






return item * 2;
}));
function sortarr(arr) {
for(i = 0; i < arr.length - 1; i++) {
for(j = 0; j < arr.length - 1 - i; j++) {
if(arr[j] > arr[j + 1]) {
var temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
console.log(sortarr(arr));
经过 UglifyJS3 的代码压缩混淆处理后的结果:
let times=1.8;function getExtra®{return[1,4,6].map(function(t){return tr})}var arr=[8,94,15,88,55,76,21,39];function sortarr®{for(i=0;i<r.length-1;i++)for(j=0;j<r.length-1-i;j++)if(r[j]>r[j+1]){var t=r[j];r[j]=r[j+1],r[j+1]=t}return r}arr=getExtra(times).concat(arr.map(function®{return 2r})),console.log(sortarr(arr));
经过 Google Closure Compiler 的代码压缩混淆处理后的结果:
var b=[8,94,15,88,55,76,21,39];b=function(a){return[1,4,6].map(function©{return ca})}(1.8).concat(b.map(function(a){return 2a}));console.log(function(a){for(i=0;i<a.length-1;i++)for(j=0;j<a.length-1-i;j++)if(a[j]>a[j+1]){var c=a[j];a[j]=a[j+1];a[j+1]=c}return a}(b));
对比上述两种工具的代码混淆压缩结果我们可以看到,UglifyJS 不会对原始代码进行“重写”,所有的压缩工作都是在代码原有结构的基础上进行的优化。而 GCC 对代码的优化则更靠近“编译器”,除了常见的变量、常量名去语义化外,还使用了常见的 DCE 优化策略,比如对常量表达式(constexpr)进行提前求值(0.1 * 8 + 1)、通过 “inline” 减少中间变量的使用等等。
UglifyJS 在处理优化 JavaScript 源代码时都是以其 AST 的形式进行分析的。比如在 Node.js 脚本中进行源码处理时,我们通常会首先使用 UglifyJS.parse 方法将一段 JavaScript 代码转换成其对应的 AST 形式,然后再通过 UglifyJS.Compressor 方法对这些 AST 进行处理。最后还需要通过print_to_string 方法将处理后的 AST 结构转换成相应的 ASCII 可读代码形式。UglifyJS.Compressor 的本质是一个官方封装好的 “TreeTransformer” 类型,其内部已经封装好了众多常用的代码优化策略,而通过对 UglifyJS.TreeTransformer 进行适当的封装,我们也可以编写自己的代码优化器。
如下所示我们编写了一个实现简单“常量传播”与“常量折叠”(注意这里其实是变量,但优化形式同 C++ 中的这两种基本优化策略相同)优化的 UglifyJS 转化器。
const UglifyJS = require(‘uglify-js’);
var symbolTable = {};
var binaryOperations = {
“+”: (x, y) => x + y,
“-”: (x, y) => x - y,
“*”: (x, y) => x * y
}
var constexpr = new UglifyJS.TreeTransformer(null, function(node) {
if (node instanceof UglifyJS.AST_Binary) {
if (Number.isInteger(node.left.value) && Number.isInteger(node.right.value)) {
return new UglifyJS.AST_Number({
value: binaryOperations[node.operator].call(this,
Number(node.left.value),
Number(node.right.value))
});
} else {
return new UglifyJS.AST_Number({
value: binaryOperations[node.operator].call(this,
Number(symbolTable[node.left.name].value),
Number(symbolTable[node.right.name].value))
})
}
}
if (node instanceof UglifyJS.AST_VarDef) {
// AST_VarDef -> AST_SymbolVar;
// 通过符号表来存储已求值的变量值(UglifyJS.AST_Number)引用;
symbolTable[node.name.name] = node.value;
}
});
var ast = UglifyJS.parse(`
var x = 10 * 2 + 6;
var y = 4 - 1 * 100;
console.log(x + y);
`);
// transform and print;
ast.transform(constexpr);
console.log(ast.print_to_string());
// output:
// var x=26;var y=-96;console.log(-70);
这里我们通过识别特定的 Uglify AST 节点类型(UglifyJS.AST_Binary / UglifyJS.AST_VarDef)来达到对代码进行精准处理的目的。可以看到,变量 x 和 y 的值在代码处理过程中被提前计算。不仅如此,其作为变量的值还被传递到了表达式 a + b 中,此时如果能够再结合简单的 DCE 策略便可以完成最初级的代码优化效果。类似的,其实通过 Babel 的 @babel/traverse 插件,我们也可以实现同样的效果,其所基于的原理也都大同小异,即对代码的 AST 进行相应的转换和处理。
