为受影响的行数
callproc(self, procname, args)
//执行单条sql语句,接收的参数为sql语句本身和使用的参数列表,返回值为受影响的行数
execute(self, query, args)
//执行单挑sql语句,但是重复执行参数列表里的参数,返回值为受影响的行数
executemany(self, query, args)
//移动到下一个结果集
nextset(self)
cursor用来接收返回值的方法
//接收全部的返回结果行.
fetchall(self)
//接收size条返回结果行.如果size的值大于返回的结果行的数量,则会返回cursor.arraysize条数据
fetchmany(self, size=None)
//返回一条结果行
fetchone(self)
//移动指针到某一行.如果mode=‘relative’,则表示从当前所在行移动value条,如果mode=‘absolute’,则表示从结果集的第一行移动value条
scroll(self, value, mode=‘relative’)
//这是一个只读属性,并返回执行execute()方法后影响的行数
rowcount
三、数据库操作
1、创建database tables 如果数据库连接存在我们可以使用execute()方法来为数据库创建表,如下所示创建表EMPLOYEE:
代码如下:
#!/usr/bin/python
encoding: utf-8
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“root”,“361way”,“test” )
使用cursor()方法获取操作游标
cursor = db.cursor()
如果数据表已经存在使用 execute() 方法删除表。
cursor.execute(“DROP TABLE IF EXISTS EMPLOYEE”)
创建数据表SQL语句
sql = “”“CREATE TABLE EMPLOYEE (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )”“”
cursor.execute(sql)
关闭数据库连接
db.close()
2、数据库插入操作
代码如下:
#!/usr/bin/python
encoding: utf-8
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“root”,“361way”,“test” )
使用cursor()方法获取操作游标
cursor = db.cursor()
SQL 插入语句
sql = “”“INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES (‘Mac’, ‘Mohan’, 20, ‘M’, 2000)”“”
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# Rollback in case there is any error
db.rollback()
关闭数据库连接
db.close()
这里是一个单sql 执行的示例,cursor.executemany的用法感兴趣的读者可以参看相关的aws主机资产管理系统示例。
上例也可以写成通过占位符传参的方式进行执行,如下:
代码如下:
#!/usr/bin/python
encoding: utf-8
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“testuser”,“test123”,“TESTDB” )
使用cursor()方法获取操作游标
cursor = db.cursor()
SQL 插入语句
sql = “INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES (‘%s’, ‘%s’, ‘%d’, ‘%c’, ‘%d’ )” %
(‘Mac’, ‘Mohan’, 20, ‘M’, 2000)
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 发生错误时回滚
db.rollback()
关闭数据库连接
db.close()
也可以以变量的方式传递参数,如下:
代码如下:
…
user_id = “test”
password = “password123”
con.execute(‘insert into Login values(“%s”, “%s”)’ %
(user_id, password))
…
3、数据库查询操作 以查询EMPLOYEE表中salary(工资)字段大于1000的所有数据为例:
代码如下:
#!/usr/bin/python
encoding: utf-8
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“root”,“361way”,“test” )
使用cursor()方法获取操作游标
cursor = db.cursor()
SQL 查询语句
sql = “SELECT * FROM EMPLOYEE
WHERE INCOME > ‘%d’” % (1000)
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
fname = row[0]
lname = row[1]
age = row[2]
sex = row[3]
income = row[4]
# 打印结果
print “fname=%s,lname=%s,age=%d,sex=%s,income=%d” %
(fname, lname, age, sex, income )
except:
print “Error: unable to fecth data”
关闭数据库连接
db.close()
以上脚本执行结果如下:
fname=Mac, lname=Mohan, age=20, sex=M, income=2000
4、数据库更新操作 更新操作用于更新数据表的的数据,以下实例将 test表中的 SEX 字段全部修改为 ‘M’,AGE 字段递增1:
代码如下:
encoding: utf-8
#!/usr/bin/python
import MySQLdb
打开数据库连接
db = MySQLdb.connect(“localhost”,“root”,“361way”,“test” )
使用cursor()方法获取操作游标
cursor = db.cursor()
SQL 更新语句
sql = “UPDATE EMPLOYEE SET AGE = AGE + 1
WHERE SEX = ‘%c’” % (‘M’)
try:
# 执行SQL语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 发生错误时回滚
db.rollback()
关闭数据库连接
db.close()
5、执行事务
事务机制可以确保数据一致性。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
① 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
② 一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
③ 隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
④ 持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
Python DB API 2.0 的事务提供了两个方法 commit 或 rollback。实例:
代码如下:
SQL删除记录语句
sql = “DELETE FROM EMPLOYEE WHERE AGE > ‘%d’” % (20)
try:
# 执行SQL语句
cursor.execute(sql)
# 向数据库提交
db.commit()
except:
# 发生错误时回滚
db.rollback()
对于支持事务的数据库, 在Python数据库编程中,当游标建立之时,就自动开始了一个隐形的数据库事务。commit()方法游标的所有更新操作,rollback()方法回滚当前游标的所有操作。每一个方法都开始了一个新的事务。
【Python中Pyyaml模块的使用】
一、YAML是什么
YAML是专门用来写配置文件的语言,远比JSON格式方便。
YAML语言的设计目标,就是方便人类读写。
YAML是一种比XML和JSON更轻的文件格式,也更简单更强大,它可以通过缩进来表示结构,是不是听起来就和Python很搭?
