







Hadoop特性优点
扩容能力:Hadoop是在可用的计算机集群间分配数据并完成计算任务,这些集群可以方便的扩展到数以千计的节点中
成本低:Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低
高效率:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快
**可靠性:**能自动维护数据的多份复制,并且在任务失败后能自动的重新部署计算任务,所以Hadoop的按位存储和处理数据的能力值得人们信赖
集群简介
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群负责海量数据存储,集群中的主要角色有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的主要角色有:
ResourceManager、NodeManager
Mapreduce是一个分布式运算编程框架,是应用程序开发包,有用户按照编程规范进行程序开发后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理
Hadoop部署方式分为三种:Standalone mode(独立模式)、Pseudo-Distributed mode(伪分布式模式)、Cluster mode(集群模式),其中前两种都是在单机部署
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试
伪分布式也是在1个机器上运行HDFS的Namenode和DataNode、YARN的ResourceManager和NodeManager,但分别启动单独的java进程,主要用于调试
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上
服务器系统设置
同步时间
查看系统时间命令:date
手动同步集群各机器时间
命令:date -s “2020-02-15 13:10:33”
网络同步时间
命令
yum install ntpdate
ntpdate http://cn.pool.ntp.org
设置主机名
编辑文件命令:vi /etc/sysconfig/network
在文件中编写如下内容
NETWORKING=yes
HOSTNAME=node01
配置IP、主机名映射
编辑文件命令:vi /etc/hosts
在文件中配置如下内容:
192.168.149.101 node01
192.168.149.102 node02
192.168.149.103 node03
192.168.149.104 node04
配置ssh免密登录
一般配置主节点到从节点的免密登录
生成ssh免登录秘钥
命令:ssh-keygen -t rsa,输入完命令之后按四次enter键
执行完这个命令后,会生成id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
如:在node01机器上拷贝node02公钥:ssh-copy-id node02
拷贝完成之后,在node01上就可以免密登录node02
配置node03免密登录
同上操作配置node04免密登录
Hadoop安装包目录结构
bin包:Hadoop最基本的管理脚本和使用脚本的目录
etc包:Hadoop配置文件所在目录
include包:对外提供的编程库头文件(具体动态库和静态库在lib目录中)
lib包:该目录包含了Hadoop对外提供的编程动态库与静态库,与include目录中的 头文件结合使用
libexec包:各个服务对用的shell配置文件所在的目录,可用于配置日志输出、启 动参数等基本信息
sbin包:Hadoop管理脚本所在目录,主要包含HDFS和YARN中各类服务的启动/ 关闭脚本
share包:Hadoop各个模块编译后的.jar包所在目录
Hadoop3分布式安装
上传hadoop-3.2.1.tar.gz到node01服务器
解压安装包命令:tar -zxvf hadoop-3.2.1.tar.gz
删除hadoop-3.2.1.tar.gz压缩包命令:rm -f hadoop-3.2.1.tar.gz
Hadoop配置文件修改
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,修改完毕后下发给其他各个从节点机器
进入hadoop配置文件目录中去
命令:cd hadoop-3.2.1/etc/hadoop/
配置hadoop-env.sh文件
文件中设置的是Hadoop运行时需要的环境变量,JAVA_HOME是必须设置的
找到jdk安装路径地址
命令:echo $JAVA_HOME
/usr/java/jdk1.8.0_60
编辑hadoop-env.sh文件命令:vi hadoop-env.sh
在该文件中需要配置jdk的环境变量,并指定NameNode、DataNode、SecondaryNameNode使用的用户,一般是root
export JAVA_HOME=/usr/java/jdk1.8.0_60
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=root
配置core-site.xml文件
hadoop的核心配置文件,有默认的配置项core-default.xml
指定HADOOP所使用的文件系统schema,HDFS的老大(NameNode)的地址
如何配置?
