






jx+jnx
__asm {
jz s;
jnz s;
_emit 0xC7;
s:
jnz实际上是fake的,因为jz这个指令,让ida认为jz下面的是另外一个分支,所以这里去除,就是将jnz下面包括jnz 全c了,然后把loc_402669+1的字节码全给nop了
这种混淆去除方式也很简单,特征也很明显,因为是近跳转,所以ida分析的时候会分析出jz或者jnz会跳转几个字节,这个时候我们就可得到垃圾数据的长度,将该长度字节的数据全部nop掉即可解混淆。
call pop / add esp

这里call指令,其实本质就是jmp&push 下一条指令的地址,但是这里其实就是一个jmp指令
所以 push这条指令是多余的,需要add esp,4 调整堆栈,但是ida会默认把call 后面的那个地址
当成一个函数。
stx/jx

clc是清除EFlags寄存器的carry位的标志,而jnb是根据cf==0时跳转的,然而jnb这个分支指令,ida
又将后面的部分认作成了另外的分支
jmp xxx红色
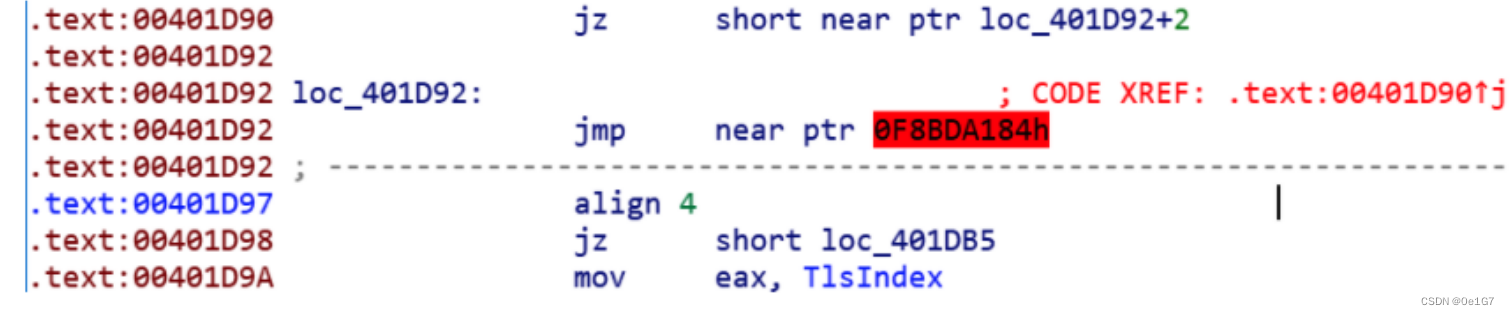
看下花指令源代码, 实际是e9在搞鬼,ida会默认将e9后面的4个字节当成地址,只要nop掉就行

多重跳转的

利用idapython去除
def nop(addr,endaddr):
while(addr<endaddr):
PatchByte(addr,0x90)
addr+=1
def undefine(addr,endaddr):
while addr<endaddr:
MakeUnkn(addr,0)
addr+=1
def dejunkcode(addr,endaddr):
