








通过查询,最近的小区分别是安鸿峰景苑和万科公园里,它两所在的区域标识是龙岗区的布吉南岭(如图所示),所以可以直接使用布吉南岭进行该字段缺失值的填充
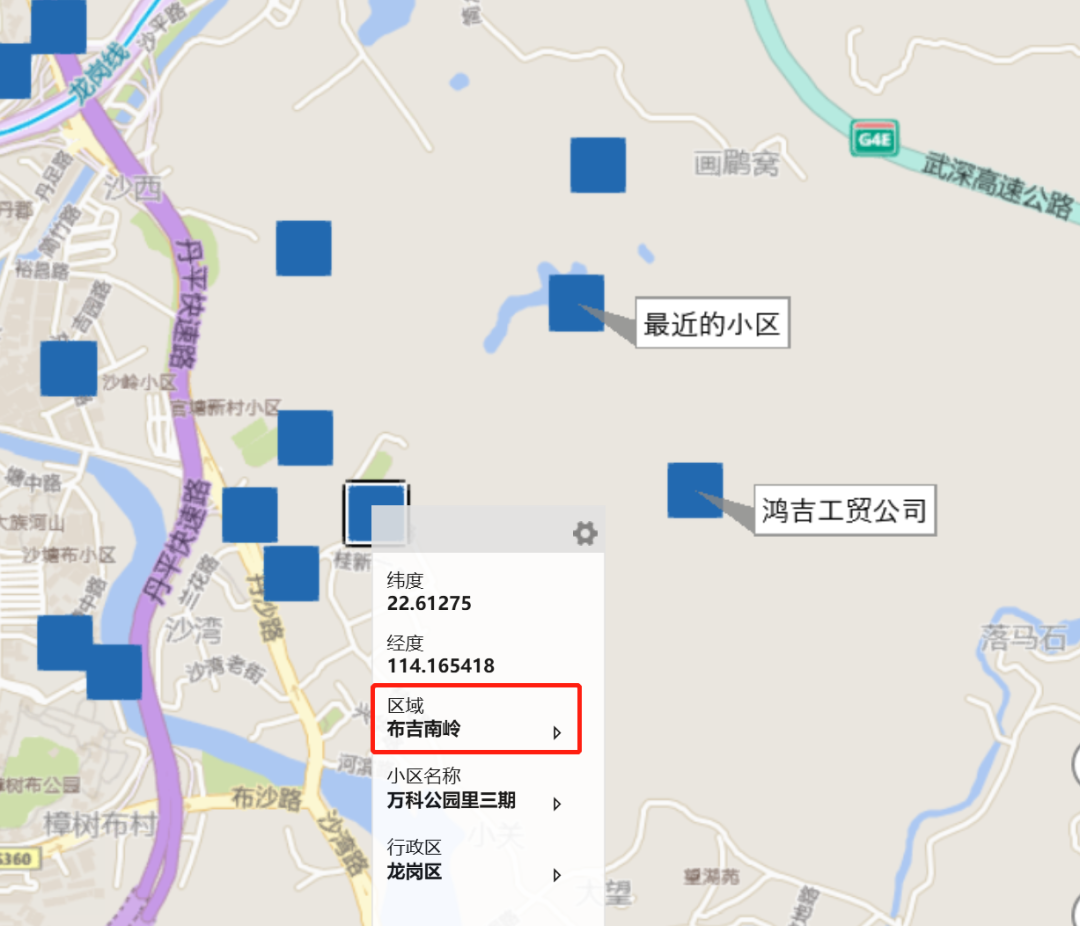
注:上述打点的位置存在偏移,但能反映真实距离,所以未做经纬度偏移转换
**补充一下,这个方法可以用于区域数据中大多数的缺失值填充。**例如:房屋价格存在缺失,可以使用同一区域内的均价进行填充;房屋类型存在缺失,可以使用同一小区的其他房屋该字段的众数进行填充;多个房屋区域存在缺失,可以通过自定义距离函数计算最近的小区进行填充。
具体的内容可以多变,但是万变不离其宗,大家可以参考上述填充方法。
对应的填充代码如下:
# 区域缺失填充
df_data_2.loc[df_data_2.index == 28060, ‘区域’] = ‘布吉南岭’
异常数据清洗
在本次数据集中,存在很多不标准的数据格式,例如:房屋总价的单位、房屋面积等,我们暂且称之为异常数据
参考总价/单价处理
通过简单的汇总查看总价和单价分布情况
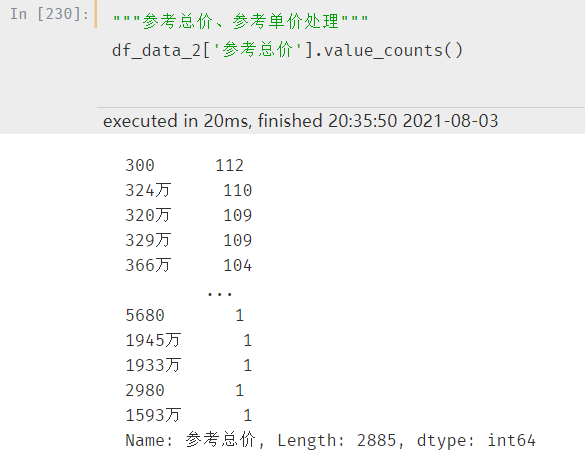
可以看到参考总价有两种形式,带单位的和不带单位的,一般处理都是直接确定成数值(方便在回归模型中应用)
同理,参考单价字段可以采用同样的处理方式。但是单价的单位是具体到元的,需要注意应该和总价的单位保持一致
ok,一行代码可以搞定:
# 统一单位
df_data_2[‘参考总价’] = df_data_2[‘参考总价’].apply(lambda x: x.replace(“万”, “”))
df_data_2[‘参考单价’] = df_data_2[‘参考单价’].apply(lambda x: int(x.replace(“元/平米”, “”))/10000)
