







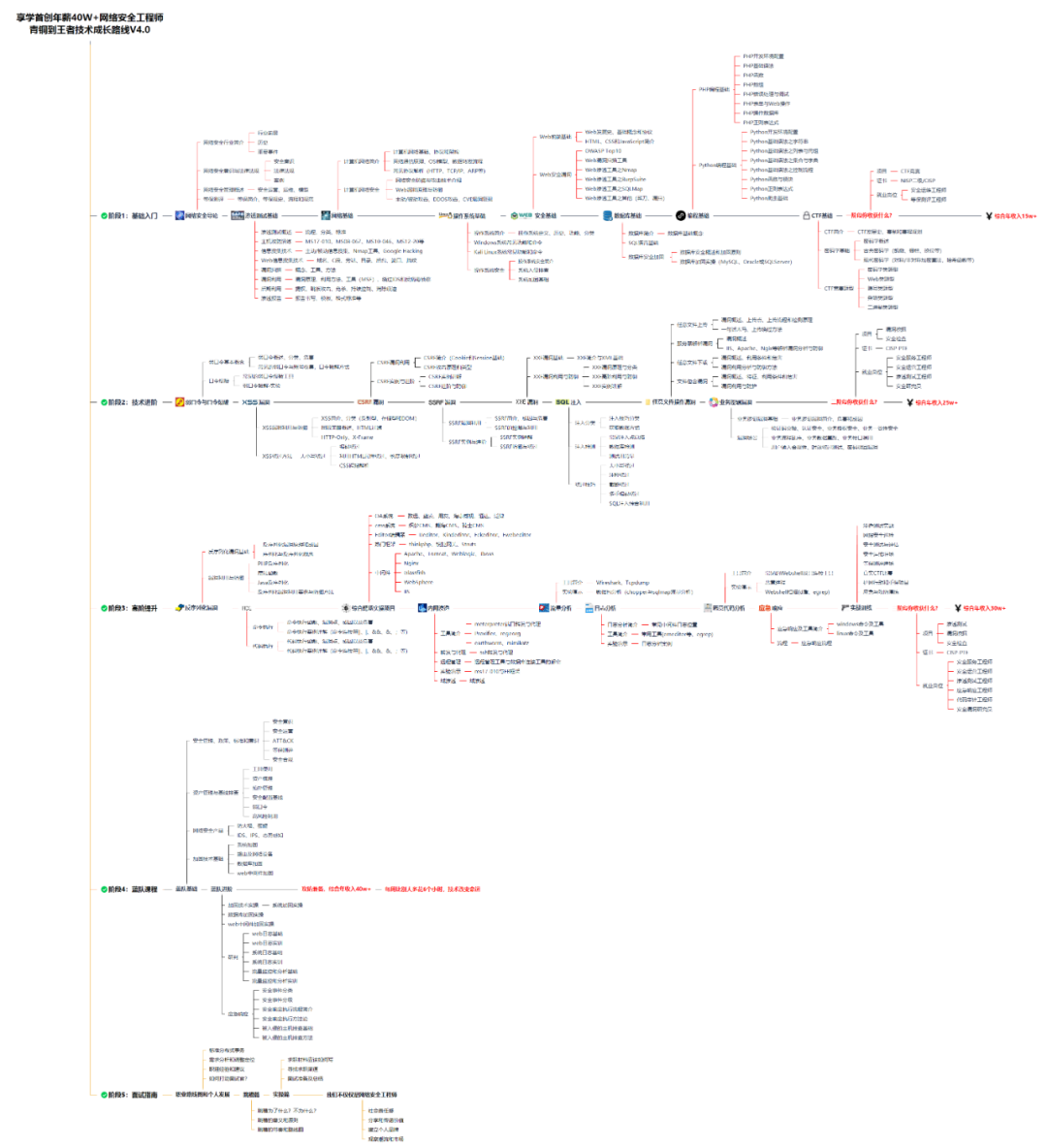
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
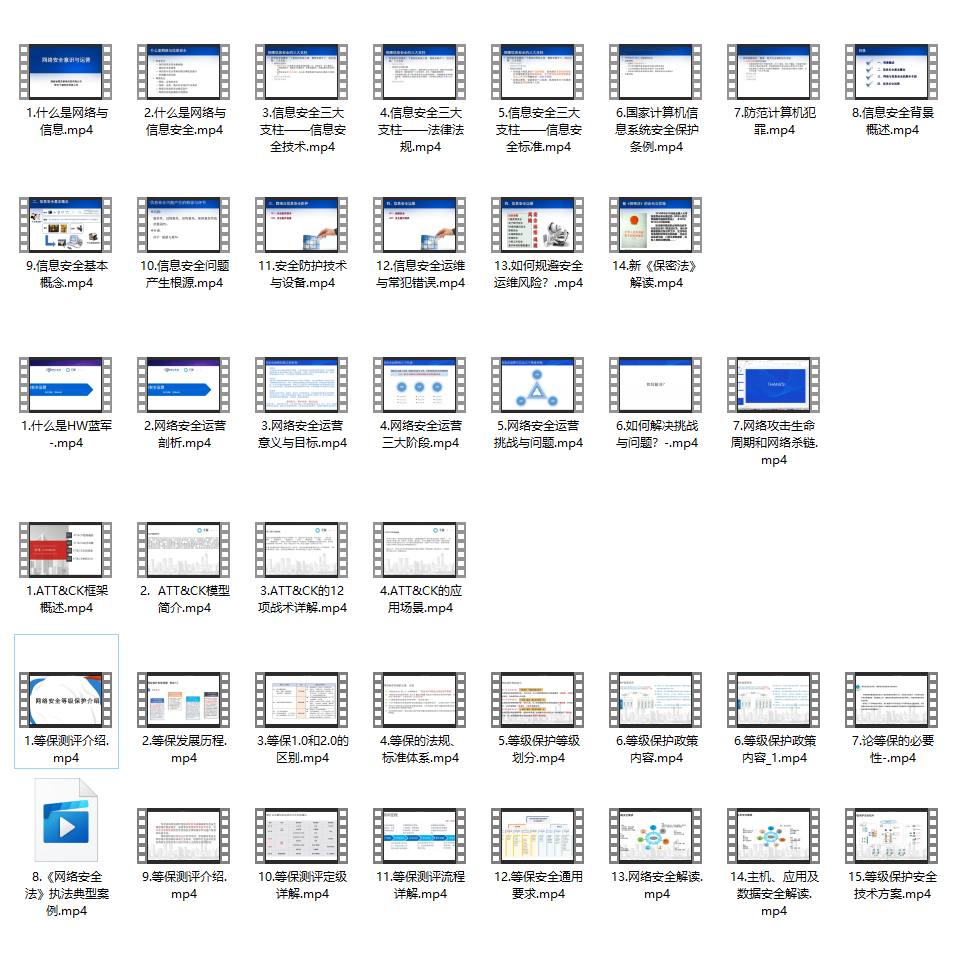
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
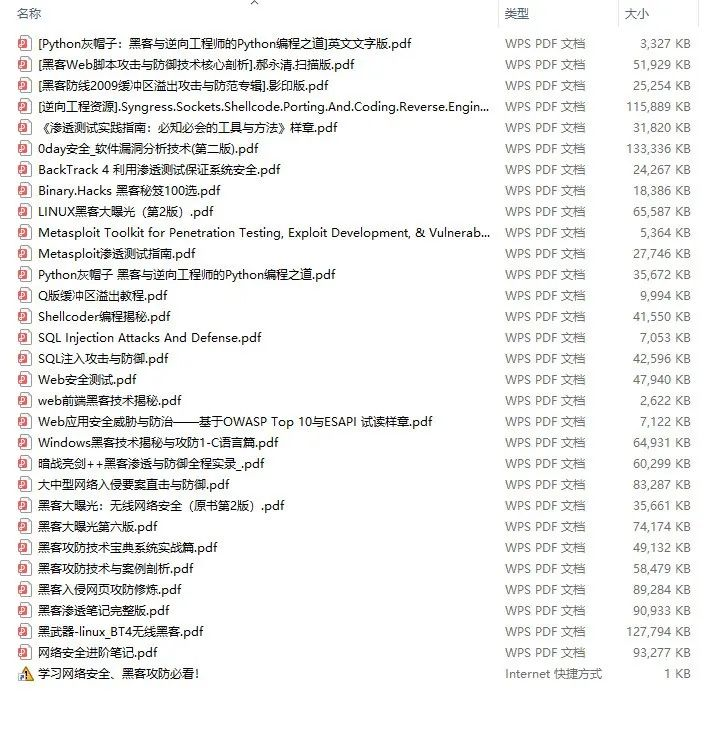
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

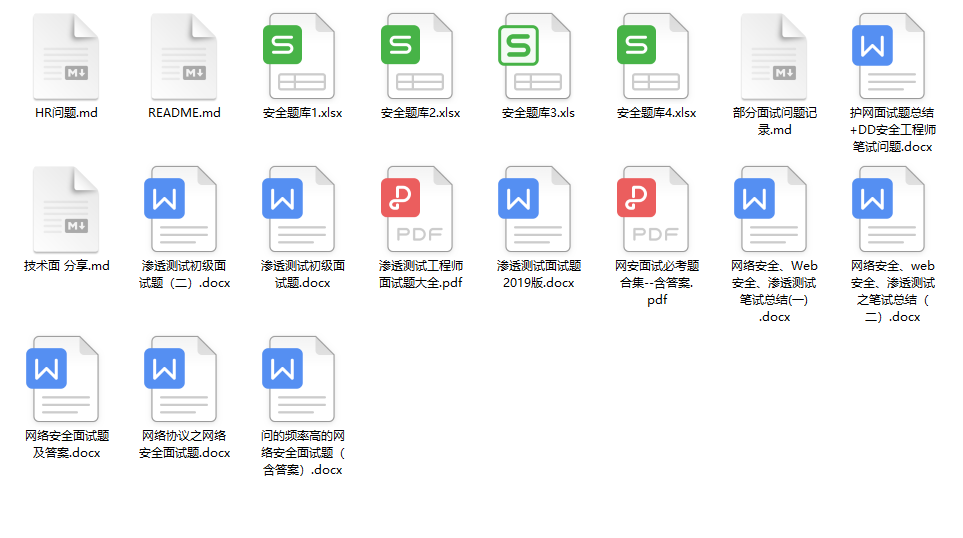
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
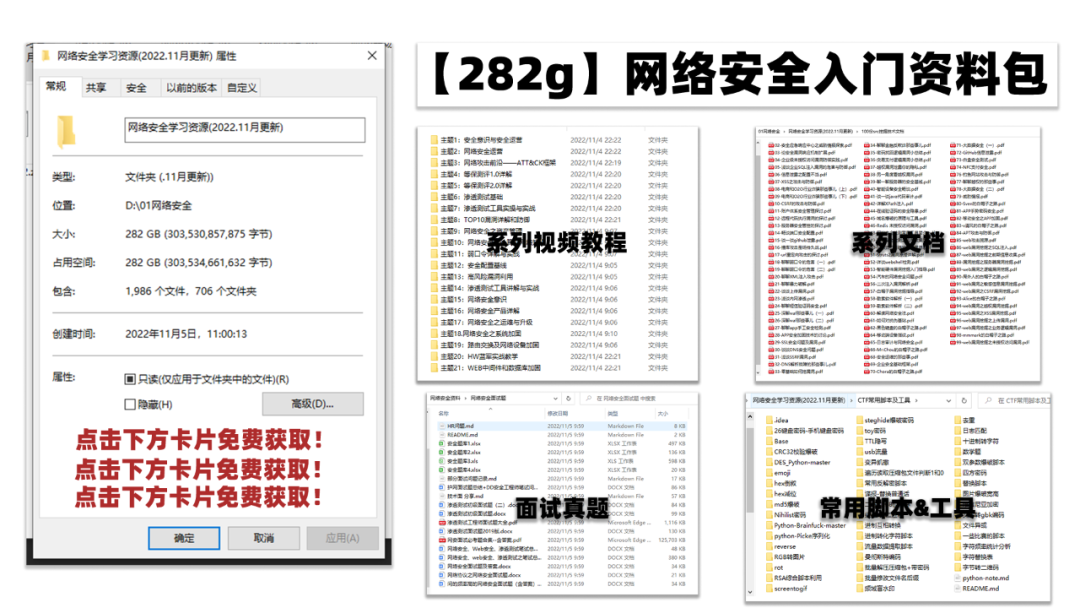
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式
sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字
sys.builtin_module_names Python解释器导入的内建模块列表
sys.executable Python解释程序路径
sys.getwindowsversion() 获取Windows的版本
sys.stdin.readline() 从标准输入读一行,sys.stdout.write(“a”) 屏幕输出a
sys.setdefaultencoding(name) 用来设置当前默认的字符编码(详细使用参考文档)
sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout(详细使用参考文档)
## datetime,date,time模块:
datetime.date.today() 本地日期对象,(用str函数可得到它的字面表示(2014-03-24))
datetime.date.isoformat(obj) 当前[年-月-日]字符串表示(2014-03-24)
datetime.date.fromtimestamp() 返回一个日期对象,参数是时间戳,返回 [年-月-日]
datetime.date.weekday(obj) 返回一个日期对象的星期数,周一是0
