







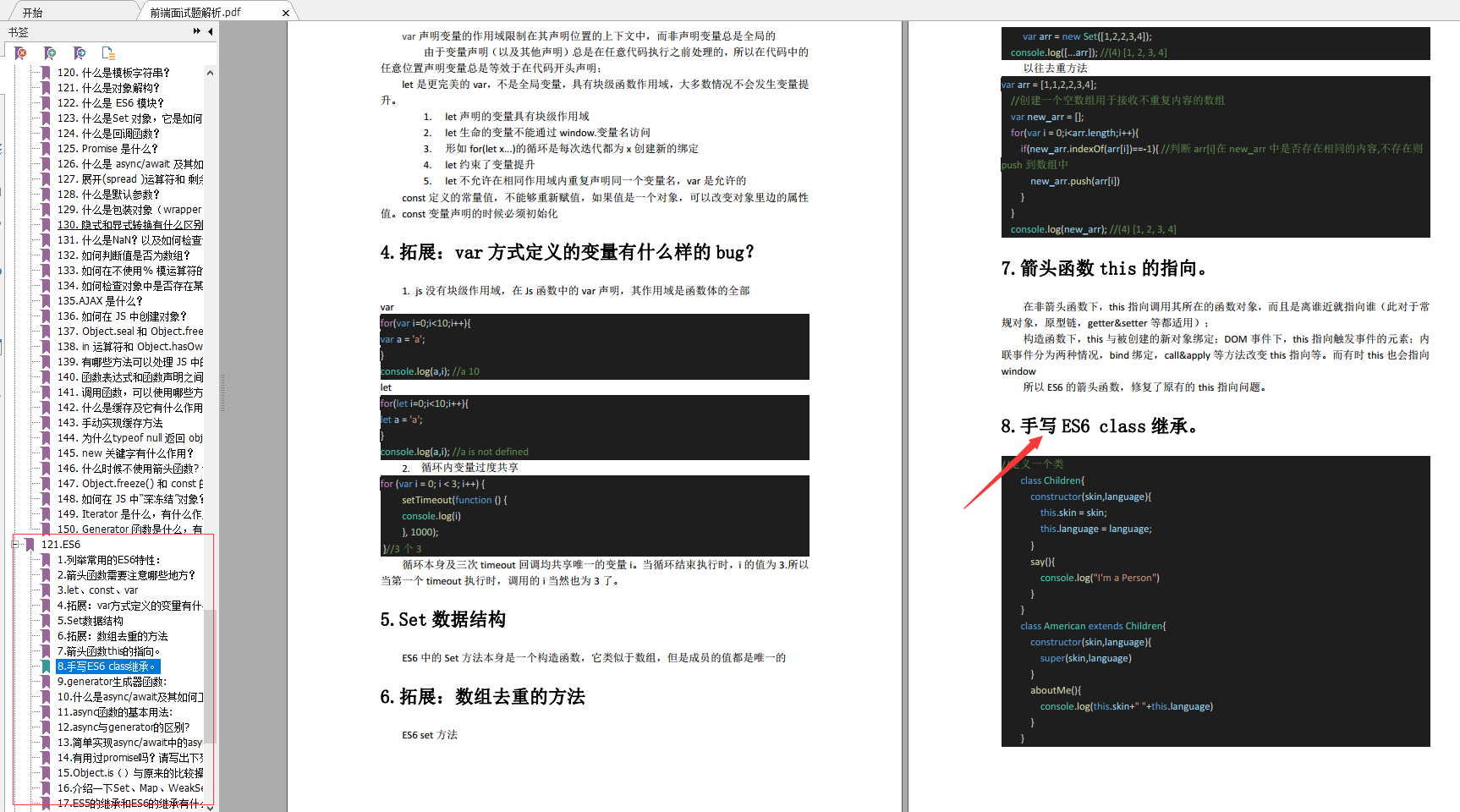
ES6
-
列举常用的ES6特性:
-
箭头函数需要注意哪些地方?
-
let、const、var
-
拓展:var方式定义的变量有什么样的bug?
