






大部分AI的训练集都以cos照和美宣图为主,这类图片本身就缺乏真实感(或者说突出理想化),因此AI出图也多会继承不真实的感觉。但这只是表面现象,探讨其深层次的原因,主要有两点:
- 假人想骗过真人本身就是非常困难的事
- AI学习的是相关概率,而非因果
先说第二点吧,图片生成AI在训练中学到的内容不是“因为穿着丝袜所以勒肉”,而是“这个白色的部分和这个粉粉的部分经常一起出现”。
(这话不绝对,我虽然搞程序但不是AI方向,肯定也没看过所有AI的实现,可能哪个图像生成AI就内嵌了什么逻辑系统或有向图还BP到生成里(等等BP实现不了识别并调整,多少得是个GAN呀),但就我所知目前主流的都没这么变态)
结果就是尽管AI最终图片第一眼看起来很好,仔细瞅就会发现各个部分都有逻辑问题。
以这张AI图为例:

这可能是我见过得AI图里质量最高的一个了(除了图片质量外,还有这个指猫女人的人物动态)…… 但还是有大量的问题。
先对红发美女下手:

除了异色虹膜,她的右眼虹膜还发散了,瞳孔不是圆的,眼皮出现了围着虹膜的弯曲:

除了嘴歪,前额突出,三角区右移,philtrum和鼻子连接的部分断了,似乎有deviated septum症,下巴也不对称。

这些地方正常人大概说不出来,但并不代表看不见,潜意识里的人类识别器在看到这些东西的时候已经开始报错了。
(当然,这也比正常人骏多了,我要是找对象也能这个颜值我绝不会说啥)
其余部分的人体也有问题,比如肩膀:
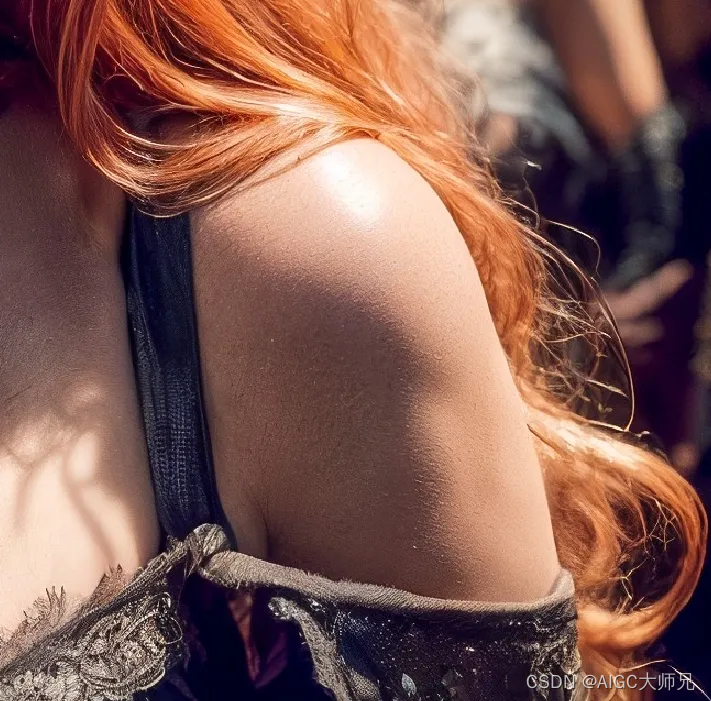
deltoid的部分出现了一个肿块。
趁着有这个图再指出下:这个图比其他AI好的一个地方就是皮肤不是完全光滑的,有纹理。但仔细一看,这个纹理却既不是汗毛也不是毛孔,这也是潜意识中报错的一个原因。
对比底层肌肉:

这个问题在金发妹身上更明显:

除了一样的deltoid肿块,金发妹的腋下还出现了双重褶子?

