







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

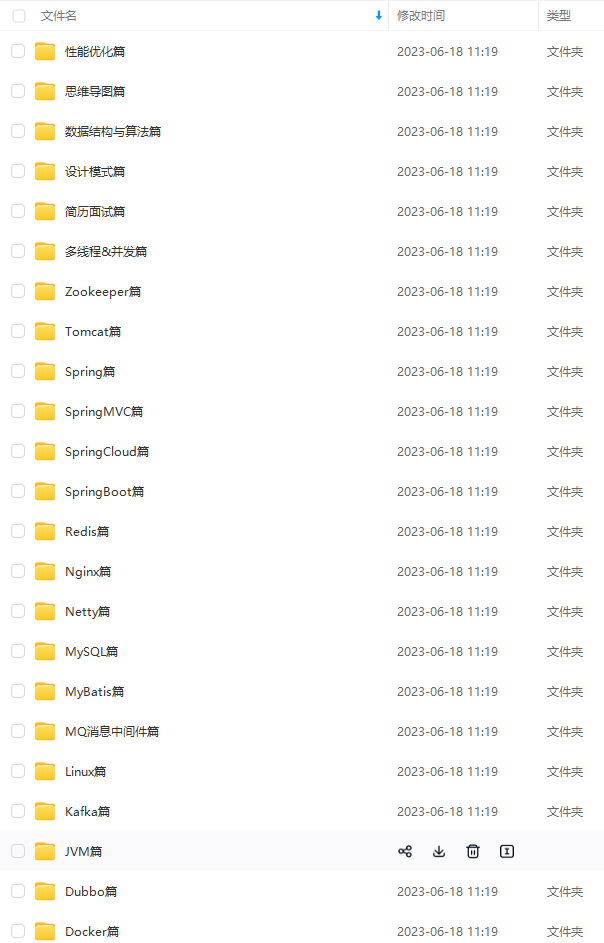
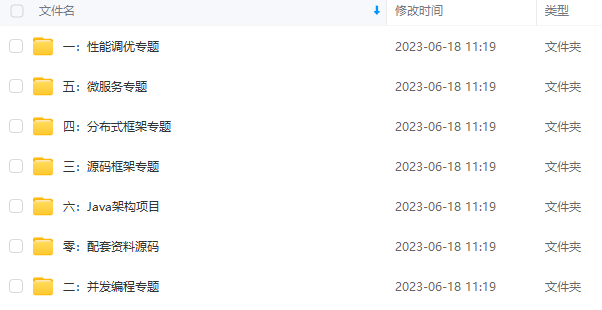
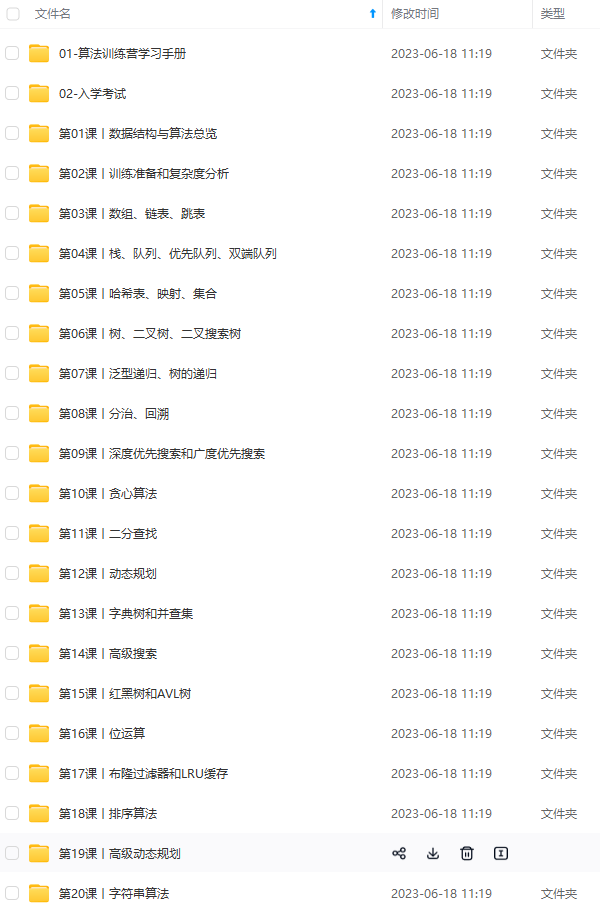
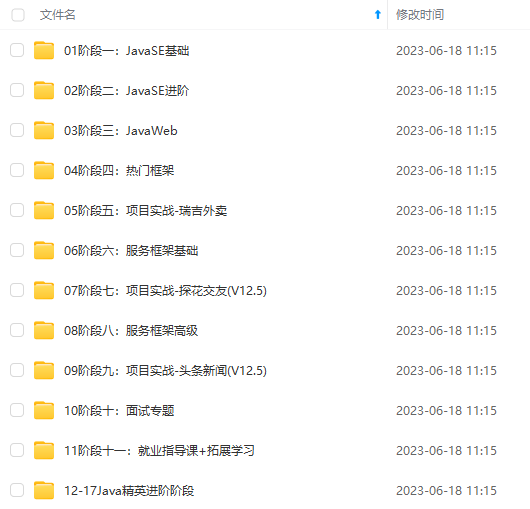
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
| 监督学习 | 无监督学习 |
| — | — |
| KNN算法 | 聚类算法(最经典,包括很多聚类算法) |
| 线性回归算法(Linear Regression) | 主成分分析 (PCA) |
| 逻辑回归算法(Logistic Regression) | 高斯混合模型 |
| 支持向量机(Support Vector Machine) | |
| 决策树和随机森林(Decision Tree and Random Forests) | |
| 神经网络(Neural Network) | |
============================================================================================
4.1 诊断偏差与方差(Diagnosing bias vs. variance)
-
偏差:可以用模型预测的误差,用以描述模型的预测精度;
-
方差:是每轮预测误差的范围(比如我第一次的得到的误差是0.5,第二次为1,那么方差就太大了),用以描述模型的稳定性。

