







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
23279:S 11 Apr 10:24:20.224 * Connecting to MASTER 127.0.0.1:6379
23279:S 11 Apr 10:24:20.224 * MASTER <-> SLAVE sync started
23279:S 11 Apr 10:24:20.224 * Non blocking connect for SYNC fired the event.
23279:S 11 Apr 10:24:20.224 * Master replied to PING, replication can continue...
23279:S 11 Apr 10:24:20.224 * Trying a partial resynchronization (request 18b61ced5990337dd8377e8bf81fcd2b20e7d399:1).
23279:S 11 Apr 10:24:20.226 * Full resync from master: f1d39130cfadf4b3e0eb192e4143ae6bcb01677b:0
23279:S 11 Apr 10:24:20.226 * Discarding previously cached master state.
23279:S 11 Apr 10:24:20.315 * MASTER <-> SLAVE sync: receiving 176 bytes from master
23279:S 11 Apr 10:24:20.315 * MASTER <-> SLAVE sync: Flushing old data
23279:S 11 Apr 10:24:20.315 * MASTER <-> SLAVE sync: Loading DB in memory
23279:S 11 Apr 10:24:20.316 * MASTER <-> SLAVE sync: Finished with success
23279:S 11 Apr 10:24:20.316 * Background append only file rewriting started by pid 23340
23279:S 11 Apr 10:24:20.356 * AOF rewrite child asks to stop sending diffs.
23340:C 11 Apr 10:24:20.356 * Parent agreed to stop sending diffs. Finalizing AOF...
23340:C 11 Apr 10:24:20.356 * Concatenating 0.00 MB of AOF diff received from parent.
23340:C 11 Apr 10:24:20.356 * SYNC append only file rewrite performed
23340:C 11 Apr 10:24:20.357 * AOF rewrite: 6 MB of memory used by copy-on-write
23279:S 11 Apr 10:24:20.426 * Background AOF rewrite terminated with success
23279:S 11 Apr 10:24:20.426 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
23279:S 11 Apr 10:24:20.426 * Background AOF rewrite finished successfully
- 当master宕机后slave会一直尝试连接Master,日志信息如下:
29511:S 11 Apr 10:37:37.567 # Error condition on socket for SYNC: Connection refused
29511:S 11 Apr 10:37:38.577 * Connecting to MASTER 127.0.0.1:6379
29511:S 11 Apr 10:37:38.577 * MASTER <-> SLAVE sync started
29511:S 11 Apr 10:37:38.577 # Error condition on socket for SYNC: Connection refused
29511:S 11 Apr 10:37:39.587 * Connecting to MASTER 127.0.0.1:6379
29511:S 11 Apr 10:37:39.587 * MASTER <-> SLAVE sync started
29511:S 11 Apr 10:37:39.587 # Error condition on socket for SYNC: Connection refused
29511:S 11 Apr 10:37:40.597 * Connecting to MASTER 127.0.0.1:6379
29511:S 11 Apr 10:37:40.597 * MASTER <-> SLAVE sync started
29511:S 11 Apr 10:37:40.597 # Error condition on socket for SYNC: Connection refused
29511:S 11 Apr 10:37:41.606 * Connecting to MASTER 127.0.0.1:6379
slave端口与master的连接(断开与master连接后,slave不再接收master的同步数据):
slaveof no one
1.2.2 数据同步阶段
1.2.2.1 工作流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wZ0lwAAh-1586788518676)(media/33.png)]](https://img-blog.csdnimg.cn/20200413223700340.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JiMTUwNzAwNDc3NDg=,size_16,color_FFFFFF,t_70#pic_center)
在master与slave建立连接成功后,开始数据同步。
1)slave发送psync2(psync1、sync)指令给master,需要同步时数据
2)master接到指令后开始执行bgsave指令,并创建复制积压缓冲区,在此期间,master接收到任何来自客户端的"写"操作都会记录在复制积压缓冲区一份。
3)master将rdb通过前面创建的socket通道发送给slave
4)slave接收到rdb文件后,清空当前机器的所有数据,开始同步rdb中的数据
5)告知master文件以及恢复完毕
6)master将复制积压缓冲区中的指令发送给slave
7)slave将接收到的指令执行bgrewriteaof重写,之后进行数据恢复
步骤1-4属于全量同步
步骤5-7属于增量同步
1.2.2.2 增量同步原理
从上图可以看出,在master执行bgsave期间接收到的所有命令都会存放在复制积压缓冲区一份,而复制积压缓冲区的大小是有限度的,默认是1MB,如果缓冲区已经满了,则会把最前面的数据挤出去(删除),后期进行增量同步时发现数据不一致,则会进行全量同步,从而造成同步死循环,因此复制积压缓冲区不易设置为太小。
- 查看复制积压缓冲区:
127.0.0.1:6379> config get repl-backlog-size
1) "repl-backlog-size"
2) "1048576"
127.0.0.1:6379>
- 调整复制积压缓冲区大小:
repl-backlog-size 2096576
1.2.3 命令传播阶段
master与slave保持连接后,此后master接到来自客户端"写"的命令之后,需要将数据同步各个slave端,此阶段叫命令传播阶段。
1.2.3.1 偏移量(offset)
在数据同步中,master与slave之间分别维护着一个offset偏移量,用于存储增量同步时主节点发送给从节点数据的位置,这样利于在网络抖动情况下,主从节点之间还可以继续接着上一次同步的位置进行同步,而不必要进行全量同步。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0atRTF9f-1586788518676)(media/34.png)]](https://img-blog.csdnimg.cn/20200413223641363.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JiMTUwNzAwNDc3NDg=,size_16,color_FFFFFF,t_70#pic_center)
假设在命令传播时,master在传输到"4"这个字节时出现网络抖动,那么master与slave都会将此offset的值(7)保存起来,下次同步数据时,slave带着此offset来到master继续增量同步数据,而不需要重新全量同步数据。
1.2.3.2 运行id(runid)
在上一小结说了master与slave之间都维护着一个offset偏移量,让我们可以根据offset的偏移量进行增量同步,避免网络抖动情况下进行全量同步。
但是如果在同步的过程中切换了master节点则会出现问题,因为新的master节点并没有维护着offset偏移量,并且slave中的数据应该与新master节点数据保持一致。那么redis是如何做到的呢?