这个表现显然是有迹可循的,在穿相对紧身的衣物时很容易勒出副乳,但这个体型勒出两层实在闻所未闻。
类似的还有肩带:

在向上到肩膀前变成了一个细线:

这个变化来自吊带经过锁骨时的变化,我擦掉了AI的带,重新画了个:

AI学到了黑条经常和旁边一个曲线一起出现,但不知道这个曲线是黑条的投影。第一眼看可能发现不了,但稍加观察就会露馅。
至于各种首饰不对称或花纹材质缝合对不上之类的问题我就不说了,太简单常见,讲打光吧。
根据背景能很容易的看出,本场景的主光源就是来自画面右侧的天光:
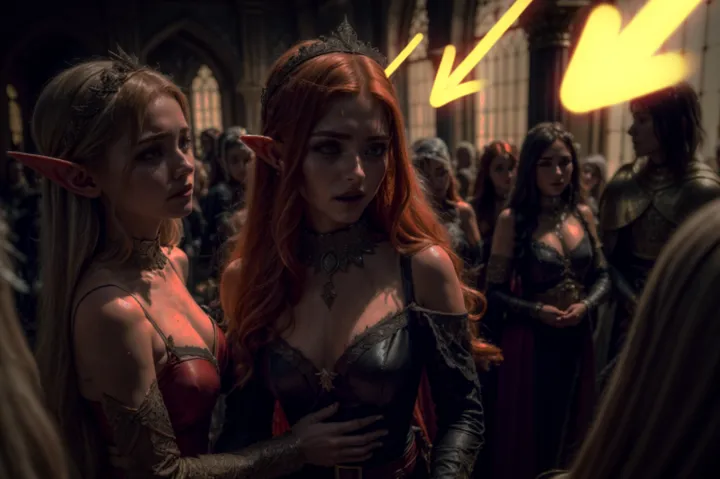
但是窗户的曝光明显低于精灵身上的曝光,实际上这俩精灵身上的照明是典型的天光色,和场景灯光严重不符。
除了曝光外,两个精灵身上的光向也非常复杂:

红头稍微稳定些,主要是偏右的顶光,金发则同时受到多个互不干扰的光源照射。金发的脸和场景主光源方向一致,但丝毫没收到红头的身体遮挡,尤其是奶子,理论上应该完全被阴影覆盖的却亮堂堂的,显然是顶光,但顶光的话又似乎完全没照到金发,如果给灯光上snoot的确能聚光,但在覆盖边缘会有明显衰减,这图里又看不见。
简单来说,这两精灵的打光是现实世界里再强的剧组也打不出来的完全不可能灯光。
再说一下物理镜头的问题,尤其是景深。
只看redhead的话:

我会说这是一个35mm头开到T1.5。
但要是只看金毛:

这得是35mm在T3.5的虚化。
这个问题在于背景虚化没有和纵深一起变:

图片左侧更远,应该有更显著的虚化,但图片中整个背景的虚化程度都一样,这个效果甚至不如手机的人像模式。
然后是CoC,以背景被虚化了的女士为例:

她这个首饰上的小光点通常被叫做bokeh,实际照片里也能看见:

RF24105@47mm拍摄
bokeh的形状取决于入射光瞳的形状,在同一纵深的bokeh,大小也是一致的,此时再看她首饰:

bokeh大小形状都有大幅不同,图片中其他部分也是一样的情况。
AI图中类似的和物理现象对不上的地方举不胜数,这里不再多说。
从更客观些的角度来说,AI生成图片还经常有频率问题,对这个图片上一个高通滤镜:

对比一张实际照片(我图里随便找的):

聚焦面部:

或者用查边:
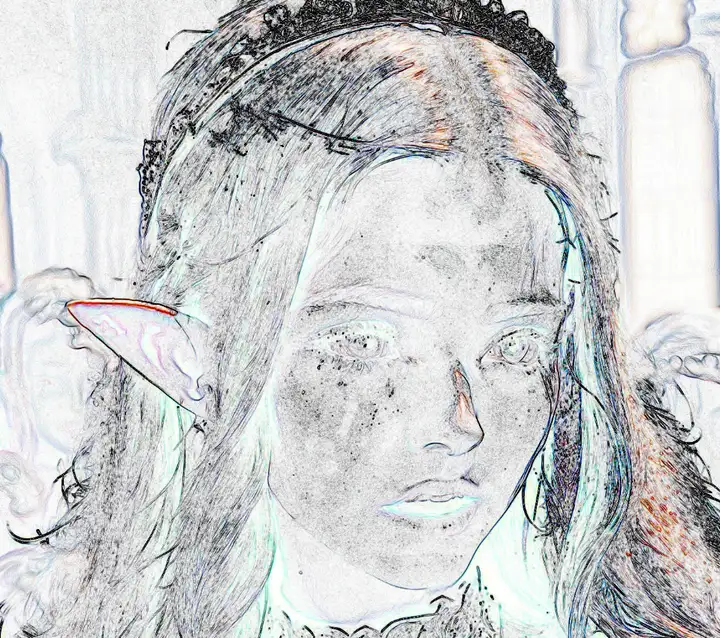
对比一个真人:

