







// 通过RequestManagerFragment获取RequestManager
RequestManager requestManager = current.getRequestManager();
if (requestManager == null) {
Glide glide = Glide.get(context);
// 如果RequestManager为空,则通过抽象工厂来创建RequestManger
requestManager =
factory.build(
glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode(), context);
// 判断当前页面是否是可见的,是的话则回调开始方法;
if (isParentVisible) {
requestManager.onStart();
}
// 将RequestManager设置给了fragment
current.setRequestManager(requestManager);
}
return requestManager;
}
这里面的实现没有很复杂,就做了两件事,创建不可见的RequestManagerFragment,创建RequestManager,并将RequestManger设置给RequestManagerFragment,而RequestManagerFragment里面生命周期的回调,都会回调到RequestManager里;
这样就让RequestManager有了生命周期的监听;
这里的Lifecycle不是Jectpack的Lifecycle组件,而是自己定义的一个监听,用于回调生命周期;
这里有哪个优化细节值得探讨的呢?
这个细节就在于RequestManagerFragment的创建;
RequestManagerFragment的创建,并不是每次获取都会重新创建的;
总共有三步逻辑,请看下面的源码
private RequestManagerFragment getRequestManagerFragment(
@NonNull final android.app.FragmentManager fm, @Nullable android.app.Fragment parentHint) {
// 先通过FragmentManager来获取对应的fragment
RequestManagerFragment current = (RequestManagerFragment) fm.findFragmentByTag(FRAGMENT_TAG);
// 如果获取为空,则从一个HashMap集合中获取;
if (current == null) {
current = pendingRequestManagerFragments.get(fm);
// 如果从集合中获取为空,那么就新建一个Fragment并添加到页面去,然后再将其放到HashMap中,并发送消息,将该Fragment从HashMap中移除掉;
if (current == null) {
current = new RequestManagerFragment();
current.setParentFragmentHint(parentHint);
…
fm.beginTransaction().add(current, FRAGMENT_TAG).commitAllowingStateLoss();
…
}
}
return current;
}
这里主要做了两步操作:
第一步:通过FragmentManager来查找Fragment,如果获取到了则返回;
第二步:第一步没有获取到Fragment,则新建一个Fragment,将其添加到页面;
在RequestManagerFragment的生命周期方法里,通过lifecycle进行回调,而RequestManger注册了这个监听,那么就可以获取到生命周期;
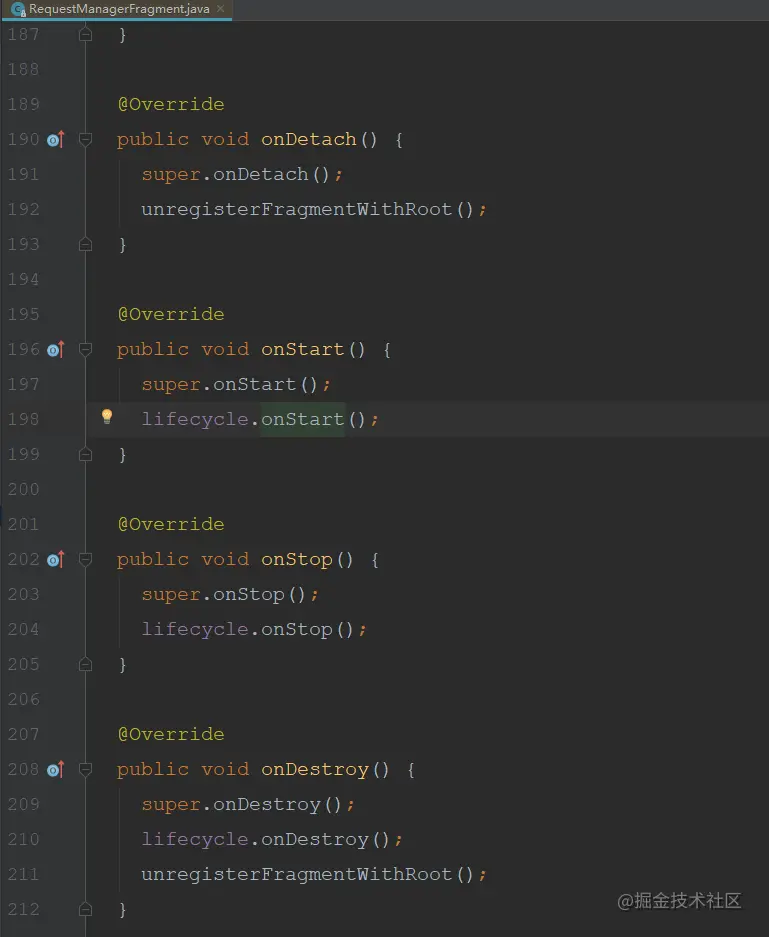
最终在RequestManger的生命周期里,开启了图片的加载和停止的操作;
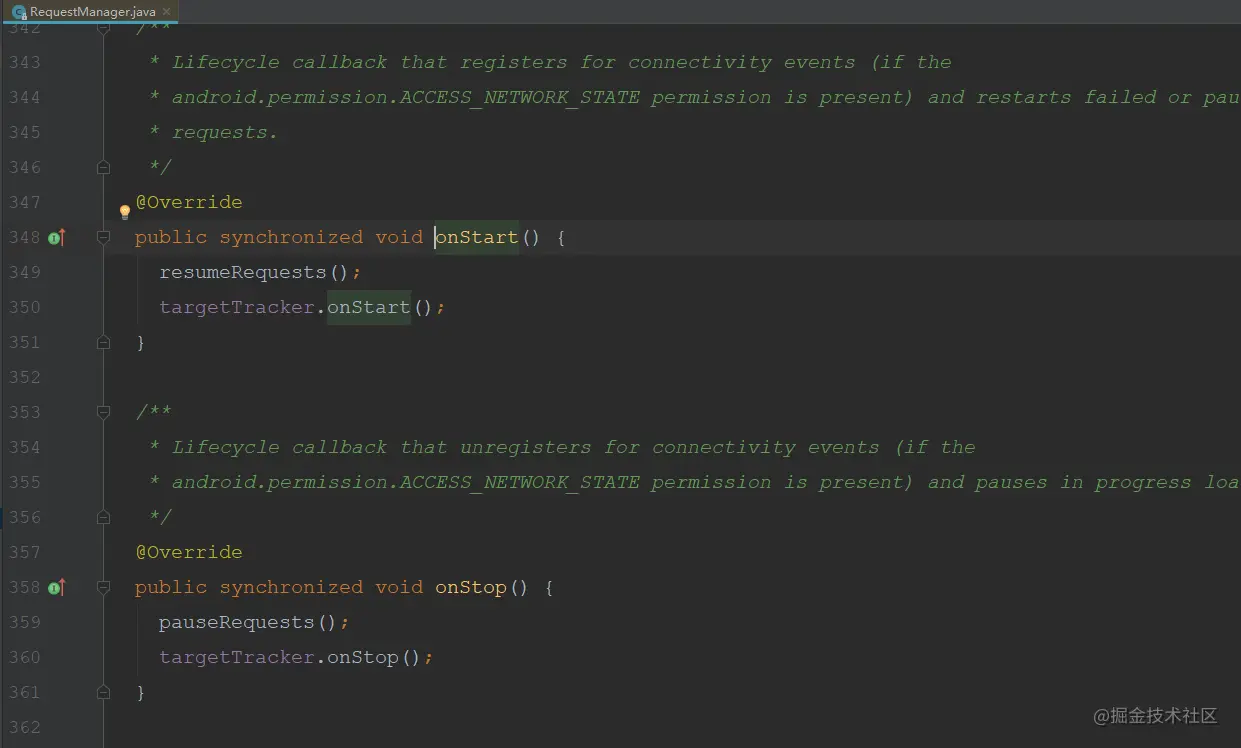
4.2、RequestBuilder
RequestBuilder的职责很明确,用于创建获取图片的请求;
这个类使用了建造者模式来构建参数,这样有一个好处就是,可以很方便的添加各种各样复杂的参数;
这个RequestBuilder没有build方法,但是有into方法,原理其实一样,没有说一定要写成build;
最终加载图片的逻辑,就是在into方法里面实现的;
private <Y extends Target> Y into(
@NonNull Y target,
@Nullable RequestListener targetListener,
BaseRequestOptions<?> options,
Executor callbackExecutor) {
…
// 创建图片请求
Request request = buildRequest(target, targetListener, options, callbackExecutor);
// 获取当前图片控件是否已经有设置图片请求了,如果有且还没有加载完成,
// 或者加载完成但是加载失败了,那么就将这个请求再重新调用begin,再一次进行请求;
Request previous = target.getRequest();
if (request.isEquivalentTo(previous)
&& !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) {
…
if (!Preconditions.checkNotNull(previous).isRunning()) {
…
previous.begin();
}
return target;
}
//清除当前图片控件的图片请求
requestManager.clear(target);
// 设置请求给控件
target.setRequest(request);
// 再将请求添加到requestManager中
requestManager.track(target, request);
return target;
}
这里有两个细节:
第一个细节:
在开始请求之前,会先获取之前的请求,如果之前的请求还没有加载完成,或者加载完成了但是加载失败了,那么则会再次重试请求;
第二个细节:
将请求设置给了封装了图片控件的target,这样做有什么好处呢?
我们的页面大多数都是列表页,那么基本上会使用RecycleView这种列表控件来加载数据,而这种列表在加载图片的时候,快速滑动时会出现加载错乱的问题,其原因是RecycleView的Item复用的问题;