while addr<endaddr:
MakeCode(addr)
# 匹配模版
if GetMnem(addr)=='jmp' and GetOperandValue(addr,0)==addr+5 and Byte(addr+2)==0x12:
next=addr+10
nop(addr,next)
addr=next
continue
addr+=ItemSize(addr)
永恒跳转
最简单的jmp指令
jmp s
db junk_code;
s:
这种jmp单次跳转只能骗过线性扫描算法,会被IDA识别(递归下降)
多层跳转
__asm {
jmp s1;
_emit 68h;
s1:
jmp s2;
_emit 0CDh;
_emit 20h;
s2:
jmp s3;
_emit 0E8h;
s3:
}
和单次跳转一样,这种也会被IDA识别。将花指令改写一下骗过IDA
__asm {
_emit 0xE8
_emit 0xFF
//_emit 立即数:代表在这个位置插入一个数据,这里插入的是0xe8
}
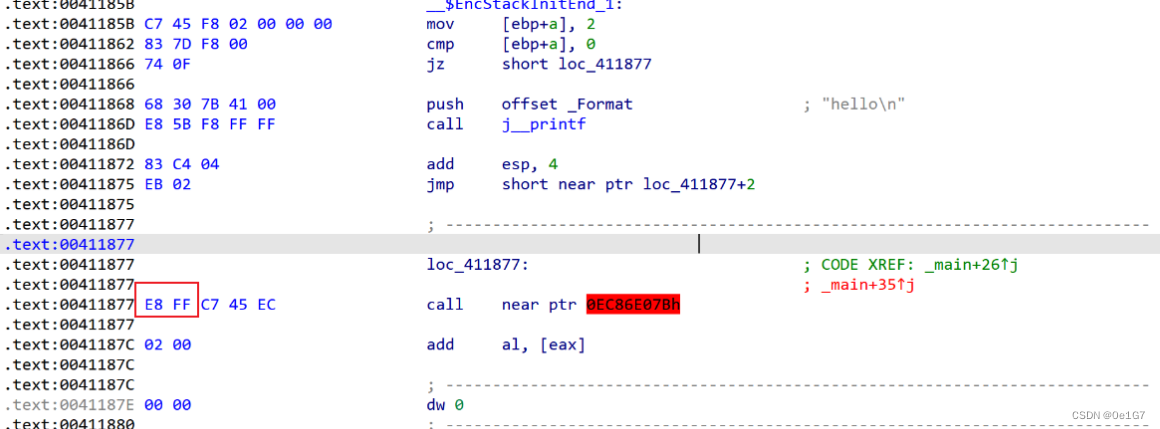
可以看到IDA错误的识别loc_411877处的代码,成功的实现了花指令的目的
常用指令含义
push ebp ----把基址指针寄存器压入堆栈
pop ebp ----把基址指针寄存器弹出堆栈
push eax ----把数据寄存器压入堆栈
pop eax ----把数据寄存器弹出堆栈
nop -----不执行
add esp,1-----指针寄存器加1
sub esp,-1-----指针寄存器加1
add esp,-1--------指针寄存器减1
sub esp,1-----指针寄存器减1