顾名思义,用语言编写的文件就可以称之为YAML文件。PyYaml是Python的一个专门针对YAML文件操作的模块,使用起来非常简单
安装 pip install pyyaml # 如果是py2,使用 pip install yaml
二、PyYaml的简单使用
使用起来非常简单,就像json、pickle一样,load、dump就足够我们使用了。
load()示例:返回一个对象
import yaml
yaml_str = """
name: 一条大河
age: 1956
job: Singer
"""
y = yaml.load(yaml_str, Loader=yaml.SafeLoader)
print(y)
运行结果:
{'name': '一条大河', 'age': 1956, 'job': 'Singer'}
load_all()示例:生成一个迭代器
如果string或文件包含几块yaml文档,可以使用yaml.load_all来解析全部的文档。
yaml_test.yaml文件内容:
---
name: qiyu
age: 20岁
---
name: qingqing
age: 19岁
操作yaml文件的test.py文件如下:
import yaml
with open("./yaml_test", 'r', encoding='utf-8') as ymlfile:
cfg = yaml.load_all(ymlfile, Loader=yaml.SafeLoader)
for data in cfg:
print(data)
运行结果:
{'name': 'qiyu', 'age': '20岁'}
{'name': 'qingqing', 'age': '19岁'}
dump()示例:将一个python对象生成为yaml文档
import yaml
json_data = {'name': '一条大河',
'age': 1956,
'job': ['Singer','Dancer']}
y = yaml.dump(json_data, default_flow_style=False).encode('utf-8').decode('unicode_escape')
print(y)
运行结果:
age: 1956
job:
- Singer
- Dancer
name: “一条大河”
使用dump()传入参数,可以直接把内容写入到yaml文件:
import yaml
json_data = {'name': '一条大河',
'age': 1956,
'job': ['Singer', 'Dancer']}
with open('./yaml_write.yaml', 'w') as f:
y = yaml.dump(json_data, f)
print(y)
写入内容后的yaml_write.yaml:

yaml.dump_all()示例:将多个段输出到一个文件中
import yaml
obj1 = {"name": "river", "age": 2019}
obj2 = ["Lily", 1956]
obj3 = {"gang": "ben", "age": 1963}
obj4 = ["Zhuqiyu", 1994]
with open('./yaml_write_all.yaml', 'w', encoding='utf-8') as f:
y = yaml.dump([obj1, obj2, obj3, obj4], f)
print(y)
with open('./yaml_write_all.yaml', 'r') as r:
y1 = yaml.load(r, Loader=yaml.SafeLoader)
print(y1)
写入内容后的yaml_write_all.yaml:

为什么写入文件后的格式有的带1个“-”,有的带2个“-”?
为什么yaml文件读出来的的格式是List?