而Glide就是在这里通过这样的操作来避免这样的问题;
在调用setRequest的时候,将当前的Request作为tag设置给了View,那么在获取Request进行加载的时候,就不会出现错乱的问题;
private void setTag(@Nullable Object tag) {
…
view.setTag(tagId, tag);
}
4.3、Engine
从上面我们知道,一切的请求都是在Request的begin里开始的,而其实现是在SingleRequest的begin里面,最终会走到SingleRequest的onSizeReady里,通过Engine的load来加载图片数据;
这个load方法主要分为两步:
第一步:从内存加载数据
第二步:从磁盘或者网络加载数据
public LoadStatus load(…) {
…
synchronized (this) {
// 第一步
memoryResource = loadFromMemory(key, isMemoryCacheable, startTime);
// 第二步
if (memoryResource == null) {
return waitForExistingOrStartNewJob(
glideContext,
model,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
options,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache,
cb,
callbackExecutor,
key,
startTime);
}
}
…
return null;
}
简单回顾一些,我上面设计了一个LruResourceCache的类来做内存缓存,里面使用了LRU算法;
相较于我们上面设计的从内存加载数据的逻辑,Glide这里的细节体现在哪里呢?
private EngineResource<?> loadFromMemory(
EngineKey key, boolean isMemoryCacheable, long startTime) {
…
// 从弱引用里获取图片资源
EngineResource<?> active = loadFromActiveResources(key);
if (active != null) {
…
return active;
}
// 从LRU缓存里面获取图片资源
EngineResource<?> cached = loadFromCache(key);
if (cached != null) {
…
return cached;
}
return null;
}
首先第一个细节:
Glide设计了一个弱引用缓存,当从内存里面加载时,会先从弱引用里面获取图片资源;
为什么要多设计一层弱引用的缓存呢?
这里要说一下弱引用在内存里面的机制,弱引用对象在Java虚拟机触发GC时,会回收弱引用对象,不管此时内存是不是够用!
那么设计了一个弱引用缓存的好处在于,没有触发GC的这段时间,可以重复的利用图片资源,减少从LruCache里的操作;
看一下源码最终调用的地方:
synchronized EngineResource<?> get(Key key) {
// 根据Key获取到了一个弱引用对象
ResourceWeakReference activeRef = activeEngineResources.get(key);
if (activeRef == null) {
return null;
}
EngineResource<?> active = activeRef.get();
…
return active;
}
第二个细节:
从LruCache里获取图片资源后,并将其存入到弱引用缓存里;
private EngineResource<?> loadFromCache(Key key) {
//
EngineResource<?> cached = getEngineResourceFromCache(key);
if (cached != null) {
cached.acquire();
activeResources.activate(key, cached);
}
return cached;
}
还有一个操作就是在图片加载完成之后,会将该图片资源存入到弱引用缓存里,以便后续复用;
其源码位置在这里调用:Engine的onEngineJobComplete;
而这个方法是在图片加载的回调里调用的,也就是EngineJob的onResourceReady
public synchronized void onEngineJobComplete(
EngineJob<?> engineJob, Key key, EngineResource<?> resource) {
…
if (resource != null && resource.isMemoryCacheable()) {
// 存入到弱引用缓存里
activeResources.activate(key, resource);
}
…
}
其实这两个细节,都是由弱引用缓存来引入的,正是因为多了一个弱引用缓存,所以才能把图片的加载性能压榨到了极致;
有人会说,加了这个有啥用呢? 又不能快多少。
俗话说的好:性能都是一步步压榨出来的,在能优化的地方优化一点点,渐渐的积累,也就成河流了!
如果上面都获取不到图片资源,那么接下来就会从磁盘或者网络加载数据了;
4.4、DecodeJob
从磁盘或者网络读取,必然是一个耗时的任务,那么肯定是要放在子线程里面执行,而Glide里也正是这样实现的;
来看下大致的源码:
最终会创建一个叫DecodeJob的异步任务,来看下这个DecordJob的run方法做了什么操作?
public void run() {
…
runWrapped();
…
}
run方法里面主要有一个runWrapped方法,这个方法才是最终执行的地方;
在这个com.bumptech.glide.load.engine.DecodeJob#getNextGenerator方法里面,会获取内存生产者Generator,这几个内容生产者分别对应着不同的缓存数据;
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
…
}
}
4.5、DataCacheGenerator
ResourceCacheGenerator:对应转化后的图片资源生产者;
DataCacheGenerator:对应没有转化的原生图片资源生产者;
SourceGenerator:对应着网络资源内容生产者;
