







空格的使用
- 使用空格来表示缩进而不要用制表符(Tab)。
- 和语法相关的每一层缩进都用4个空格来表示。
- 每行的字符数不要超过79个字符,如果表达式因太长而占据了多行,除了首行之外的其余各行都应该在正常的缩进宽度上再加上4个空格。
- 函数和类的定义,代码前后都要用两个空行进行分隔。
- 在同一个类中,各个方法之间应该用一个空行进行分隔。
- 二元运算符的左右两侧应该保留一个空格,而且只要一个空格就好。
标识符命名
- 变量、函数和属性应该使用小写字母来拼写,如果有多个单词就使用下划线进行连接。
- 类中受保护的实例属性,应该以一个下划线开头。
- 类中私有的实例属性,应该以两个下划线开头。
- 类和异常的命名,应该每个单词首字母大写。
- 模块级别的常量,应该采用全大写字母,如果有多个单词就用下划线进行连接。
- 类的实例方法,应该把第一个参数命名为self以表示对象自身。
- 类的类方法,应该把第一个参数命名为cls以表示该类自身。
表达式和语句
- 采用内联形式的否定词,而不要把否定词放在整个表达式的前面。例如:if a is not b就比if not a is b更容易让人理解。
- 不要用检查长度的方式来判断字符串、列表等是否为None或者没有元素,应该用if not x这样的写法来检查它。
- 就算if分支、for循环、except异常捕获等中只有一行代码,也不要将代码和if、for、except等写在一起,分开写才会让代码更清晰。
- import语句总是放在文件开头的地方。
- 引入模块的时候,from math import sqrt比import math更好。
- 如果有多个import语句,应该将其分为三部分,从上到下分别是Python标准模块、第三方模块和自定义模块,每个部分内部应该按照模块名称的字母表顺序来排列。
题目43:运行下面的代码是否会报错,如果报错请说明哪里有什么样的错,如果不报错请说出代码的执行结果。
class A:
def __init__(self, value):
self.__value = value
@property
def value(self):
return self.__value
obj = A(1)
obj.__value = 2
print(obj.value)
print(obj.__value)
点评:这道题有两个考察点,一个考察点是对_和__开头的对象属性访问权限以及@property装饰器的了解,另外一个考察的点是对动态语言的理解,不需要过多的解释。
1
2
扩展:如果不希望代码运行时动态的给对象添加新属性,可以在定义类时使用__slots__魔法。例如,我们可以在上面的A中添加一行__slots__ = (‘__value’, ),再次运行上面的代码,将会在原来的第10行处产生AttributeError错误。
题目44:对下面给出的字典按值从大到小对键进行排序。
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
点评:sorted函数的高阶用法在面试的时候经常出现,key参数可以传入一个函数名或一个Lambda函数,该函数的返回值代表了在排序时比较元素的依据。
sorted(prices, key=lambda x: prices[x], reverse=True)
题目45:说一下namedtuple的用法和作用。
点评:Python标准库的collections模块提供了很多有用的数据结构,这些内容并不是每个开发者都清楚,就比如题目问到的namedtuple,在我参加过的面试中,90%的面试者都不能准确的说出它的作用和应用场景。此外,deque也是一个非常有用但又经常被忽视的类,还有Counter、OrderedDict 、defaultdict 、UserDict等类,大家清楚它们的用法吗?
在使用面向对象编程语言的时候,定义类是最常见的一件事情,有的时候,我们会用到只有属性没有方法的类,这种类的对象通常只用于组织数据,并不能接收消息,所以我们把这种类称为数据类或者退化的类,就像C语言中的结构体那样。我们并不建议使用这种退化的类,在Python中可以用namedtuple(命名元组)来替代这种类。
from collections import namedtuple
Card = namedtuple('Card', ('suite', 'face'))
card1 = Card('红桃', 13)
card2 = Card('草花', 5)
print(f'{card1.suite}{card1.face}')
print(f'{card2.suite}{card2.face}')
命名元组与普通元组一样是不可变容器,一旦将数据存储在namedtuple的顶层属性中,数据就不能再修改了,也就意味着对象上的所有属性都遵循“一次写入,多次读取”的原则。和普通元组不同的是,命名元组中的数据有访问名称,可以通过名称而不是索引来获取保存的数据,不仅在操作上更加简单,代码的可读性也会更好。
学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
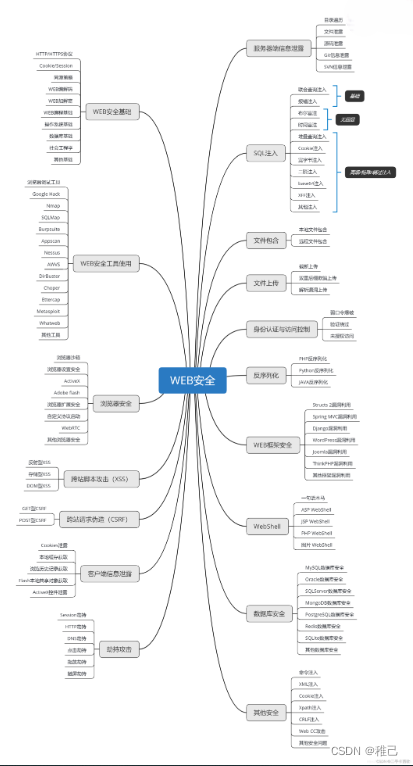
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









