







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


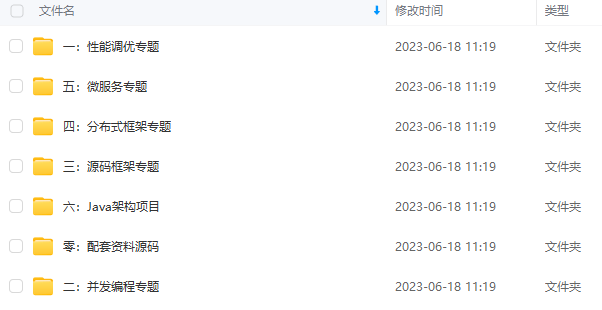
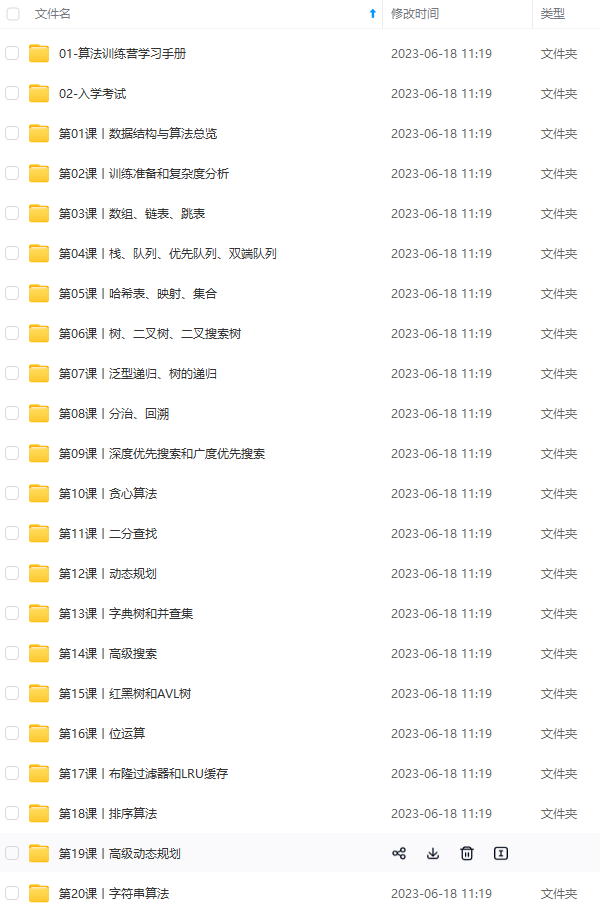
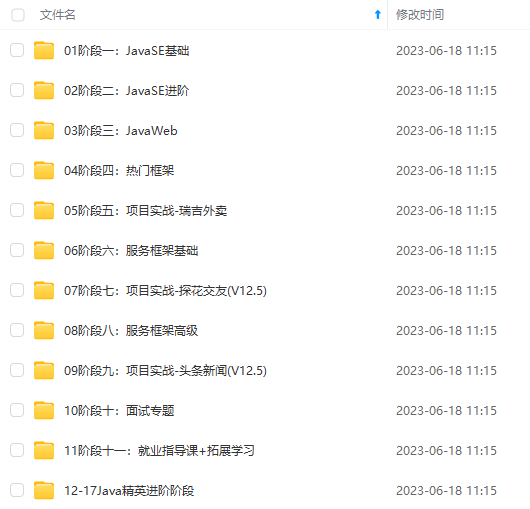
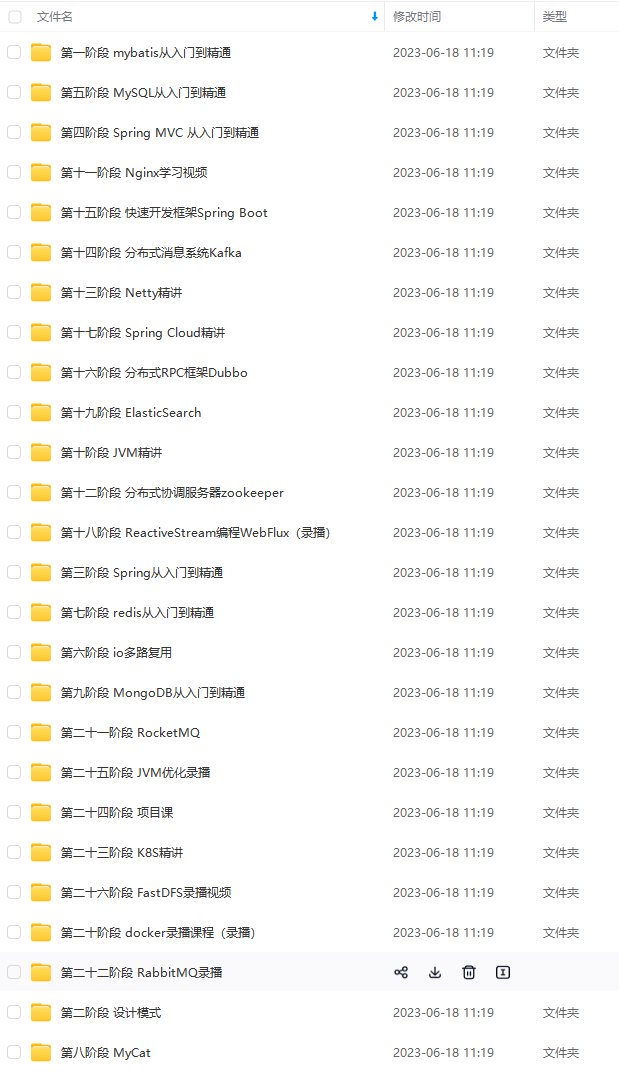
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
二狗:卧槽,还彪英文,来来来,这代码你给我解释下。
囧辉:我们先不看第一行“int n = cap - 1”,先看下面的5行计算。
|=(或等于):这个符号比较少见,但是“+=”应该都见过,看到这你应该明白了。例如:a |= b ,可以转成:a = a | b。
>>>(无符号右移):例如 a >>> b 指的是将 a 向右移动 b 指定的位数,右移后左边空出的位用零来填充,移出右边的位被丢弃。
假设 n 的值为 0010 0001,则该计算如下图:
相信你应该看出来,这5个公式会通过最高位的1,拿到2个1、4个1、8个1、16个1、32个1。当然,有多少个1,取决于我们的入参有多大,但我们肯定的是经过这5个计算,得到的值是一个低位全是1的值,最后返回的时候 +1,则会得到1个比n 大的 2 的N次方。
这时再看开头的 cap - 1 就很简单了,这是为了处理 cap 本身就是 2 的N次方的情况。
计算机底层是二进制的,移位和或运算是非常快的,所以这个方法的效率很高。
PS:这是 HashMap 中我个人最喜欢的设计,非常巧妙,真想给作者一个么么哒(不小心暴露了)。
二狗:(这叼毛讲的还凑合啊,连我都听懂了)你说 HashMap 的容量必须是 2 的 N 次方,这是为什么?
囧辉:计算索引位置的公式为:(n - 1) & hash,当 n 为 2 的 N 次方时,n - 1 为低位全是 1 的值,此时任何值跟 n - 1 进行 & 运算的结果为该值的低 N 位,达到了和取模同样的效果,实现了均匀分布。实际上,这个设计就是基于公式:x mod 2^n = x & (2^n - 1),因为 & 运算比 mod 具有更高的效率。
如下图,当 n 不为 2 的 N 次方时,hash 冲突的概率明显增大。
二狗:你说 HashMap 的默认初始容量是 16,为什么是16而不是其他的?
囧辉:(这是什么煞笔问题)我认为是16的原因主要是:16是2的N次方,并且是一个较合理的大小。如果用8或32,我觉得也是OK的。实际上,我们在新建 HashMap 时,最好是根据自己使用情况设置初始容量,这才是最合理的方案。
二狗:刚才说的负载因子默认初始值又是多少?
囧辉:负载因子默认值是0.75。
二狗:为什么是0.75而不是其他的?
囧辉:(又问这种憨逼问题)这个也是在时间和空间上权衡的结果。如果值较高,例如1,此时会减少空间开销,但是 hash 冲突的概率会增大,增加查找成本;而如果值较低,例如 0.5 ,此时 hash 冲突会降低,但是有一半的空间会被浪费,所以折衷考虑 0.75 似乎是一个合理的值。