这里我们只关心从磁盘获取的数据,那么则对应着这个ResourceCacheGenerator和这个DataCacheGenerator的生产者;
这两个方法的实现差不多,都是通过获取一个File对象,然后再根据File对象来加载对应的图片数据;
从上面我们可以知道,Glide的磁盘缓存,是从DiskLruCache里面获取的;
下面我们来看一下这个DataCacheGenerator的startNext方法;
public boolean startNext() {
while (modelLoaders == null || !hasNextModelLoader()) {
sourceIdIndex++;
…
Key originalKey = new DataCacheKey(sourceId, helper.getSignature());
// 通过生成的key从DiskLruCache里面获取File对象
cacheFile = helper.getDiskCache().get(originalKey);
if (cacheFile != null) {
this.sourceKey = sourceId;
modelLoaders = helper.getModelLoaders(cacheFile);
modelLoaderIndex = 0;
}
}
…
while (!started && hasNextModelLoader()) {
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
loadData =
modelLoader.buildLoadData(
cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
这里主要分为两步:
第一步是通过生成的key从DiskLruCache里面获取File对象;
第二步是将File对象,通过LoadData将File对象转化为Bitmap对象;
第一步:获取File对象
Glide在加载DiskLruCache的时候,会将所有图片对应的路径信息加载到内存中,当调用DiskLruCache的get方法时,其实是从DiskLruCache里面维护的一个Lru内存缓存里直接获取的;
所以第一步的get方法,其实是从LruCache内存缓存里面获取File对象的;
这个处理逻辑是在DiskLruCache的open方法里面操作的,里面会触发一个读取本地文件的操作,也就是DiskLruCache的readJournal方法;
最终走到了readJournalLine方法;
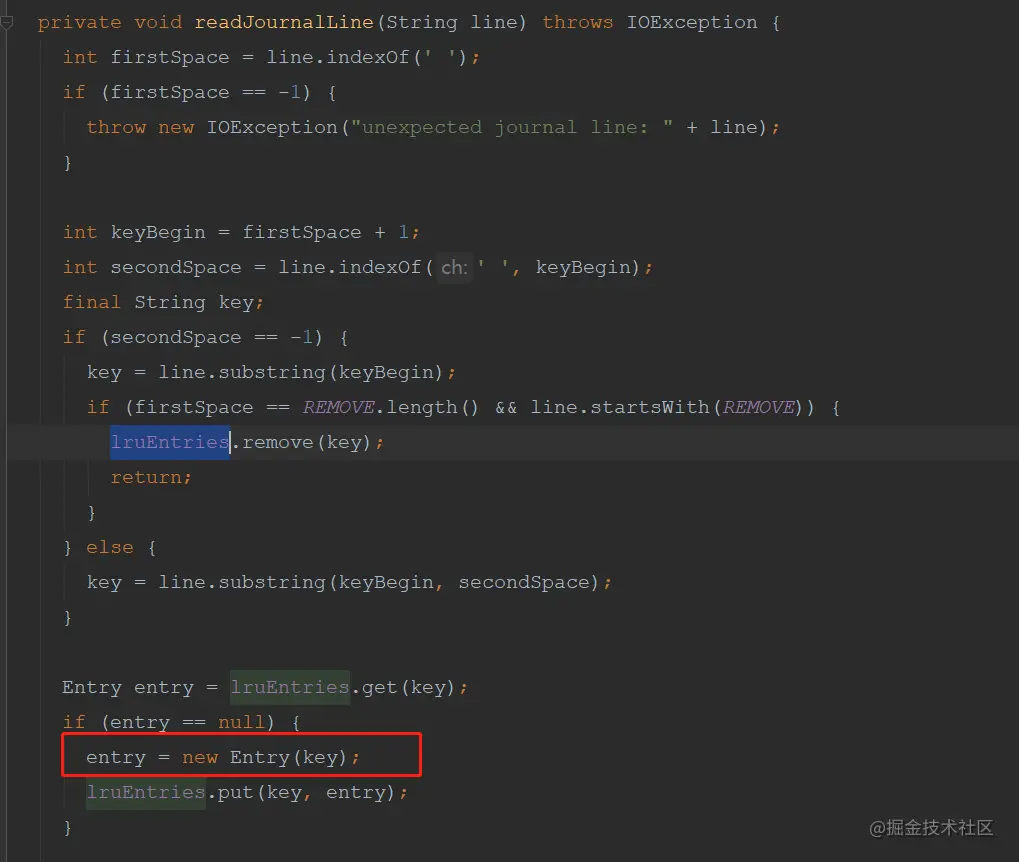
这个文件主要存放了图片资源的key,用于获取本地图片路径的文件;
最终是在DiskLruCache的readJournalLine方法里面,会创建一个Entry对象,在Entry对象的构造方法里面创建了File对象;
private Entry(String key) {
…
for (int i = 0; i < valueCount; i++) {
// 创建图片文件File对象
cleanFiles[i] = new File(directory, fileBuilder.toString());
fileBuilder.append(“.tmp”);
dirtyFiles[i] = new File(directory, fileBuilder.toString());
…
}
}
到这里你是否会有疑问了,如果我是在DiskLruCache初始化之后下载的图片呢? 这时候DiskLruCache的Lru内存里面肯定没有这个数据,那这个数据是哪来的?
相信聪明的你已经猜到了,就是图片文件在存入本地的时候也会将其加入到DiskLruCache的Lru内存里;
其实现是在DiskLruCache的edit()方法;
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
…
Entry entry = lruEntries.get(key);
…
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
}
…
Editor editor = new Editor(entry);
entry.currentEditor = editor;
…
return editor;
}
这里先把生成的Entry对象加入到内存中,然后再通过Editor将图片文件写入到本地,通过IO操作,这里就不多赘述了;
存的方法有了,来看一下DiskLruCache的get方法吧;
public synchronized Value get(String key) throws IOException {
…
// 直接通过内存获取Entry对象;
Entry entry = lruEntries.get(key);
…
return new Value(key, entry.sequenceNumber, entry.cleanFiles, entry.lengths);
}
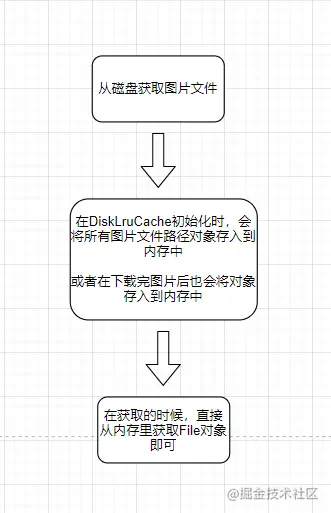
第二步:File对象转化
当根据key拿到File对象时,那么接下来就是将File文件转化为bitmap数据了;
这一段代码的设计非常有意思,下面我们来看一下具体是怎么实现的!
DataCacheGenerator的startNext方法:
public boolean startNext() {
while (modelLoaders == null || !hasNextModelLoader()) {
…
modelLoaders = helper.getModelLoaders(cacheFile);
…
}
while (!started && hasNextModelLoader()) {
// 遍历获取ModelLoader
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
// 获取LoadData
loadData =
modelLoader.buildLoadData(
cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
// 加载数据
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
4.6、ModelLoader
这里通过设计了ModelLoader类,来用于加载数据逻辑;
这一段代码都是基于接口来实现的,没有依赖具体实现,好处就是非常的解耦与灵活,坏处就是代码阅读性降低,因为你很一时半会很难找到这里的实现类到底是哪个!
这个ModelLoader类的职责具体是做什么的呢? 我们可以先来看看注释;