AI的脸上有明显的高低频跳跃(这个现象和打光无关),一些地方出现了非常强烈的明度和色度噪点,但却能紧挨着一块平滑的区域,哪怕两块是一个材质(这个现象在以前基于照片拼接的的影视概设中也经常出现,黄光剑之类的个别画家也喜欢用这个效果)。
(那个真人图看着有点儿瘆人…… 实际上是个非常甜的小姐姐)

AI图这些现象都是因为其生成并不基于逻辑而是基于概率,就像是打字时的预测,AI知道打下“我要”之后经常伴随一个动词,动词后经常跟一个名词,加上用户词库,直接按AI提供的下一个词就可能打出现“我要吃屎”这种东西,尽管AI并不知道吃是什么,屎又是什么(感觉这个比喻可能不太恰当,NLP搞预测经常会向量化,此时AI的确不知道屎为何物,但根据参考高维空间里这个词的位置,多少知道点儿什么时候用)。
对于大多数人,上面说到的解剖学和镜头成像分析可能多是一些从没想过或听过的概念,自己是并不知道的。但实际上,大多数人只是不能明确指出这东西,看AI图时,潜意识中已经发现了这些迹象。
人这辈子看的最多的就是人(听着真别扭),因此潜意识中对“什么是人”有着极其强大且准确的判断,对于理性的知道是人但感性的觉得不像人的东西会产生 生理排斥。想混过这个人类识别器是极其困难的挑战,哪怕是好莱坞也经常不过关。举些近些年比较出名的CGI人类例子:
由ILM制作,游侠一号里的的Grand Moff Tarkin:

Grand Moff Tarkin的演员Peter Cushing在拍游侠一号时已经逝世,但因为剧情衔接ep3他又必须出场,所以电影中的Tarkin是ILM计算机制作的。ILM、Weta、MPC算是现在好莱坞特效三巨头了(技术层面讲),但做人还是达不到无懈可击。
Weta则在阿丽塔里负责了大量阿丽塔的视效:

这个片子违和感倒没那么严重,因为阿丽塔写明了不是人,加上这个大眼睛几乎是在尖叫着“我不是人”,看几分钟就习惯了。
Henry Cavill在拍正义联盟时,同时也在拍谍中谍,而碟中谍的造型需要他留胡子,所以正义联盟中Henry Cavill其实都带着胡子,超人的脸上没胡子是用后期去掉的。结果很多地方Henry Cavill看起来都非常奇怪:

影视作品中让人觉得真实的CGI角色,多是指环王的咕噜、妇联灭霸、阿凡达小蓝人那样第一眼就知道“不是人类”的角色。
大多数现代人看AI图就像是那个银行训练的故事,因为只接触过真币,熟悉了真的感觉,在接触到假币时立刻就感觉到不对劲。
生活中可能很多人都觉得那些黑人白人明星长得都差不多,而分辨自己身边的人则轻而易举。这个现象在其他族裔中也存在,把人当成AI,那每个人都是把自己周围的人当训练集,因此擅长分辨自己常见的人,对于其他族裔,因为缺少数据,难以分辨个体的不同[1][2](跨种族也类似[3],好比你可能觉得咖啡店里那几个橘猫长得都一样,但开了5年的店主远远的就知道哪个是大黄)。
AI在这个问题上类似于一个“新种族”,因为大多数人只见过真人,所以在见到AI和CGI假人时,尽管不能直接指出哪里有问题,潜意识就是在告诉你“这不是人”。
这也带出另一个结论,AI以后肯定是越来越强的,人类现在则是越来越废宅的。既然识别能力需要经验他人来做训练集,那么将来总有一天,对大多数来说,AI图片和视频看起来将和真实的一样,二者完全无法通过肉眼分辨。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