如上图所示,左边的一点表明训练集的误差与验证集的误差相当,说明是高偏差的缘故,右边的一点表明验证集的误差比训练集的误差要大很多,说明是高方差的缘故。
4.3 当知道是高方差(过拟合)还是高偏差(欠拟合)的原因后,就可以知道用什么方法来解决。
-
什么是过拟合与欠拟合:简单来说,欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况;过拟合是指模型在训练集上表现很好,到了验证和测试阶段就大不如意了,即模型的泛化能力很差。
-
解决过拟合:增加训练数据集;使用正则化约束;减少特征数;调节参数和超参数;降低模型复杂度;提前结束训练(early stopping);使用 Dropout。
-
解决欠拟合:增加特征数;调节参数和超参数;增加模型复杂度;降低正则化约束。
4.4 出现不同的问题时,解决途径是不同的,如果用错了方法,有可能会得到相反的效果。
-
If a learning algorithm is suffering from high bias, getting more training data will not help much.
-
If a learning algorithm is suffering from high variance, getting more training data is likely to help.
如下图,通过在训练集上测得损失函数最小的参数,并把它们放在交叉训练集上验证。表明到当正则化参数为0.08时效果最好。


五、支持向量机(Support Vector Machine)
==================================================================================================





=========================================================================
- 数据压缩(Data Compression)
如果发现两个数据在大致情况下呈现线性关系,那么可以由此降维进行数据压缩,这样的话可以使得数据采集者的工作量减少,同时便于模型的建立。

- 数据可视化(Data Visualization)
因为人只能想象三维一下的图像,因此,数据的可视化一定要将高维降为三维及其以下。但是要注意的是,降维之后的数据一定还是要能完整表达原数据的分布。
- 主成分分析法(Principal Component Analysis(PCA))
通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。找到一个超平面(由向量张成的空间),当数据的各个点映射到这个面上的误差最小,那么,这个面,就是最好的超平面。
- 子集选择(Subset Selection)
这个方法非常的暴力,即利用枚举的方式求得所有情况。如下图:

红色点为当前k个variable能达到的最小二乘,灰色点为其他非最优的情况。(若k的时候求最优选择了某个variable,那么大于k的情况求最优不一定会选择该variable。)
- 核方法降维(kernel method)——增维
核方法是一类把低维空间的非线性可分问题,转化为高维空间的线性可分问题的方法。核方法不仅仅用于SVM,还可以用于其他数据为非线性可分的算法。核方法的理论基础是Cover’s theorem,指的是对于非线性可分的训练集,可以大概率通过将其非线性映射到一个高维空间来转化成线性可分的训练集。
- 维度灾难的解决办法
https://www.jianshu.com/p/867193608bbd
===========================================================================
- booststrap——Sample n samples from the overall N samples with replacement
步骤:
读者福利
分享一份自己整理好的Java面试手册,还有一些面试题pdf
不要停下自己学习的脚步


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-D8DkQwFI-1713475060162)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