其实在master与slave服务器启动时都保存有一个由40位随机的16进制字符串组成的运行id(runid),用于标识一台唯一的redis,每次启动都不一样。在info的server组下可以查看到
info server
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sBxbPWFo-1586788518676)(media/35.png)]](https://img-blog.csdnimg.cn/20200413223719896.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JiMTUwNzAwNDc3NDg=,size_16,color_FFFFFF,t_70#pic_center)
在slave首次连接master时,master会将自己的runid发送给slave,slave会将此runid保存下来,当出现网络抖动时,slave会将此runid发送给master,master根据此runid判断进行全量同步还是增量同步。
- runid与现在master的runid一致:说明网络是同一个master节点,增量同步条件满足(具体是否执行还需要看复制积压缓冲区与偏移量)。
- runid与现在master的runid不一致:说明是新的master节点,进行全量同步。
1.2.3.3 复制积压缓冲区
复制积压缓冲区(replication backlog buffer):复制积压缓冲区是master节点创建的一个先进先出的队列,默认大小为1MB,用于备份主节点的传播命令,所有的slave共享一个复制积压缓冲区。
slave将offset发送给master之后,master会根据当前的offset值来决定是全量同步还是增量同步。
- 如果offset偏移量之后的数据仍在缓冲区中(意味着在执行bgsave时,缓冲区还未满),则执行部分同步
- 如果offset偏移量之后的数据不再缓冲区中(意味着在执行bgsave时间过长,缓冲区的数据已经被挤出),此时执行全量同步
完整同步过程如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K5zCXPR9-1586788518677)(media/37.png)]](https://img-blog.csdnimg.cn/202004132237414.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JiMTUwNzAwNDc3NDg=,size_16,color_FFFFFF,t_70#pic_center)
1.2.3.4 心跳机制
在命令传播阶段,master与slave之间通过心跳机制来保证master与slave双方正常连接在线。
- master定时向slave发送ping,查看对方是否在线,通过
repl-ping-slave-period参数维护,默认10s
127.0.0.1:6379> config get repl-ping-slave-period
1) "repl-ping-slave-period"
2) "10"
127.0.0.1:6379>
-
slave定时向master发送
replcconf ack命令,频率为每秒发送一次。-
作用1):用于检测slave与master的连接状态,可以在master端使用info命令查看replication组的lag值,代表上一次接收到此slave的
replcconf ack命令间隔。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2Q05giJj-1586788518677)(media/38.png)]](https://img-blog.csdnimg.cn/2020041322375794.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JiMTUwNzAwNDc3NDg=,size_16,color_FFFFFF,t_70#pic_center)
-
作用2):slave发送当前的offset来到master与之对比,如果出现网络丢包情况下那么slave与master之间的offset不一致,此时可以进行数据的部分恢复。
-
slave每次发送replcconf ack命令给master,master用于确认有多少个slave与之连接,并且还可以确定多个slave与master上一次发送心跳的时间(lag),如果slave长时间未发送心跳来到master,可以先将master暂停写的操作。
- min-slaves-to-write:当前master的slave数量小于此值则暂停写操作
min-slaves-to-write 5
## 学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
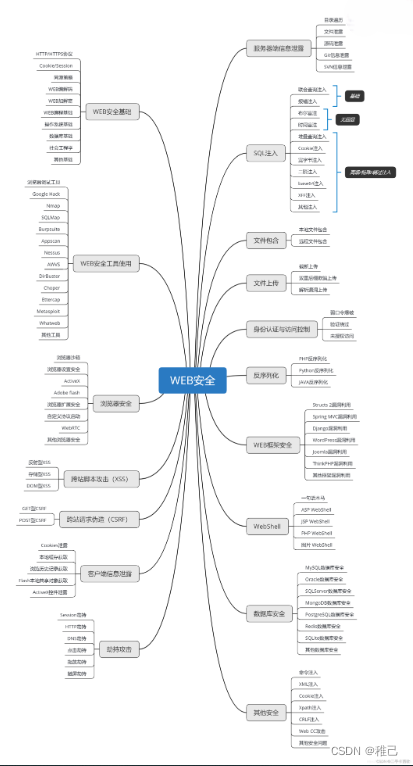
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