datetime.date.isoweekday(obj) 返回一个日期对象的星期数,周一是1
datetime.date.isocalendar(obj) 把日期对象返回一个带有年月日的元组
datetime对象:
datetime.datetime.today() 返回一个包含本地时间(含微秒数)的datetime对象 2014-03-24 23:31:50.419000
datetime.datetime.now([tz]) 返回指定时区的datetime对象 2014-03-24 23:31:50.419000
datetime.datetime.utcnow() 返回一个零时区的datetime对象
datetime.fromtimestamp(timestamp[,tz]) 按时间戳返回一个datetime对象,可指定时区,可用于strftime转换为日期表示
datetime.utcfromtimestamp(timestamp) 按时间戳返回一个UTC-datetime对象
datetime.datetime.strptime(‘2014-03-16 12:21:21‘,”%Y-%m-%d %H:%M:%S”) 将字符串转为datetime对象
datetime.datetime.strftime(datetime.datetime.now(), ‘%Y%m%d %H%M%S‘) 将datetime对象转换为str表示形式
datetime.date.today().timetuple() 转换为时间戳datetime元组对象,可用于转换时间戳
datetime.datetime.now().timetuple()
time.mktime(timetupleobj) 将datetime元组对象转为时间戳
time.time() 当前时间戳
time.localtime
time.gmtime
## hashlib,md5模块:
hashlib.md5(‘md5_str‘).hexdigest() 对指定字符串md5加密
md5.md5(‘md5_str‘).hexdigest() 对指定字符串md5加密
## random模块:
random.random() 产生0-1的随机浮点数
random.uniform(a, b) 产生指定范围内的随机浮点数
random.randint(a, b) 产生指定范围内的随机整数
random.randrange([start], stop[, step]) 从一个指定步长的集合中产生随机数