WebAssembly
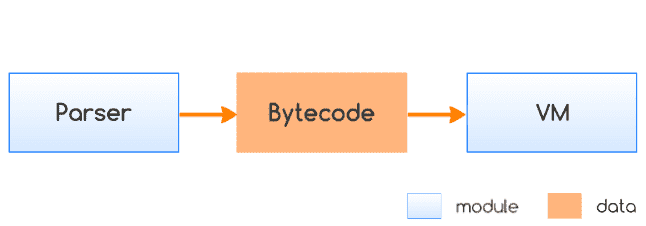
关于 Wasm 的基本介绍,这里我们不再多谈。那么到底应该如何利用 Wasm 的“字节码”特性来做到尽可能地做到“降低 JavaScript 代码可读性”这一目的呢?一个简单的 JavaScript 代码“加密”服务系统架构图如下所示:

这里整个系统分为两个处理阶段:
**第一阶段:**先将明文的 JavaScript 代码转换为基于特定 JavaScript 引擎(VM)的 OpCode 代码,这些二进制的 OpCode 代码会再通过诸如 Base64 等算法的处理而转换为经过编码的明文 ASCII 字符串格式;
**第二阶段:**将上述经过编码的 ASCII 字符串连同对应的 JavaScript 引擎内核代码统一编译成完整的 ASM / Wasm 模块。当模块在网页中加载时,内嵌的 JavaScript 引擎便会直接解释执行硬编码在模块中的、经过编码处理的 OpCode 代码;
比如我们以下面这段处于 Top-Level 层的 JavaScript 代码为例:
[1, 2, 3, 5, 6, 7, 8, 9].map(function(i) {
return i * 2;
}).reduce(function(p, i) {
return p + i;
}, 0);
按照正常的 VM 执行流程,上述代码在执行后会返回计算结果 82。这里我们以 JerryScript 这个开源的轻量级 JavaScript 引擎来作为例子,第一步首先将上述 ASCII 形式的代码 Feed 到该引擎中,然后便可以获得对应该引擎中间状态的 ByteCode 字节码。
然后再将这些二进制的字节码通过 Base64 算法编码成对应的可见字符形式。结果如下所示:
WVJSSgAAABYAAAAAAAAAgAAAAAEAAAAYAAEACAAJAAEEAgAAAAAABwAAAGcAAABAAAAAWDIAMhwyAjIBMgUyBDIHMgY6CCAIwAIoAB0AAToARscDAAAAAAABAAMBAQAhAgIBAQAAACBFAQCPAAAAAAABAAICAQAhAgICAkUBAIlhbQADAAYAcHVkZXIAAGVjAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA==
按照我们的架构思路,这部分被编码后的可见字符串会作为“加密”后的源代码被硬编码到包含有 VM 引擎核心的 Wasm 模块中。当模块被加载时,VM 会通过相反的顺序解码这段字符串,并得到二进制状态的 ByteCode。然后再通过一起打包进来的 VM 核心来执行这些中间状态的比特码。这里我们上述所提到的 ByteCode 实际上是以 JerryScript 内部的 SnapShot 快照结构存在于内存中的。
最后这里给出上述 Demo 的主要部分源码,详细代码可以参考 Github:
#include “jerryscript.h”
#include “cppcodec/base64_rfc4648.hpp”
#include
#include
#define BUFFER_SIZE 256
#ifdef WASM
#include “emscripten.h”
#endif
std::string encode_code(const jerry_char_t*, size_t);
const unsigned char* transferToUC(const uint32_t* arr, size_t length) {
auto container = std::vector();
for (size_t x = 0; x < length; x++) {
auto _t = arr[x];
container.push_back(_t >> 24);
container.push_back(_t >> 16);
container.push_back(_t >> 8);
container.push_back(_t);
}
return &container[0];
}
std::vector<uint32_t> transferToU32(const uint8_t* arr, size_t length) {
auto container = std::vector<uint32_t>();
for (size_t x = 0; x < length; x++) {
size_t index = x * 4;
uint32_t y = (arr[index + 0] << 24) | (arr[index + 1] << 16) | (arr[index + 2] << 8) | arr[index + 3];
container.push_back(y);
}
return container;
}
int main (int argc, char** argv) {
const jerry_char_t script_to_snapshot[] = u8R"(
[1, 2, 3, 5, 6, 7, 8, 9].map(function(i) {
return i * 2;
}).reduce(function(p, i) {
return p + i;
}, 0);
)";
std::cout << encode_code(script_to_snapshot, sizeof(script_to_snapshot)) << std::endl;
return 0;
最后
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
u8R"(
[1, 2, 3, 5, 6, 7, 8, 9].map(function(i) {
return i * 2;
}).reduce(function(p, i) {
return p + i;
}, 0);
)";
std::cout << encode_code(script_to_snapshot, sizeof(script_to_snapshot)) << std::endl;
return 0;
最后
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









