







计算机辅助病理学分析显微组织病理学图像以诊断越来越多的乳腺癌患者,可以降低诊断成本和延迟。组织病理学中的深度学习在过去十年中因其在分类和定位任务中实现最先进的性能而引起了人们的关注。卷积神经网络是一种深度学习框架,在组织图像分析方面提供了显着的结果,但缺乏提供决策背后的解释和推理。
我们的目标是通过提供显微组织病理学图像的定位来更好地解释分类结果。将图像分类问题定义为弱监督多实例学习问题,其中图像是补丁的集合,即实例。
基于注意力的多实例学习 (A-MIL) 从图像中学习对补丁的注意力,以定位图像中的恶性和正常区域,并使用它们对图像进行分类。展示了两个公开可用的 BreakHis 和 BACH 数据集的分类和本地化结果。
1. 介绍
乳腺癌是女性最主要的死亡原因,病理学家根据病理切片中观察到的各种视觉特征(例如细胞核的形态特征、细胞核的微观和宏观结构等)做出决定。计算机辅助诊断(CAD)系统可以帮助病理学家自动做出决策。
卷积神经网络是最广泛使用的深度学习框架,用于学习图像类别之间的复杂判别特征。多年来,VGG16 [3] 和 ResNet18 [4] 等各种 CNN 架构在海量 ImageNet 数据集上产生了出色的结果。 CNN 被用于医学图像以产生最先进的结果。Grad-CAM [6] 为图像中存在的所有类别提供了定位信息。所有这些技术都跟踪在卷积神经网络(CNNs)反向传播过程中的梯度流动,以在输入图像中产生定位,结果是对代表一个类别的最显著特征进行定位。
深度神经网络经常因其缺乏可解释性而受到批评。在大多数应用中,神经网络充当黑盒特征提取单元。在医学图像分析等应用中,缺乏可解释性更为严重。
深度神经网络的可解释性主要指的是一种能够解释和理解模型内部决策过程的能力。
CNN 特征的可视化是一个活跃的研究领域,引导反向传播 、反卷积 和 CAM 相关方法等技术提出了输入图像中预测类别的定位。所有这些技术都跟踪 CNN 反向传播中流动的梯度,以在输入图像中产生定位,从而实现对代表类别的最突出特征的定位。
在CNN(卷积神经网络)中,CAM(Class Activation Mapping)类别激活映射方法是一种可视化技术,用于解释模型在进行图像分类时是如何依赖输入图像中的特定区域的。CAM方法将CNN在分类时使用的分类依据(即图像中对应的类别特征)在原图的位置进行可视化,并绘制成热图,以此作为物体定位的依据。
CAM方法的核心思想是利用全局平均池化(GAP)替代全连接层,以使卷积网络的定位能力能够延续到网络的最后一层。
基于梯度的定位技术不会在组织病理学图像上产生良好的结果,因为特征分布在图像的大部分区域。使用基于注意力的多实例学习来更好地定位乳腺组织病理学图像中的恶性区域。我们通过将单个标签分配给输入图像的多个块来将图像分类问题构建为弱监督学习问题。
基于注意力的多实例学习(A-MIL)
将图像的多个实例(补丁)制作一个包,并使用基于注意力的多实例学习(A-MIL)进行分类。
在 A-MIL 中,实例池为每个实例分配一个学习权重,以将特征聚合到一个包中。这些学习权重可用于本地化,因为每个权重表示特定补丁对于分类任务的重要性。将这些权重叠加在输入图像上以显示我们的定位结果。
与广泛使用的 CNN 架构(例如 ResNet18 和 VGG16)相比,A-MIL 产生相似的分类结果。与 Grad-CAM 相比,A-MIL 在本地化任务中表现更好,且不影响分类任务的准确性。
2. 相关工作