random.choice(sequence) 从序列中产生一个随机数
random.shuffle(x[, random]) 将一个列表中的元素打乱
random.sample(sequence, k) 从序列中随机获取指定长度的片断
## types模块:
保存了所有数据类型名称。
if type(‘1111‘) == types.StringType:
MySQLdb模块:
MySQLdb.get_client_info() 获取API版本
MySQLdb.Binary(‘string‘) 转为二进制数据形式
MySQLdb.escape_string(‘str‘) 针对mysql的字符转义函数
MySQLdb.DateFromTicks(1395842548) 把时间戳转为datetime.date对象实例
MySQLdb.TimestampFromTicks(1395842548) 把时间戳转为datetime.datetime对象实例
MySQLdb.string_literal(‘str‘) 字符转义
MySQLdb.cursor()游标对象上的方法:《python核心编程》P624
## atexit模块:
atexit.register(fun,args,args2…) 注册函数func,在解析器退出前调用该函数
## string模块
str.capitalize() 把字符串的第一个字符大写
str.center(width) 返回一个原字符串居中,并使用空格填充到width长度的新字符串
str.ljust(width) 返回一个原字符串左对齐,用空格填充到指定长度的新字符串
str.rjust(width) 返回一个原字符串右对齐,用空格填充到指定长度的新字符串
str.zfill(width) 返回字符串右对齐,前面用0填充到指定长度的新字符串
str.count(str,[beg,len]) 返回子字符串在原字符串出现次数,beg,len是范围
str.decode(encodeing[,replace]) 解码string,出错引发ValueError异常
str.encode(encodeing[,replace]) 解码string
str.endswith(substr[,beg,end]) 字符串是否以substr结束,beg,end是范围
str.startswith(substr[,beg,end]) 字符串是否以substr开头,beg,end是范围