inc ecx -----计数器加1
dec ecx -----计数器减1
sub esp,1 ----指针寄存器-1
sub esp,-1----指针寄存器加1
jmp 入口地址----跳到程序入口地址
push 入口地址—把入口地址压入堆栈
retn ------ 反回到入口地址,效果与jmp 入口地址一样
mov eax,入口地址 ------把入口地址转送到数据寄存器中.
jmp eax ----- 跳到程序入口地址
jb 入口地址
jnb 入口地址 ------效果和jmp 入口地址一样,直接跳到程序入口地址
xor eax,eax 寄存器EAX清0
CALL 空白命令的地址 无效call
栈指针平衡
这里借用大佬的图来看一个栈针平衡的示例,总结就是先进后出,每一次pop和push要改变esp让栈平衡

例题:
[HNCTF 2022 WEEK2]e@sy_flower
当使用IDA分析伪代码时,有花指令会发生
无法查看伪代码,需要去给出的地址查看具体发生的问题
要设置一下IDA,让它显示出栈指针(Options-General-Disassembly-"Stack pointer")

可以把stack pointer打开,然后再把number of opcode bytes 设为5
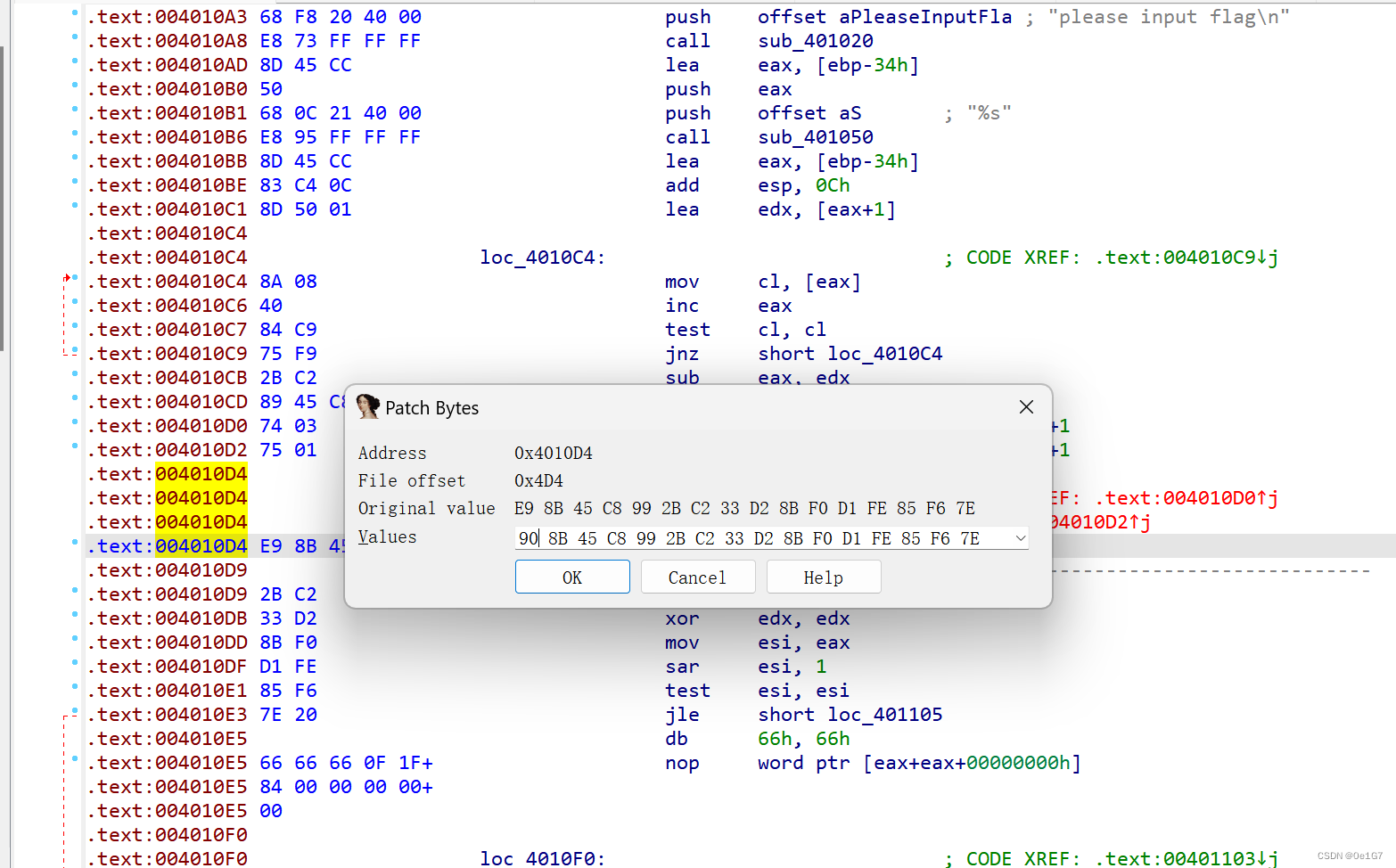
发现jz和jnz互补跳转了,后面地址+1已经提示了跳转的字节大小。
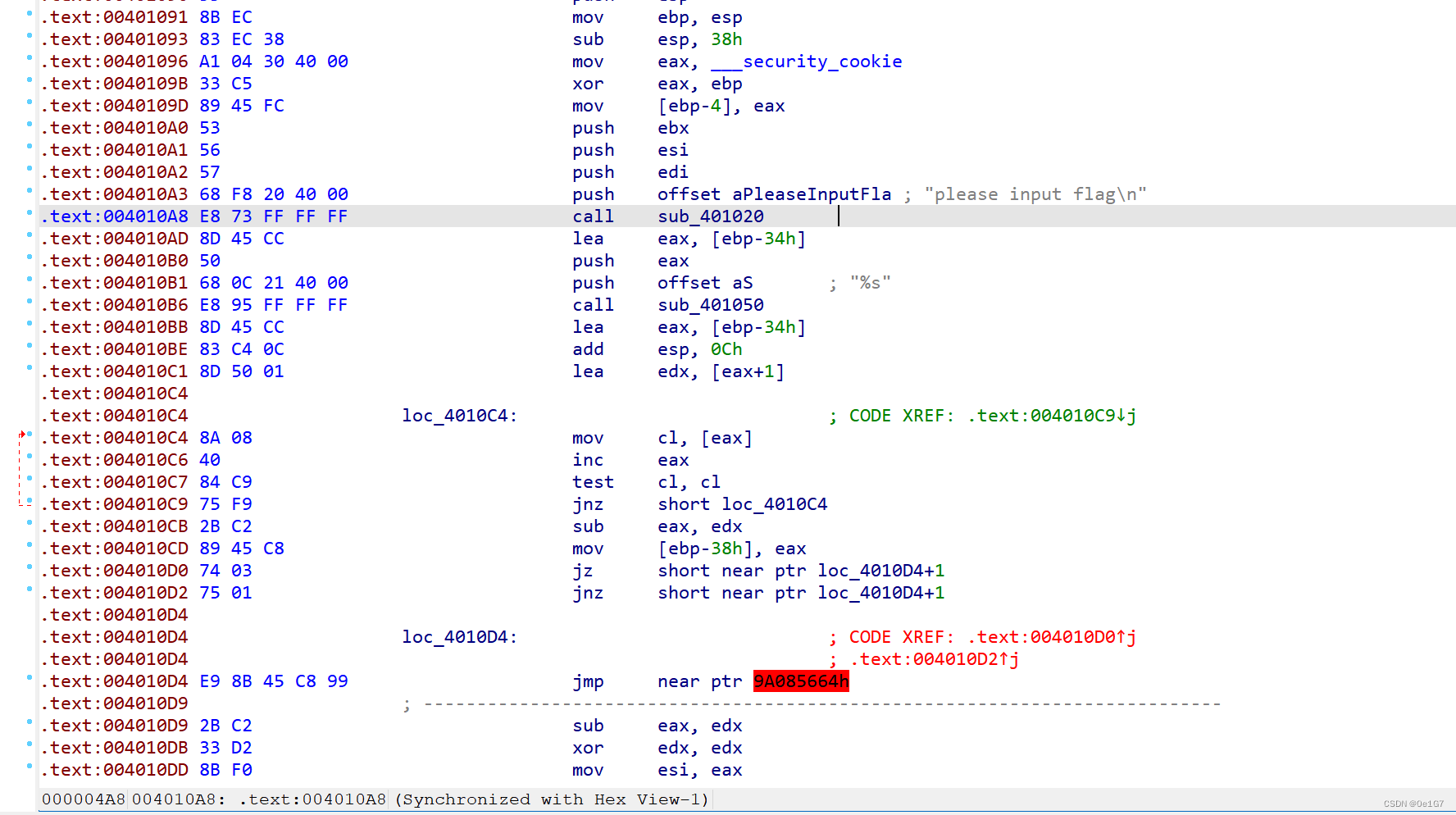
选中这一行,Edit-Patch program-Change bytes,把第一个e9改为90
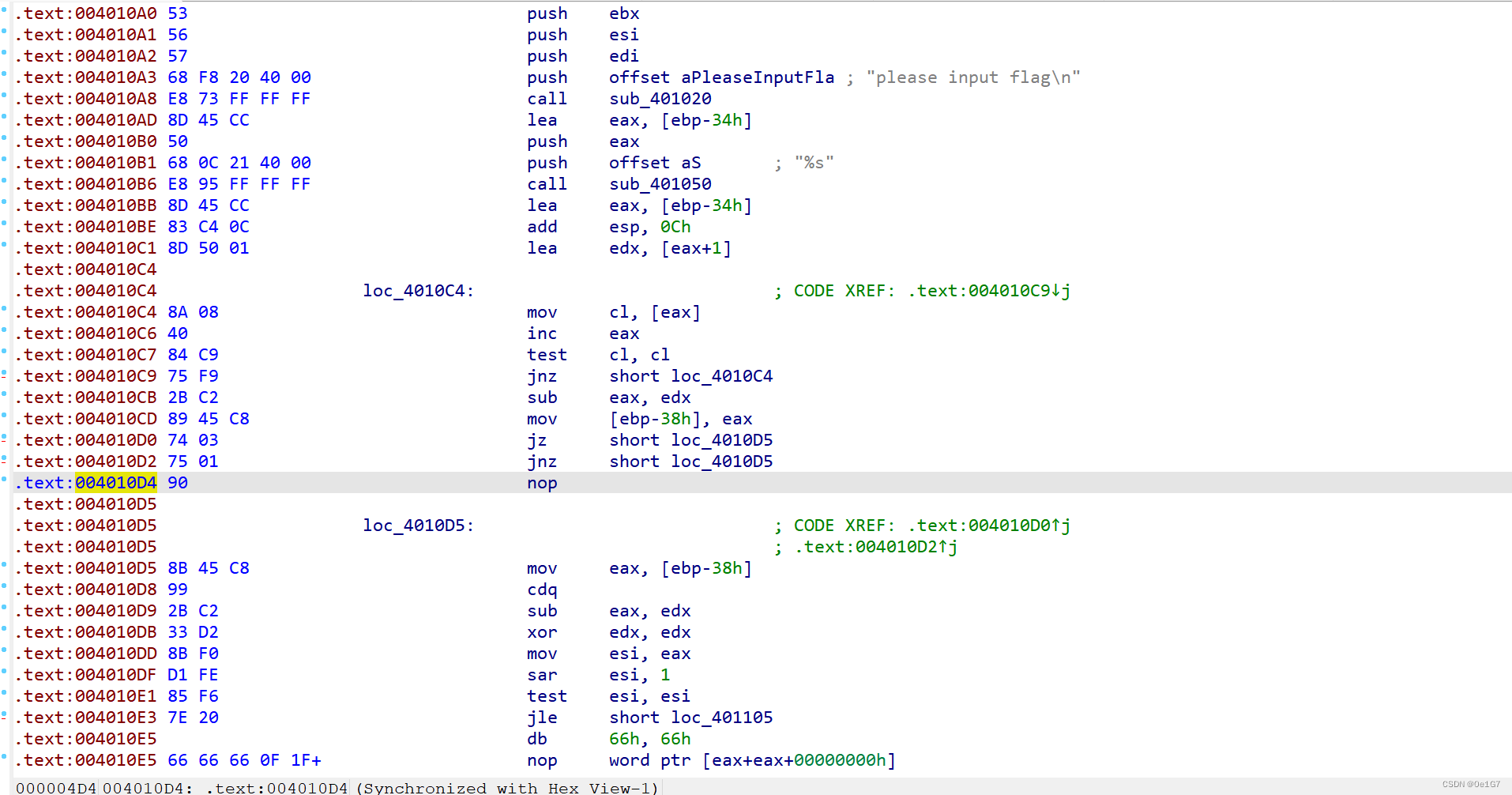