CAD 中的传统方法涉及基于原子核及其微环境的纹理和外观的特征提取。这些特征包括核的周长、致密性、光滑度、偏心率、坚固性、当量直径、范围、长轴长度和短轴长度以及周围区域的纹理特征。这些特征被输入到模糊 Cmeans、高斯混合模型、SVM、MLP 和聚类算法等分析方法中,以确定组织病理学实体(如细胞核或斑块)的类别。
尽管使用深度学习算法对组织病理学图像进行分类已经得到了广泛的研究,但在组织病理学数据集上的可视化或定位方面所做的工作却非常少。基于梯度的方法,例如引导反向传播[5]、反卷积[5]、Grad-CAM [6],在自然图像上提供了良好的可视化,但由于尺寸大、疾病状态变化的挑战,无法在组织病理学图像上提供合理的定位,以及载玻片制备过程中人为引起的错误。
使用基于注意力的多实例学习方法对组织病理学图像中相关区域进行分类和定位
3. 数据集
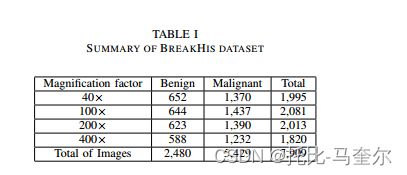
公开的数据集 BreakHis [1] 和 BACH [12] 进行分析。 BreakHis 数据集包含 7909 张四种不同放大级别的图像,分为两大类:良性和恶性。 BreakHis 数据集中的每个图像的大小为 700×460。我们在每个放大倍数下将数据集分为 80% 用于训练,20% 用于验证,以执行实验。
第二个数据集是ICIAR 2018乳腺癌组织学图像大赛(BACH)中使用的数据集。BACH 数据集包含 400 张乳腺癌组织病理学图像。该数据集的每张图像都是三个通道,大小为 2048 × 1536 像素。BACH 数据集包含四个类别,即:正常、良性、原位和侵入性。我们将正常类和良性类合并起来,形成二元分类问题的一个类,而另一类则通过将原位类和侵入类合并在一起形成。
多实例学习
多实例学习(MIL)为弱监督学习问题提供了解决方案。
在 MIL 中,任务是预测由多个实例组成的包的分类标签。
如果,其中
是数据集
中的包,一个包包含 m 个实例。
,其中
是包
中具有二分类标签
的第
个实例。如果包
中至少有一个实例
为正,则称包
为正。
多实例学习(MIL)最关键的部分是实例级池化。实例级池化聚合实例级特征以获得包级特征。 MIL 中最流行的实例池化操作是平均池和最大池。平均池操作对所有实例进行平均以预测包标签,而最大池操作将最大激活的实例标签作为包标签。
实例级特征 通过加权平均值进行池化。加权平均池的系数是使用具有 softmax 激活的两层神经网络来学习的。
注意力计算的表达式为:,
,
。
是实例级特征的数量,
是网络学习到的注意力权重。
包准备
将 BreakHis 数据集中的每个三通道 700 × 460 图像划分为 28 × 28 个补丁,步长为 28。这导致每个图像有 400 个补丁,我们将其用作单个包中的实例。在 BACH 数据集中,我们从 2408 × 1536 的原始图像中提取了 124 × 124 的补丁,每个图像有 192 个补丁。
A-MIL(基于注意力的多实例学习)框架
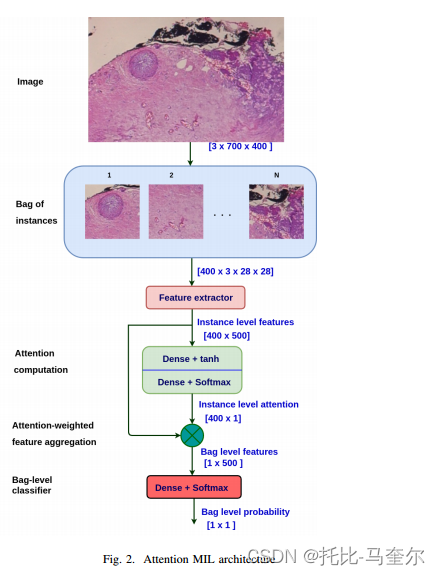
包中的每个补丁都通过特征提取器进行处理,以获得实例级特征。密集层从每个实例中提取 500 个特征。注意力计算块使用每个实例的 500 个特征来计算注意力分数。这些注意力权重进一步用于注意力聚合以获得包级特征。A-MIL 允许包中的不同实例有不同的权重。注意力聚合计算使得包对于包级分类器来说具有很高的信息量。
4. 实验与结果