str.expandtabs(tabsize = 8) 把字符串的tab转为空格,默认为8个
str.find(str,[stat,end]) 查找子字符串在字符串第一次出现的位置,否则返回-1
str.index(str,[beg,end]) 查找子字符串在指定字符中的位置,不存在报异常
str.isalnum() 检查字符串是否以字母和数字组成,是返回true否则False
str.isalpha() 检查字符串是否以纯字母组成,是返回true,否则false
str.isdecimal() 检查字符串是否以纯十进制数字组成,返回布尔值
str.isdigit() 检查字符串是否以纯数字组成,返回布尔值
str.islower() 检查字符串是否全是小写,返回布尔值
str.isupper() 检查字符串是否全是大写,返回布尔值
str.isnumeric() 检查字符串是否只包含数字字符,返回布尔值
str.isspace() 如果str中只包含空格,则返回true,否则FALSE
str.title() 返回标题化的字符串(所有单词首字母大写,其余小写)
str.istitle() 如果字符串是标题化的(参见title())则返回true,否则false
str.join(seq) 以str作为连接符,将一个序列中的元素连接成字符串
str.split(str=‘‘,num) 以str作为分隔符,将一个字符串分隔成一个序列,num是被分隔的字符串
str.splitlines(num) 以行分隔,返回各行内容作为元素的列表
str.lower() 将大写转为小写
str.upper() 转换字符串的小写为大写
str.swapcase() 翻换字符串的大小写
str.lstrip() 去掉字符左边的空格和回车换行符
str.rstrip() 去掉字符右边的空格和回车换行符
str.strip() 去掉字符两边的空格和回车换行符
str.partition(substr) 从substr出现的第一个位置起,将str分割成一个3元组。
str.replace(str1,str2,num) 查找str1替换成str2,num是替换次数
str.rfind(str[,beg,end]) 从右边开始查询子字符串
str.rindex(str,[beg,end]) 从右边开始查找子字符串位置
str.rpartition(str) 类似partition函数,不过从右边开始查找