-
Set数据结构
-
拓展:数组去重的方法
-
箭头函数this的指向。
-
手写ES6 class继承。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
微信小程序
-
简单描述一下微信小程序的相关文件类型?
-
你是怎么封装微信小程序的数据请求?
-
有哪些参数传值的方法?
-
你使用过哪些方法,来提高微信小程序的应用速度?
-
小程序和原生App哪个好?
-
简述微信小程序原理?
-
分析微信小程序的优劣势
-
怎么解决小程序的异步请求问题?

其他知识点面试
-
webpack的原理
-
webpack的loader和plugin的区别?
-
怎么使用webpack对项目进行优化?
-
防抖、节流
-
浏览器的缓存机制
-
描述一下二叉树, 并说明二叉树的几种遍历方式?
-
项目类问题
-
笔试编程题:

最后
技术栈比较搭,基本用过的东西都是一模一样的。快手终面喜欢问智力题,校招也是终面问智力题,大家要准备一下一些经典智力题。如果排列组合、概率论这些基础忘了,建议回去补一下。
风急天高猿啸哀,渚清沙白鸟飞回。
无边落木萧萧下,不尽长江滚滚来。
万里悲秋常作客,百年多病独登台。
艰难苦恨繁霜鬓,潦倒新停浊酒杯。
——杜甫《登高》
语雀地址:https://www.yuque.com/beilayanmen
Github地址:https://github.com/SuZui-cn/my-web
Gitee地址:https://gitee.com/north_gate/my-web
个人博客地址:https://foollyone.cn/
