







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
4)**终端:**指用户使用IM系统的机器(通常有Android端、iOS端、Web端等等)。
5)**未读数:**指用户还没读的消息数量。
6)**用户状态:**指用户当前是在线、离线还是挂起等状态。
7)**关系链:**是指用户与用户之间的关系,通常有单向的好友关系、双向的好友关系、关注关系等等(这里需要注意与会话的区别:用户只有在发起聊天时才产生会话,但关系并不需要聊天才能建立。对于关系链的存储,可以使用图数据库(Neo4j等等),可以很自然地表达现实世界中的关系,易于建模)。
8)**单聊:**一对一聊天。
9)**群聊:**多人聊天。
10)**客服:**在电商领域,通常需要对用户提供售前咨询、售后咨询等服务(这时,就需要引入客服来处理用户的咨询)。
11)**消息分流:**在电商领域,一个店铺通常会有多个客服,此时决定用户的咨询由哪个客服来处理就是消息分流(通常消息分流会根据一系列规则来确定消息会分流给哪个客服,例如客服是否在线(客服不在线的话需要重新分流给另一个客服)、该消息是售前咨询还是售后咨询、当前客服的繁忙程度等等)。
12)**信箱:**本文的信箱我们指一个Timeline、一个收发消息的队列。
读扩散 vs 写扩散
IM系统里经常会涉及到读扩散和写扩散这两个技术概念,我们来看看。
读扩散
读扩散也称为“拉模式”,这应该是最符合我们认知直觉的一种技术实现方式。
原理如下图:
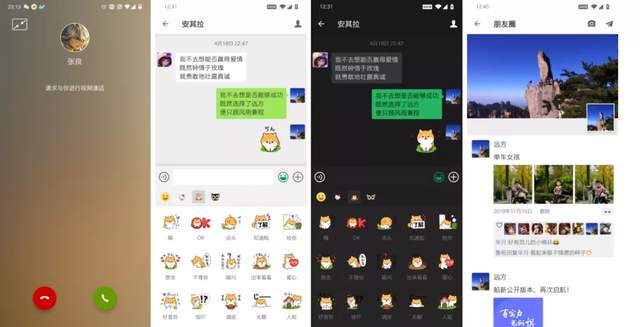
**如上图所示:**每一个内容发布者都有一个自己的发件箱(“我发布的内容”),每当我们发出一个新帖子,都存入自己的发件箱中。当我们的粉丝来阅读时,系统首先需要拿到粉丝关注的所有人,然后遍历所有发布者的发件箱,取出他们所发布的帖子,然后依据发布时间排序,展示给阅读者。
**这种设计:**阅读者读一次消息流,后台会扩散为N次读操作(N等于关注的人数)以及一次聚合操作,因此称为读扩散。每次读消息流相当于去关注者的收件箱主动拉取帖子,因此也得名——拉模式。
这种模式:
1)**好处是:**底层存储简单,没有空间浪费。
2)**坏处是:**每次读操作会非常重,操作非常多。
**设想一下:**如果我关注的人数非常多,遍历一遍我所关注的所有人,并且再聚合一下,这个系统开销会非常大,时延上可能达到无法忍受的地步。
**因此:**读扩散主要适用系统中阅读者关注的人没那么多,并且刷消息流并不频繁的场景。
**拉模式还有一个比较大的缺点:**就是分页不方便,我们刷微博或朋友圈,肯定是随着大拇指在屏幕不断划动,内容一页一页的从后台拉取。如果不做其他优化,只采用实时聚合的方式,下滑到比较靠后的页码时会非常麻烦。
写扩散
**据统计:**大多数消息流产品的读写比大概在100:1,也就是说大部分情况都是刷消息流看别人发的朋友圈和微博,只有很少情况是自己亲自发一条朋友圈或微博给别人看。
**因此:**读扩散那种很重的读逻辑并不适合大多数场景。
我们宁愿让发帖的过程复杂一些,也不愿影响用户读消息流的体验,因此稍微改造一下前面方案就有了写扩散。写扩散也称为“推模式”,这种模式会对拉模式的一些缺点做改进。