翻译过来的意思就是:将任意复杂的数据模型转换为具体数据类型的工厂接口;
怎么理解这句话呢? 可以理解为适配器模式,将某一类数据转化为另外一类数据;
public interface ModelLoader<Model, Data> {
…
class LoadData {
public final Key sourceKey;
public final List alternateKeys;
public final DataFetcher fetcher;
public LoadData(@NonNull Key sourceKey, @NonNull DataFetcher fetcher) {
this(sourceKey, Collections.emptyList(), fetcher);
}
public LoadData(
@NonNull Key sourceKey,
@NonNull List alternateKeys,
@NonNull DataFetcher fetcher) {
this.sourceKey = Preconditions.checkNotNull(sourceKey);
this.alternateKeys = Preconditions.checkNotNull(alternateKeys);
this.fetcher = Preconditions.checkNotNull(fetcher);
}
}
…
@Nullable
LoadData buildLoadData(
@NonNull Model model, int width, int height, @NonNull Options options);
…
boolean handles(@NonNull Model model);
这个类方法很少,里面持有内部类LoadData,LoadData里面又持有接口DataFetcher,DataFetcher的职责就是用于加载数据,里面持有接口方法loadData;
这是一个典型的组合模式,可以在不改变类结构的情况下,让这个类具有更多的功能;
ModelLoader还有一个接口方法buildLoadData,用于构建LoadData对象;