df_data_2[‘参考总价’] = df_data_2[‘参考总价’].astype(dtype=‘float’)
df_data_2[‘参考单价’] = df_data_2[‘参考单价’].astype(dtype=‘float’)
需要注意原始数据类型默认是 Object,也就是字符类型,但是在我们处理之后已经变成了数值类型,所以在后续的处理中为了避免计算出错,直接将其格式进行转换。
更需要注意的是:总价的单位。因为发现有部分房屋的总价小于10w,谨慎起见把小于10w的房屋单独列出来观察一下
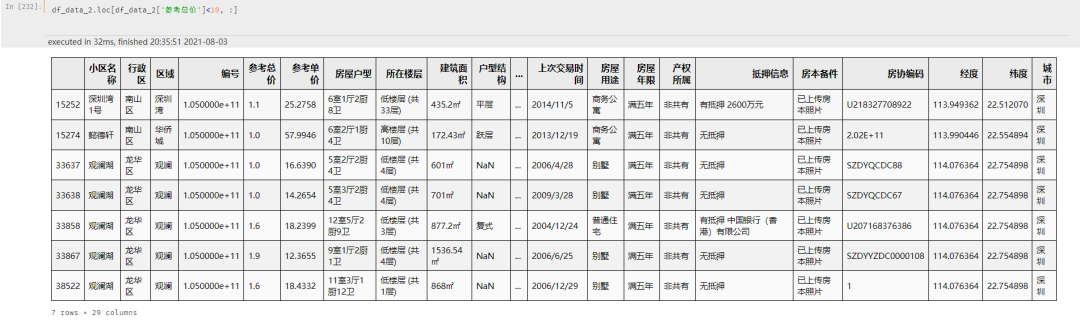
可以看到,并不是总价标错了,而是这些房屋总价的单位是亿,并不是w,所以需要对这部分房屋的总价进行处理
df_data_2.loc[df_data_2[‘参考总价’]<10, ‘参考总价’] = df_data_2.loc[df_data_2[‘参考总价’]<10, ‘参考总价’]*10000
房屋户型处理
同样通过汇总的方式查看户型分布:
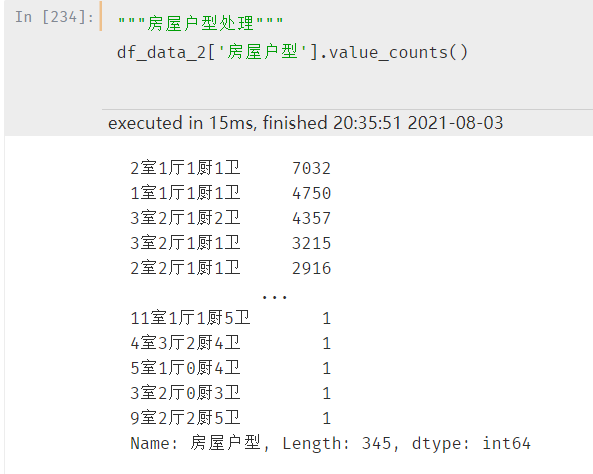
房屋户型的格式是:xx室xx厅xx厨xx卫,一共有345种户型布局。但是实际上并没有这么多,需要注意
一般我们在说户型的时候,都只是说 xx室xx厅,很少去关注后面的厨房和卫生间个数。
所以一种思路是只取前两个属性,另一种思路是把每一个属性的个数当做一个单独的字段(拆分下来也就是4个字段)
当然了上面所有属性的个数加在一起可以组成一个新的字段,至于这个字段对于模型具体有没有用最终可以通过贡献度来决定。
这里,我直接采用第一种思路
# 因为不确定xx室xx厅中的数字具体是几位数,所以采用正则匹配的方式
import re