-
DOM介绍
-
获取节点
-
通过ID获取
-
用类名获取
-
用CSS选择器获取
-
用name属性获取
-
用标签获取
-
获取属性
-
获取元素内容
-
获取表单数据
-
创建节点
-
插入节点
-
删除节点
-
事件
-
轮播图案例
在本节中会学习如何使用DOM,也就是用js操作标签和属性,还是一样的,学计算机就要多写代码。所以再次建议大家多写代码。
先来介绍一下什么是DOM。
文档对象模型(DOM)是表示和操作HTML和XML文档内容的基础API。API不是特别复杂,但是需要理解大量的架构细节。首先,应该理解HTML或XML文档的嵌套元素在DOM树对象中的表示。HTML文档的树状结构包含表示HTML标签或元素(如、
)和表示文本字符串的节点,它也可能包含表示HTML注释的节点。
——弗兰纳根《JavaScript权威指南》
节点演示如下:
这是一级标题
这里是段落
我们把上面的代码转换成树状图,如下图:
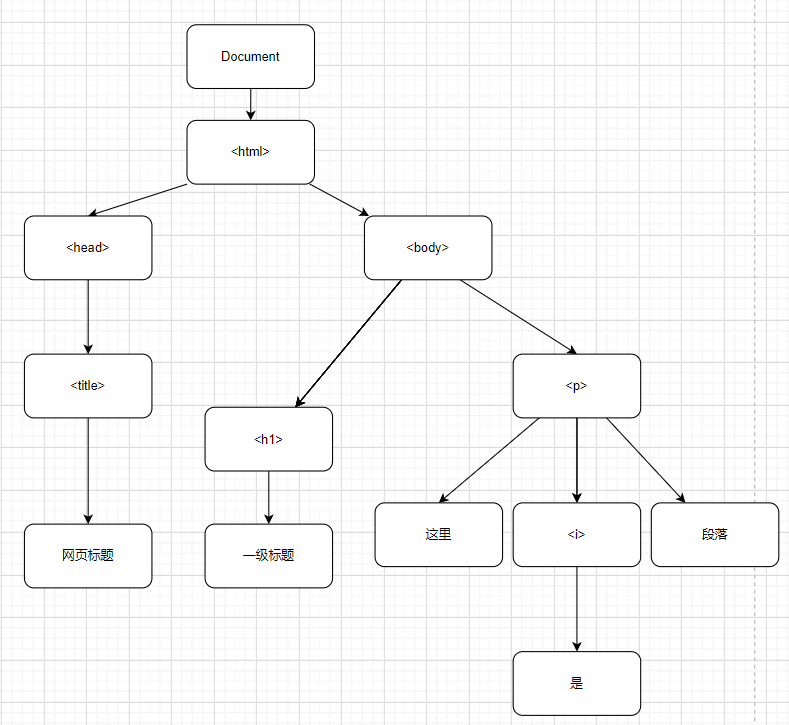
在上面的图中,每个方框是文档的一个节点,它表示一个Node对象。同时,上图包含了3种不同类型的节点。树形的根部是Document节点,它代表整个文档。代表HTML元素的节点是Element节点,代表文本的节点是Text节点。Document、Element和Text是Node的子类,在第四部分中它们有自己的条目。Document和Element是两个重要的DOM类,本章大部分内容将阐述它们的属性和方法。
