







写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
sklearn是基于Python的机器学习工具包,自带大量数据集,可供我们练习各种机器学习算法。
二、安装sklearn
环境要求:
- Python(>=2.7 or >=3.3)
- NumPy (>= 1.8.2)
- SciPy (>= 0.13.3)
先安装 numpy、scipy,再安装 scikit-learn
PyCharm左上角【file】-【Settings】-【Project:pythonProject】-【Python Interpreter】
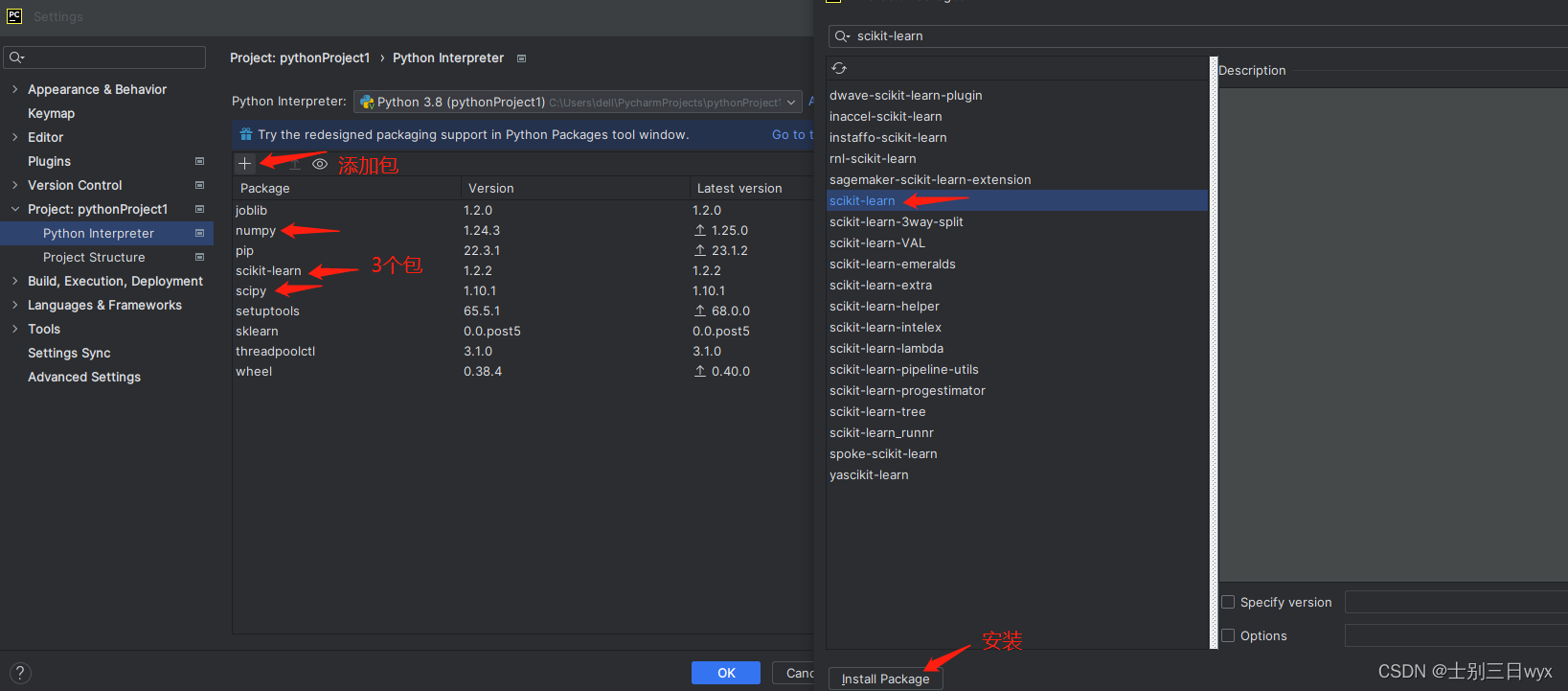
二、获取数据集
sklearn数据集有有三种「获取数据」的方式:
- sklearn.datasets.load_*():小规模数据集(本地加载)
- sklearn.datasets.fetch_*():大规模数据集(在线下载)
- sklearn.datasets.make_*():本地生成数据集(本地构造)
sklearn数据集的「返回值」是字典格式:
- data:特征值数据数组
- target:目标值数据数组(标签)
- target_names:标签名(目标值和标签的对应关系)
- DESCR:数据描述
- feature_names:特征名
接下来,我们获取一个自带的本地数据集:
from sklearn import datasets
# 获取数据集
iris = datasets.load_iris()
# 打印数据集
print(iris)
输出:
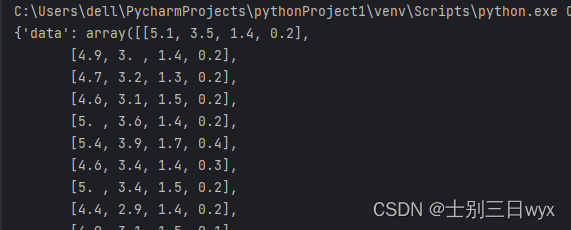
从输出结果来看,它返回的数据集是一个字典,里面包含了特征值(data)、目标值(target)等信息。
我们可以调用返回值「属性」,单独查看数据集的某个信息:
from sklearn import datasets
# 获取数据集
iris = datasets.load_iris()
# 查看数据值
print(iris.data)
# 查看目标值(标签)
print(iris.target)
# 查看标签名
print(iris.target_names)
# 查看数据描述
print(iris.DESCR)
# 查看特征名
print(iris.feature_names)
三、数据集划分
数据集通常会划分为两个部分:
- 「训练数据」:用于训练,生成模型。
- 「测试数据」:用于检验,判断模型是否有效。
sklearn.model_selection.train_test_split() 用来划分数据集
参数:
- x:(必选)数组类型,数据集的特征值
- y:(必选)数组类型,数据集的目标值
- test_size:(可选,默认0.25)浮点型,测试集的大小
- random_state:(可选)整型,随机数种子,不同的随机数对应不同的采样结果。
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 4133
4133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