对main函数用P重新定义下,再F5反编译
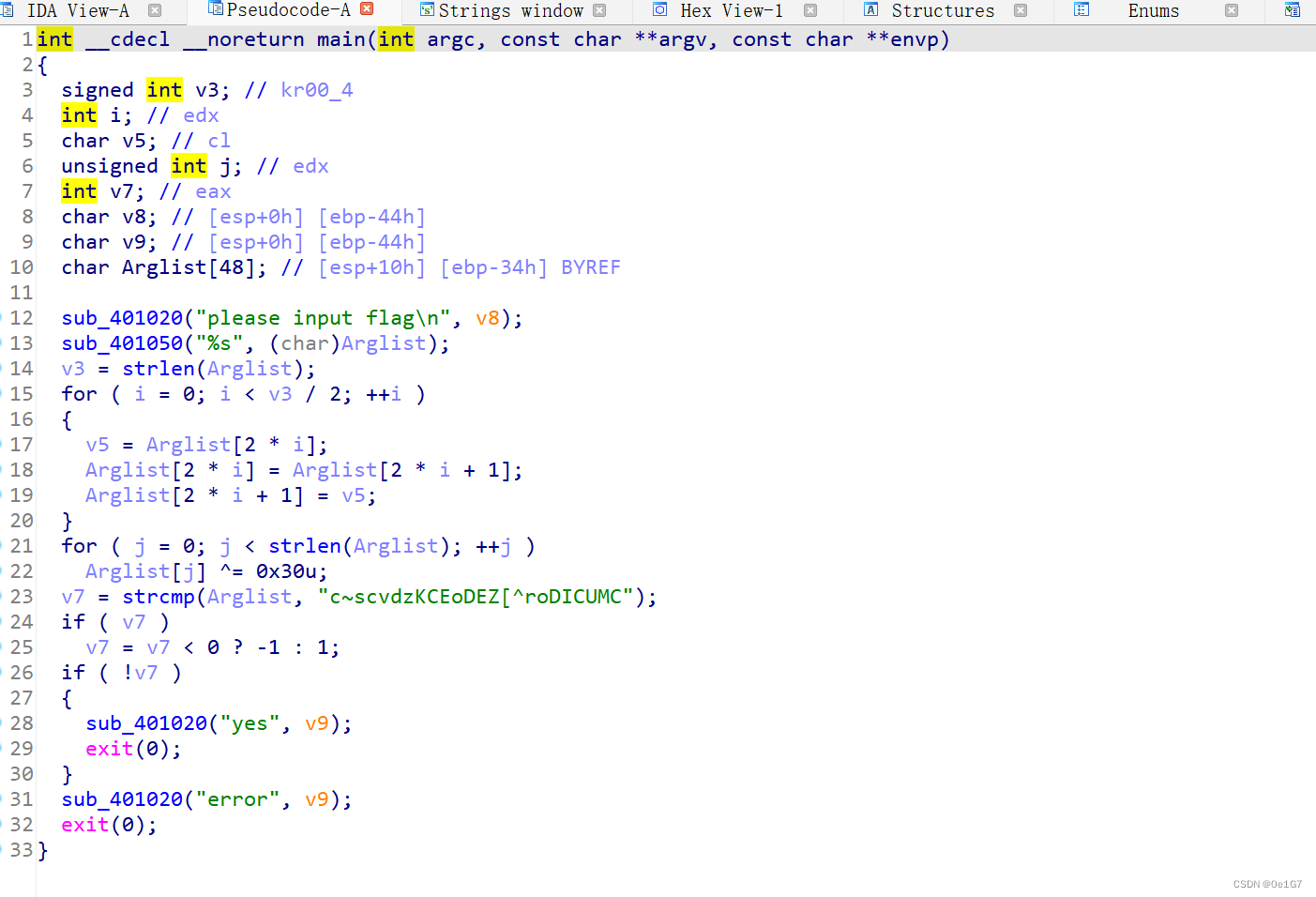
逻辑就是输入的flag先互换位置,再与0x30异或
enc = list('c~scvdzKCEoDEZ[^roDICUMC')
flag = []
for i in range(len(enc)):
flag.append(chr(ord(enc[i])^0x30))
for i in range(int(len(flag)/2)):
tmp = flag[2*i]
flag[2 * i] = flag[2 * i + 1]
flag[2 * i + 1] = tmp
for i in flag:
print(i,end="")
[MoeCTF 2022]chicken_soup