原理如下图:
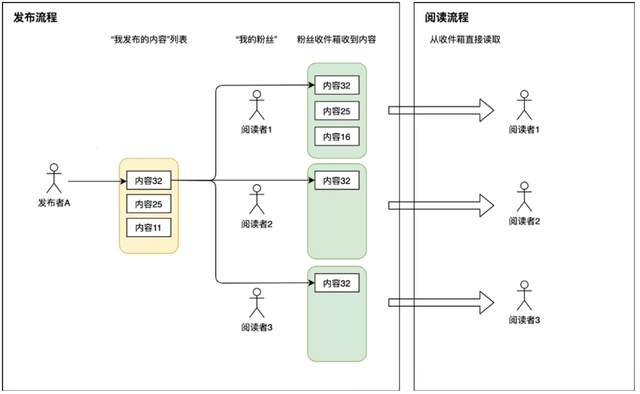
**如上图所示:**系统中每个用户除了有发件箱,也会有自己的收件箱。当发布者发表一篇帖子的时候,除了往自己发件箱记录一下之外,还会遍历发布者的所有粉丝,往这些粉丝的收件箱也投放一份相同内容。这样阅读者来读消息流时,直接从自己的收件箱读取即可。
这种设计:每次发表帖子,都会扩散为M次写操作(M等于自己的粉丝数),因此成为写扩散。每篇帖子都会主动推送到所有粉丝的收件箱,因此也得名推模式。
**这种模式可想而知:**发一篇帖子,背后会涉及到很多次的写操作。通常为了发帖人的用户体验,当发布的帖子写到自己发件箱时,就可以返回发布成功。后台另外起一个异步任务,不慌不忙地往粉丝收件箱投递帖子即可。
写扩散的好处在于通过数据冗余(一篇帖子会被存储M份副本),提升了阅读者的用户体验。通常适当的数据冗余不是什么问题,但是到了微博明星这里,完全行不通。比如目前微博粉丝量Top2的谢娜与何炅,两个人微博粉丝过亿。
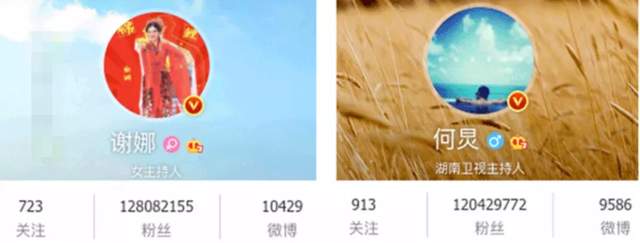
**设想一下:**如果单纯采用推模式,那每次谢娜何炅发一条微博,微博后台都要地震一次。一篇微博导致后台上亿次写操作,这显然是不可行的。
**另外:**由于写扩散是异步操作,写得太慢会导致帖子发出去半天,有些粉丝依然没能看见,这种体验也不太好。
通常写扩散适用于好友量不大的情况,比如微信朋友圈正是写扩散模式。每一名微信用户的好友上限为5000人,也就是说你发一条朋友圈最多也就扩散到5000次写操作,如果异步任务性能好一些,完全没有问题。
那对于上面说的超级大V到底是采用读扩散还是写扩散了,其实都不是,在业界还有另一种读写混合模式。
亿级架构核心点
由于概念比较多,一篇文章是不可能全部描述清楚的,还有像钉钉、微信与微博这种亿级海量用户的系统架构实现其实有很多难点,随便给你说几个,看下你自己是否知道!
1、亿级用户同时在线聊天如何保证高并发聊天消息正常推送
2、公众号千万级粉丝大V发文章如何让粉丝高效收取
3、高并发聊天系统如何保证发送的消息不乱序
4、微信钉钉后端海量离线消息如何高效存储与获取
Kafka实战笔记
关于这份笔记,为了不影响大家的阅读体验,我只能在文章中展示部分的章节内容和核心截图

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置

- Kafka的集群
- 第一个Kafka程序

afka的生产者

- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

- Kafka实战之削峰填谷

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-2ZFNissM-1713552823617)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