注意,通用的Document和Element类型与HTMLDocument和HTMLElement类型之间是有严格的区别的。Document类型代表一个HTML或XML文档,Element类型代表该文档中的一个元素。HTMLDocument和HTMLElement子类只是针对于HTML文档和元素。
在一个节点之上的直接节点是其父节点,在其下一层的直接节点是其子节点。在同一层上具有相同父节点的节点是兄弟节点。在一个节点之下的所有层级的一组节点是其后代节点。一个节点的任何父节点、祖父节点和其上层的所有节点是祖先节点。
文档节点的部分层次结构图:

大多数客户端JavaScript程序运行时总是在操作一个或多个文档元素。当这些程序启动时,可以使用全局变量document来引用Document对象。但是,为了操作文档中的元素,必须通过某种方式获得或选取这些引用文档元素的Element对象。DOM定义许多方式来选取元素,查询文档的一个或多个元素有如下方法:
-
用指定的id属性;
-
用指定的类名;
-
匹配指定的选择器。
-
用指定的name属性;
-
用指定的标签名字;
用ID获取
任何HTML元素可以有一个id属性,在文档中该值必须唯一,即同一个文档中的两个元素不能有相同的ID。可以用Document对象的getElementById()方法选取一个基于唯一ID的元素。
pass:在使用getElementById() 方法的时候里面的参数不需要加#。

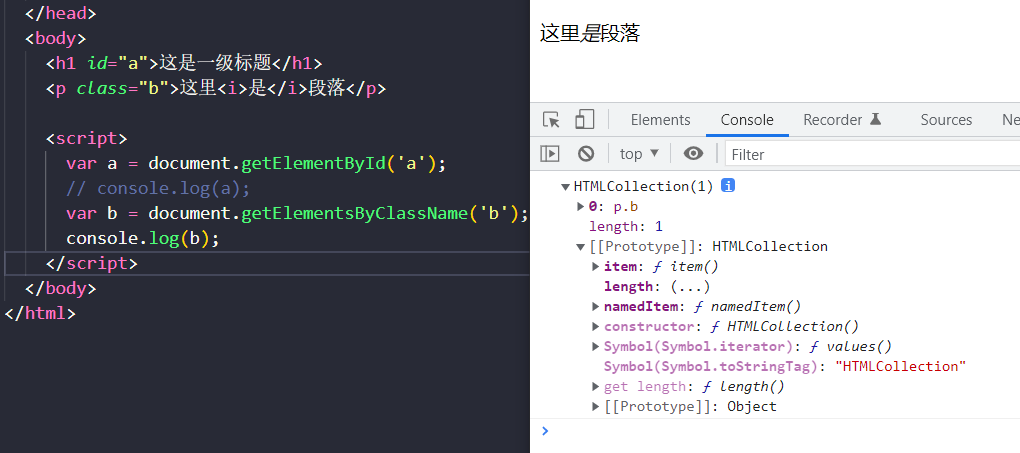
用类名获取