看到这里,你是否感觉懂了,但是又没完全懂!
是的,尽管我们知道了这里的实现逻辑,但是具体的实现我们并不知道在哪里!
这里使用了两个接口,一个是ModelLoader,一个是DataFetcher,找完ModelLoader的实现,还得找DataFetcher的实现,看起来就非常的绕!
而这一切还是得从ModelLoader讲起;
实现了ModelLoader,也就实现了构建LoadData的方法,在构建LoadData的时候也就构建了DataFetcher对象,而这里的LoadData对象,其实只负责维护DataFetcher等相关变量,最终加载数据的地方还是DataFetcher;
也就是说我们找到了ModelLoader,也就找到了相应的DataFetcher,也就知道了对应的加载逻辑;
这个在设计上叫做啥? 高内聚!同一类相关的实现放在一起,实现了高内聚的封装;
短短几行代码,大牛诠释了什么叫做高内聚,低耦合,先膜拜一下!

接下来我们来看看ModelLoader是怎么获取的;
从上面的源码我们可以看到,ModelLoader是通过DecodeHelper的getModelLoaders方法来获取的,通过传进去的File对象;
最终的调用是通过Registry的getModelLoaders方法来获取ModelLoader列表;
这里有必要来讲一下这个Registry类;
4.7、Registry
这个类的主要职责就是用于保存各种各样的数据,提供给外部使用,你这里可以理解为一个Map集合,存放着各种各样的数据,通过Key值来获取;
只是这个Registry封装的更强大,里面能保存的内容更丰富;