df_data_2[‘房屋户型’] = df_data_2[‘房屋户型’].apply(lambda x: re.findall(r"\d+室\d+厅", x)[0])
房屋楼层处理
同样采用汇总的方式查看分布:
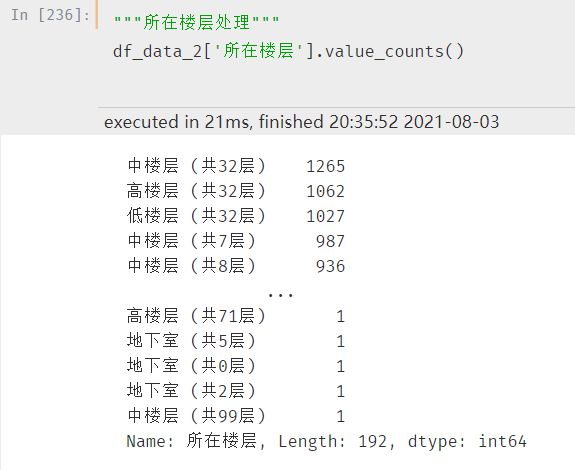
同样的可以用两种处理方式:一种是直接取描述性数据,例如中楼层、高楼层。一种是将通过总楼层,将对应的中楼层进行计算。
例如:总楼层是7层,1-2是低楼层、3-5是中楼层、6-7是高楼层
这样做的好处是将楼层的高度统一到一个层级,但是也会相对的失真,毕竟不同总高的楼总体价格都是差别很大的
这里,为了方便计算,直接采用第一种思路
# 注意分隔符,是:空格+左括号。细节!!!
df_data_2[‘所在楼层’] = df_data_2[‘所在楼层’].apply(lambda x: x.split(" (")[0])
房屋面积处理
同样采用汇总的方式查看分布:
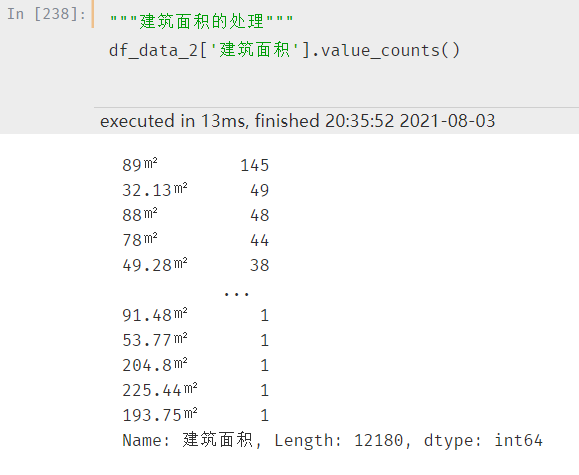
将对应的 ㎡ 剔除掉,保证字段为数值类型
需要注意的是有部分数据为空的,官方标记的是“暂无数据”,这部分我们需要进行缺失值填充。填充的方式上面也有提到过,通过该房屋对应的户型,最好是同小区下对应的户型的建筑面积进行填充
另外,“套内面积”字段也是同样的情况,在此一并进行处理
主要代码如下:
# 统一单位
df_data_2[‘建筑面积’] = df_data_2[‘建筑面积’].apply(lambda x: x.replace(“㎡”, “”))
df_data_2[‘套内面积’] = df_data_2[‘套内面积’].apply(lambda x: x.replace(“㎡”, “”))