HTML元素的class属性值是一个以空格隔开的列表,可以为空或包含多个标识符。它描述一种方法来定义多组相关的文档元素:在它们的class属性中有相同标识符的任何元素属于该组的一部分。在JavaScript中class是保留字,所以客户端JavaScript使用className属性来保存HTML的class属性值。class属性通常与CSS样式表一起使用,对某组内的所有元素应用相同的样式。
用CSS选择器获取
CSS选择器可以使用下面的方法选取元素:通过ID、名字、标签名和类名。与CSS3选择器的标准化一起的另一个称做“选择器API”的W3C标准定义了获取匹配一个给定选择器的元素的JavaScript方法。该API的关键是Document方法querySelectorAll()。它接受包含一个CSS选择器的字符串参数,返回一个表示文档中匹配选择器的所有元素的NodeList对象。与前面描述的选取元素的方法不同,querySelectorAll()返回的NodeList对象并不是实时的:它包含在调用时刻选择器所匹配的元素,但它并不更新后续文档的变化。如果没有匹配的元素,querySelectorAll()将返回一个空的NodeList对象。如果选择器字符串非法,querySelectorAll()将抛出一个异常。

除了querySelectorAll(),文档对象还定义了querySelector()方法。与querySelectorAll()的工作原理类似,但它只是返回第一个匹配的元素(以文档顺序)或者如果没有匹配的元素就返回null。