看一下这个类的构造方法,创建了一堆的注册类,用于存放对应的数据;
而这个类的初始化是在Glide的构造方法,注册对应的数据也是在Glide的构造方法;
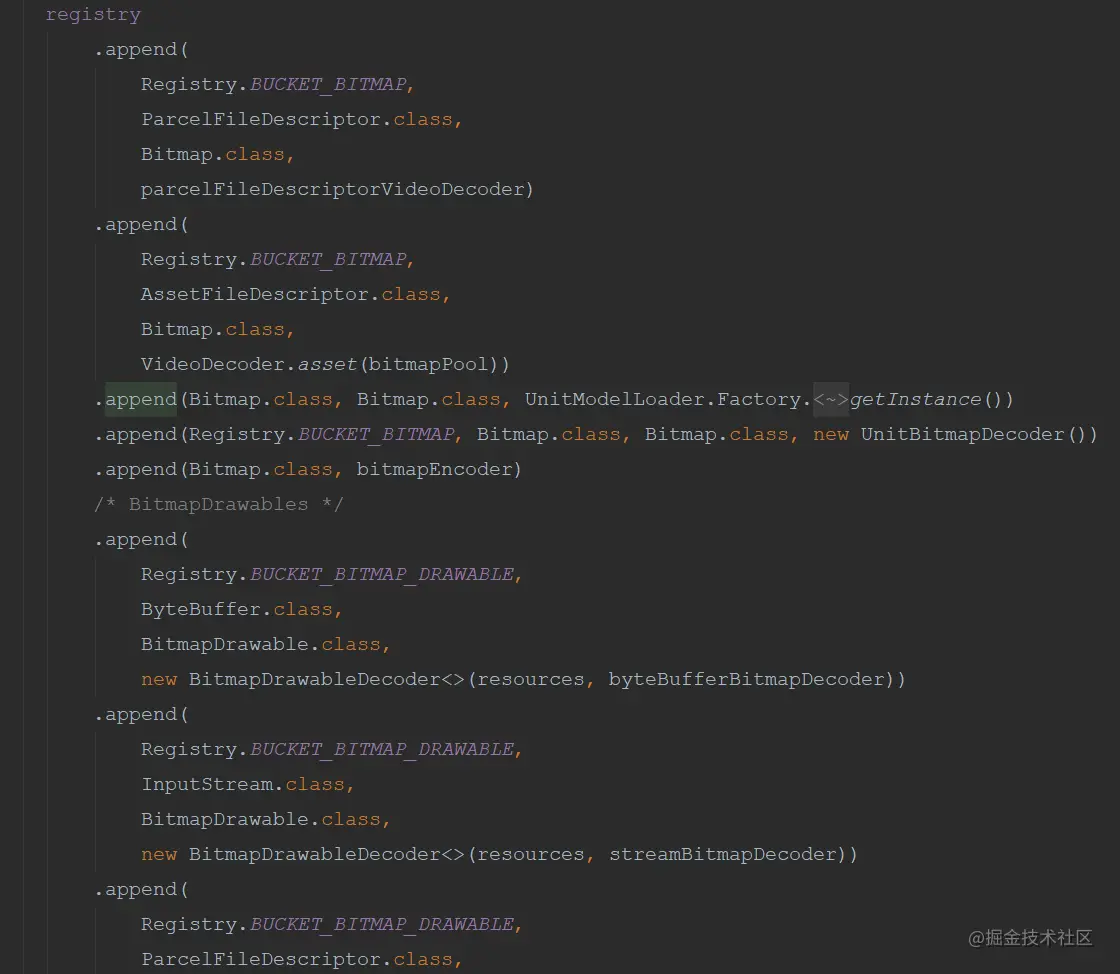
大致瞄一眼,不必太过深入去了解,只需要知道这个类是用于存放注册的数据,提供给外部使用;
当我们通过Registry获取到ModelLoader列表后,就会进行遍历,判断当前的LoadData是否有LoadPath,这个LoadPath我们下面再讲;
这里只需要了解这个类是用来做资源转换的,比如把资源文件转化为Bitmap或者Drawable等等;

当有一个符合的时候,就只会执行一次;
而我们这里最终执行的类是ByteBufferFileLoader;
这个类在loadData执行方法的时候将File对象转化为字节数据ByteBuffer;

看一下大致的实现,不必太过深入了解;
上面我们获取到了文件的流数据,那么接下来怎么将其转化为能展示的bitmap数据呢?
这里就到了解码的阶段了;
上面获取到的字节数据ByteBuffer,最终会回调到DecodeJob这个类,在这里面实现了解码的逻辑;
看一下DecodeJob的onDataFetcherReady方法:
public void onDataFetcherReady(
Key sourceKey, Object data, DataFetcher<?> fetcher, DataSource dataSource, Key attemptedKey) {
…
decodeFromRetrievedData();
…
}
里面调用了decodeFromRetrievedData方法来解码图片流数据;
这里通过LoadPath类来实现解码的功能,
4.8、LoadPath
这个LoadPath类里面实现其实并不复杂,里面持有各种抽象的变量,比如Pool,DecodePath,这个类也是用的组合的模式,里面不持有具体的实现;
而是通过组合的类来进行调用,将实现抽象出来,让这个类可以更灵活的使用;

解码的地方是在这个类的LoadPath的load方法,最终是通过DecodePath的decode方法,具体实现并不在这个类中;
这个DecodePath的设计和LoadPath其实差不多,都是不涉及具体实现,而是通过里面持有的接口来进行调用,进而将具体实现抽象到外部,由外部传入来控制;
来大概看一下这个类的成员变量和构造方法:

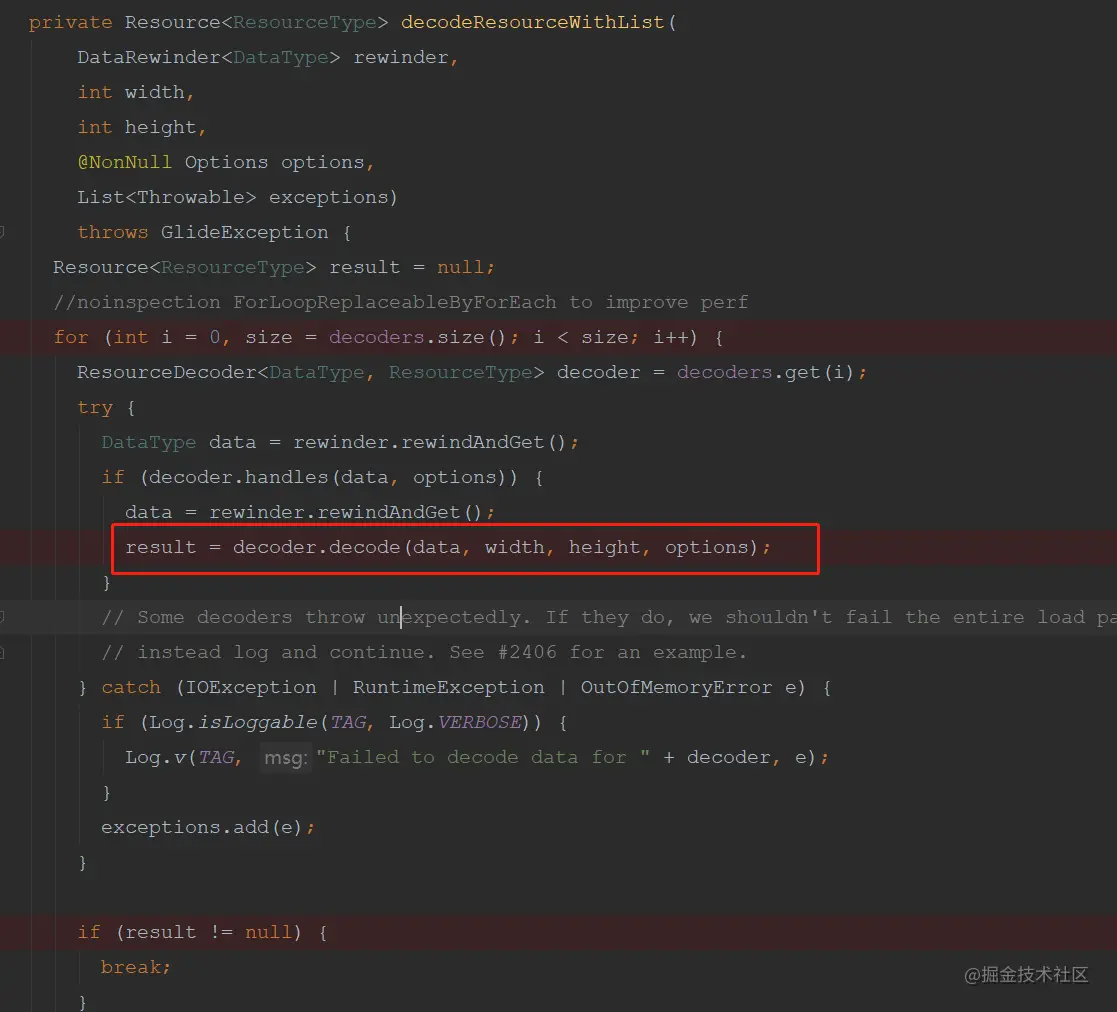
在DecodePath的decode方法里面进行解码,最终调用的地方是通过ResourceDecoder的decode方法 来进行解码;
瞄一下大致的实现;
而这个ResourceDecoder是一个接口,具体实现有很多个类,具体看下面的截图:

最终的实现是在这些类里面;
看一下大致流程图:

这些类是在哪里创建的呢?
我们通过上面的构造方法可以知道,这个类是由外部一步步传进来的;
首先创建LoadPath的时候会将DecodePath传进来,创建DecodePath的时候,又会把ResourceDecoder传进来,那么我们可以先从创建LoadPath的地方找起;
首先是在DecodeJob的decodeFromFetcher方法里,通过DecodeHelper的getLoadPath方法;
private Resource decodeFromFetcher(Data data, DataSource dataSource)
throws GlideException {
LoadPath<Data, ?, R> path = decodeHelper.getLoadPath((Class) data.getClass());
return runLoadPath(data, dataSource, path);
}
在DecodeHelper的getLoadPath里,可以看到,最终是通过Registry类来获取LoadPath;
LoadPath<Data, ?, Transcode> getLoadPath(Class dataClass) {
return glideContext.getRegistry().getLoadPath(dataClass, resourceClass, transcodeClass);
}
上面我们讲过Registry类,这个类是用来保存数据,提供给外部调用的,添加数据的地方是在Glide的构造方法;
下面看一下Registry的getLoadPath方法;
public <Data, TResource, Transcode> LoadPath<Data, TResource, Transcode> getLoadPath(
@NonNull Class dataClass,
@NonNull Class resourceClass,
@NonNull Class transcodeClass) {
// 从缓存里面获取LoadPath
LoadPath<Data, TResource, Transcode> result =
loadPathCache.get(dataClass, resourceClass, transcodeClass);
if (loadPathCache.isEmptyLoadPath(result)) {
return null;
} else if (result == null) {
// 获取DecodePath集合
List<DecodePath<Data, TResource, Transcode>> decodePaths =
getDecodePaths(dataClass, resourceClass, transcodeClass);
// It’s possible there is no way to decode or transcode to the desired types from a given
// data class.
if (decodePaths.isEmpty()) {
result = null;
} else {
// 通过DecodePath来创建LoadPath,并将其保存到缓存里,以便下次使用
result =
new LoadPath<>(
dataClass, resourceClass, transcodeClass, decodePaths, throwableListPool);
}
loadPathCache.put(dataClass, resourceClass, transcodeClass, result);
}
return result;
}
这个方法主要做了三件事:
(1)从缓存里面获取LoadPath,可见优化无处不在,能复用的绝不多次创建;
(2)获取DecodePath集合;
(3)根据DecodePath来创建LoadPath,并保存到缓存里;
这里的实现没有什么复杂的地方,下面来看看DecodePath的获取,具体是在Registry的getDecodePaths方法里;
private <Data, TResource, Transcode> List<DecodePath<Data, TResource, Transcode>> getDecodePaths(
@NonNull Class dataClass,
@NonNull Class resourceClass,
@NonNull Class transcodeClass) {
…
for (Class registeredResourceClass : registeredResourceClasses) {
…
for (Class registeredTranscodeClass : registeredTranscodeClasses) {
// 通过Glide构造方法注册的ResourceDecoder数据来创建DecodePath
List<ResourceDecoder<Data, TResource>> decoders =
decoderRegistry.getDecoders(dataClass, registeredResourceClass);
ResourceTranscoder<TResource, Transcode> transcoder =
transcoderRegistry.get(registeredResourceClass, registeredTranscodeClass);
@SuppressWarnings(“PMD.AvoidInstantiatingObjectsInLoops”)
DecodePath<Data, TResource, Transcode> path =
new DecodePath<>(
dataClass,
registeredResourceClass,
registeredTranscodeClass,
decoders,
transcoder,
throwableListPool);
decodePaths.add(path);
}
}
return decodePaths;
}
那么到这里我们就很清晰了,LoadPath和DecodePath都是在获取的时候创建的,通过Registry类保存的ResourceDecoder数据,先创建了DecodePath,然后再创建了LoadPath;
下面我们来看一下ResourceDecoder这个类的创建是怎么实现的;