三、YAML的语法规则和数据结构
看完了以上4个简单的示例,现在就来总结下YAML语言的基本语法
****YAML基本语法规则如下:
1、大小写敏感
2、使用缩进表示层级关系
3、缩进时不允许使用Tab键,只允许使用空格。
4、缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
5、# 表示注释,从这个字符一直到行尾,都会被解析器忽略,这个和python的注释一样
6、列表里的项用"-"来代表,字典里的键值对用":"分隔
知道了语法规则,现在来回答下上面的2个问题:
1、带1个“-”表示不同的模块(单个数组或者字典),带2个“-”是因为数组中元素以“-”开始,加上表示不同模块的那一个“-”,呈现出来就是2个“-”
2、因为yaml文件中包含多个模块(多个数组或者字典),读取出来的是这些模块的一个集合
3、有且只有当yaml文件中只有1个字典时,读取出来的数据的类型也是字典
YAML 支持的数据结构有3种:
1、对象:键值对的集合2、数组:一组按次序排列的值,序列(sequence) 或 列表(list)
3、纯量(scalars):单个的、不可再分的值,如:字符串、布尔值、整数、浮点数、Null、时间、日期
支持数据示例:
yaml_test_data.yaml的内容:
str: "Big River" #字符串
int: 1548 #整数
float: 3.14 #浮点数
boolean: true #布尔值
None: null # 也可以用 ~ 号来表示 null
time: '2019-11-20T08:47:46.576701+00:00' # 时间,ISO8601
date: 2019-11-20 16:47:46.576702 # 日期
操作代码:
import yaml
import datetime
import pytz
yaml_data = {
"str": "Big River",
"int": 1548,
"float": 3.14,
'boolean': True,
"None": None,
'time': datetime.datetime.now(tz=pytz.timezone('UTC')).isoformat(),
'date': datetime.datetime.today()
}
with open('./yaml_test', 'w') as f:
y = yaml.dump(yaml_data, f)
print(y)
with open('./yaml_test', 'r') as r:
y1 = yaml.load(r, Loader=yaml.SafeLoader)
print(y1)
控制台输出:

其他语法规则
1、如果字符串没有空格或特殊字符,不需要加引号,但如果其中有空格或特殊字符,就需要加引号了

2、引用
& 和 * 用于引用
name: &name SKP
tester: *name
运行结果:
{'name': 'SKP', 'tester': 'SKP'}
3、强制转换
用 !! 实现
str: !!str 3.14
int: !!int "123"
运行结果:
{'int': 123, 'str': '3.14'}
4、分段
在同一个yaml文件中,可以用“—”3个“-”来分段,这样可以将多个文档写在一个文件中
举例见上述load_all()示例
**四、**python对象生成yaml文档
1、yaml.dump()方法
import yaml
import os
def generate_yaml_doc(yaml_file):
py_object = {'school': 'zhu',
'students': ['a', 'b']}
file = open(yaml_file, 'w', encoding='utf-8')
yaml.dump(py_object, file)
file.close()
current_path = os.path.abspath(".")
yaml_path = os.path.join(current_path, "generate.yaml")
generate_yaml_doc(yaml_path)
"""结果
school: zhu
students:
- a
- b
"""
2、使用ruamel模块中的yaml方法生成标准的yaml文档
import os
from ruamel import yaml # pip3 install ruamel.yaml
def generate_yaml_doc_ruamel(yaml_file):
py_object = {'school': 'zhu',
'students': ['a', 'b']}
file = open(yaml_file, 'w', encoding='utf-8')
yaml.dump(py_object, file, Dumper=yaml.RoundTripDumper)
file.close()
current_path = os.path.abspath(".")
yaml_path = os.path.join(current_path, "generate.yaml")
generate_yaml_doc_ruamel(yaml_path)
"""结果
school: zhu
students:
- a
- b
"""
使用ruamel模块中的yaml方法读取yaml文档(用法与单独import yaml模块一致)
import os
from ruamel import yaml
def get_yaml_data_ruamel(yaml_file):
file = open(yaml_file, 'r', encoding='utf-8')
data = yaml.load(file, Loader=yaml.Loader)
file.close()
print(data)
current_path = os.path.abspath(".")