pass:CSS定义了“:first-line”和“:first-letter”等伪元素。在CSS中,它们匹配文本节点的一部分而不是实际元素。如果和querySelectorAll()或querySelector()一起使用它们是不匹配的。而且,很多浏览器会拒绝返回“:link”和“:visited”等伪类的匹配结果,因为这会泄露用户的浏览历史记录。
用name属性获取
HTML的name属性最初打算为表单元素分配名字,在表单数据提交到服务器时使用该属性的值。类似id属性,name是给元素分配名字,但是区别于id,name属性的值不是必须唯一:多个元素可能有同样的名字,在表单中,单选和复选按钮通常是这种情况。而且,和id不一样的是name属性只在少数HTML元素中有效,包括表单、表单元素、和元素。基于name属性的值选取HTML元素,可以使用Document对象的getElementsByName()方法。
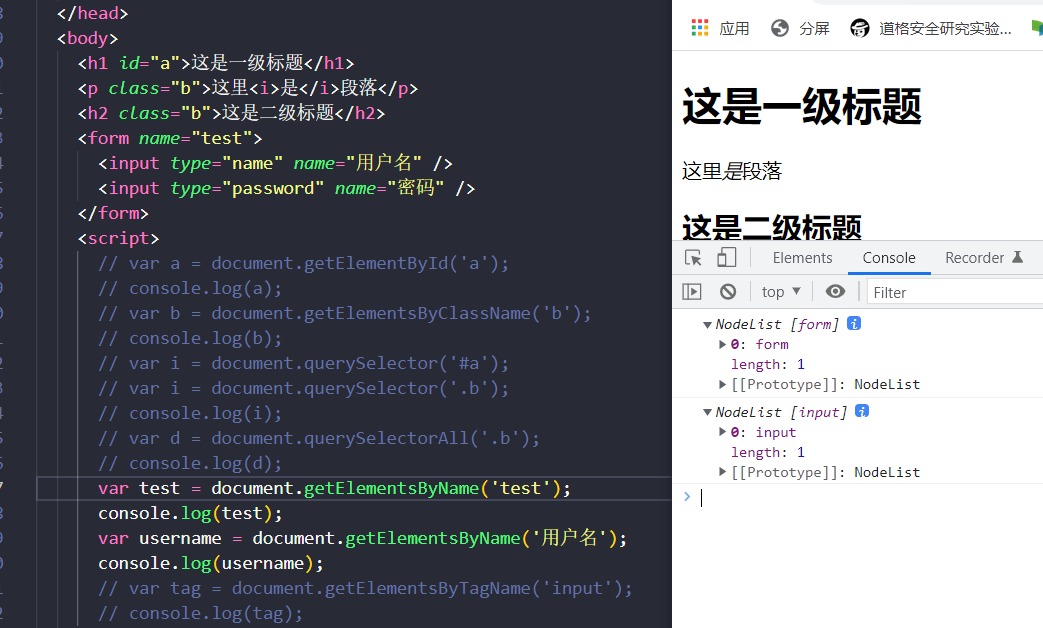
getElementsByName()定义在HTMLDocument类中,而不在Document类中,所以它只针对HTML文档可用,在XML文档中不可用。它返回一个NodeList对象,后者的行为类似一个包含若干Element对象的只读数组。在IE中,getElementsByName()也返回id属性匹配指定值的元素。为了兼容,应该小心谨慎,不要将同样的字符串同时用做名字和ID。
用标签获取
Document对象的getElementsByTagName()方法可用来选取指定类型(标签名)的所有HTML或XML元素。例如,如下代码,在文档中获得包含所有元素的只读的类数组对象:

获取属性