str.translate(str,del=‘‘) 按str给出的表转换string的字符,del是要过虑的字符
## urllib模块:
urllib.quote(string[,safe]) 对字符串进行编码。参数safe指定了不需要编码的字符
urllib.unquote(string) 对字符串进行解码
urllib.quote_plus(string[,safe]) 与urllib.quote类似,但这个方法用‘+‘来替换‘ ‘,而quote用‘%20‘来代替‘ ‘
urllib.unquote_plus(string ) 对字符串进行解码
urllib.urlencode(query[,doseq]) 将dict或者包含两个元素的元组列表转换成url参数。
例如 字典{‘name‘:‘wklken‘,‘pwd‘:‘123‘}将被转换为”name=wklken&pwd=123″
urllib.pathname2url(path) 将本地路径转换成url路径
urllib.url2pathname(path) 将url路径转换成本地路径
urllib.urlretrieve(url[,filename[,reporthook[,data]]]) 下载远程数据到本地
filename:指定保存到本地的路径(若未指定该,urllib生成一个临时文件保存数据)
reporthook:回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调
data:指post到服务器的数据
rulrs = urllib.urlopen(url[,data[,proxies]]) 抓取网页信息,[data]post数据到Url,proxies设置的代理
urlrs.readline() 跟文件对象使用一样
urlrs.readlines() 跟文件对象使用一样
urlrs.fileno() 跟文件对象使用一样
urlrs.close() 跟文件对象使用一样
urlrs.info() 返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息
urlrs.getcode() 获取请求返回状态HTTP状态码
urlrs.geturl() 返回请求的URL
## re模块:
一.常用正则表达式符号和语法:
‘.’ 匹配所有字符串,除\n以外
‘-’ 表示范围[0-9]