# 缺失值填充
df_data_2.loc[df_data_2[‘建筑面积’]‘暂无数据’, ‘建筑面积’] = df_data_2.loc[df_data_2[‘建筑面积’]‘暂无数据’, [‘小区名称’, ‘房屋户型’, ‘建筑面积’]].apply(lambda x: get_nan_info(“小区名称”, “房屋户型”, x[0], x[1], df_data_2, target_col=“建筑面积”, target_value=x[2]), axis=1)
df_data_2.loc[df_data_2[‘套内面积’]‘暂无数据’, ‘套内面积’] = df_data_2.loc[df_data_2[‘套内面积’]‘暂无数据’, [‘小区名称’, ‘房屋户型’, ‘套内面积’]].apply(lambda x: get_nan_info(“小区名称”, “房屋户型”, x[0], x[1], df_data_2, target_col=“套内面积”, target_value=x[2]), axis=1)
但是套内面积的缺失较多,有 15684 条数据,在进行上一步的准确填充之后,当前仍有 8746 条缺失数据
可以进一步扩大,采用深圳市同户型房屋的平均面积进行填充,更进一步的,可使用处理后的房屋户型的平均面积进行填充
但是由于部分户型只有个位数的数据记录,如下图:
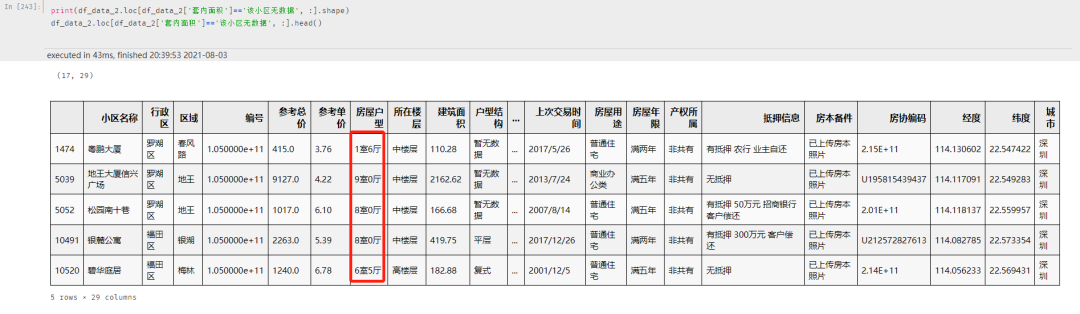
仍旧存在 17 条数据存在缺失,都是属于户型超出正常范围的房屋,例如:1室6厅、9室0厅、8室0厅 这种
为了方便起见,直接用建筑面积填充套内面积即可
df_data_2.loc[df_data_2[‘套内面积’]‘该小区无数据’, “套内面积”] = df_data_2.loc[df_data_2[‘套内面积’]‘该小区无数据’, “建筑面积”]
# 手动更改数据类型
df_data_2[‘建筑面积’] = df_data_2[‘建筑面积’].astype(dtype=‘float’)