训练一个 VGG16 网络,该网络使用 ImageNet 训练过的权重进行初始化。对于 VGG16 的训练,我们随机选取大小为 224 × 224 的 patch 进行训练。我们使用相同的策略来训练 ResNet18 模型。由于 VGG16 和 ResNet18 中的可调参数数量很大,因此使用大量数据增强来训练这些网络。
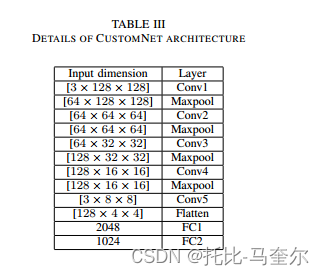
训练了一个参数较少的自定义神经网络。此定制卷积神经网络包含五个卷积层,后面是两个全连接 (FC) 层。
Grad-CAM 只能检测输入图像中的边缘,而 A-MIL 可以产生更好的可视化效果。 A-MIL 准确定位恶性腺体并忽略背景。在 BACH 数据集上重复了相同的实验以进行二类分类和定位。我们使用大小为 124 × 124 的非重叠块从单个图像形成一个包。一个包包含此实验的 192 个实例。

5. 文章总结
首先把图像裁剪为小块的正方形图像块,然后创建了一个包含这些图像块的包。这个图像包作为一个批次来使用。接下来,使用AMIL架构(基于注意力的多实例学习架构)来处理这些图像。
首先,我们从输入图像中提取小块图像,形成一个图像包。
然后,我们将这个图像包传递给特征提取器,这个特征提取器基本上是一个卷积神经网络块。
接着,我们将实例级别的特征传递给分类器,以获取实例级别的注意力权重。
首先,通过特征提取器从输入数据中提取特征,生成一个特征向量。然后,将特征向量传递给注意力模块。注意力模块根据特征向量计算每个实例的注意力分数。计算得到的注意力分数通过某种方式进行归一化,从而作为权重使用。归一后的注意力分数就是注意力权重。
得到了注意力权重之后,这些权重将进一步用于注意力聚合,以获取包级别的特征。
用于可视化深度学习模型决策过程的方法
在处理医学图像(如良性、恶性或侵袭性的分类)时,除了提取特征和计算注意力权重外,还会应用一个密集层(也称为全连接层)来进行最终的分类。这个密集层会接收经过处理的特征作为输入,并输出每个类别的预测概率。
图像补丁和注意力权重的处理
- 首先,从输入图像中提取出多个小区域或补丁(patches)。每个补丁都包含图像的一部分信息。
- 接着,为每个补丁计算注意力权重。这些权重反映了模型在做出决策时对每个补丁的重视程度。
- 为了获得整个输入图像的可视化,每个补丁都与其对应的注意力权重相乘。这强调了模型认为重要的图像区域。
- 最后,将所有加权后的补丁拼接起来,形成一幅完整的可视化图像。这幅图像展示了模型在做出分类决策时主要关注的图像部分。
GradCAM和AMIL方法的比较
GradCAM是一种常用的可视化技术,它通过高亮图像中对分类决策贡献最大的区域来工作。但在某些情况下,如医学图像分析,GradCAM可能无法准确地突出显示关键区域。
AMIL(基于注意力的多实例学习)方法能够更好地突出显示对分类决策有用的图像部分。使用这种方法,既不会损害模型的准确性,也不会使模型变得过于复杂。
GradCAM (梯度加权类激活映射)
用于解释卷积神经网络(CNN)决策的可视化技术。GradCAM 通过高亮图像中对于特定类别输出贡献最大的区域,帮助用户理解模型是如何做出决策的。这种方法基于梯度的全局平均池化,来生成一个热图(heatmap),该热图展示了每个像素对模型最终决策的贡献程度。通过查看这些热图,用户可以直观地理解模型在做出分类决策时关注图像中的哪些部分。
因为医学图像的复杂性和特异性,使得简单的可视化方法GradCAM可能无法准确捕捉模型决策的关键部分。

















 5034
5034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