‘’ 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。
‘+’ 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +
‘^’ 匹配字符串开头
‘$’ 匹配字符串结尾 re
‘’ 转义字符, 使后一个字符改变原来的意思,如果字符串中有字符需要匹配,可以*或者字符集[] re.findall(r’3*','3ds’)结[‘3*’]
‘’ 匹配前面的字符0次或多次 re.findall("ab",“cabc3abcbbac”)结果:[‘ab’, ‘ab’, ‘a’]
‘?’ 匹配前一个字符串0次或1次 re.findall(‘ab?’,‘abcabcabcadf’)结果[‘ab’, ‘ab’, ‘ab’, ‘a’]
‘{m}’ 匹配前一个字符m次 re.findall(‘cb{1}’,‘bchbchcbfbcbb’)结果[‘cb’, ‘cb’]
‘{n,m}’ 匹配前一个字符n到m次 re.findall(‘cb{2,3}’,‘bchbchcbfbcbb’)结果[‘cbb’]
‘\d’ 匹配数字,等于[0-9] re.findall(’\d’,‘电话:10086’)结果[‘1’, ‘0’, ‘0’, ‘8’, ‘6’]
‘\D’ 匹配非数字,等于[^0-9] re.findall(‘\D’,‘电话:10086’)结果[‘电’, ‘话’, ‘:’]
‘\w’ 匹配字母和数字,等于[A-Za-z0-9] re.findall(‘\w’,‘alex123,./;;;’)结果[‘a’, ‘l’, ‘e’, ‘x’, ‘1’, ‘2’, ‘3’]
‘\W’ 匹配非英文字母和数字,等于[^A-Za-z0-9] re.findall(‘\W’,‘alex123,./;;;’)结果[‘,’, ‘.’, ‘/’, ‘;’, ‘;’, ‘;’]
‘\s’ 匹配空白字符 re.findall(‘\s’,‘3ds \t\n’)结果[’ ‘, ‘\t’, ‘\n’]
‘\S’ 匹配非空白字符 re.findall(’\s’,'3ds \t\n’)结果[‘3’, '', ‘d’, ‘s’]
‘\A’ 匹配字符串开头
‘\Z’ 匹配字符串结尾
‘\b’ 匹配单词的词首和词尾,单词被定义为一个字母数字序列,因此词尾是用空白符或非字母数字符来表示的
‘\B’ 与\b相反,只在当前位置不在单词边界时匹配