查壳32,打开分析后发现401000和401080对v4加密了,点击进去,就发现401000和401080被加花了
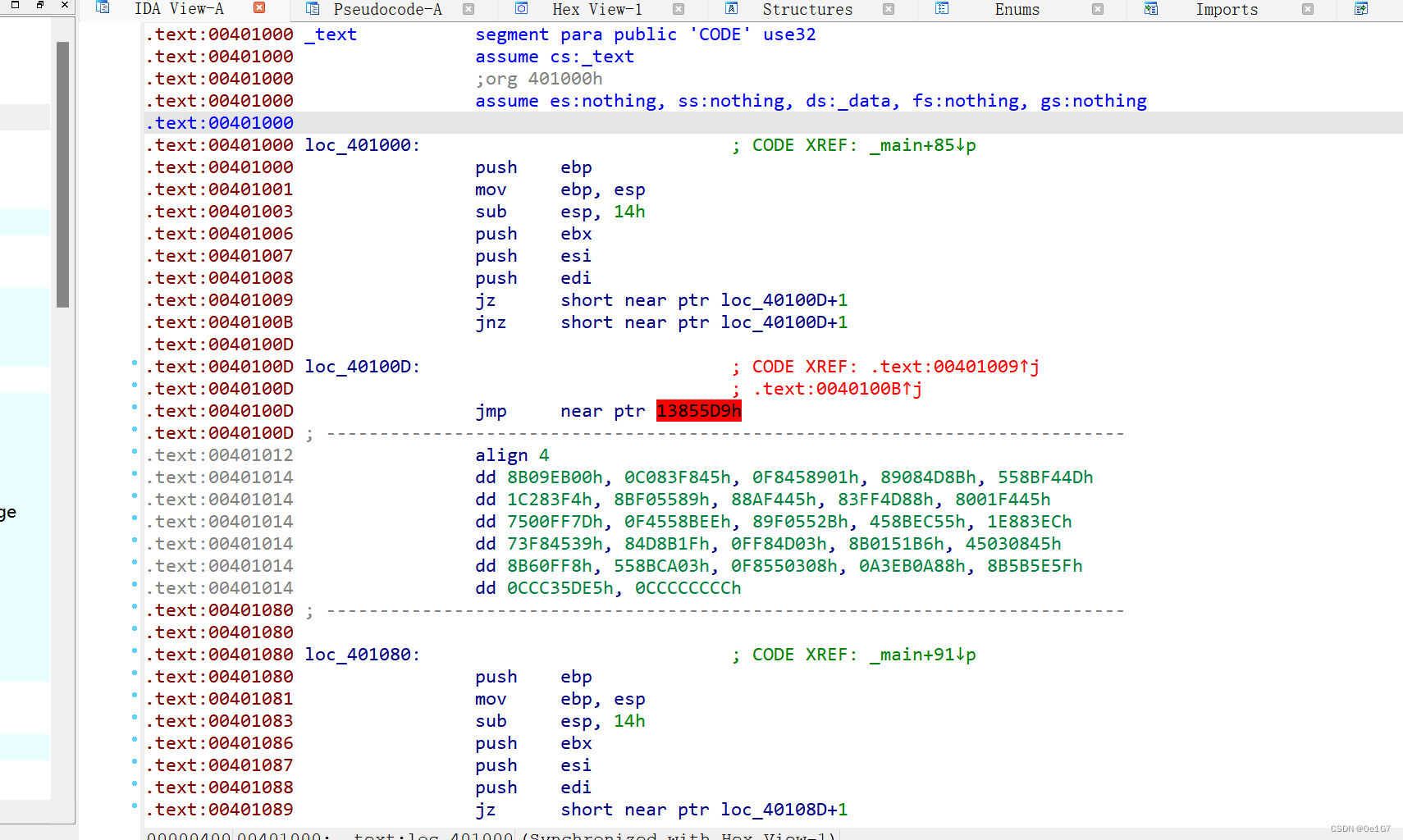
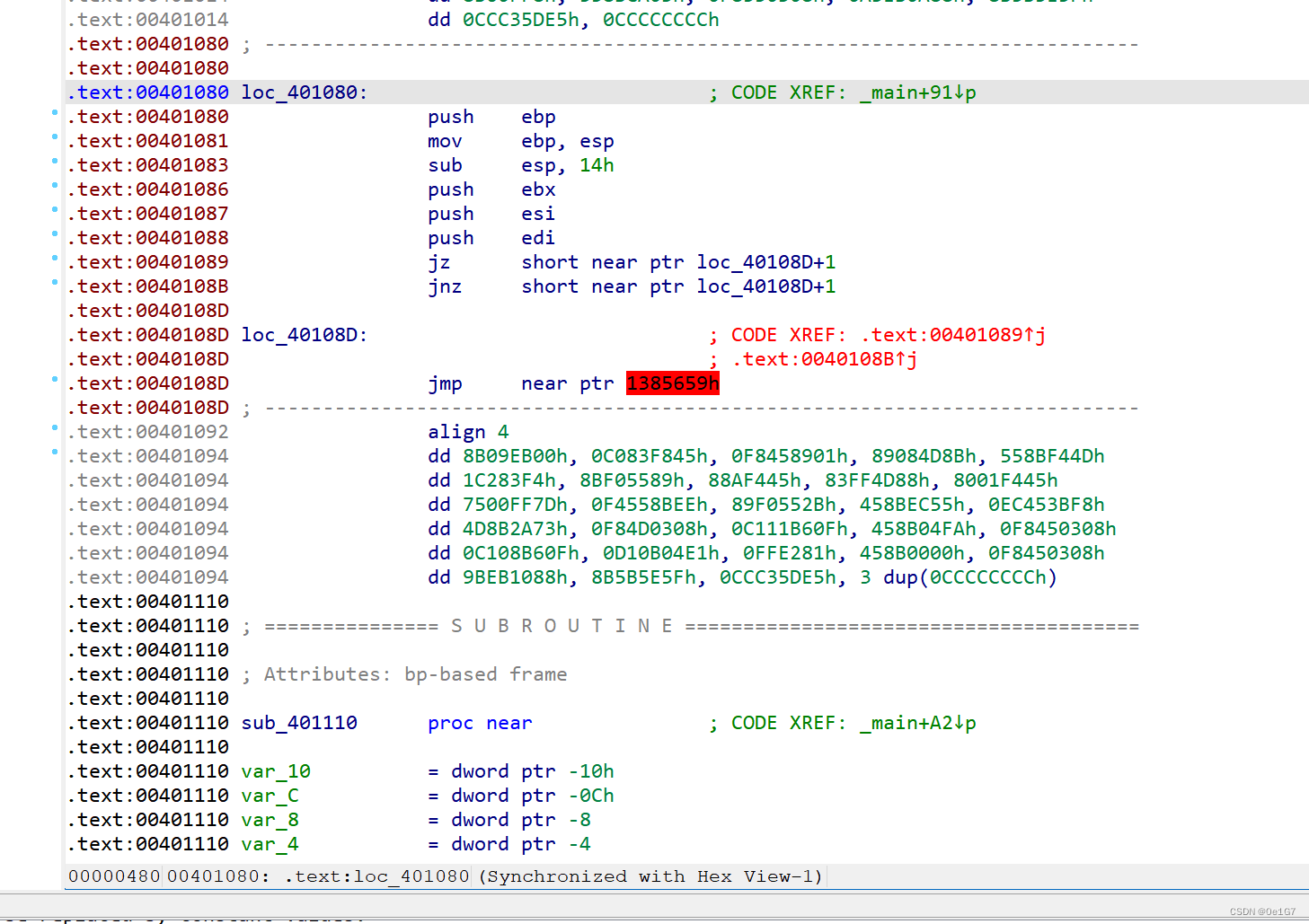
jz和jnz互补跳转。打开opcode bytes的显示,然后分别对E9改为90nop掉,然后用P再F5

进去main,可以看到sub_401000和sub_401080分别对v4进行加密
思路:输入字符串---->flag长度检验为38个—>经过2个函数指针的运算后----->与加密过后的数据进行比较

第一层加密,即flag[i] = flag[i] + flag[i+1]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