二狗:为什么不是 0.74 或 0.76?
囧辉:
二狗:那我们换个问题问吧,HashMap 的插入流程是怎么样的?
囧辉:Talk is cheap. Show you the picture。
二狗:图里刚开始有个计算 key 的 hash 值,是怎么设计的?
囧辉:拿到 key 的 hashCode,并将 hashCode 的高16位和 hashCode 进行异或(XOR)运算,得到最终的 hash 值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
二狗:为什么要将 hashCode 的高16位参与运算?
囧辉:主要是为了在 table 的长度较小的时候,让高位也参与运算,并且不会有太大的开销。
例如下图,如果不加入高位运算,由于 n - 1 是 0000 0111,所以结果只取决于 hash 值的低3位,无论高位怎么变化,结果都是一样的。
如果我们将高位参与运算,则索引计算结果就不会仅取决于低位。
二狗:扩容(resize)流程介绍下?
囧辉:
二狗:红黑树和链表都是通过 e.hash & oldCap == 0 来定位在新表的索引位置,这是为什么?
囧辉:请看对下面的例子。
扩容前 table 的容量为16,a 节点和 b 节点在扩容前处于同一索引位置。
扩容后,table 长度为32,新表的 n - 1 只比老表的 n - 1 在高位多了一个1(图中标红)。
因为 2 个节点在老表是同一个索引位置,因此计算新表的索引位置时,只取决于新表在高位多出来的这一位(图中标红),而这一位的值刚好等于 oldCap。
因为只取决于这一位,所以只会存在两种情况:1) (e.hash & oldCap) == 0 ,则新表索引位置为“原索引位置” ;2)(e.hash & oldCap) != 0,则新表索引位置为“原索引 + oldCap 位置”。
二狗:HashMap 是线程安全的吗?
囧辉:不是。HashMap 在并发下存在数据覆盖、遍历的同时进行修改会抛出 ConcurrentModificationException 异常等问题,JDK 1.8 之前还存在死循环问题。
二狗:介绍一下死循环问题?
囧辉:导致死循环的根本原因是 JDK 1.7 扩容采用的是“头插法”,会导致同一索引位置的节点在扩容后顺序反掉。而 JDK 1.8 之后采用的是“尾插法”,扩容后节点顺序不会反掉,不存在死循环问题。
JDK 1.7.0 的扩容代码如下,用例子来看会好理解点。
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
PS:这个流程较难理解,建议对着代码自己模拟走一遍。
例子:我们有1个容量为2的 HashMap,loadFactor=0.75,此时线程1和线程2 同时往该 HashMap 插入一个数据,都触发了扩容流程,接着有以下流程。
1)在2个线程都插入节点,触发扩容流程之前,此时的结构如下图。
2)线程1进行扩容,执行到代码:Entry<K,V> next = e.next 后被调度挂起,此时的结构如下图。
3)线程1被挂起后,线程2进入扩容流程,并走完整个扩容流程,此时的结构如下图。