yaml_path = os.path.join(current_path, "generate.yaml")
get_yaml_data_ruamel(yaml_path)
【Python操作excel的几种方式–xlrd、xlwt、openpyxl】
xlrd
xlrd是用来从Excel中读写数据的,但我平常只用它进行读操作,写操作会遇到些问题。用xlrd进行读取比较方便,流程和平常手动操作Excel一样,打开工作簿(Workbook),选择工作表(sheets),然后操作单元格(cell)。下面举个例子,例如要打开当前目录下名为”data.xlsx”的Excel文件,选择第一张工作表,然后读取第一行的全部内容并打印出来。Python代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
#打开excel文件
data=xlrd.open_workbook('data.xlsx')
#获取第一张工作表(通过索引的方式)
table=data.sheets()[0]
#data_list用来存放数据
data_list=[]
#将table中第一行的数据读取并添加到data_list中
data_list.extend(table.row_values(0))
#打印出第一行的全部数据
for item in data_list:
print item
|
上面的代码中读取一行用table.row_values(number),类似的读取一列用table.column_values(number),其中number为行索引,在xlrd中行和列都是从0开始索引的,因此Excel中最左上角的单元格A1是第0行第0列。
xlrd中读取某个单元格用table.cell(row,col)即可,其中row和col分别是单元格对应的行和列。
下面简单归纳一下xlrd的用法
xlrd用法总结
- 打开Excel工作簿
1
|
data=xlrd.open_workbook(filename)
|
- 查看工作簿中所有sheet的名称
1
|
data.sheet_names()
|
- 选择某一个工作表(通过索引或表名称)
1
2
3
4
5
6
7
8
|
#获取第一个工作表
table=data.sheets()[0]
#通过索引获取第一个工作表
table=data.sheet_by_index(0)
#通过表名称选择工作表
table=data.sheet_by_name(u'哈哈')
|
- 获取表格的行数和列数
1
2
|
nrows=table.nrows
ncols=table.ncols
|
- 获取整行和整列的值
1
2
|
table.row_values(number)
table.column_values(number)
|
- 通过循环读取表格的所有行
1
2
|
for rownum in xrange(table.nrows):
print table.row_values(rownum)
|
- 获取单元格的值
1
2
3
4
5
|
cell_A1=table.row(0)[0].value
#或者像下面这样
cell_A1=table.cell(0,0).value
#或者像下面这样通过列索引
cell_A1=table.col(0)[0].value
|
写操作自己很少用,所以就不归纳了。
xlwt
如果说xlrd不是一个单纯的Reader(如果把xlrd中的后两个字符看成Reader,那么xlwt后两个字符类似看成Writer),那么xlwt就是一个纯粹的Writer了,因为它只能对Excel进行写操作。xlwt和xlrd不光名字像,连很多函数和操作格式也是完全相同。下面简要归纳一下常用操作。
xlwt常用操作
新建一个Excel文件(只能通过新建写入)
1
|
data=xlwt.Workbook()
|
新建一个工作表
1
|
table=data.add_sheet('name')
|
写入数据到A1单元格
1
|
table.write(0,0,u'呵呵')
|
注意:如果对同一个单元格重复操作,会引发overwrite Exception,想要取消该功能,需要在添加工作表时指定为可覆盖,像下面这样
1
|
table=data.add_sheet('name',cell_overwrite_ok=True)
|
保存文件
1
|
data.save('test.xls')
|
这里只能保存扩展名为xls的,xlsx的格式不支持
xlwt支持一定的样式,操作如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#初始化样式
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
num)
|
- 获取单元格的值
1
2
3
4
5
|
cell_A1=table.row(0)[0].value
#或者像下面这样
cell_A1=table.cell(0,0).value
#或者像下面这样通过列索引
cell_A1=table.col(0)[0].value
|
写操作自己很少用,所以就不归纳了。
xlwt
如果说xlrd不是一个单纯的Reader(如果把xlrd中的后两个字符看成Reader,那么xlwt后两个字符类似看成Writer),那么xlwt就是一个纯粹的Writer了,因为它只能对Excel进行写操作。xlwt和xlrd不光名字像,连很多函数和操作格式也是完全相同。下面简要归纳一下常用操作。
xlwt常用操作
新建一个Excel文件(只能通过新建写入)
1
|
data=xlwt.Workbook()
|
新建一个工作表
1
|
table=data.add_sheet('name')
|
写入数据到A1单元格
1
|
table.write(0,0,u'呵呵')
|
注意:如果对同一个单元格重复操作,会引发overwrite Exception,想要取消该功能,需要在添加工作表时指定为可覆盖,像下面这样
1
|
table=data.add_sheet('name',cell_overwrite_ok=True)
|
保存文件
1
|
data.save('test.xls')
|
这里只能保存扩展名为xls的,xlsx的格式不支持
xlwt支持一定的样式,操作如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#初始化样式
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)**
[外链图片转存中...(img-xBPftvJv-1713708634094)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