df_data_2[‘套内面积’] = df_data_2[‘套内面积’].astype(dtype=‘float’)
房屋其他属性处理
同样采用汇总的方式查看分布:
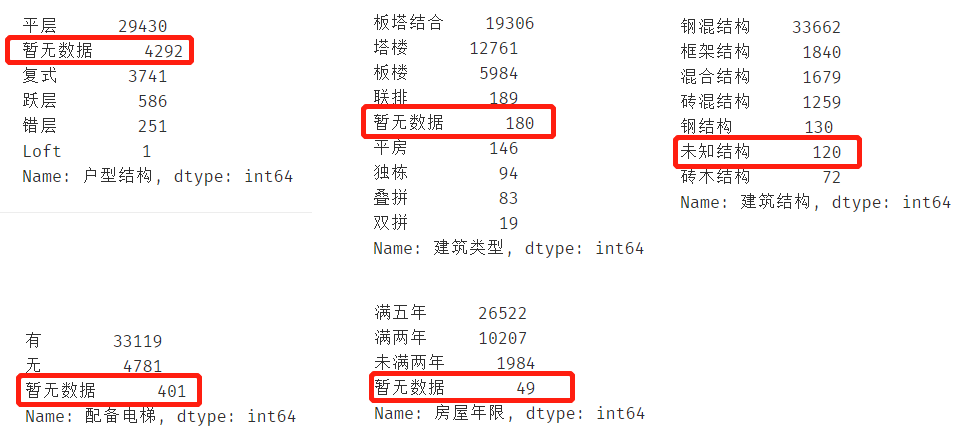
其中:
-
建筑类型、房屋年限字段存在标记为“暂无数据”的缺失值,
-
建筑结构存在标记为“未知结构”的缺失值
-
梯户比例存在NAN缺失(需要NAN检测)
-
户型结构、配备电梯字段存在以上两种类型的缺失值,需要进行处理
处理方式参考上面房屋面积的处理,只需要改动部分代码即可
房屋抵押信息处理
同样采用汇总的方式查看分布:
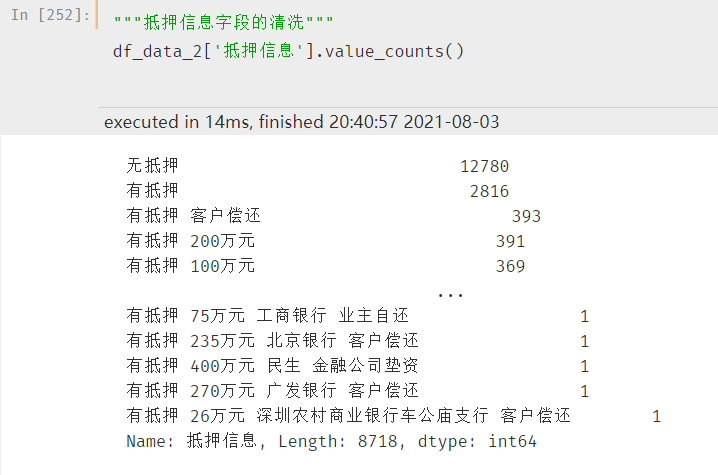
抵押信息看似很多,但是其实说白了就两种,有抵押和无抵押,直接进行处理即可
具体代码如下:
df_data_2.loc[df_data_2[‘抵押信息’]==‘暂无数据’, ‘抵押信息’] = “未知”
df_data_2[‘抵押信息’] = df_data_2[‘抵押信息’].apply(lambda x: x[0:3])
可视化分析与探索
可视化部分属于非必要内容,它的作用主要是通过绘图的方式发现数据中存在的隐形问题。
比如说:通过可视化发现数值中的极大极小值;通过可视化发现特征和结果之间的规律;通过可视化发现特征之间的相关性等。
但是切记不要为了可视化而可视化**,可视化探索的目的是为了发现问题,进而方便在特征工程中进行深层的特征挖掘,而不是为了绘图的美观!**
如果你数据量不大,能用 Excel 绘图就没必要用 matplotlib,代码绘图推荐用 seaborn 包,方便高效
可视化探索部分因为篇幅原因,具体的绘图代码就不贴出来了,感兴趣的可以加小一好友获取
区域存量分布
绘图如下:
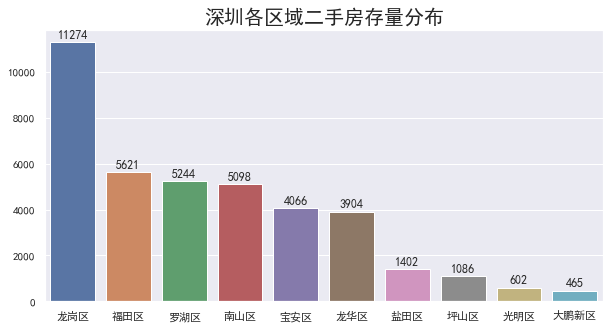
其中,龙岗区以 11274套 二手房的存量遥遥领先,接下来是福田区、罗湖区、南山区等关内区域
从二手房的存量来看,龙岗区是目前最为火热的区域,虽然地处深圳市的关外区域,但是由于区域面积大,且4号线延长线、10号线等地铁线路的开通,交通便利的同时带动了整个区域的发展
如此看来,宝安、龙华、坪山、光明等关外区域的发展似乎也会慢慢加速
片区存量分布
绘图如下:
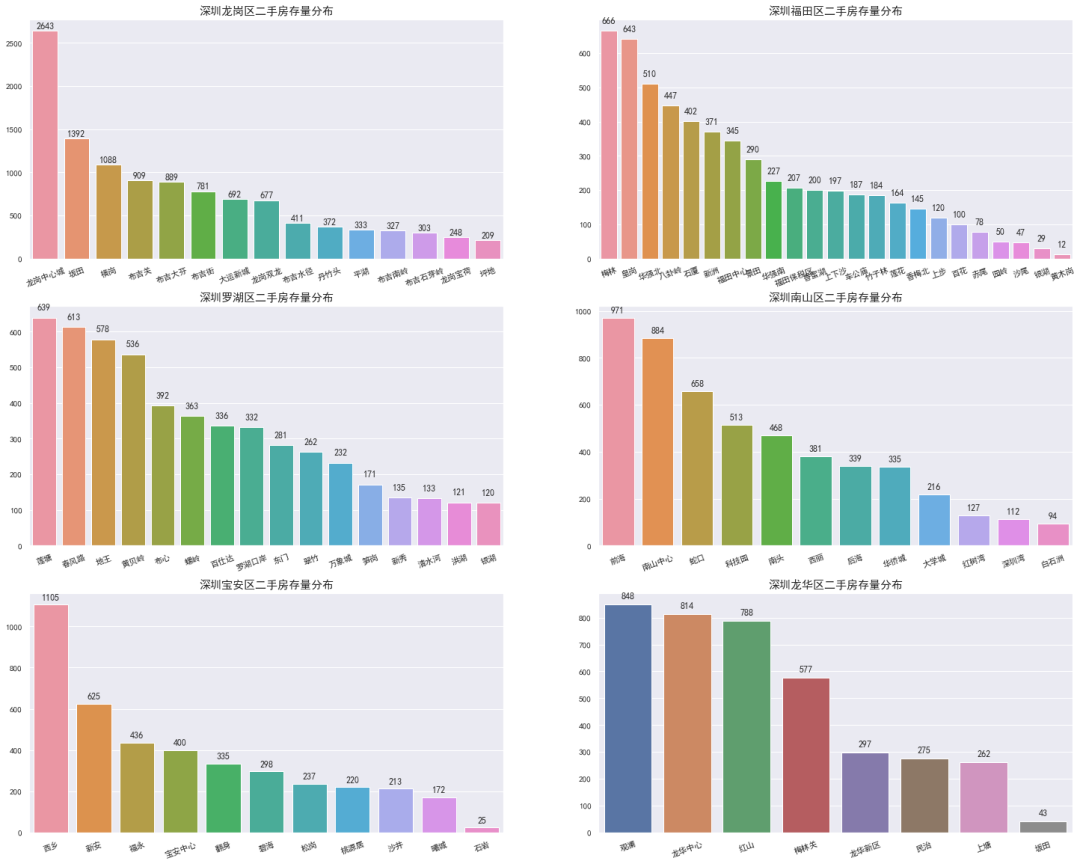
其中,龙岗区以龙岗中心城为主要二手房存量区域,达到2643套,较第二名坂田区域的存量多了近一倍
福田区域二手房存量排行前三则分别是:梅林(666)皇岗(643)和华强北(510)****
罗湖区域二手房存量排行前三分别是:莲塘(639)春风路(613)和地王(578)****,和福田区域的数量比较相近,毕竟是两个不相上下的中心区域
南山区二手房存量排行前三分别是:前海(971)南山中心(884)和蛇口(658)****,前三的存量差异较大
宝安区和龙华区做为出龙岗以外的两个关外区域,整体存量分布相近的情况下,区域差异较明显
其中,宝安区二手房存量排名前三分别是:西乡(1105)新安(625)福永(436);龙华区二手房存量排名前三分别是:观澜(848)龙华中心(814)红山(788)****
小总结 :龙岗区和宝安区的整体分布差异比较相似,而关内三大区域(福田、南山、罗湖)的整体分布差异比较相似
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-i8IS0GIN-1712841963470)]















 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