‘(?P…)’ 分组,除了原有编号外在指定一个额外的别名 re.search(“(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{8})”,“371481199306143242”).groupdict(“city”) 结果{‘province’: ‘3714’, ‘city’: ‘81’, ‘birthday’: ‘19930614’}
[] 是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s]表示空格或者*号。
二.常用的re函数:
方法/属性 作用
re.match(pattern, string, flags=0) 从字符串的起始位置匹配,如果起始位置匹配不成功的话,match()就返回none
re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配
re.findall(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个列表返回
re.finditer(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个迭代器返回
re.sub(pattern, repl, string, count=0, flags=0) 替换匹配到的字符串
## math模块
ceil:取大于等于x的最小的整数值,如果x是一个整数,则返回x
copysign:把y的正负号加到x前面,可以使用0
cos:求x的余弦,x必须是弧度
degrees:把x从弧度转换成角度
e:表示一个常量
exp:返回math.e,也就是2.71828的x次方
expm1:返回math.e的x(其值为2.71828)次方的值减1
fabs:返回x的绝对值
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
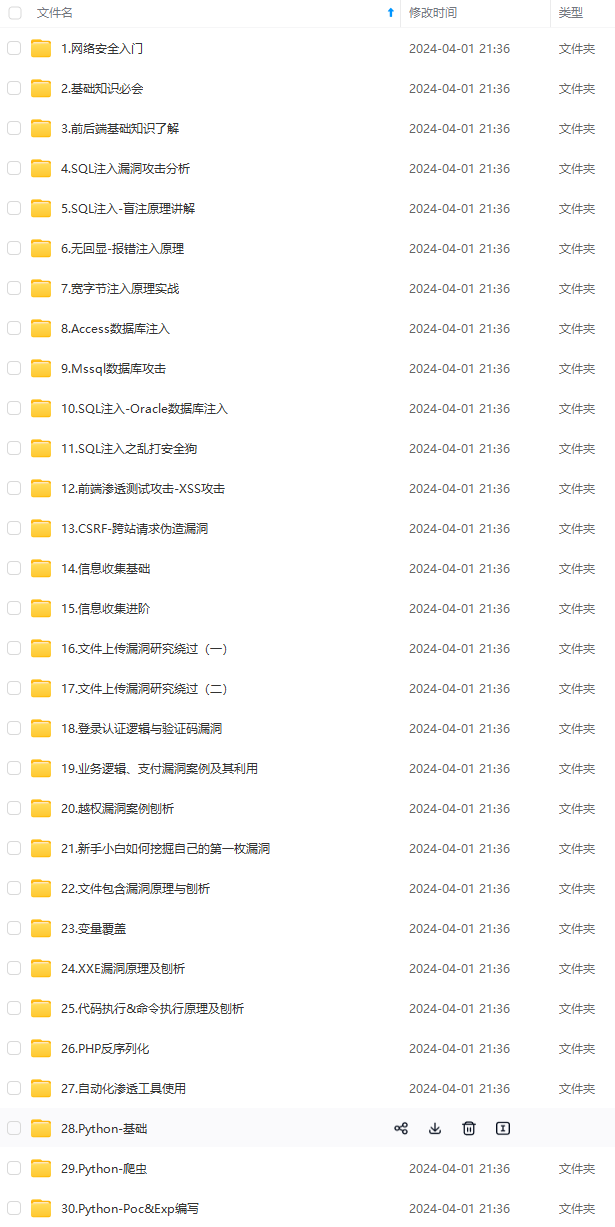
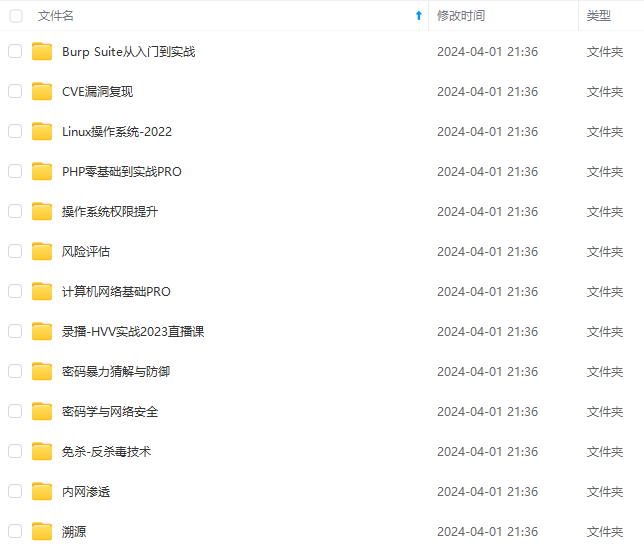
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
转存中…(img-BTXnrrcm-1715369582734)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