由于两个线程操作的是同一个 table,所以该图又可以画成如下图。
4)线程1恢复后,继续走完第一次的循环流程,此时的结构如下图。
5)线程1继续走完第二次循环,此时的结构如下图。
6)线程1继续执行第三次循环,执行到 e.next = newTable[i] 时形成环,执行完第三次循环的结构如下图。
如果此时线程1调用 map.get(11) ,悲剧就出现了——Infinite Loop。
二狗:(尼玛,没听懂,尴尬了)那总结下 JDK 1.8 主要进行了哪些优化?
囧辉:JDK 1.8 的主要优化刚才我们都聊过了,主要有以下几点:
1)底层数据结构从“数组+链表”改成“数组+链表+红黑树”,主要是优化了 hash 冲突较严重时,链表过长的查找性能:O(n) -> O(logn)。
2)计算 table 初始容量的方式发生了改变,老的方式是从1开始不断向左进行移位运算,直到找到大于等于入参容量的值;新的方式则是通过“5个移位+或等于运算”来计算。
// JDK 1.7.0
public HashMap(int initialCapacity, float loadFactor) {
// 省略
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// … 省略
}
// JDK 1.8.0_191
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
最后
即使是面试跳槽,那也是一个学习的过程。只有全面的复习,才能让我们更好的充实自己,武装自己,为自己的面试之路不再坎坷!今天就给大家分享一个Github上全面的Java面试题大全,就是这份面试大全助我拿下大厂Offer,月薪提至30K!
我也是第一时间分享出来给大家,希望可以帮助大家都能去往自己心仪的大厂!为金三银四做准备!
一共有20个知识点专题,分别是:
Dubbo面试专题

JVM面试专题

Java并发面试专题

Kafka面试专题

MongDB面试专题

MyBatis面试专题

MySQL面试专题

Netty面试专题

RabbitMQ面试专题

Redis面试专题

Spring Cloud面试专题

SpringBoot面试专题

zookeeper面试专题

常见面试算法题汇总专题

计算机网络基础专题

设计模式专题

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
zookeeper面试专题
[外链图片转存中…(img-cgBB5AVI-1713563484323)]
常见面试算法题汇总专题
[外链图片转存中…(img-noSRoR1n-1713563484324)]
计算机网络基础专题
[外链图片转存中…(img-VQFjrkYi-1713563484324)]
设计模式专题
[外链图片转存中…(img-iKs1XT06-1713563484325)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-xWjgcNhx-1713563484326)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