HTML元素由一个标签和一组称为属性(attribute)的名/值对组成。例如,元素定义了一个超链接,它的href属性值作为链接的目的地址。HTML元素的属性值在代表这些元素的HTMLElement对象的属性(property)中是可用的。DOM还定义了另外的API来获取或设置XML属性值和非标准的HTML属性。
比如下面的获取图片标签的属性。
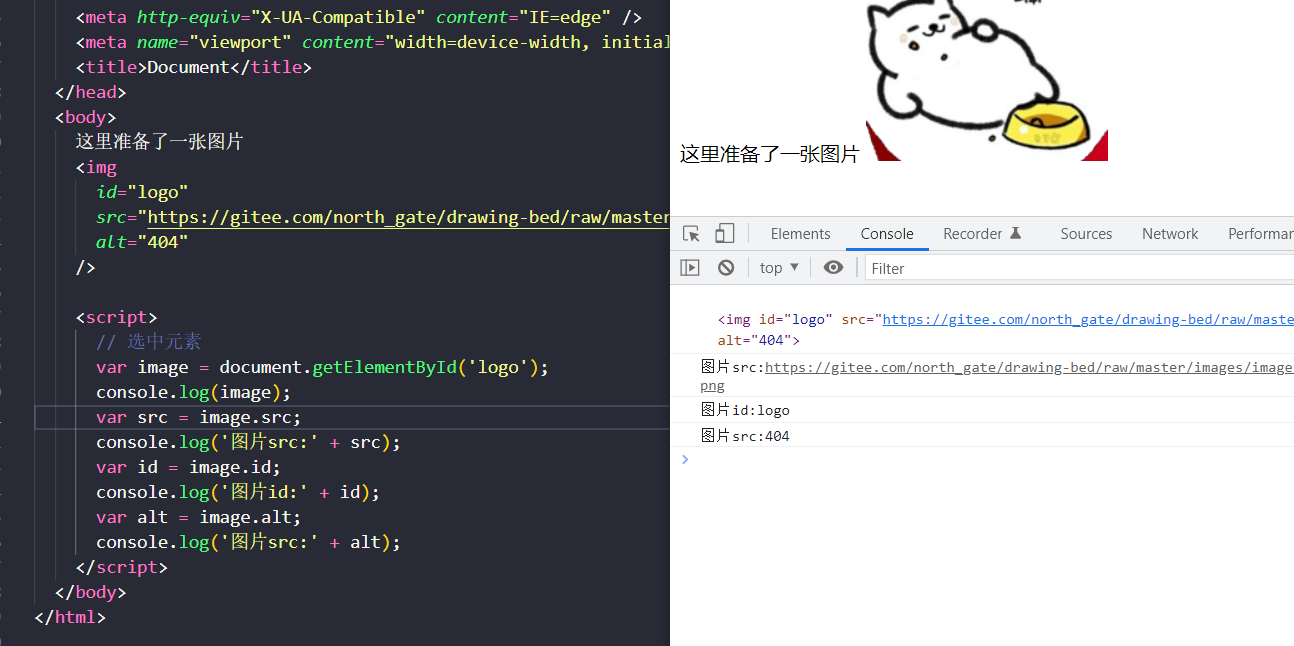
获取元素内容
在DOM中我们可以通过innerHTML 或者 innerText 来获取内容。操作如下:

同时我们也可以使用这两个属性给标签设置内容,但是我们需要知道这两个属性在设置内容上的区别,innerHTML 如果设置的内容含有标签的话会渲染,而 innerText 则不会渲染。
具体如下:
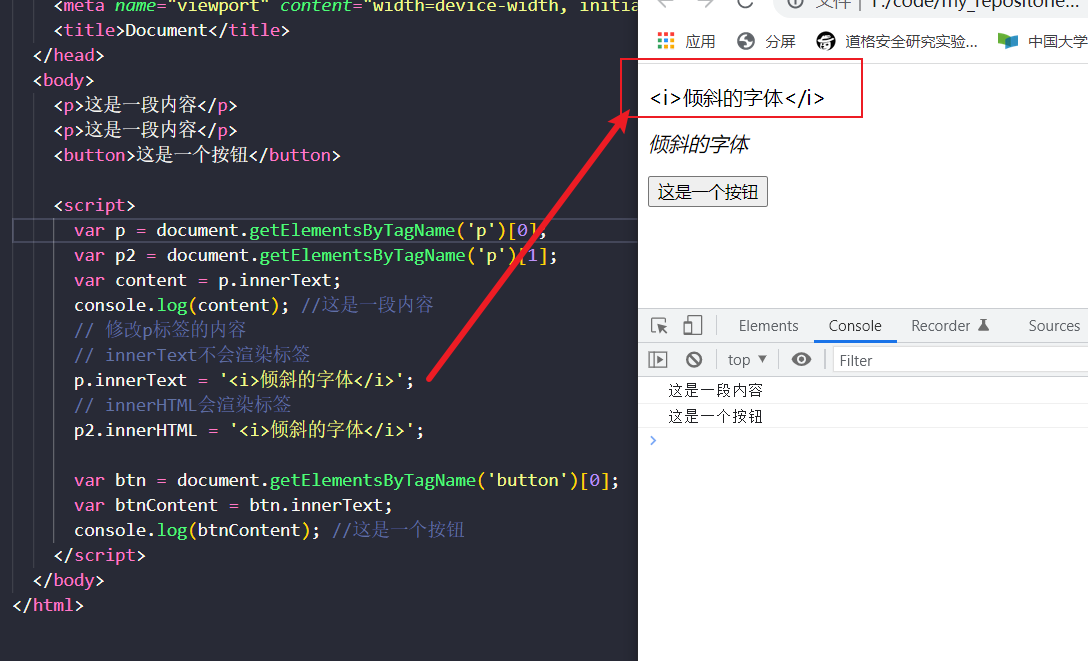
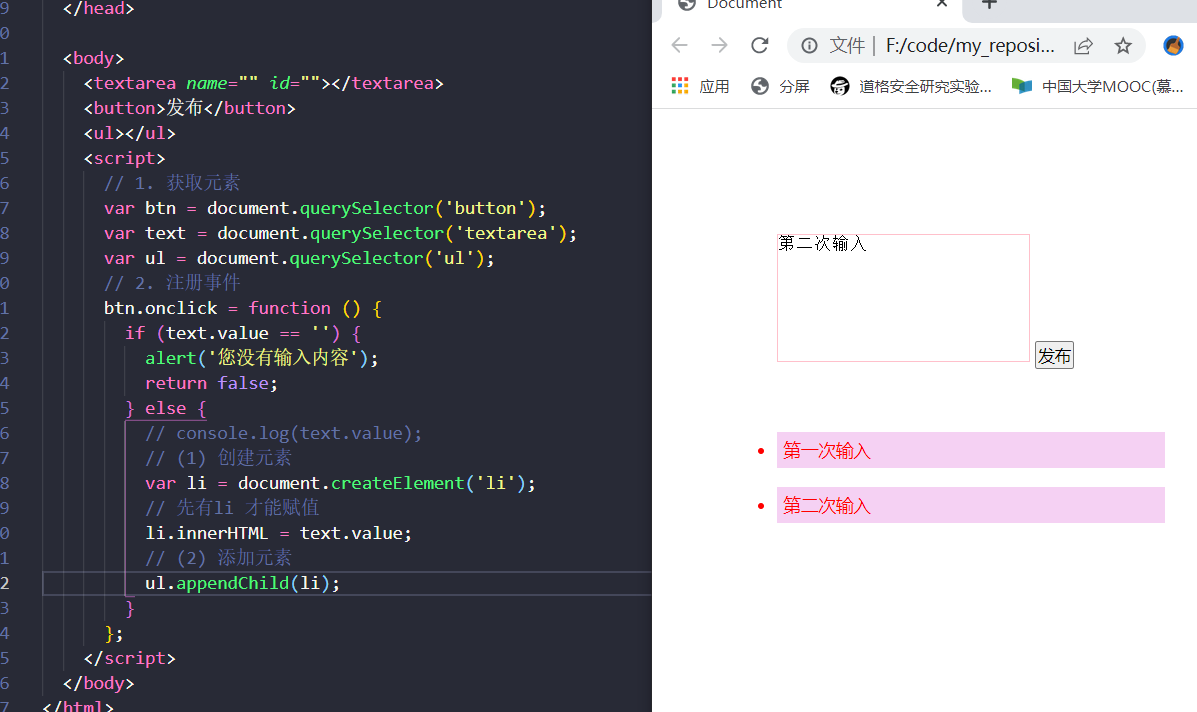
获取表单数据
我们可以使用value 属性来获取表单的数据。

具体代码如下:
用户名:
密码:
性别:男
女
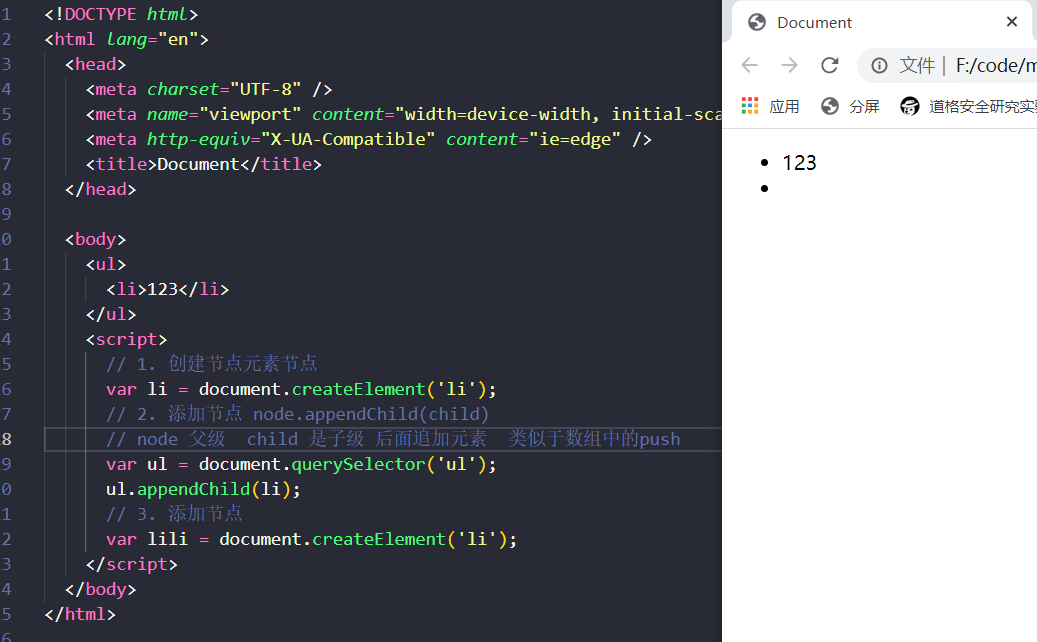
创建新的Element节点可以使用Document对象的createElement()方法。给方法传递元素的标签名:对HTML文档来说该名字不区分大小写。
让我们来看一个案例:
















 1752
1752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