打开hadoop-3.2.1—share----doc—hadoop----index.html文件
在打开的网页中点击Single Node Setup
找到core-site.xml的配置语句
修改成如下代码,hadoop3默认端口为9820
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-&{user.name}
tmp目录会未经过同意,直接删除其中的文件,所以需要重新定义一个文件存储目录
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hdata/hddata</value>
</property>
配置hdfs-site.xml文件
指定HDFS副本的数量,默认备份3份
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
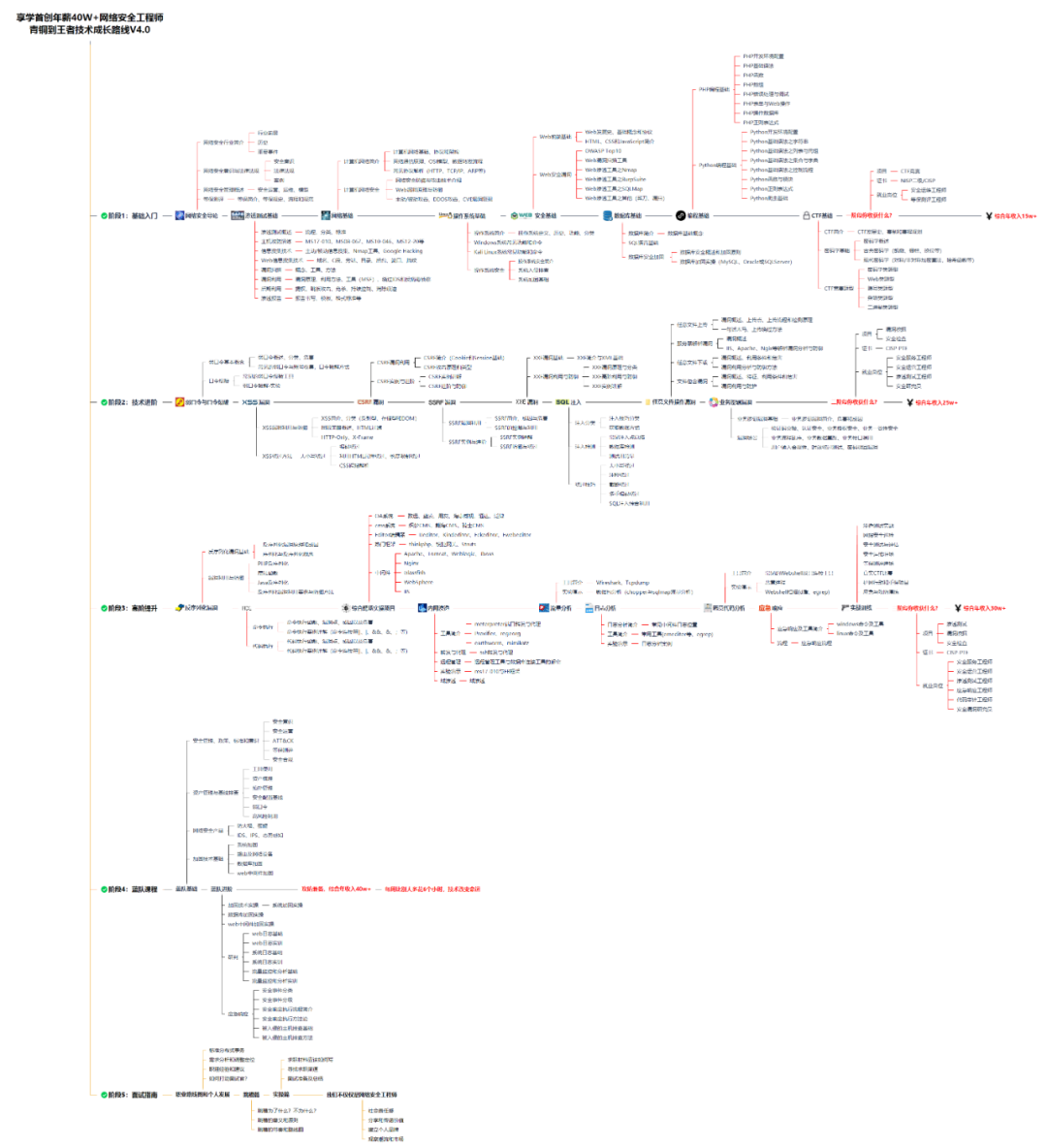
### 一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
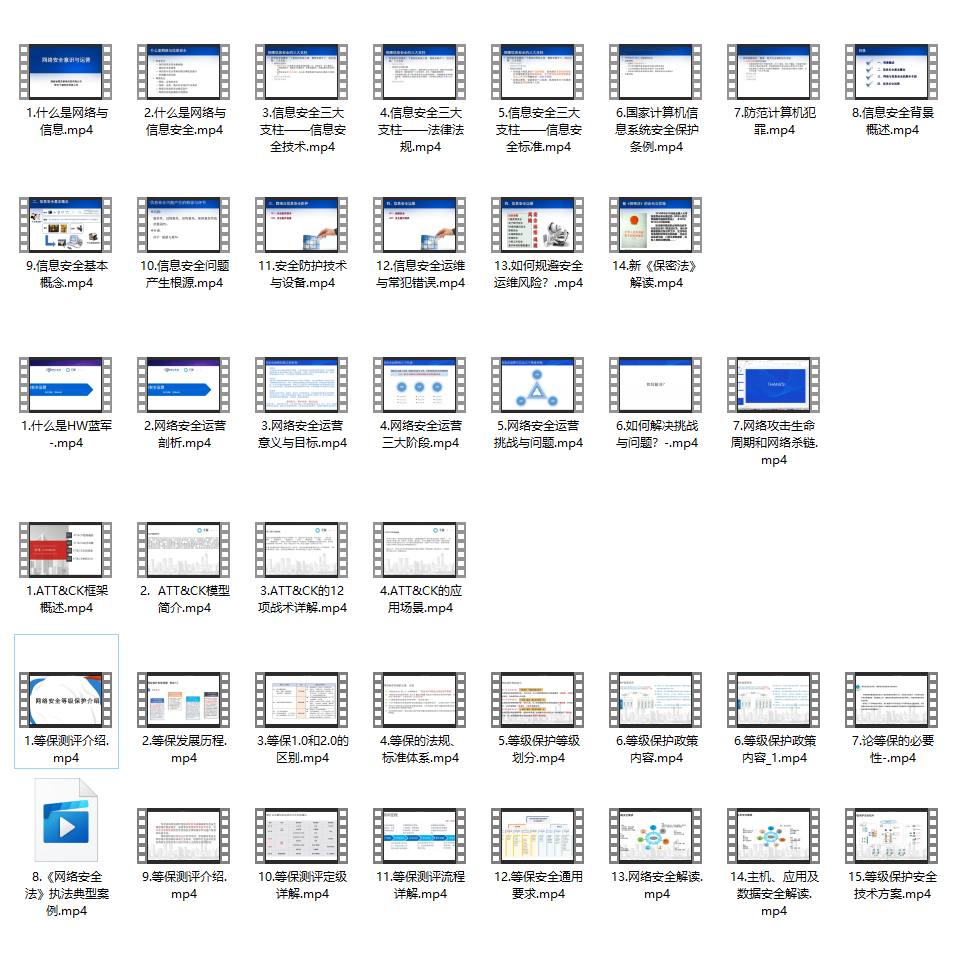
### 二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
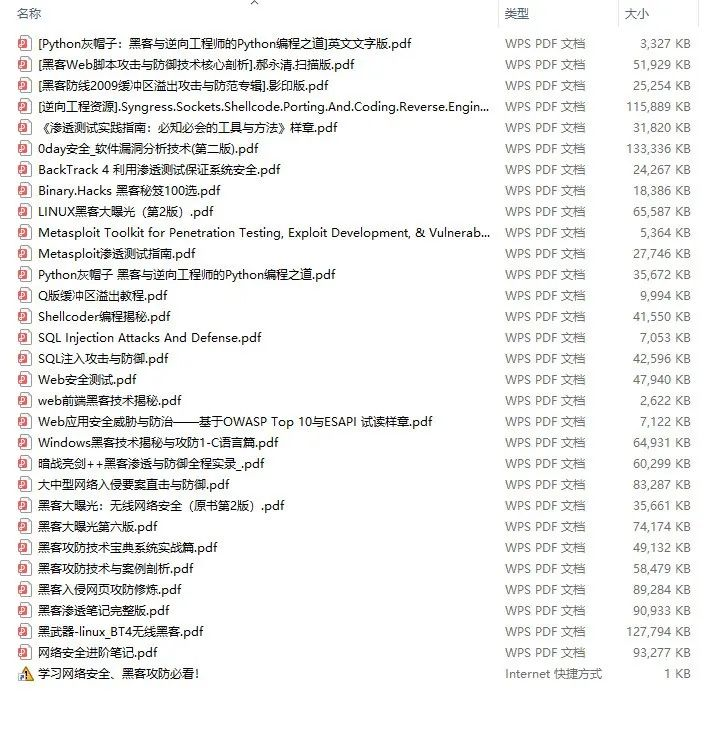
### 三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
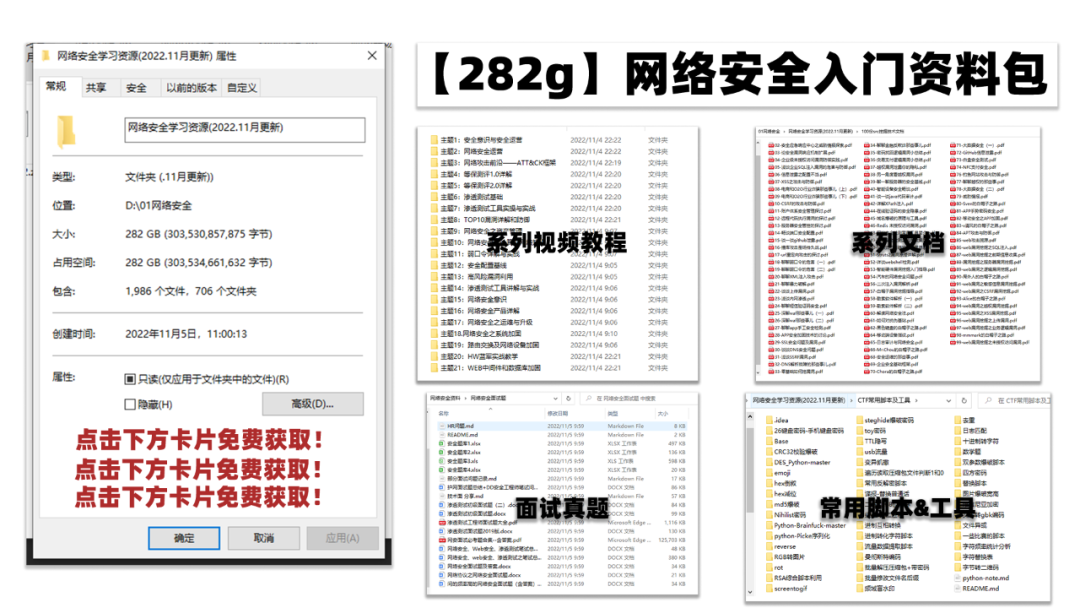
### 四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