看到这里一切就清晰明朗了,ResourceDecoder是Registry类在Glide的构造方法里面创建的,并保存到集合里;
然后在解码的时候,通过获取LoadPath,进而获取到DecodePath,而DecodePath是通过Registry类保存的ResourceDecoder数据来创建的;
看一下大致的流程图:

上面我们看完了从磁盘缓存获取的逻辑,下面来看看如果从网络获取图片数据的;
4.9、SourceGenerator
加载网络缓存的地方是在SourceGenerator类的startNext方法,我们来看一下大致的实现;
public boolean startNext() {
if (dataToCache != null) {
Object data = dataToCache;
dataToCache = null;
// 缓存数据
cacheData(data);
}
…
loadData = null;
boolean started = false;
while (!started && hasNextModelLoader()) {
loadData = helper.getLoadData().get(loadDataListIndex++);
if (loadData != null
&& (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource())
|| helper.hasLoadPath(loadData.fetcher.getDataClass()))) {
started = true;
startNextLoad(loadData);
}
}
return started;
}
这个方法做了两步,第一步是缓存数据,第二步就是从网络下载图片资源了;
下面这个实现看起来是不是很熟悉,和磁盘缓存的逻辑一样,也是通过ModelLoader来加载数据;
而这个ModelLoader也是通过Registry来获取的,创建的地方也是通过Registry在Glide的构造方法里进行创建,并缓存到缓存里;
而这里最终调用的ModelLoader是HttpGlideUrlLoader,加载网络数据的地方是在HttpUrlFetcher的loadData方法;
我们来看一下这个方法的实现;
public void loadData(
@NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) {
…
InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0, null, glideUrl.getHeaders());
callback.onDataReady(result);
} catch (IOException e) {
…
callback.onLoadFailed(e);
}
…
}
最终调用的地方是在loadDataWithRedirects方法;
这里面的实现,其实就是Android原生的网络请求,通过创建HttpURLConnection来从网络获取图片数据;
获取成功之后,就会将其保存到磁盘里去;
最后我还整理了很多Android中高级的PDF技术文档。以及一些大厂面试真题解析文档。

Android高级架构师之路很漫长,一起共勉吧!
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!
方法,我们来看一下大致的实现;
public boolean startNext() {
if (dataToCache != null) {
Object data = dataToCache;
dataToCache = null;
// 缓存数据
cacheData(data);
}
…
loadData = null;
boolean started = false;
while (!started && hasNextModelLoader()) {
loadData = helper.getLoadData().get(loadDataListIndex++);
if (loadData != null
&& (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource())
|| helper.hasLoadPath(loadData.fetcher.getDataClass()))) {
started = true;
startNextLoad(loadData);
}
}
return started;
}
这个方法做了两步,第一步是缓存数据,第二步就是从网络下载图片资源了;
下面这个实现看起来是不是很熟悉,和磁盘缓存的逻辑一样,也是通过ModelLoader来加载数据;
而这个ModelLoader也是通过Registry来获取的,创建的地方也是通过Registry在Glide的构造方法里进行创建,并缓存到缓存里;
而这里最终调用的ModelLoader是HttpGlideUrlLoader,加载网络数据的地方是在HttpUrlFetcher的loadData方法;
我们来看一下这个方法的实现;
public void loadData(
@NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) {
…
InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0, null, glideUrl.getHeaders());
callback.onDataReady(result);
} catch (IOException e) {
…
callback.onLoadFailed(e);
}
…
}
最终调用的地方是在loadDataWithRedirects方法;
这里面的实现,其实就是Android原生的网络请求,通过创建HttpURLConnection来从网络获取图片数据;
获取成功之后,就会将其保存到磁盘里去;
最后我还整理了很多Android中高级的PDF技术文档。以及一些大厂面试真题解析文档。
[外链图片转存中…(img-znLE4Ydw-1714750509755)]
Android高级架构师之路很漫长,一起共勉吧!
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!














 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









